Integrace OneLake se službou Azure HDInsight
Azure HDInsight je spravovaná cloudová služba pro analýzu velkých objemů dat, která organizacím pomáhá zpracovávat velké objemy dat. V tomto kurzu se dozvíte, jak se připojit k OneLake pomocí poznámkového bloku Jupyter z clusteru Azure HDInsight.
Použití Služby Azure HDInsight
Připojení k OneLake pomocí poznámkového bloku Jupyter z clusteru HDInsight:
Vytvoření clusteru Apache Spark (HDInsight) Postupujte podle těchto pokynů: Nastavte clustery ve službě HDInsight.
Při poskytování informací o clusteru si zapamatujte uživatelské jméno a heslo pro přihlášení ke clusteru, protože je budete potřebovat pro pozdější přístup ke clusteru.
Vytvořte spravovanou identitu přiřazenou uživatelem (UAMI): Vytvořte pro Azure HDInsight – UAMI a zvolte ji jako identitu na obrazovce Úložiště .
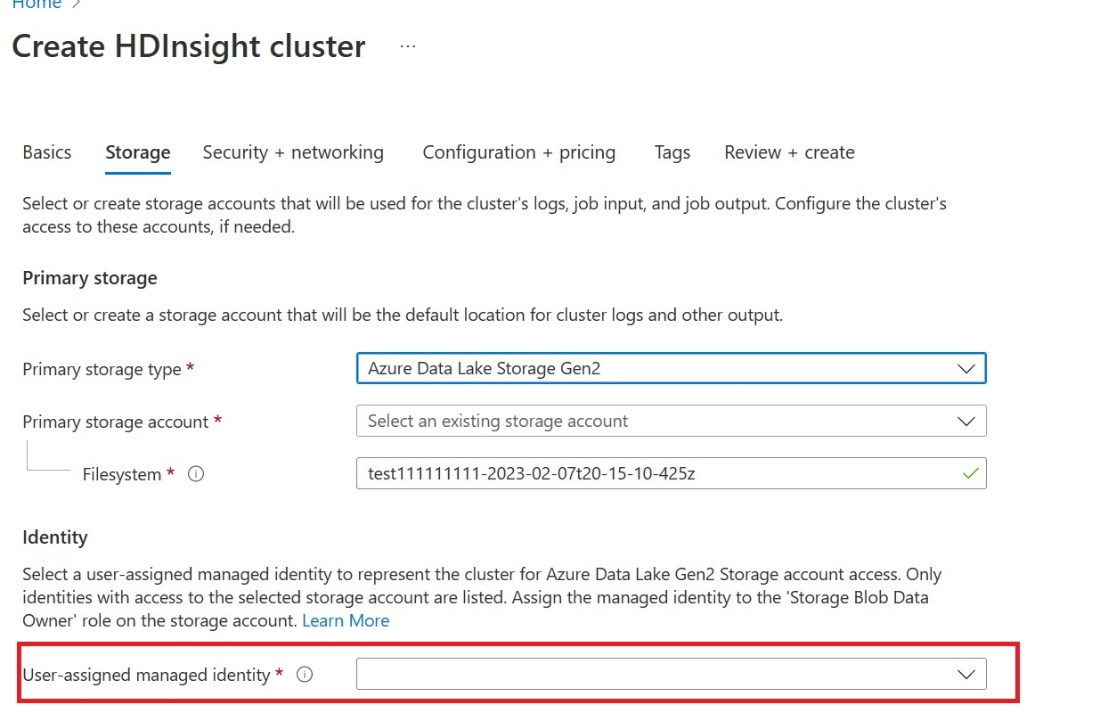
Dejte tomuto nástroji UAMI přístup k pracovnímu prostoru Fabric, který obsahuje vaše položky. Nápovědu k rozhodování o tom, jaká role je nejlepší, najdete v tématu Role pracovního prostoru.
