Poradce pro Apache Spark pro rady k poznámkovým blokům v reálném čase
Poradce Pro Apache Spark analyzuje příkazy a kód spouštěný Apache Sparkem a zobrazuje rady pro spuštění poznámkového bloku v reálném čase. Poradce pro Apache Spark má předdefinované vzory, které uživatelům pomůžou vyhnout se běžným chybám. Nabízí doporučení pro optimalizaci kódu, provádí analýzu chyb a vyhledá původní příčinu selhání.
Předdefinované rady
Poradce Spark, nástroj integrovaný s Impulsem, poskytuje integrované vzory pro zjišťování a řešení problémů v aplikacích Apache Spark. Tento článek vysvětluje některé vzory, které jsou součástí nástroje.
Podokno Poslední spuštění můžete otevřít na základě typu potřebné rady.
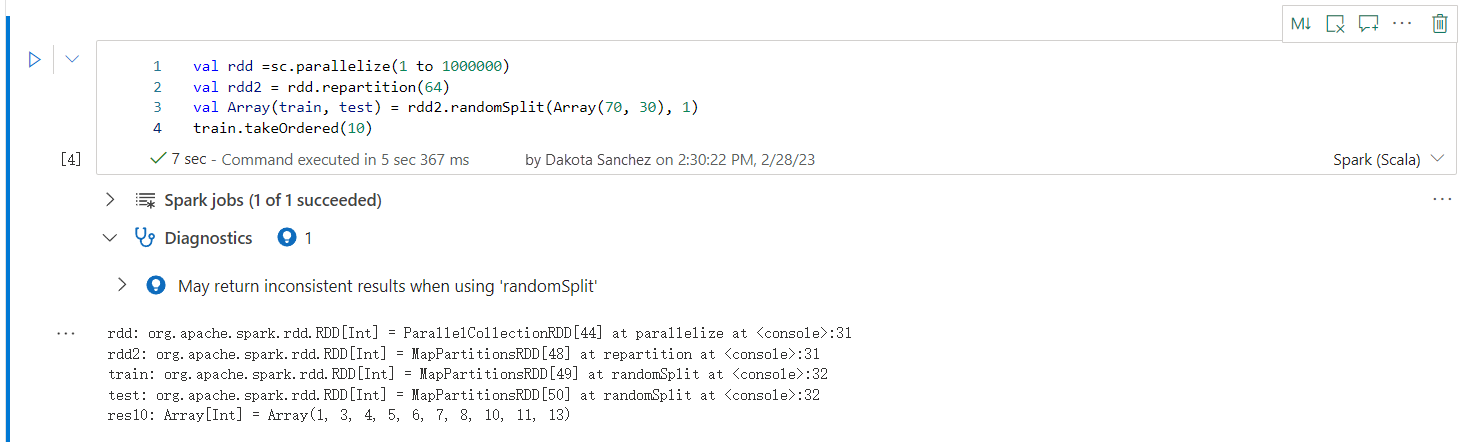
Při použití metody randomSplit může vrátit nekonzistentní výsledky.
Při práci s metodou randomSplit mohou být vráceny nekonzistentní nebo nepřesné výsledky. Před použitím metody randomSplit() použijte mezipaměť Apache Sparku (RDD).
Metoda randomSplit() je ekvivalentní provedení sample() na datovém rámci několikrát. Kde každá ukázka načítá, rozdělí a seřadí datový rámec v rámci oddílů. Distribuce dat mezi oddíly a pořadí řazení je důležitá pro randomSplit() i sample(). Pokud se při opětovném načtení dat změní, můžou existovat duplicitní hodnoty nebo chybějící hodnoty napříč rozděleními. Stejný vzorek, který používá stejné počáteční hodnoty, může vést k různým výsledkům.
K těmto nekonzistencem nemusí dojít při každém spuštění, ale k jejich úplnému odstranění, uložení datového rámce do mezipaměti, opětovné rozdělení do sloupců nebo použití agregačních funkcí, jako je groupBy.
Název tabulky nebo zobrazení se už používá.
Zobrazení již existuje se stejným názvem jako vytvořená tabulka nebo tabulka již existuje se stejným názvem jako vytvořené zobrazení. Pokud se tento název použije v dotazech nebo aplikacích, vrátí se pouze zobrazení bez ohledu na to, který z nich byl vytvořen jako první. Pokud se chcete vyhnout konfliktům, přejmenujte tabulku nebo zobrazení.
