Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Data replikovaná z zrcadlené databáze můžete prozkoumat pomocí dotazů Sparku v poznámkových blocích.
Poznámkové bloky jsou výkonnou položkou kódu pro vývoj úloh Apache Sparku a experimentů strojového učení na vašich datech. Poznámkové bloky v Fabric Lakehouse můžete použít k prozkoumání zrcadlených tabulek.
Požadavky
- Dokončete kurz a vytvořte zrcadlenou databázi ze zdrojové databáze.
- Kurz: Konfigurace zrcadlené databáze Microsoft Fabric pro Azure Cosmos DB
- Kurz: Konfigurace zrcadlených databází Microsoft Fabric z Azure Databricks
- Kurz: Konfigurace zrcadlených databází Microsoft Fabric ze služby Azure SQL Database
- Kurz: Konfigurace zrcadlených databází Microsoft Fabric ze spravované instance Azure SQL
- Kurz: Konfigurace zrcadlených databází Microsoft Fabric ze Snowflake
- Kurz: Konfigurace zrcadlených databází Microsoft Fabric z SQL Serveru
- Kurz: Vytvoření otevřené zrcadlené databáze
Vytvoření zástupce
Nejdřív musíte vytvořit zástupce ze zrcadlených tabulek do Lakehouse a pak vytvořit poznámkové bloky s dotazy Sparku ve vašem Lakehouse.
Na portálu Fabric otevřete přípravu dat.
Pokud ještě nemáte vytvořený Lakehouse, vyberte Lakehouse a vytvořte nový Lakehouse tak, že ho pojmenujete.
Vyberte Načíst data –>nová klávesová zkratka.
Vyberte Microsoft OneLake.
Všechny zrcadlené databáze můžete zobrazit v pracovním prostoru Prostředky infrastruktury.
Vyberte zrcadlenou databázi, kterou chcete přidat do lakehouse, jako zástupce.
Vyberte požadované tabulky ze zrcadlené databáze.
Vyberte Další a pak Vytvořte.
V Průzkumníku teď můžete ve svém Lakehouse zobrazit vybraná data tabulky.
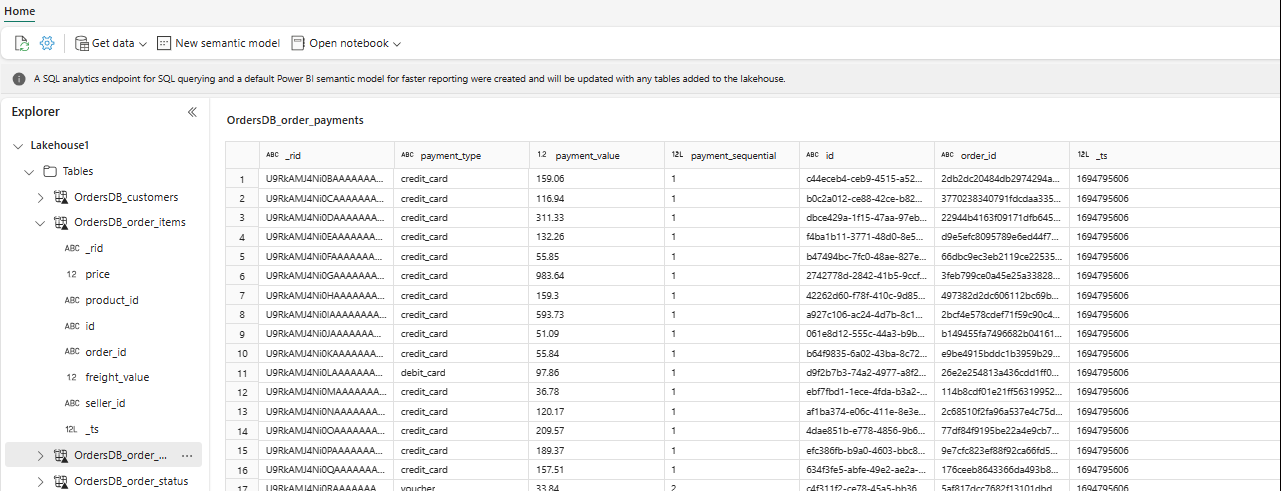
Návod
Do Lakehouse můžete přidat další data přímo nebo můžete přidat zástupce, jako je S3, ADLS Gen2. Můžete přejít na koncový bod analýzy SQL lakehouse a spojit data napříč všemi těmito zdroji s bezproblémově zrcadlenými daty.
Pokud chcete tato data prozkoumat ve Sparku, vyberte
...tečky vedle jakékoli tabulky. Vyberte Nový poznámkový blok nebo Existující poznámkový blok a začněte analyzovat.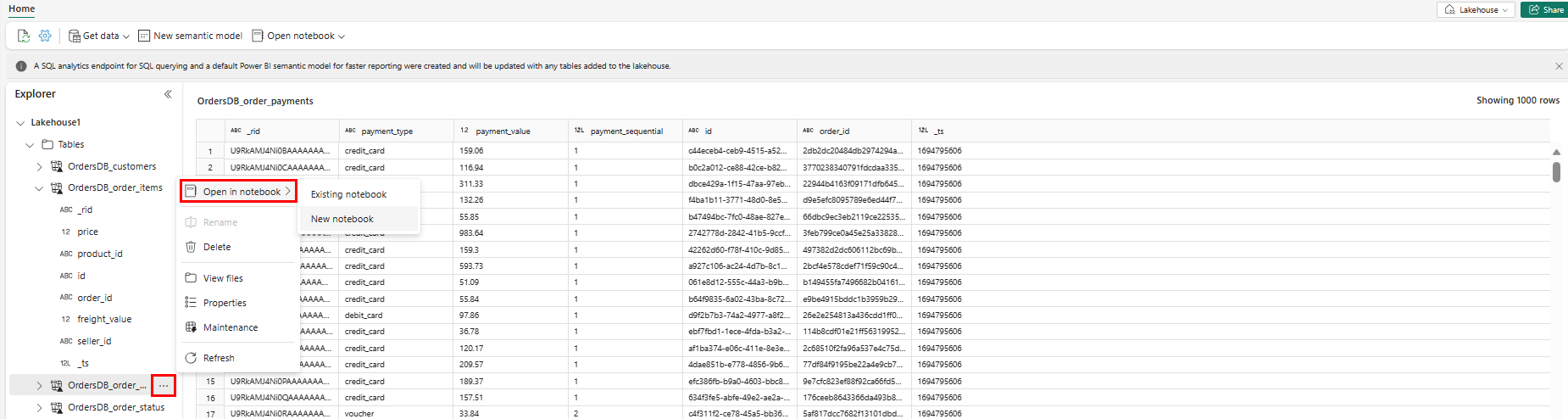
Poznámkový blok se automaticky otevře a načte datový rámec pomocí
SELECT ... LIMIT 1000dotazu Spark SQL.- Úplné načtení nových poznámkových bloků může trvat až dvě minuty. Toto zpoždění se můžete vyhnout použitím existujícího poznámkového bloku s aktivní relací.
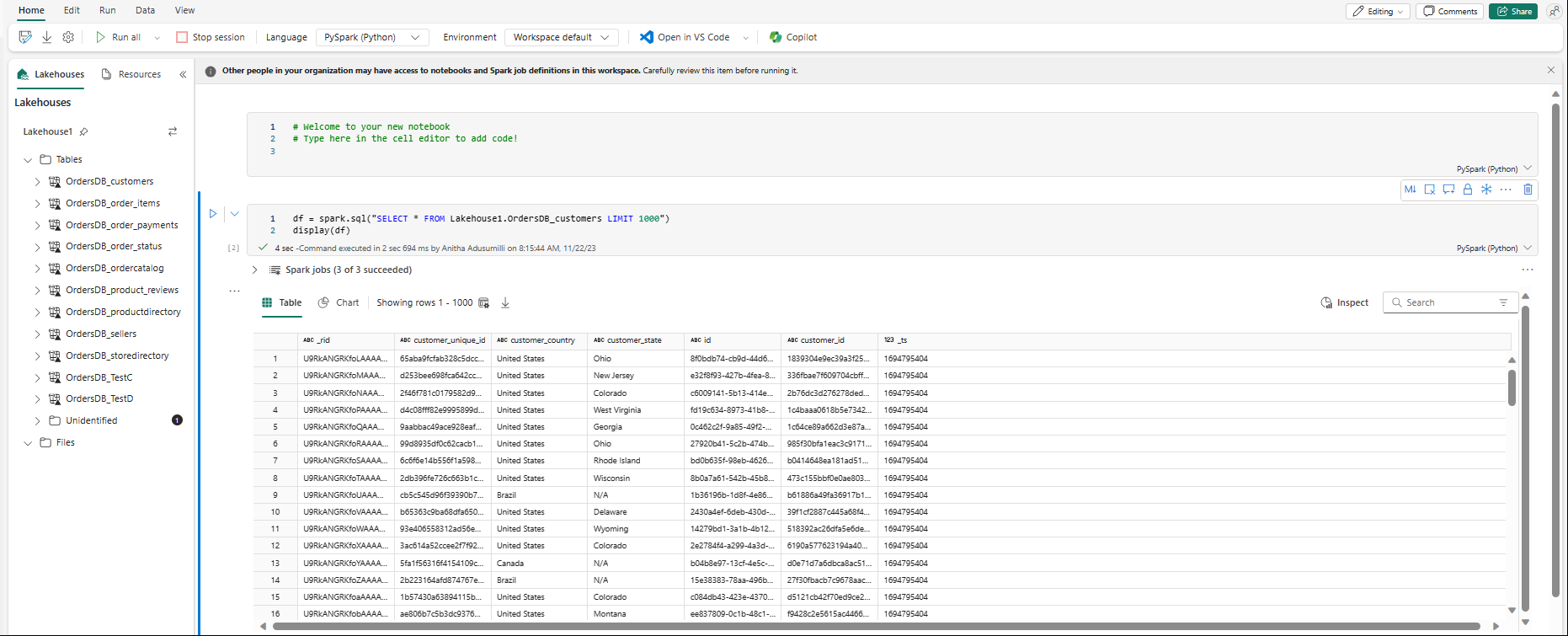
- Úplné načtení nových poznámkových bloků může trvat až dvě minuty. Toto zpoždění se můžete vyhnout použitím existujícího poznámkového bloku s aktivní relací.