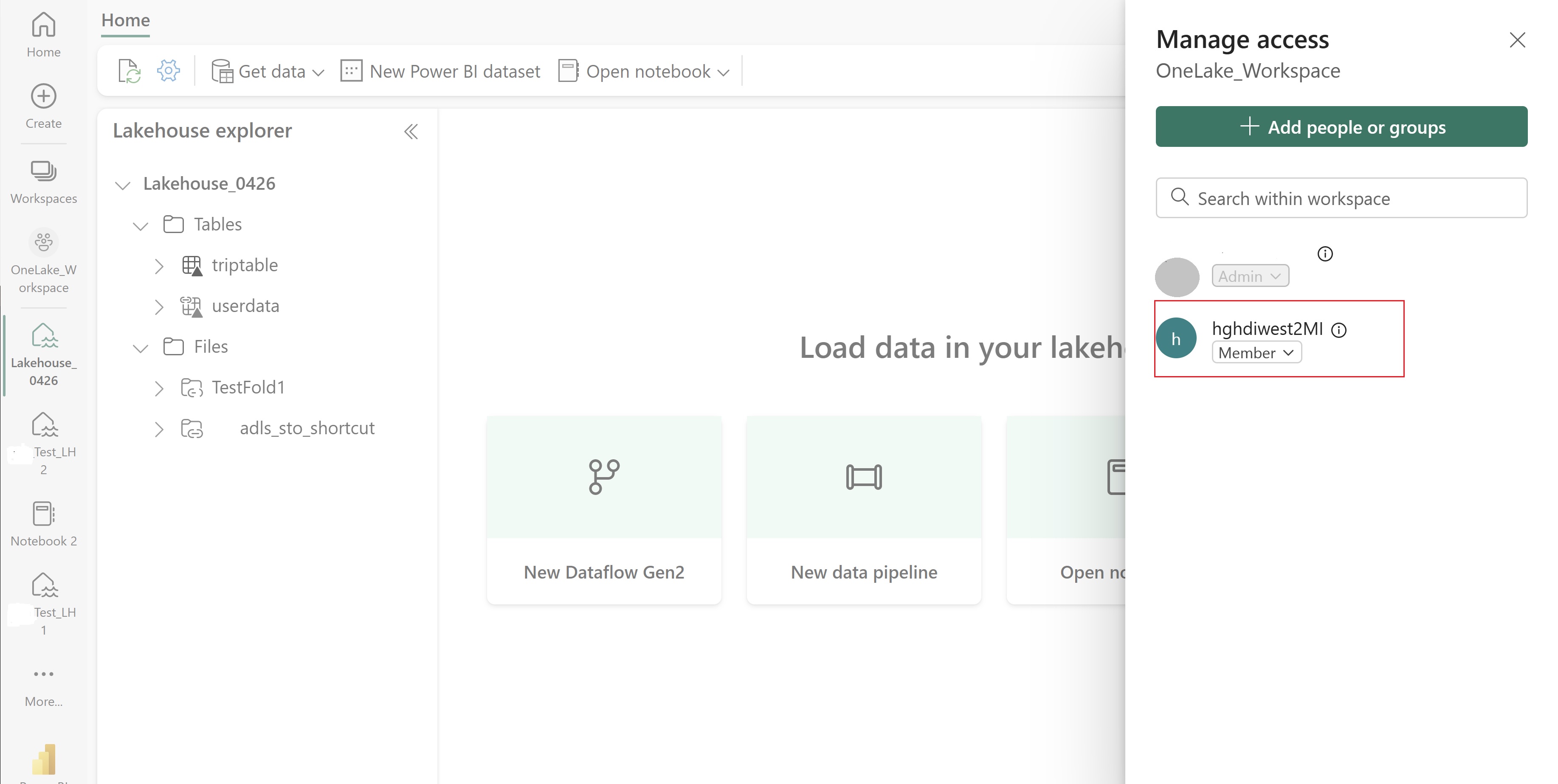
Přejděte do svého jezera a najděte název vašeho pracovního prostoru a jezerahouse. Najdete je v adrese URL vašeho jezera nebo v podokně Vlastnosti souboru.
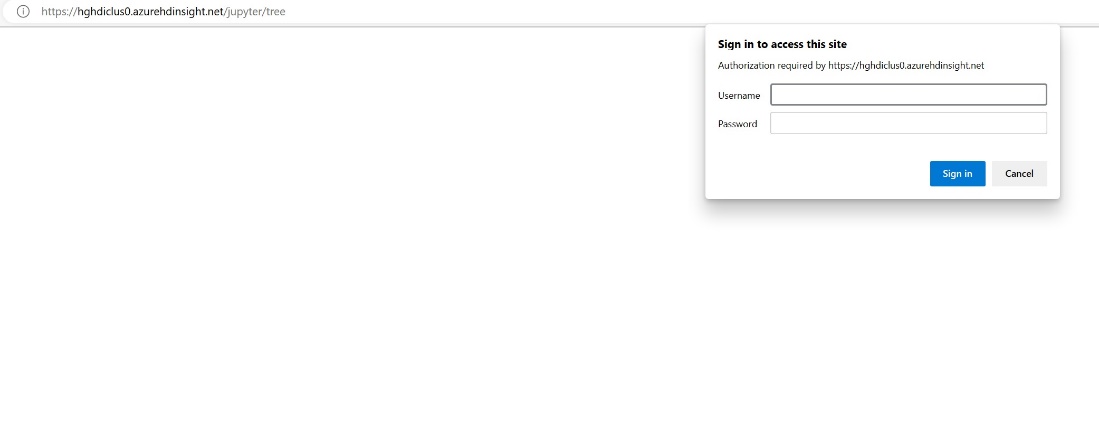
Na webu Azure Portal vyhledejte cluster a vyberte poznámkový blok.

Zadejte informace o přihlašovacích údaji, které jste zadali při vytváření clusteru.
Vytvořte nový poznámkový blok Apache Sparku.
Zkopírujte názvy pracovních prostorů a lakehouse do poznámkového bloku a sestavte adresu URL OneLake pro váš lakehouse. Teď můžete číst jakýkoli soubor z této cesty k souboru.
fp = 'abfss://' + 'Workspace Name' + '@onelake.dfs.fabric.microsoft.com/' + 'Lakehouse Name' + '/Files/' df = spark.read.format("csv").option("header", "true").load(fp + "test1.csv") df.show()Zkuste do jezera zapsat nějaká data.
writecsvdf = df.write.format("csv").save(fp + "out.csv")Otestujte, jestli se data úspěšně zapisovala, a to tak, že zkontrolujete lakehouse nebo si přečtete nově načtený soubor.




Teď můžete číst a zapisovat data v OneLake pomocí poznámkového bloku Jupyter v clusteru HDI Spark.
Související obsah
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro