Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
V tomto článku se dozvíte, jak provádět průzkumnou analýzu dat pomocí Azure Open Datasets a Apache Sparku. Tento článek analyzuje datovou sadu taxislužby v New Yorku. Data jsou k dispozici prostřednictvím Azure Open Datasets. Tato podmnožina datové sady obsahuje informace o žlutých jízdách taxíkem: informace o každé jízdě, počátečním a koncovém čase a umístění, nákladech a dalších zajímavých atributech.
V tomto článku:
- Stažení a příprava dat
- Analýza dat
- Vizualizace dat
Požadavky
Získejte předplatné Microsoft Fabric. Nebo si zaregistrujte bezplatnou zkušební verzi Microsoft Fabricu.
Přihlaste se k Microsoft Fabric.
Použijte přepínač prostředí v levém dolním rohu domovské stránky pro přepnutí na Fabric.

Stažení a příprava dat
Začněte tím, že si stáhnete datovou sadu taxislužby New Yorku (NYC) a připravíte data.
Vytvořte poznámkový blok pomocí PySparku. Pokyny najdete v tématu Vytvoření poznámkového bloku.
Poznámka:
Kvůli jádru PySpark nemusíte explicitně vytvářet žádné kontexty. Kontext Sparku se automaticky vytvoří za vás při spuštění první buňky kódu.
V tomto článku použijete několik různých knihoven, které vám pomůžou vizualizovat datovou sadu. Pokud chcete tuto analýzu provést, naimportujte následující knihovny:
import matplotlib.pyplot as plt import seaborn as sns import pandas as pdVzhledem k tomu, že nezpracovaná data jsou ve formátu Parquet, můžete použít kontext Sparku k přímému načtení souboru do paměti jako datového rámce. K načtení dat a vytvoření datového rámce Spark použijte rozhraní API Open Datasets. K odvození datových typů a schématu použijte schéma datového rámce Sparku pro vlastnosti čtení .
from azureml.opendatasets import NycTlcYellow end_date = parser.parse('2018-06-06') start_date = parser.parse('2018-05-01') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) nyc_tlc_pd = nyc_tlc.to_pandas_dataframe() df = spark.createDataFrame(nyc_tlc_pd)Po přečtení dat proveďte počáteční filtrování, abyste datovou sadu vyčistili. Nepotřebné sloupce můžete odebrat a přidat sloupce, které extrahují důležité informace. Kromě toho můžete vyfiltrovat anomálie v datové sadě.
# Filter the dataset from pyspark.sql.functions import * filtered_df = df.select('vendorID', 'passengerCount', 'tripDistance','paymentType', 'fareAmount', 'tipAmount'\ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , dayofweek('tpepPickupDateTime').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month'))\ .filter((df.passengerCount > 0)\ & (df.tipAmount >= 0)\ & (df.fareAmount >= 1) & (df.fareAmount <= 250)\ & (df.tripDistance > 0) & (df.tripDistance <= 200)) filtered_df.createOrReplaceTempView("taxi_dataset")
Analýza dat
Jako datový analytik máte k dispozici širokou škálu nástrojů, které vám pomůžou extrahovat přehledy z dat. V této části článku se dozvíte o několika užitečných nástrojích dostupných v poznámkových blocích Microsoft Fabric. V této analýze chcete pochopit faktory, které poskytují vyšší tipy taxi pro vybrané období.
Apache Spark SQL Magic
Nejprve proveďte průzkumnou analýzu dat pomocí Apache Spark SQL a příkazů magic s poznámkovým blokem Microsoft Fabric. Jakmile budete mít dotaz, vizualizujte výsledky pomocí integrované chart options funkce.
V poznámkovém bloku vytvořte novou buňku a zkopírujte následující kód. Pomocí tohoto dotazu můžete pochopit, jak se průměrné částky tipu v průběhu vybraného období mění. Tento dotaz vám také pomůže identifikovat další užitečné přehledy, včetně minimální/maximální částky tipu za den a průměrného množství jízdného.
%%sql SELECT day_of_month , MIN(tipAmount) AS minTipAmount , MAX(tipAmount) AS maxTipAmount , AVG(tipAmount) AS avgTipAmount , AVG(fareAmount) as fareAmount FROM taxi_dataset GROUP BY day_of_month ORDER BY day_of_month ASCPo dokončení dotazu můžete výsledky vizualizovat přepnutím do zobrazení grafu. Tento příklad vytvoří spojnicový graf zadáním
day_of_monthpole jako klíče aavgTipAmounthodnoty. Po provedení výběru vyberte Použít a aktualizujte graf.
Vizualizace dat
Kromě předdefinovaných možností vytváření grafů v poznámkových blocích můžete k vytváření vlastních vizualizací použít oblíbené opensourcové knihovny. V následujících příkladech použijte Knihovny Seaborn a Matplotlib, které se běžně používají pro vizualizaci dat v Pythonu.
Aby byl vývoj jednodušší a levnější, převzorkujte datovou sadu. Použijte integrovanou funkci vzorkování Apache Sparku. Kromě toho vyžaduje Knihovna Seaborn i Matplotlib datový rámec Pandas nebo pole NumPy. K získání datového rámce Pandas použijte
toPandas()příkaz k převodu datového rámce.# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) # The charting package needs a Pandas DataFrame or NumPy array to do the conversion sampled_taxi_pd_df = sampled_taxi_df.toPandas()Můžete pochopit distribuci tipů v datové sadě. Pomocí knihovny Matplotlib vytvořte histogram, který zobrazuje rozdělení množství tipu a počtu. V závislosti na distribuci vidíte, že tipy se zkosí směrem k částekm nižším nebo rovnou 10 USD.
# Look at a histogram of tips by count by using Matplotlib ax1 = sampled_taxi_pd_df['tipAmount'].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show()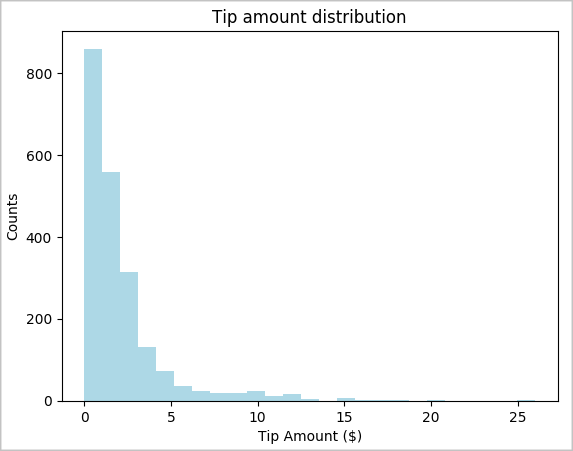
Dále se pokuste pochopit vztah mezi tipy pro danou cestu a dnem v týdnu. Pomocí Seabornu vytvořte krabicový graf, který shrnuje trendy pro každý den v týdnu.
# View the distribution of tips by day of week using Seaborn ax = sns.boxplot(x="day_of_week", y="tipAmount",data=sampled_taxi_pd_df, showfliers = False) ax.set_title('Tip amount distribution per day') ax.set_xlabel('Day of Week') ax.set_ylabel('Tip Amount ($)') plt.show()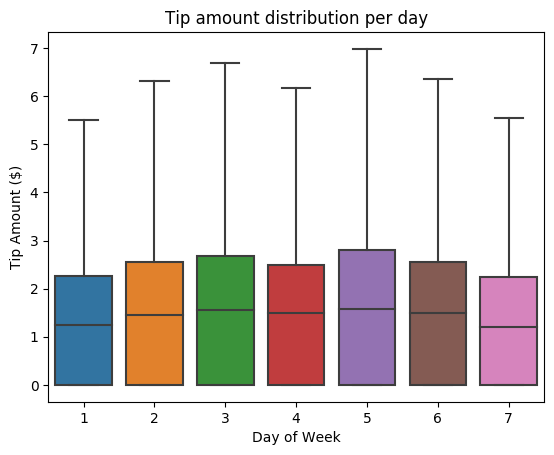
Další hypotézou může být, že existuje kladný vztah mezi počtem cestujících a celkovou částkou tipu taxislužby. Pokud chcete ověřit tuto relaci, spusťte následující kód a vygenerujte krabicový graf, který znázorňuje rozdělení tipů pro každý počet cestujících.
# How many passengers tipped by various amounts ax2 = sampled_taxi_pd_df.boxplot(column=['tipAmount'], by=['passengerCount']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') ax2.set_ylim(0,30) plt.suptitle('') plt.show()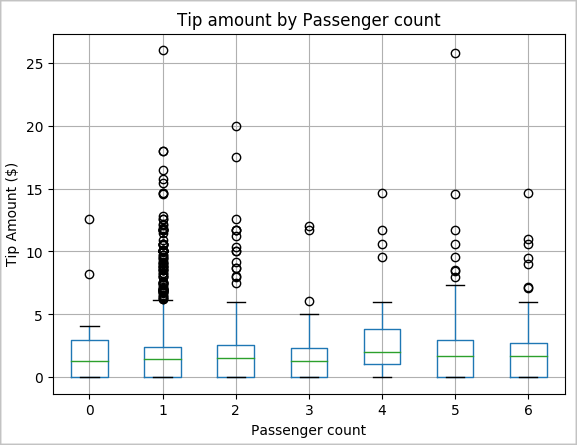
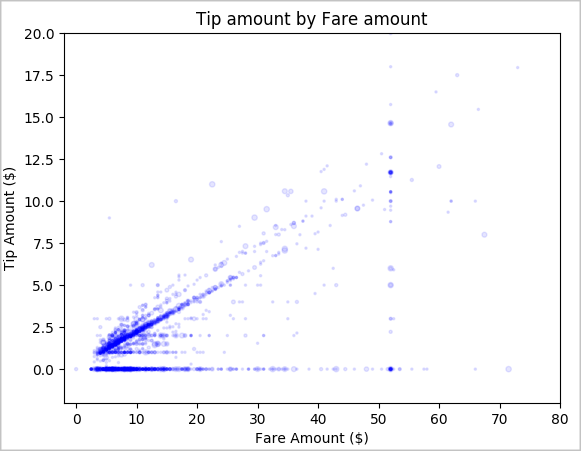
Nakonec prozkoumejte vztah mezi částkou jízdného a částkou tipu. Na základě výsledků můžete vidět, že existuje několik pozorování, kde lidé ne tipují. Existuje však kladný vztah mezi celkovým množstvím jízdného a tipem.
# Look at the relationship between fare and tip amounts ax = sampled_taxi_pd_df.plot(kind='scatter', x= 'fareAmount', y = 'tipAmount', c='blue', alpha = 0.10, s=2.5*(sampled_taxi_pd_df['passengerCount'])) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.suptitle('') plt.show()