Nelze rozpoznat nápovědu
spark.sql("SELECT /*+ unknownHint */ * FROM t1")
Nelze najít zadané názvy relací.
Nelze najít relace zadané v nápovědě. Ověřte, že jsou relace zadány správně a přístupné v rámci rozsahu nápovědy.
spark.sql("SELECT /*+ BROADCAST(unknownTable) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Nápověda v dotazu zabraňuje použití jiné nápovědy.
Vybraný dotaz obsahuje nápovědu, která brání použití jiné nápovědy.
spark.sql("SELECT /*+ BROADCAST(t1), MERGE(t1, t2) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Povolte spark.advise.divisionExprConvertRule.enable, abyste snížili šíření chyb zaokrouhlování.
Tento dotaz obsahuje výraz s dvojitým typem. Doporučujeme povolit konfiguraci spark.advise.divisionExprConvertRule.enable, což může pomoct snížit výrazy dělení a snížit šíření chyby zaokrouhlování.
"t.a/t.b/t.c" convert into "t.a/(t.b * t.c)"
Povolení spark.advise.nonEqJoinConvertRule.enable za účelem zlepšení výkonu dotazů
Tento dotaz obsahuje časově náročné spojení kvůli podmínce Or v dotazu. Doporučujeme povolit konfiguraci spark.advise.nonEqJoinConvertRule.enable, která může pomoct převést spojení aktivované podmínkou "Or" na SMJ nebo BHJ a zrychlit tento dotaz.
Uživatelské prostředí
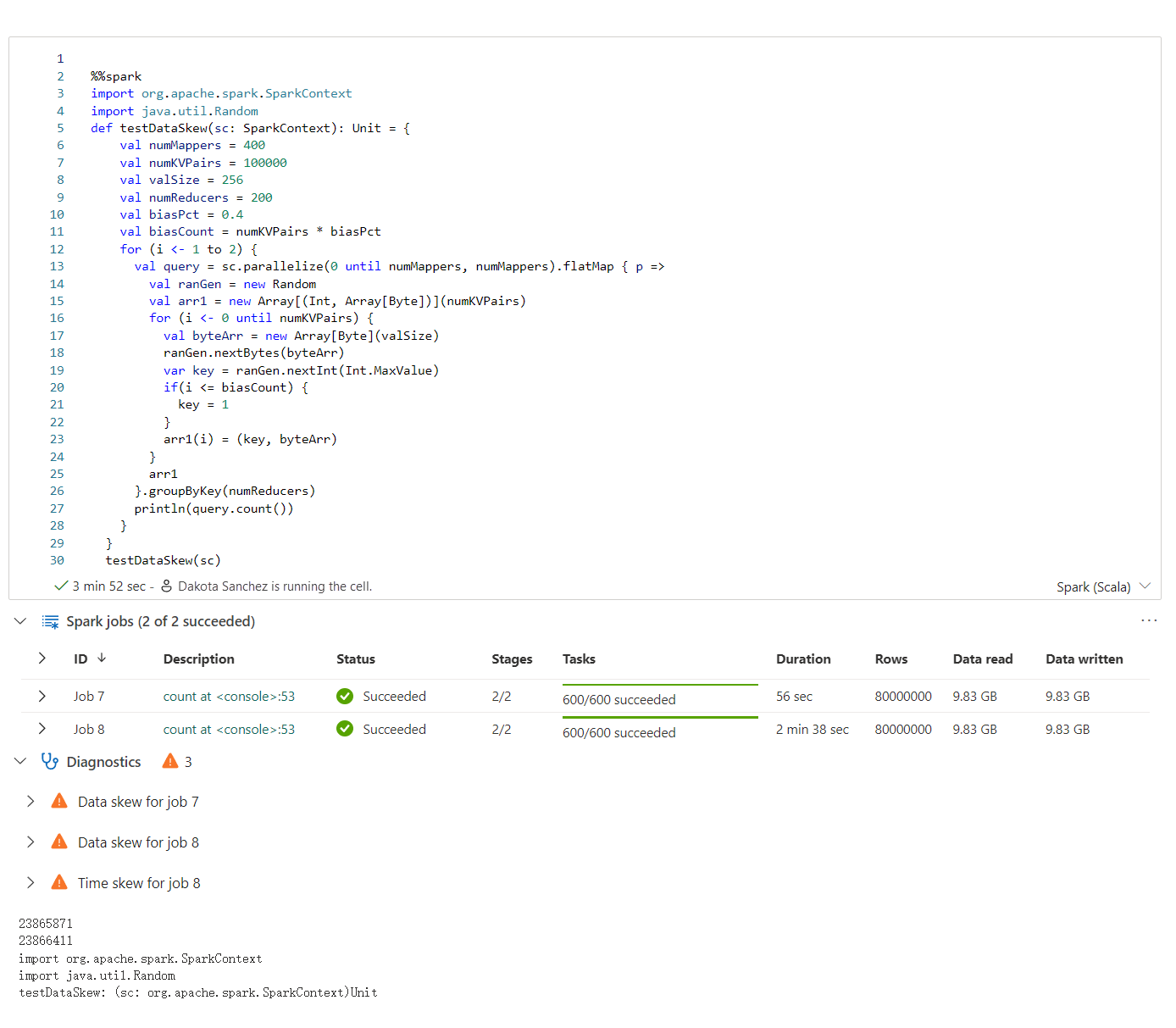
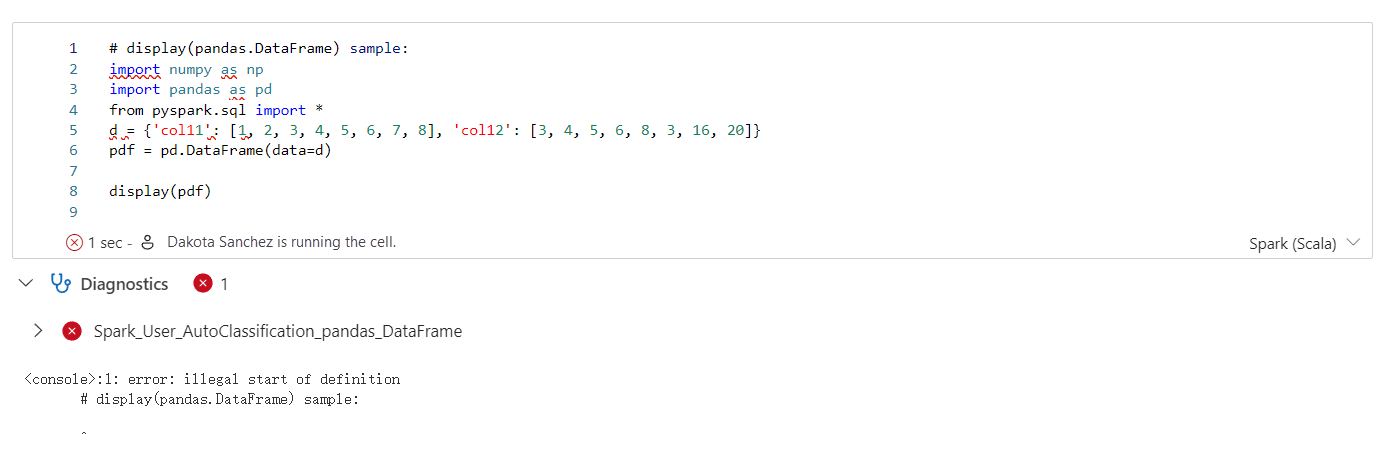
Poradce Pro Apache Spark zobrazí rady, včetně informací, upozornění a chyb, ve výstupu buňky poznámkového bloku v reálném čase.
Info
Upozornění
Chyba
Nastavení Spark Advisoru
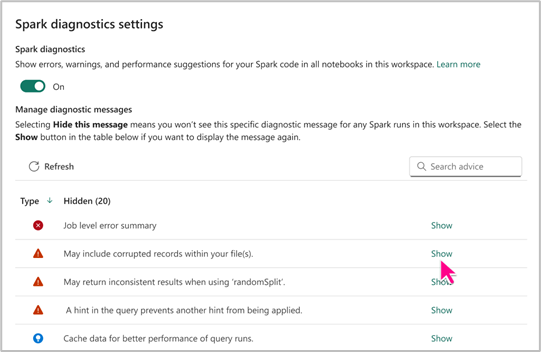
Nastavení Poradce pro Spark umožňuje zvolit, jestli se mají zobrazovat nebo skrýt konkrétní typy rad Sparku podle vašich potřeb. Kromě toho máte možnost povolit nebo zakázat Poradce pro Spark pro poznámkové bloky v pracovním prostoru na základě vašich preferencí.
K nastavení Spark Advisoru můžete přistupovat na úrovni poznámkového bloku Infrastruktury, abyste mohli využívat jeho výhody a zajistit produktivní prostředí pro vytváření poznámkových bloků.
Související obsah
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro