Cíle a spravovaná nastavení toku dat Gen2
Jakmile data vyčistíte a připravíte pomocí Toku dat Gen2, chcete svá data přistála v cíli. Můžete to udělat pomocí možností cíle dat v Toku dat Gen2. Díky této funkci si můžete vybrat z různých cílů, jako je Azure SQL, Fabric Lakehouse a mnoho dalších. Tok dat Gen2 pak zapíše data do cíle a odtud můžete data použít k další analýze a vytváření sestav.
Následující seznam obsahuje podporované cíle dat.
- Databáze Azure SQL
- Azure Data Explorer (Kusto)
- Fabric Lakehouse
- Fabric Warehouse
- Databáze KQL infrastruktury
Vstupní body
Každý datový dotaz ve vašem toku dat Gen2 může mít cíl dat. Funkce a seznamy nejsou podporovány; můžete ho použít jenom na tabulkové dotazy. Můžete zadat cíl dat pro každý dotaz jednotlivě a v rámci toku dat můžete použít několik různých cílů.
Existují tři hlavní vstupní body pro určení cíle dat:
Přes horní pás karet.
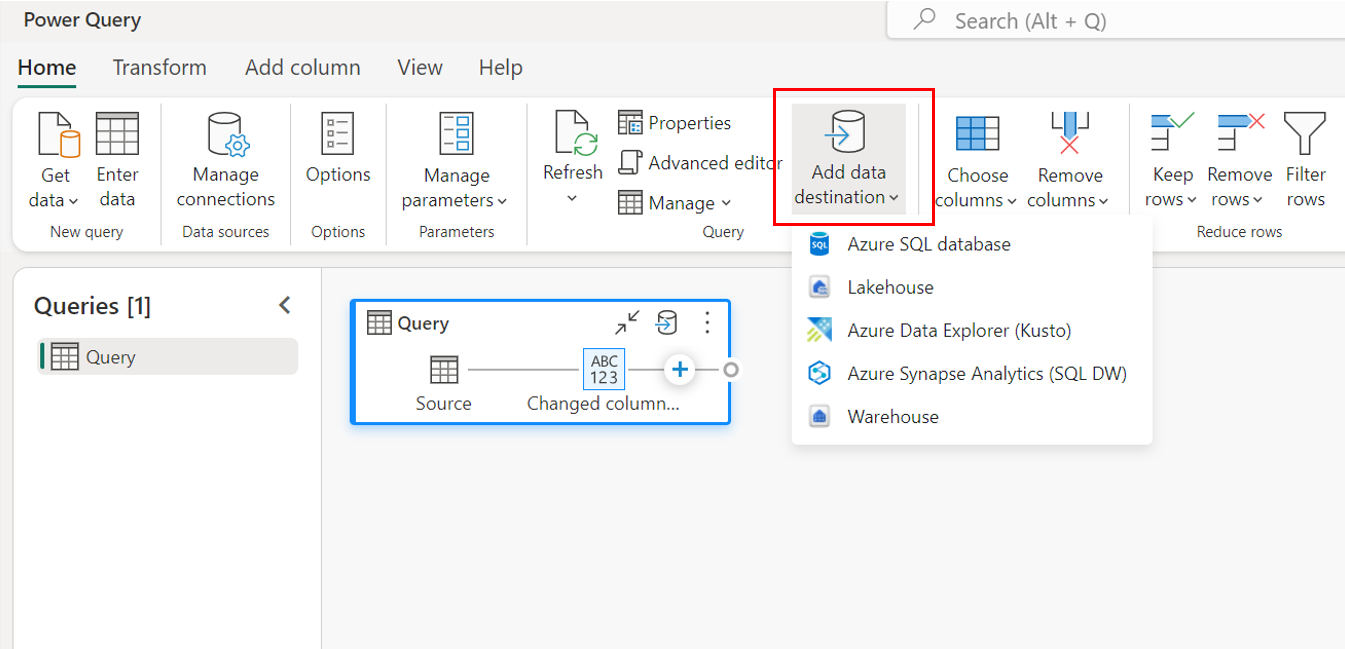
Prostřednictvím nastavení dotazu.
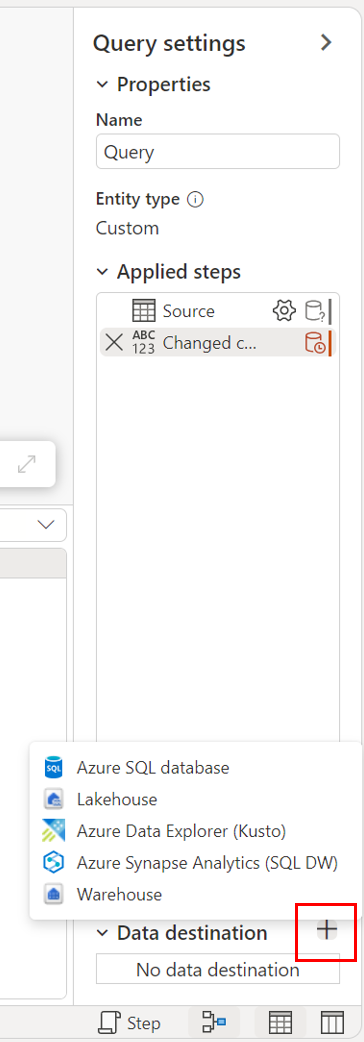
Prostřednictvím zobrazení diagramu.
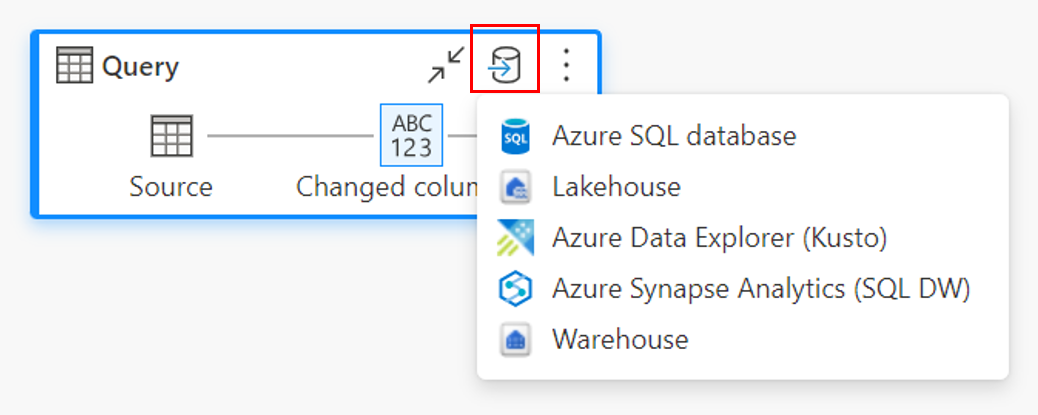
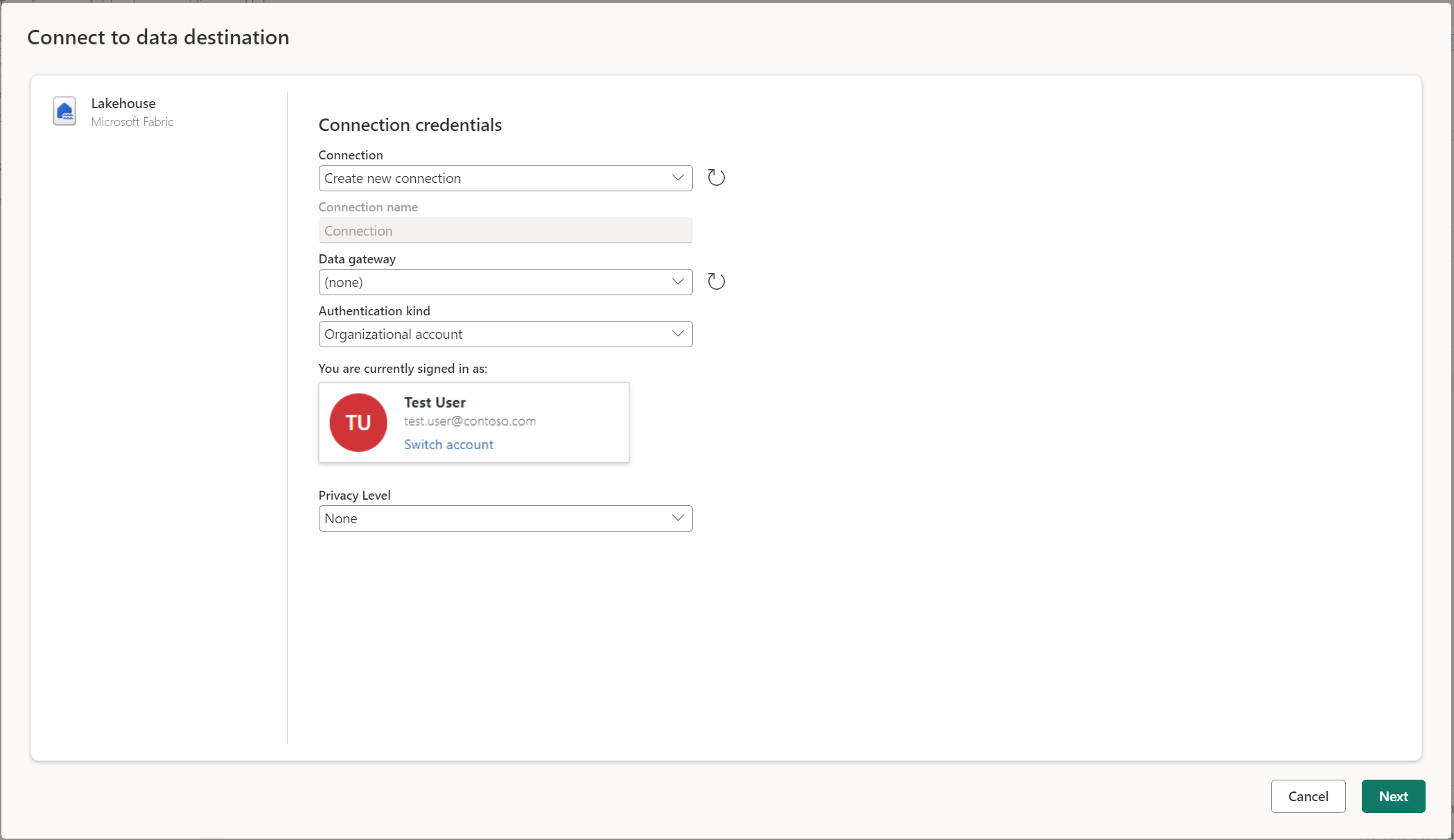
Připojení do cíle dat
Připojení cíl dat se podobá připojení ke zdroji dat. Připojení můžete použít ke čtení i zápisu dat, protože máte správná oprávnění ke zdroji dat. Musíte vytvořit nové připojení nebo vybrat existující připojení a pak vybrat Další.
Vytvoření nové tabulky nebo výběr existující tabulky
Při načítání do cíle dat můžete vytvořit novou tabulku nebo vybrat existující tabulku.
Vytvoření nové tabulky
Když se rozhodnete vytvořit novou tabulku, během aktualizace toku dat Gen2 se v cíli dat vytvoří nová tabulka. Pokud se tabulka odstraní v budoucnu ručním přechodem do cíle, tok dat tabulku během další aktualizace toku dat znovu vytvoří.
Ve výchozím nastavení má název tabulky stejný název jako název dotazu. Pokud v názvu tabulky máte neplatné znaky, které cíl nepodporuje, název tabulky se automaticky upraví. Mnoho cílů například nepodporuje mezery ani speciální znaky.
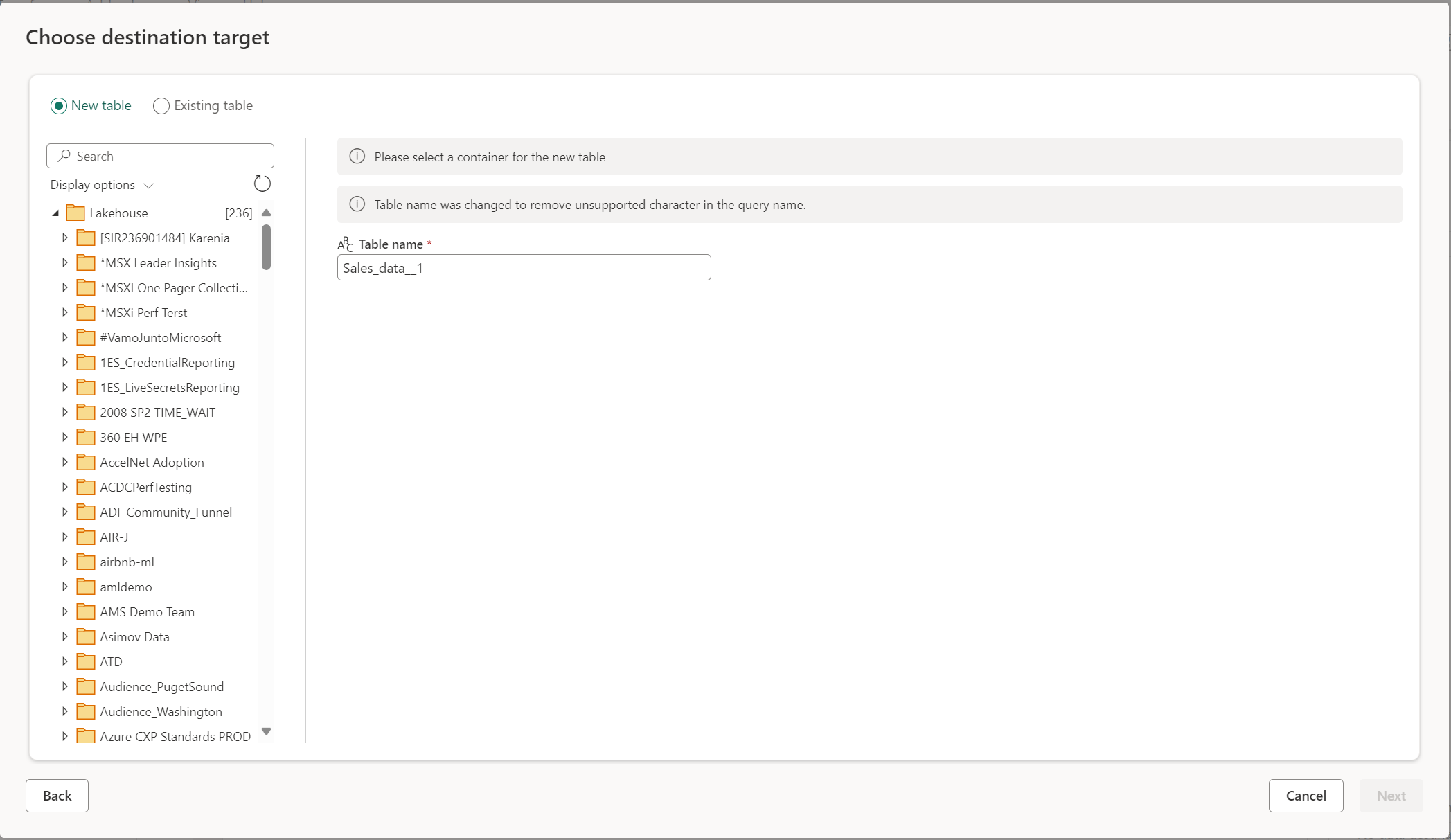
Dále musíte vybrat cílový kontejner. Pokud jste zvolili některý z cílů dat Infrastruktury, můžete pomocí navigátoru vybrat artefakt prostředků infrastruktury, do kterého chcete načíst data. V případě cílů Azure můžete databázi zadat během vytváření připojení nebo vybrat databázi z prostředí navigátoru.
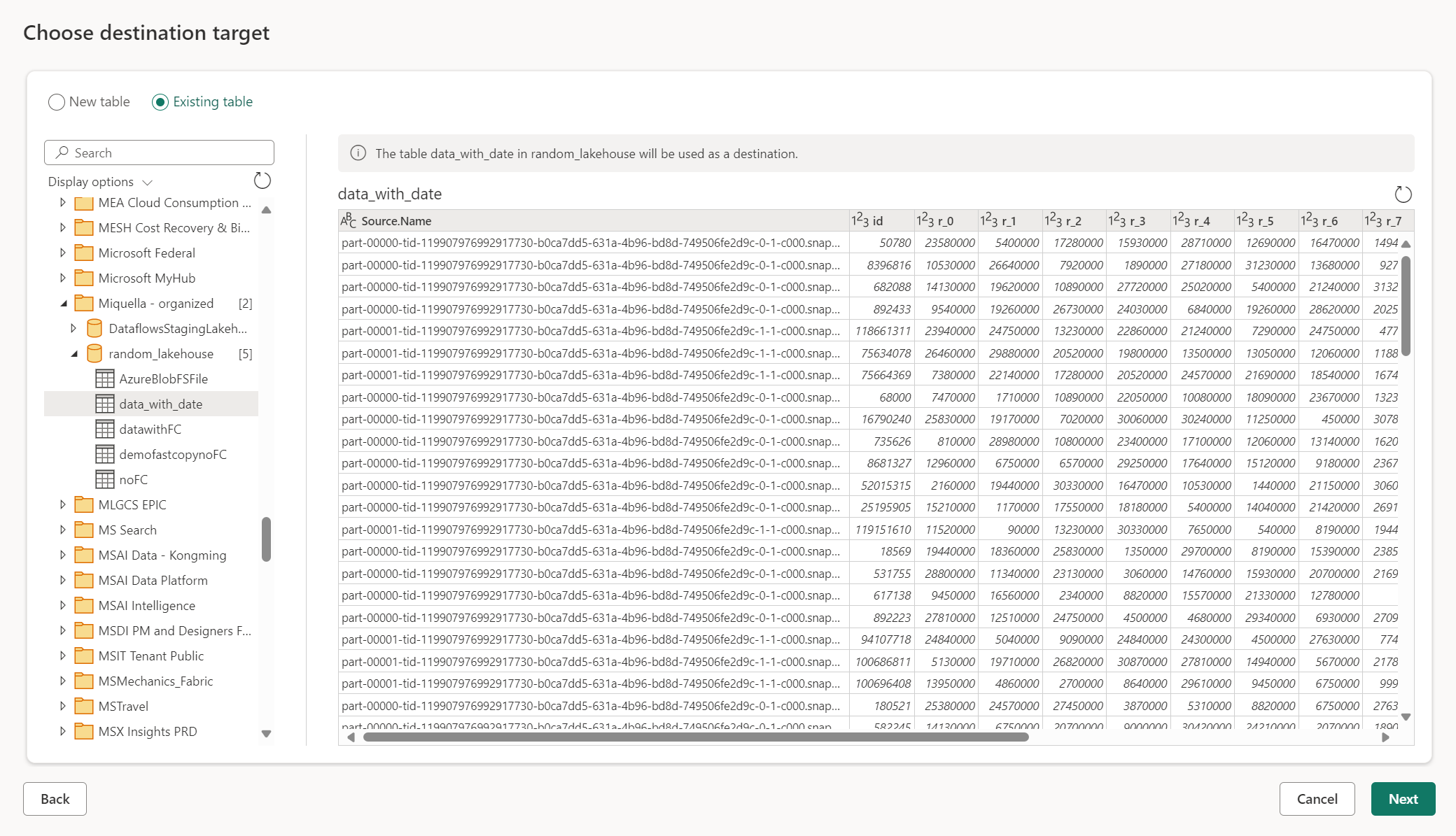
Použití existující tabulky
Pokud chcete zvolit existující tabulku, použijte přepínač v horní části navigátoru. Při výběru existující tabulky musíte pomocí navigátoru vybrat artefakt nebo databázi Prostředků infrastruktury i tabulku.
Pokud používáte existující tabulku, nelze ji v žádném scénáři znovu vytvořit. Pokud tabulku odstraníte ručně z cíle dat, tok dat Gen2 znovu nevytvoření tabulky při příští aktualizaci.
Spravovaná nastavení pro nové tabulky
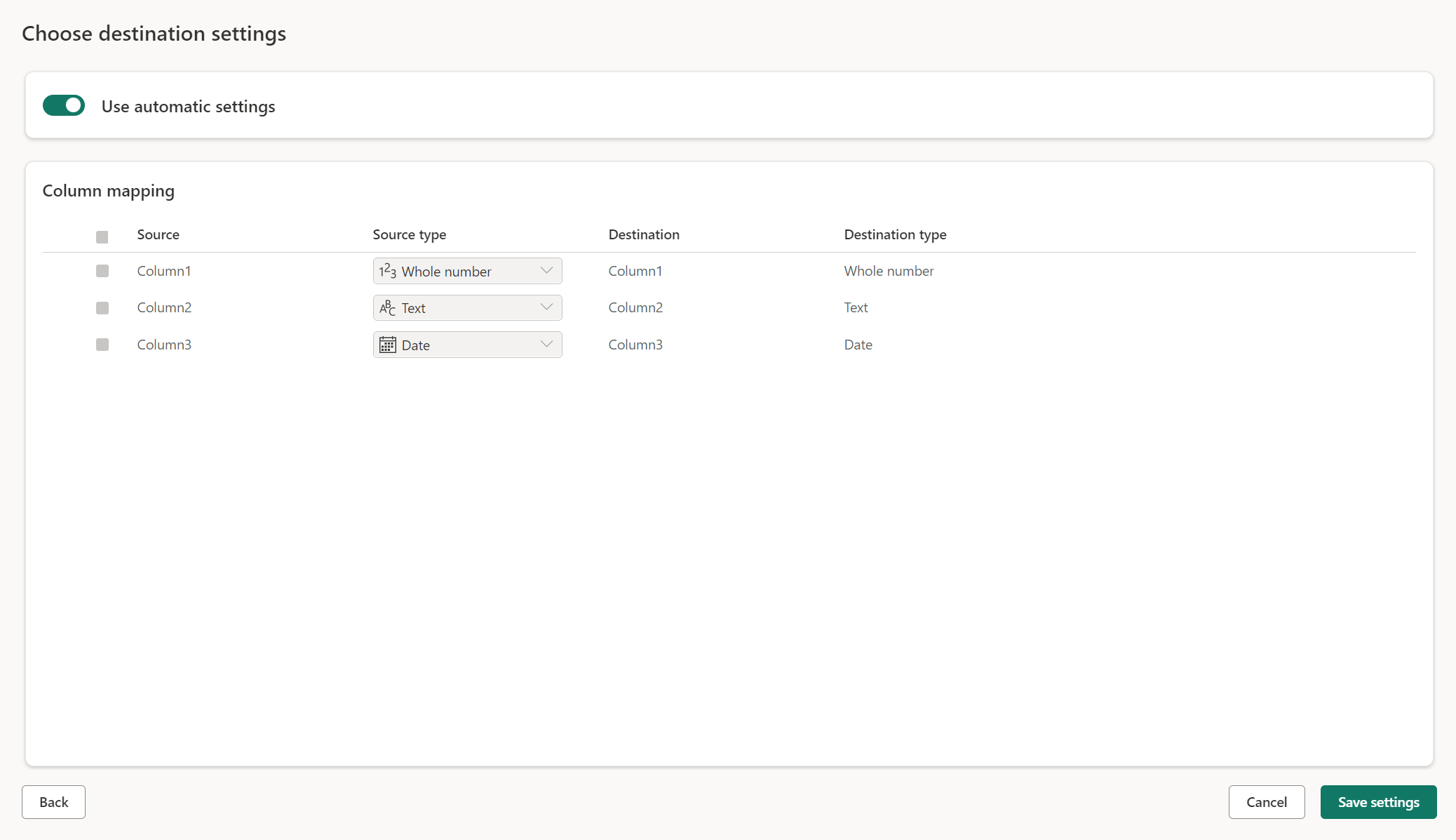
Při načítání do nové tabulky jsou ve výchozím nastavení zapnutá automatická nastavení. Pokud použijete automatické nastavení, dataflow Gen2 spravuje mapování za vás. Automatické nastavení poskytují následující chování:
Nahrazení metody aktualizace: Data se nahradí při každé aktualizaci toku dat. Všechna data v cíli se odeberou. Data v cíli se nahradí výstupními daty toku dat.
Spravované mapování: Mapování se spravuje za vás. Pokud potřebujete v datech nebo dotazu udělat změny, abyste přidali další sloupec nebo změnili datový typ, mapování se automaticky upraví pro tuto změnu při opětovném publikování toku dat. Při každé změně toku dat nemusíte přecházet do cílového prostředí dat, což umožňuje snadné změny schématu při opětovném publikování toku dat.
Přetažení a opětovné vytvoření tabulky: Aby bylo možné tyto změny schématu povolit, při každé aktualizaci toku dat se tabulka zahodí a znovu vytvoří. Aktualizace toku dat může způsobit odebrání relací nebo měr, které byly přidány dříve do tabulky.
Poznámka:
V současné době se automatické nastavení podporuje pouze pro službu Lakehouse a Azure SQL Database jako cíl dat.
Ruční nastavení
Přepnutím možnosti Použít automatické nastavení získáte úplnou kontrolu nad tím, jak načíst data do cíle dat. Jakékoli změny mapování sloupců můžete provést tak, že změníte typ zdroje nebo vyloučíte jakýkoli sloupec, který v cíli dat nepotřebujete.
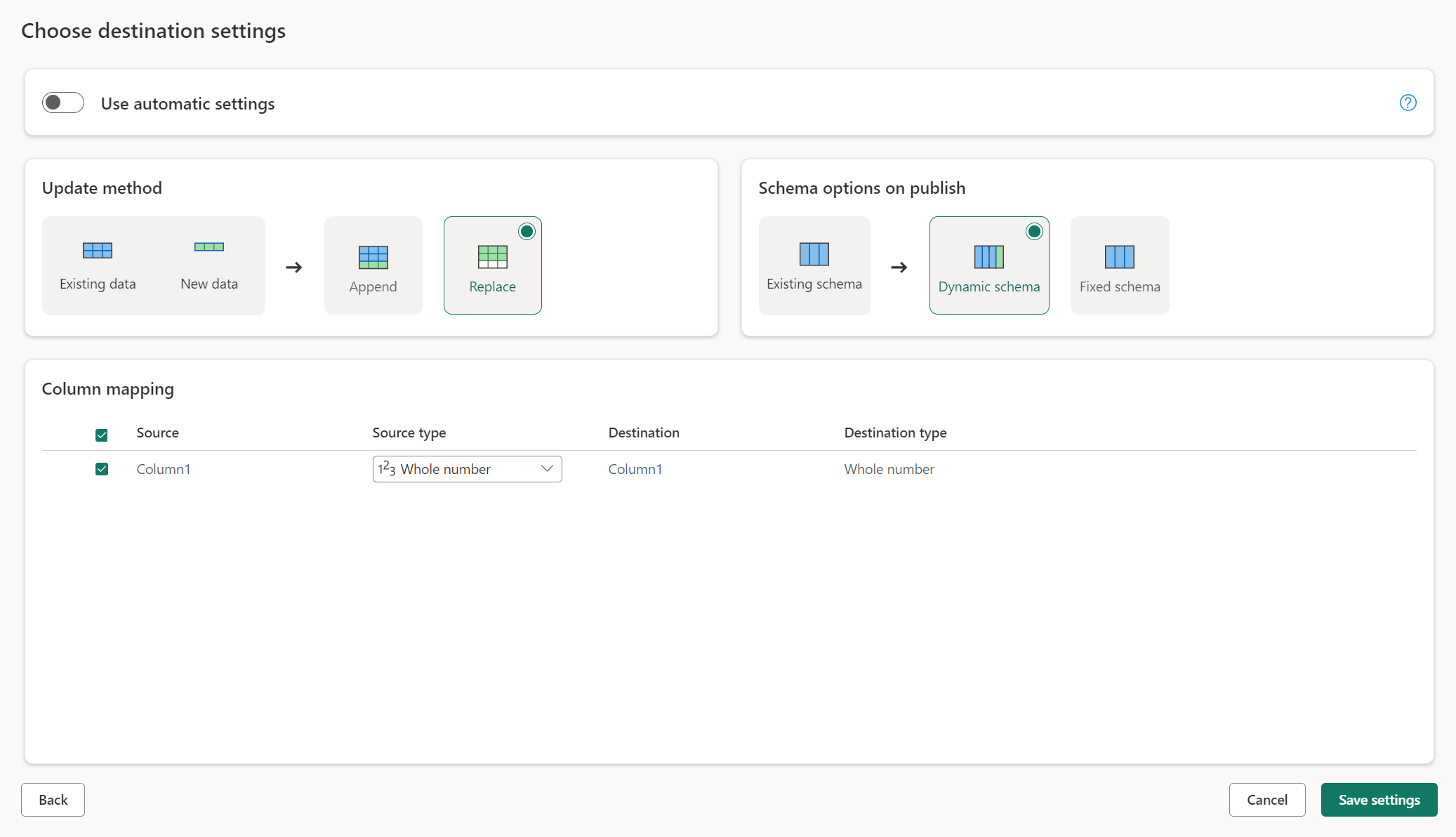
Metody aktualizace
Většina cílů podporuje připojení i nahrazení jako metody aktualizace. Databáze KQL prostředků infrastruktury a Azure Data Explorer však nepodporují nahrazení jako metodu aktualizace.
Nahradit: Při každé aktualizaci toku dat se vaše data zahodí z cíle a nahradí se výstupními daty toku dat.
Připojení: Při každé aktualizaci toku dat se výstupní data z toku dat připojí k existujícím datům v cílové tabulce dat.
Možnosti schématu při publikování
Možnosti schématu při publikování se použijí pouze při nahrazení metody aktualizace. Když připojíte data, změny schématu nejsou možné.
Dynamické schéma: Při výběru dynamického schématu povolíte změny schématu v cíli dat při opětovném publikování toku dat. Vzhledem k tomu, že nepoužíváte spravované mapování, je stále potřeba aktualizovat mapování sloupců v cílovém toku dat, když provedete jakékoli změny dotazu. Po aktualizaci toku dat se tabulka zahodí a znovu vytvoří. Aktualizace toku dat může způsobit odebrání relací nebo měr, které byly přidány dříve do tabulky.
Pevné schéma: Když zvolíte pevné schéma, změny schématu nejsou možné. Když se tok dat aktualizuje, zahodí se jenom řádky v tabulce a nahradí se výstupními daty z toku dat. Všechny relace nebo míry v tabulce zůstanou nedotčené. Pokud v toku dat provedete nějaké změny dotazu, publikování toku dat selže, pokud zjistí, že schéma dotazu neodpovídá cílovému schématu dat. Toto nastavení použijte, pokud neplánujete změnit schéma a mít do cílové tabulky přidané relace nebo míru.
Poznámka:
Při načítání dat do skladu se podporuje pouze pevné schéma.
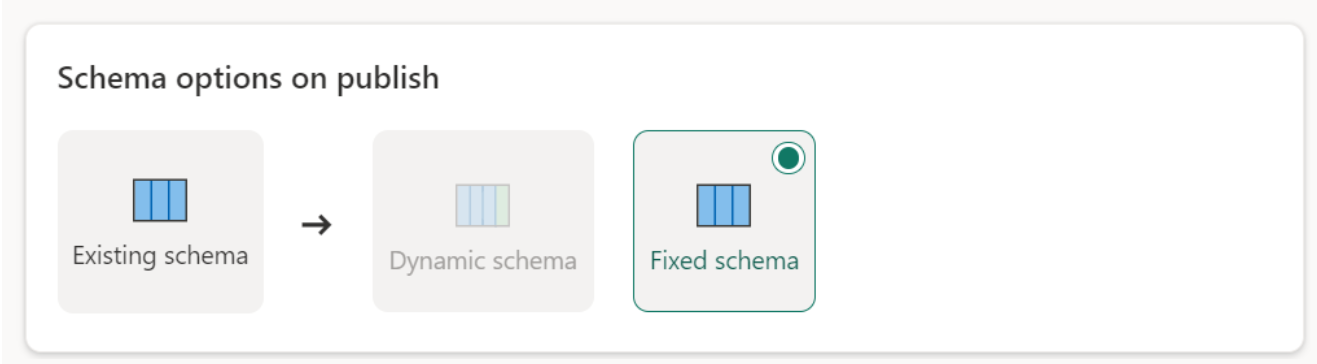
Podporované typy zdrojů dat na cíl
| Podporované datové typy na umístění úložiště | DataflowStagingLakehouse | Výstup služby Azure DB (SQL) | Výstup Azure Data Exploreru | Výstup LH (Fabric Lakehouse) | Výstup služby Fabric Warehouse (WH) |
|---|---|---|---|---|---|
| Akce | No | No | No | No | Ne |
| Všechny | No | No | No | No | Ne |
| Binární | No | No | No | No | Číslo |
| Měna | Ano | Ano | Ano | Ano | No |
| DateTimeZone | Ano | Ano | Ano | No | Ne |
| Duration | No | No | Ano | No | Ne |
| Function | No | No | No | No | Ne |
| Nic | No | No | No | No | Ne |
| Null | No | No | No | No | Ne |
| Čas | Ano | Ano | No | No | Ne |
| Typ | No | No | No | No | Ne |
| Structured (List, Record, Table) | No | No | No | No | Ne |
Pokročilá témata
Použití přípravy před načtením do cíle
Pokud chcete zvýšit výkon zpracování dotazů, můžete ho použít v rámci toků dat Gen2 k použití výpočetních prostředků infrastruktury ke spouštění dotazů.
Pokud je pro dotazy povolená příprava (výchozí chování), data se načtou do přípravného umístění, což je interní objekt Lakehouse přístupný jenom samotným tokem dat.
Použití pracovních umístění může v některých případech zvýšit výkon, kdy posouvání dotazu na koncový bod SQL je rychlejší než při zpracování paměti.
Když načítáte data do lakehouse nebo jiných cílů mimo sklad, ve výchozím nastavení zakážeme přípravnou funkci, aby se zlepšil výkon. Při načítání dat do cíle dat se data zapisuje přímo do cíle dat bez použití přípravy. Pokud chcete pro svůj dotaz použít přípravu, můžete ho znovu povolit.
Pokud chcete povolit přípravu, klikněte pravým tlačítkem myši na dotaz a povolte přípravu výběrem tlačítka Povolit přípravnou přípravu . Dotaz se pak změní na modrou.
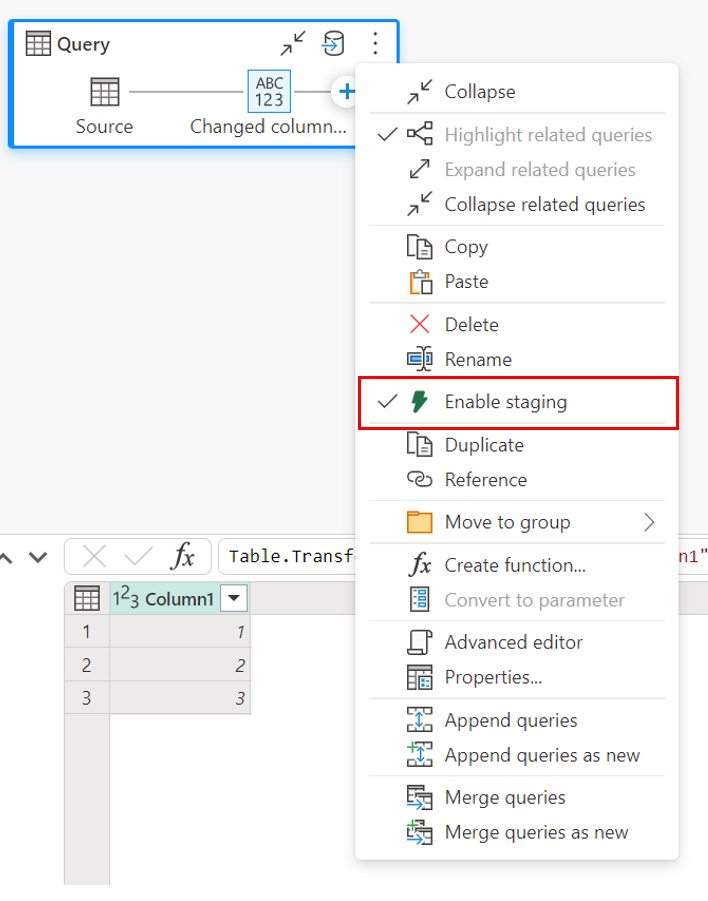
Načtení dat do skladu
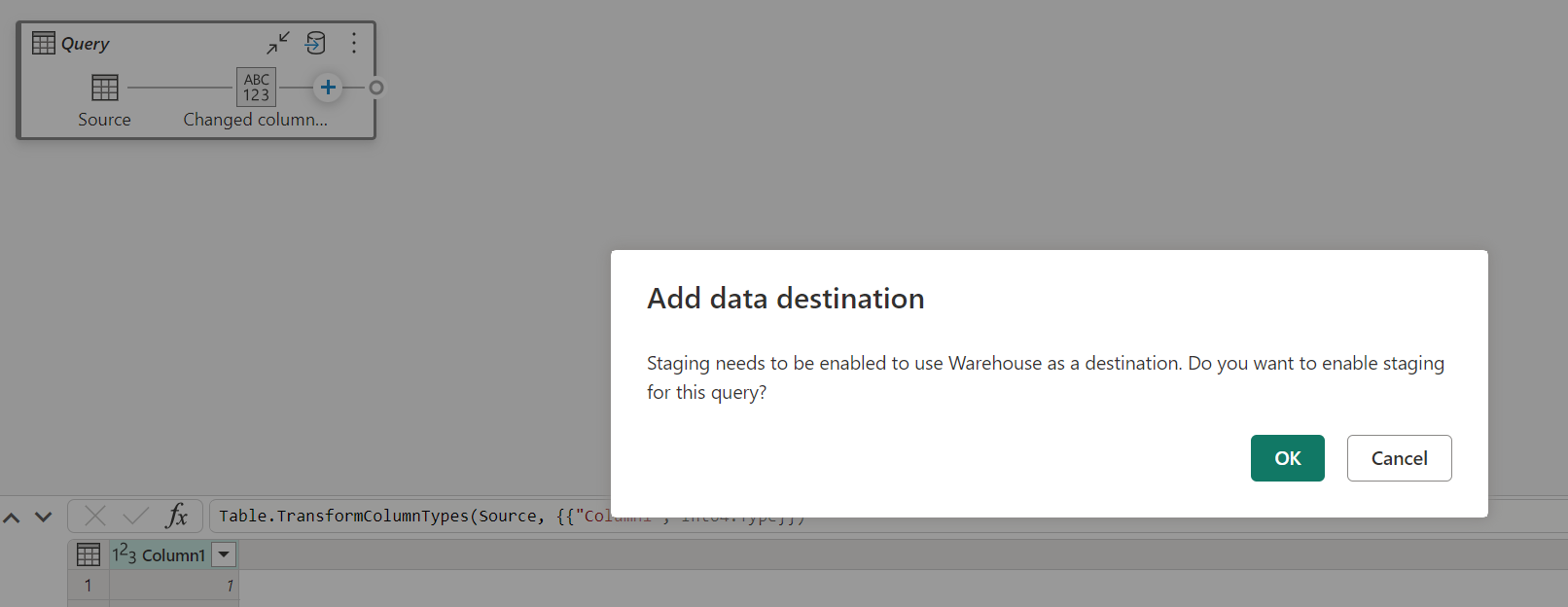
Při načítání dat do skladu se před operací zápisu do cíle dat vyžaduje příprava. Tento požadavek zlepšuje výkon. V současné době se podporuje pouze načítání do stejného pracovního prostoru jako tok dat. Ujistěte se, že je pro všechny dotazy, které se načítají do skladu, povolená příprava.
Když je příprava zakázaná a jako cíl výstupu zvolíte Sklad, zobrazí se upozornění, abyste před konfigurací cíle dat nejprve povolili přípravu.
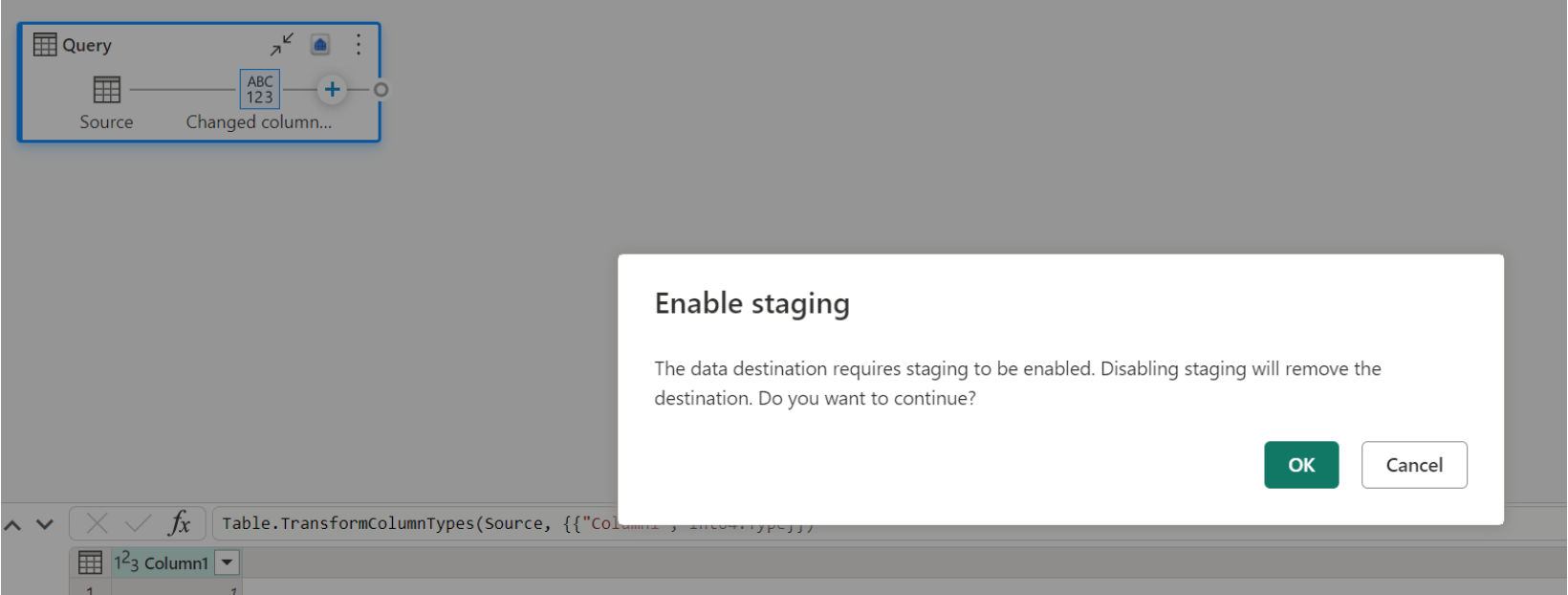
Pokud už máte sklad jako cíl a pokusíte se zakázat přípravu, zobrazí se upozornění. Sklad můžete buď odebrat jako cíl, nebo zavřít přípravnou akci.
Vynulovatelné
V některýchpřípadechchm hodnotám se v některých případech zjistí v Power Query jako nenulový sloupec a při zápisu do cíle dat je typ sloupce nenulový Během aktualizace dojde k následující chybě:
E104100 Couldn’t refresh entity because of an issue with the mashup document MashupException.Error: DataFormat.Error: Error in replacing table’s content with new data in a version: #{0}., InnerException: We can’t insert null data into a non-nullable column., Underlying error: We can’t insert null data into a non-nullable column. Details: Reason = DataFormat.Error;Message = We can’t insert null data into a non-nullable column.; Message.Format = we can’t insert null data into a non-nullable column.
Pokud chcete vynutit, aby byly sloupce s možnou hodnotou null, můžete vyzkoušet následující kroky:
Odstraňte tabulku z cíle dat.
Odeberte cíl dat z toku dat.
Přejděte do toku dat a aktualizujte datové typy pomocí následujícího kódu Power Query:
Table.TransformColumnTypes( #"PREVIOUS STEP", { {"COLLUMNNAME1", type nullable text}, {"COLLUMNNAME2", type nullable Int64.Type} } )Přidejte cíl dat.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro