Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
platí pro:✅ Warehouse v Microsoft Fabric
Tento článek popisuje funkce a inovace v architektuře datového skladu Fabric, které zlepšují výkon, škálovatelnost a nákladovou efektivitu.
Datový sklad Fabric běží na architektuře připravené pro budoucnost v sblížené datové platformě. S otevřeným formátem úložiště Delta a integrací OneLake jsou vaše data ve službě Fabric Data Warehouse připravená k analýze.
Architektura vysoké úrovně

Datový sklad Fabric je účelově vytvořený pro analýzy ve velkém měřítku s následujícími stavebními bloky:
| Stavební blok | Description |
|---|---|
| Optimalizátor sjednocených dotazů | Generuje optimální plán spouštění pro distribuovaná cloudová prostředí bez ohledu na kvalitu dotazů SQL vytvořených uživatelem. |
| Distribuované zpracování dotazů | Podporuje masivní paralelní spouštění dotazů s rychlou cloudovou infrastrukturou automatického škálování a okamžitě poskytuje potřebné výpočetní prostředky pro dotazy. Samostatné úlohy SELECT a DML používají k efektivnímu a izolovanému provádění odlišné fondy. |
| Modul spouštění dotazů | Modul založený na SQL pro spouštění analytických dotazů na velké množství dat s rychlým výkonem a vysokou souběžností. |
| Metadata a správa transakcí | Metadata se nacházejí ve front-endu, back-endu a v místní mezipaměti SSD i vzdáleném úložišti OneLake. Podporuje souběžné transakce a zajišťuje dodržování předpisů ACID. |
| Úložiště ve OneLake | Strukturované tabulky protokolu implementované pomocí otevřeného formátu tabulky Delta, modelu lakehouse se zabezpečeným otevřeným úložištěm. |
| Platforma Fabric | Platforma Fabric poskytuje jednotný model ověřování a zabezpečení, monitorování a auditování. Datový sklad Fabric je automaticky dostupný pro další služby platformy Fabric, které vyhovují obchodním potřebám, včetně Power BI, datových kanálů ve službě Data Factory, Real-Time Intelligence a dalších. |
Modul pro optimalizaci sjednocených dotazů
Unified query optimizer in Fabric Data Warehouse je modul, který rozhoduje o nejchytřejším způsobu spouštění dotazů SQL.
Když odešlete dotaz, sjednocený optimalizátor dotazů se podívá na možné způsoby jeho spuštění: jak spojit tabulky, kam přesunout data a jak používat prostředky, jako je procesor, paměť a síť. Sjednocený optimalizátor dotazů nevybírá jenom první možnost, ale v době povolené vyhodnocením nákladů napříč těmito faktory a dostupnými metadaty a statistikami zvolí optimální plán.
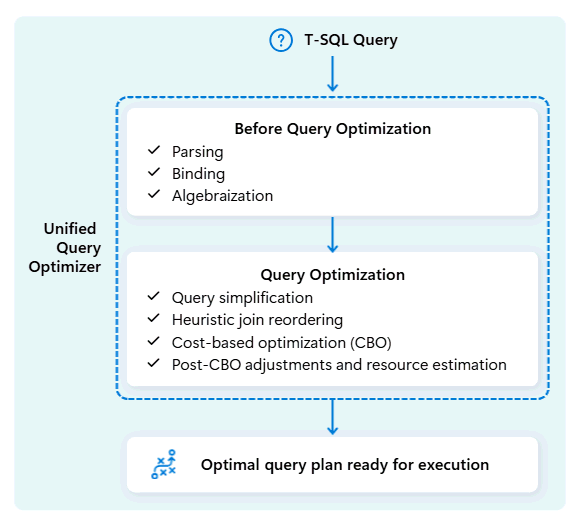
Při optimalizaci plánu provádění dotazu považuje jednotný optimalizátor dotazů vše na jednom místě: tvar dotazu, distribuci dat tabulek a náklady na přesun dat vs. zpracování místně. Jednotný optimalizátor dotazů může vytvářet inteligentní kompromisy, jako je rozhodování, jestli je vysílání malé tabulky levnější než prohazování velké tabulky. To znamená méně zbytečných náhodného prohazování dat, lepší využití výpočetních prostředků a rychlejší výkon, a to i pro složité nebo špatně napsané dotazy T-SQL.
Konzistentní výkon nevyžaduje, aby vývojáři strávili čas ručním laděním dotazů T-SQL. Například nemusíte ručně určit nejlepší JOIN pořadí v dotazech. Pokud váš SQL vypíše nejprve velkou tabulku a jako druhou menší, vysoce selektivní tabulku dat, může optimalizátor automaticky přepínat jejich pozice pro lepší výkon. Použije menší tabulku jako výchozí bod pro porovnávání řádků (tzv. "build side") a větší tabulku jako tu, kterou je potřeba prohledat (tzv. "probe side", kontroluje shody). Tento přístup minimalizuje využití paměti, snižuje přesun dat a zlepšuje paralelismus a současně poskytuje přesné výsledky.
Sjednocený optimalizátor dotazů se průběžně učí z minulých spuštění dotazů při vývoji úloh a upřesňuje svůj optimalizační algoritmus tak, aby poskytoval co nejlepší možný výkon. Uživatelé mohou využívat rychlé spouštění dotazů automaticky bez ohledu na složitost a bez nutnosti zásahu.
Modul pro distribuované zpracování dotazů
Ve službě Fabric Data Warehouse modul pro zpracování distribuovaných dotazů přiděluje výpočetní prostředky úkolům v plánech dotazů. Distribuovaný modul pro zpracování dotazů může plánovat úlohy napříč výpočetními uzly, takže každý uzel spouští část plánu dotazu a umožňuje paralelní spouštění pro rychlejší výkon. Složité výkazy velkých datových sad můžou těžit z distribuovaného zpracování dotazů.
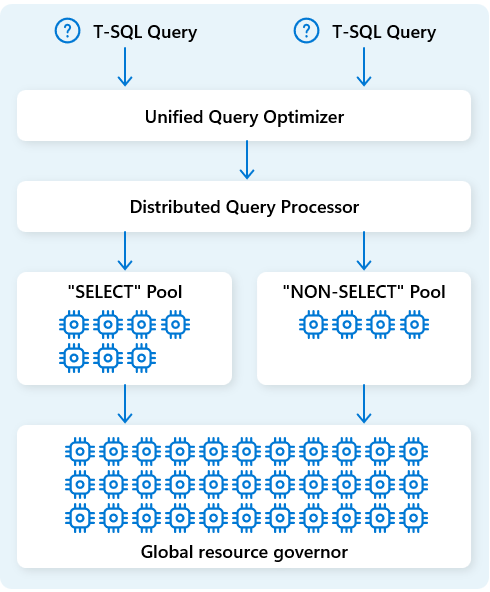
Aby bylo možné dále optimalizovat prostředky, distribuovaný modul pro zpracování dotazů odděluje výpočetní prostředky do dvou fondů: pro SELECT dotazy a úlohy příjmu dat (NON-SELECT dotazy). Každá úloha podle potřeby přijímá vyhrazené prostředky. Například to znamená, že vaše noční ETL procesy nezpozdí ranní řídicí panely.
Díky rychlému zřizování uzlů v cloudu modul pro zpracování distribuovaných dotazů automaticky škáluje výpočetní prostředky nahoru nebo dolů v reakci na změny objemu dotazů, velikosti dat a složitosti dotazů. Datový sklad Fabric má možnosti paralelního zpracování pro malé datové sady nebo data ve velkém měřítku s více petabajty.
Modul spouštění dotazů
Prováděcí modul dotazů je proces, který spouští části distribuovaného plánu provádění, které jsou přiřazeny jednotlivým výpočetním uzlům. Modul spouštění dotazů je založený na stejném modulu, který používá SQL Server a Azure SQL Database k použití dávkového režimu spouštění a sloupcových datových formátů pro efektivní analýzu velkých objemů dat za optimálních nákladů.
Spouštěcí modul dotazů čte data přímo ze souborů Delta Parquet uložených v Fabric OneLake a využívá několik vrstev ukládání do mezipaměti (paměť a SSD) ke zrychlení výkonu dotazů a zajištění optimální rychlosti provádění dotazů. Modul spouštění dotazů zpracovává data v paměti a v případě potřeby načte další data z mezipaměti SSD nebo úložiště OneLake.
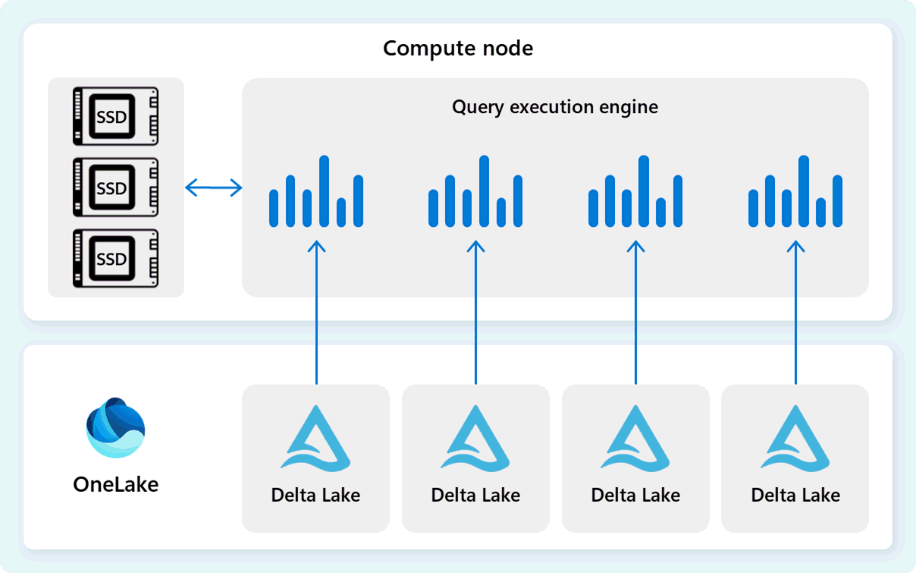
Při zpracování dat provádí modul spouštění dotazů odstranění skupin sloupců a řádků a přeskočí segmenty, které nejsou pro dotaz relevantní. Tato optimalizace snižuje množství dat kontrolovaných ze souborů a mezipaměti paměti, což pomáhá minimalizovat využití prostředků a zlepšit celkovou dobu provádění.
Prováděcí modul dotazů exceluje při filtrování a agregaci miliard řádků a podporuje obecné vzorce analýzy dat používané v moderních řešeních datového skladu. Provádění dávkového režimu využívá moderní schopnost procesoru zpracovávat více řádků paralelně, čímž výrazně snižuje režii a zajišťuje, že dotazy běží až stonásobně rychleji než při tradičním spouštění řádek po řádku.
Metadata a správa transakcí
Modul skladu používá metadata k popisu schématu tabulky, organizace souborů, historie verzí a transakčních stavů. Tato metadata umožňují modulu skladu efektivně spravovat a dotazovat data. Datový sklad Fabric nabízí robustní a komplexní architekturu správy metadat a transakcí, která rozšiřuje správce transakcí OLTP, aby orchestruje vysoce souběžné operace metadat a zajišťuje dodržování předpisů ACID.
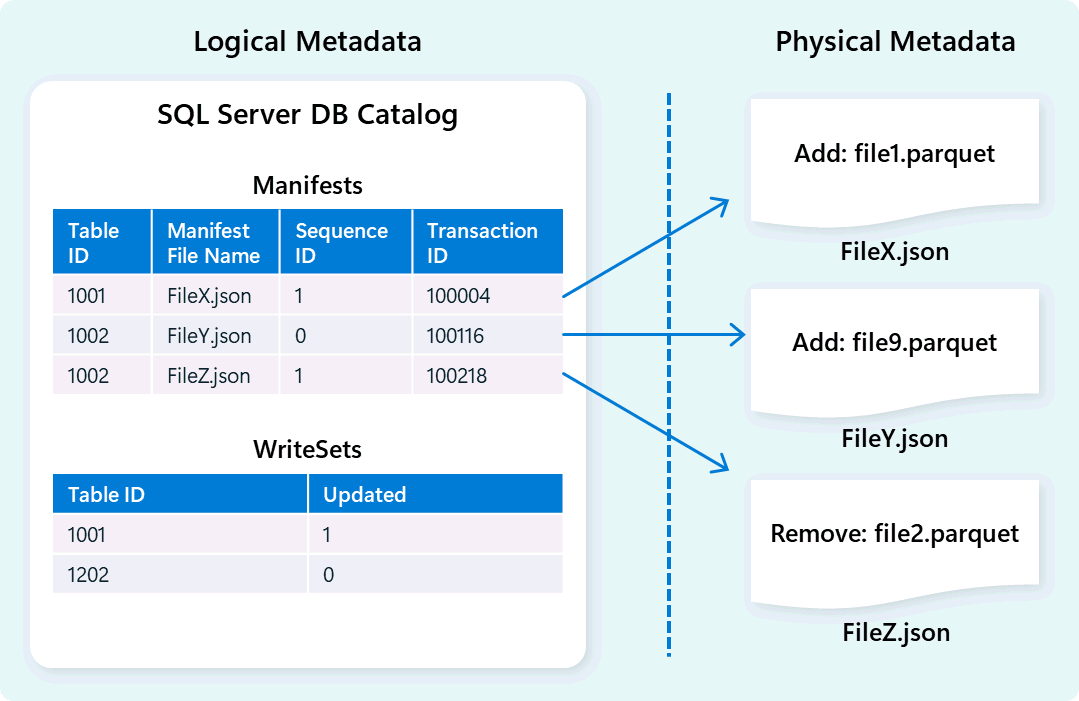
Tento návrh umožňuje rychlou a spolehlivou navigaci transakčních stavů a podporuje úlohy s vysokou souběžností a zároveň zajišťuje konzistenci.
Úložiště a příjem dat
Datový sklad Fabric používá architekturu lakehouse s opensourcovým formátem Delta pro škálovatelné, zabezpečené a vysoce výkonné úložiště. Formát tabulky Delta podporuje správu verzí dat a umožňuje okamžitý přístup k historickým snímkům prostřednictvím časového cestování a klonování bez kopírování pro bezpečné operace testování a vrácení zpět. Uživatelská data se ukládají v rámci OneLake a umožňují všem modulům Fabric efektivní přístup ke sdíleným datům bez redundance.
Služba Fabric Data Warehouse je navržená tak, aby poskytovala optimální výkon příjmu dat se zaměřením na jednoduchost a flexibilitu. Systém efektivně spravuje úložiště dat tabulky prostřednictvím automatického zhušťování dat, které konsoliduje fragmentované soubory na pozadí, aby se omezilo zbytečné skenování dat. Jeho inteligentní metoda distribuce dat rozdělí a uspořádá data do mikrodělených buněk, aby se zvýšilo paralelní zpracování a zvýšilo výsledky dotazů. Tyto funkce fungují samostatně, aniž by bylo nutné provádět ruční úpravy.