Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Operátor SQL, označovaný také jako editor kódu SQL, je nová funkce transformace dat v eventstreamech Microsoft Fabric. Operátory SQL poskytují prostředí pro úpravy kódu, kde můžete snadno definovat vlastní logiku transformace dat pomocí jednoduchých výrazů SQL. Tento článek popisuje, jak používat operátor SQL pro transformace dat v eventstreamu.
Note
Názvy artefaktů eventstreamu, které obsahují podtržítko (_) nebo tečky (.), nejsou kompatibilní s operátory SQL. Pro zajištění co nejlepšího prostředí vytvořte nový eventstream bez použití podtržítka nebo tečky v názvu artefaktu.
Prerequisites
- Přístup k pracovnímu prostoru v režimu licence kapacity Fabric nebo v režimu zkušební licence s oprávněními přispěvatele nebo vyšší.
Přidání operátoru SQL do eventstreamu
Pokud chcete u datových proudů provádět operace zpracování datových proudů pomocí operátoru SQL, přidejte do streamu událostí operátor SQL pomocí následujících pokynů:
Vytvořte nový stream událostí. Potom k němu přidejte operátor SQL pomocí jedné z následujících možností:
Na vláknové liště zvolte Převod událostí, a poté zvolte SQL.
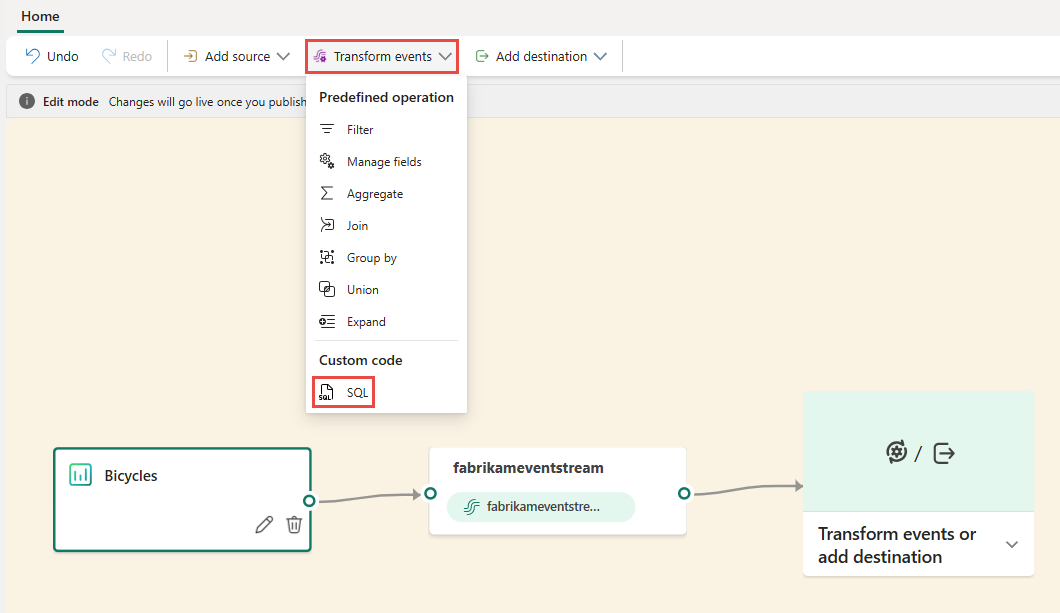
Na plátně vyberte Transformace událostí nebo přidat cíl a pak vyberte SQL Code.
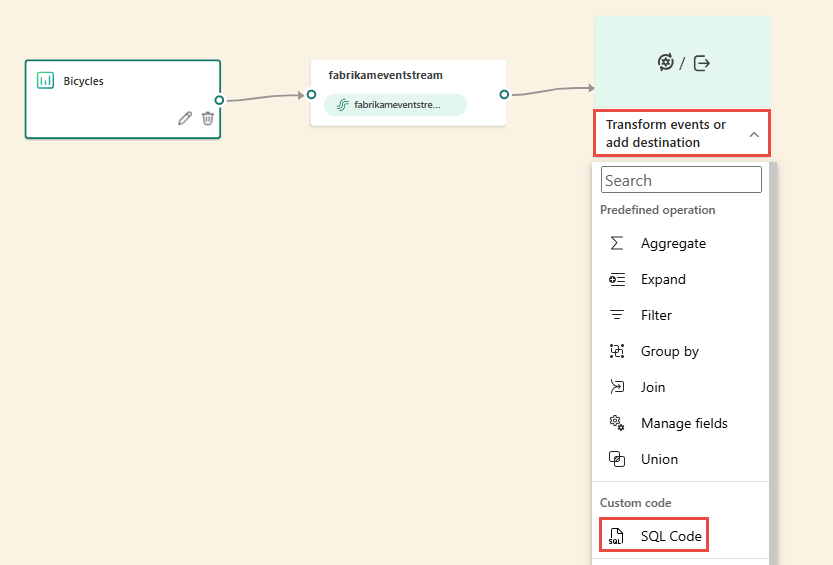
Do vašeho eventstreamu se přidá nový uzel SQL. Pokud chcete pokračovat v nastavování operátoru SQL, vyberte ikonu tužky.
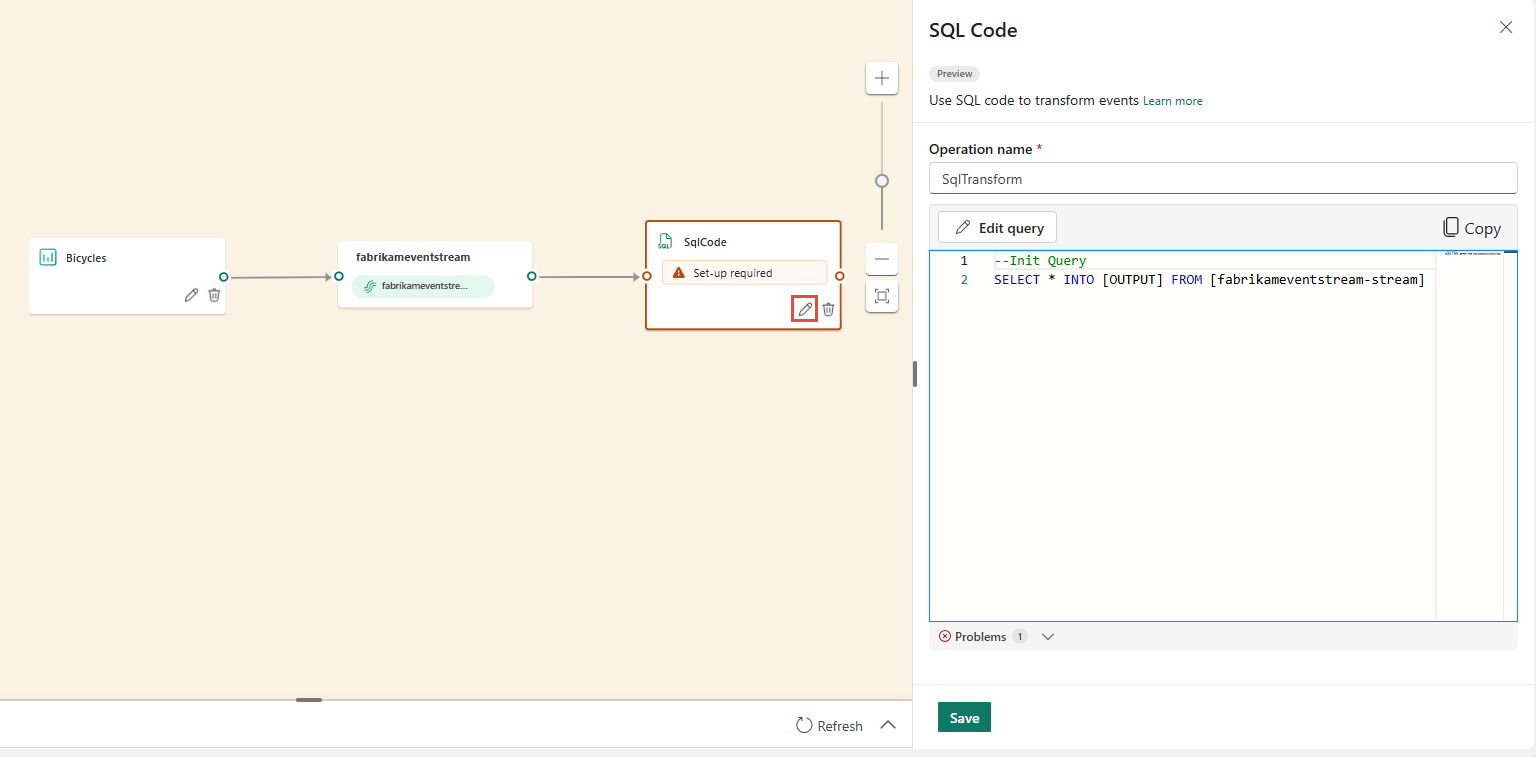
V podokně kód SQL zadejte jedinečný název pro uzel operátoru SQL v eventstreamu.
Upravte dotaz v oblasti dotazu nebo vyberte Upravit dotaz a zadejte zobrazení editoru kódu na celé obrazovce.
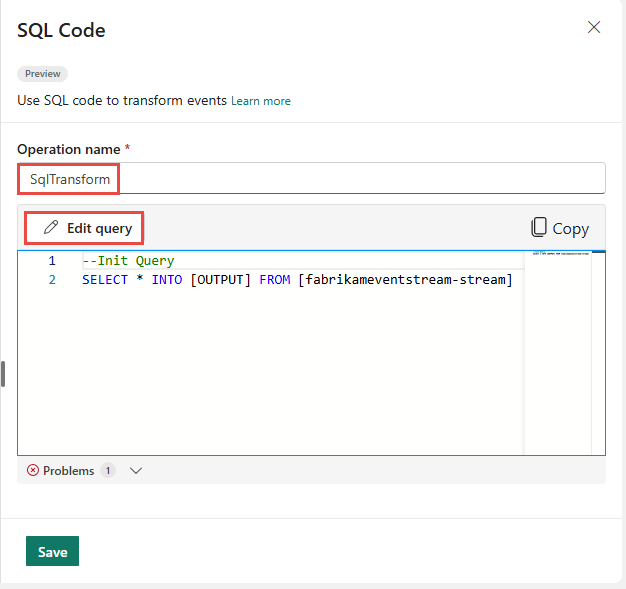
Režim editoru kódu na celé obrazovce obsahuje podokno průzkumníka vstupu a výstupu na levé straně. Oddíl editoru kódu je upravitelný, takže ho můžete změnit podle svých preferencí. Část Náhled v dolní části umožňuje zobrazit jak vstupní data, tak výsledek testu dotazu.
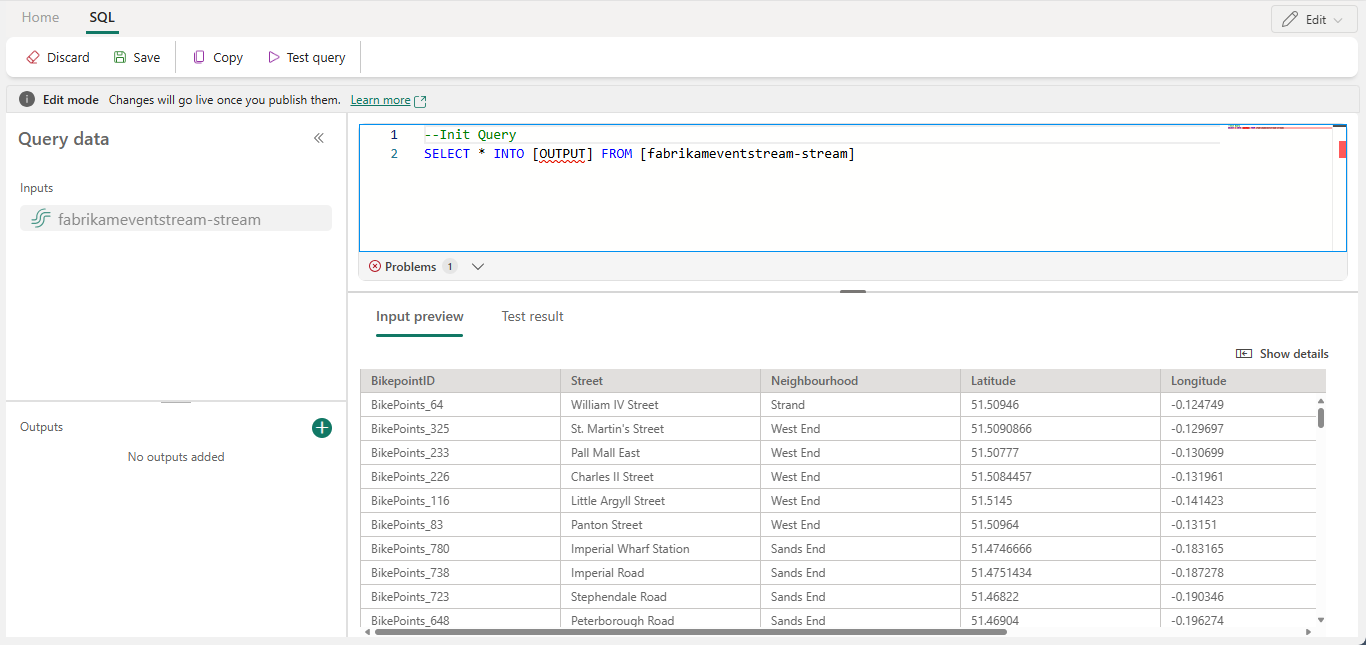
Vyberte text v části Výstupy a zadejte název cílového uzlu. Operátor SQL podporuje všechny cíle Real-Time Intelligence, včetně eventhouse, lakehouse, aktivátoru nebo streamu.
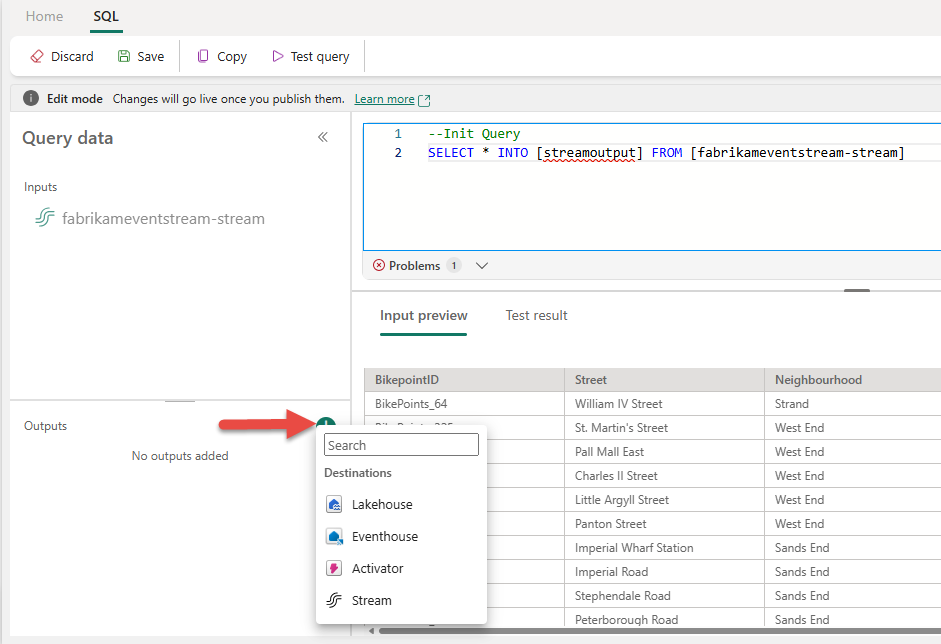
Zadejte alias nebo název výstupního cíle, kde se zapisují data zpracovávaná pomocí operátoru SQL.
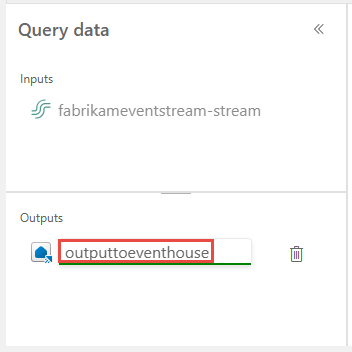
Přidejte dotaz SQL pro požadovanou transformaci dat.
Eventstream je založený na Azure Stream Analytics a podporuje stejnou sémantiku dotazů dotazovacího jazyka Stream Analytics. Další informace o syntaxi a použití najdete v tématu Azure Stream Analytics a reference k jazyku Eventstream Query Language.
Tady je základní struktura dotazu:
SELECT column1, column2, ... INTO [output alias] FROM [input alias]Tento příklad dotazu ukazuje detekci vysokých teplot v místnosti každou minutu:
SELECT System.Timestamp AS WindowEnd, roomId, AVG(temperature) AS AvgTemp INTO output FROM input GROUP BY roomId, TumblingWindow(minute, 1) HAVING AVG(temperature) > 75Tento příklad dotazu ukazuje
CASEpříkaz pro kategorizaci teploty:SELECT deviceId, temperature, CASE WHEN temperature > 85 THEN 'High' WHEN temperature BETWEEN 60 AND 85 THEN 'Normal' ELSE 'Low' END AS TempCategory INTO CategorizedTempOutput FROM SensorInputNa pásu karet použijte příkaz Test dotazu k ověření logiky transformace. Výsledky testu dotazu se zobrazí na kartě Výsledek testu .
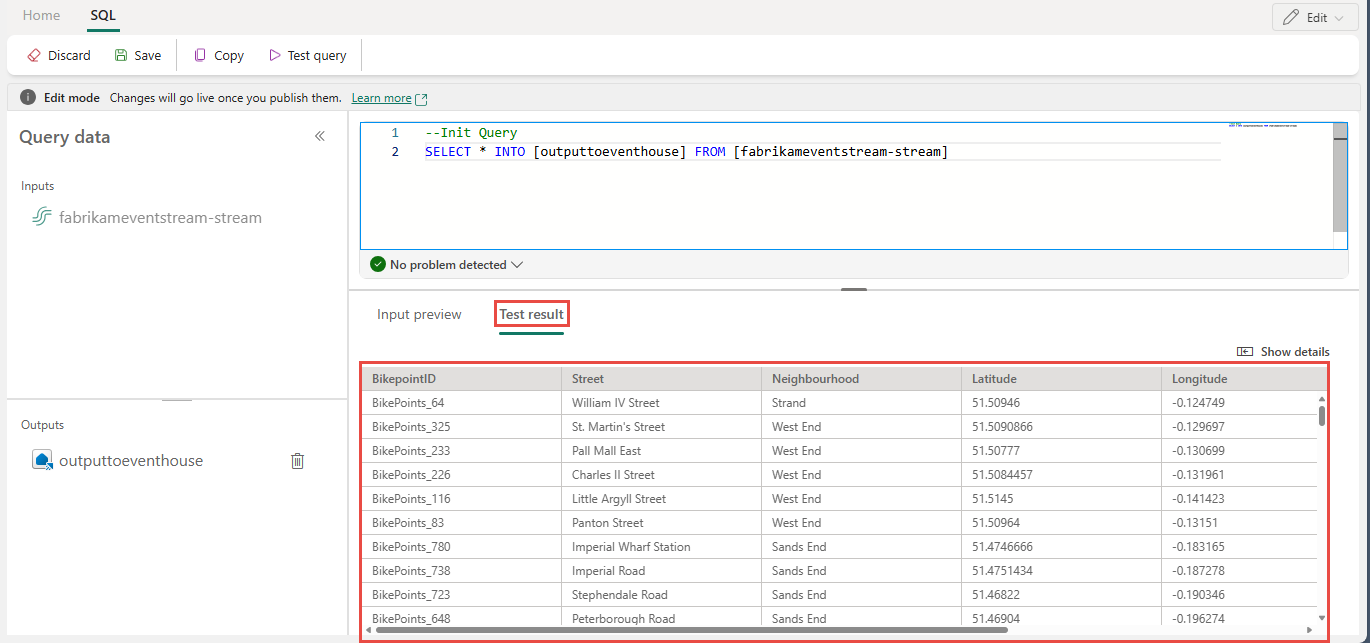
Po dokončení testování vyberte Uložit na pásu s nástroji a vraťte se na plátno eventstreamu.
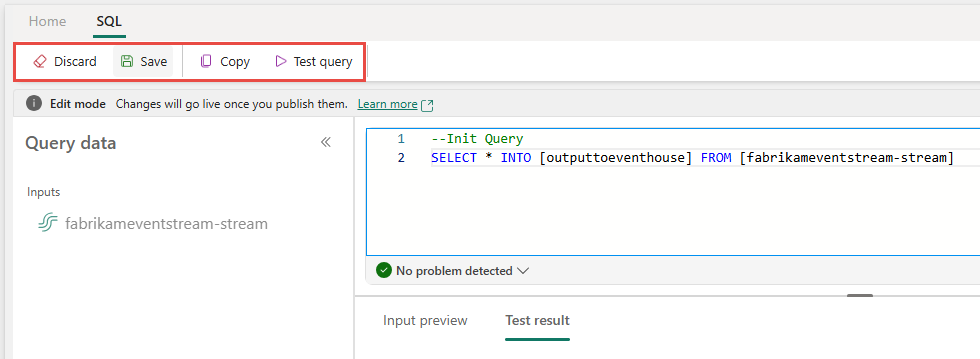
Pokud je v podokně kód SQL povolené tlačítko Uložit , vyberte ho a uložte nastavení.
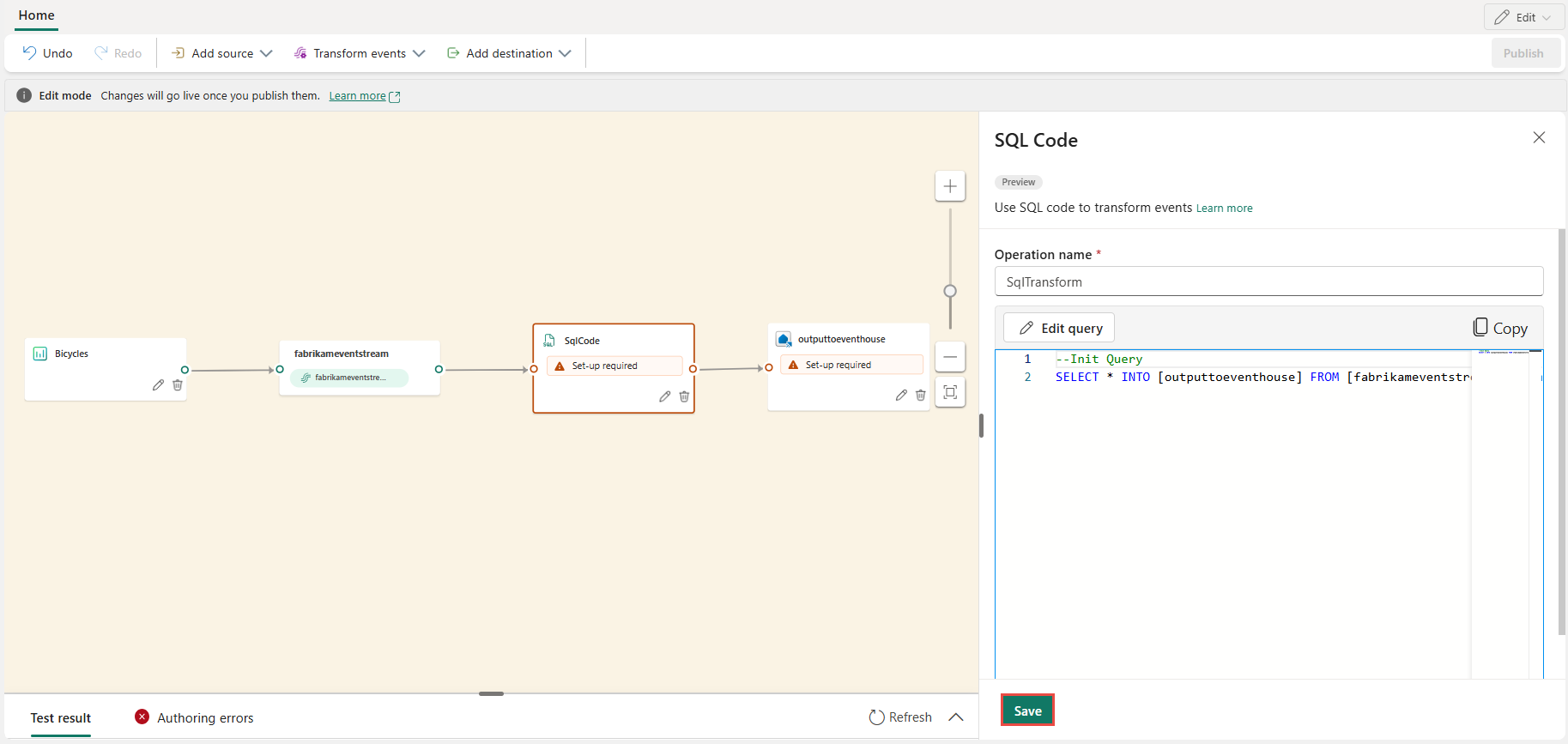
Nakonfigurujte cíl.











Další příklady
Následující příklady ukazují běžné scénáře analýzy v reálném čase, které můžete implementovat pomocí operátoru SQL.
Agregace prodeje města za minutu – slouží TumblingWindow k výpočtu pevných, nepřekryvných celkových tržeb po minutách seskupených podle města:
SELECT
System.Timestamp AS WindowEnd,
city,
SUM(salesAmount) AS TotalSales
INTO
output
FROM
input
GROUP BY
city,
TumblingWindow(minute, 1)
Detekce špiček a robotů – Slouží HoppingWindow k detekci uživatelů, kteří do pětiminutového přesouvajícího se intervalu umístí neobvykle vysoký počet objednávek, vyhodnocují se každou minutu:
SELECT
System.Timestamp AS WindowEnd,
userId,
COUNT(*) AS OrderCount
INTO
output
FROM
input
GROUP BY
userId,
HoppingWindow(minute, 5, 1)
HAVING
COUNT(*) > 10
Anomálie indikující na pohyblivý základ – použijte HoppingWindow k výpočtu pohyblivého průměru a označení zařízení, jejichž maximální hodnota metriky překračuje dvojnásobek průměru v rámci okna, což naznačuje potenciální anomálii:
SELECT
System.Timestamp AS WindowEnd,
deviceId,
AVG(metricValue) AS RollingAvg,
MAX(metricValue) AS CurrentMax
INTO
output
FROM
input
GROUP BY
deviceId,
HoppingWindow(minute, 10, 1)
HAVING
MAX(metricValue) > 2 * AVG(metricValue)
Psát do více cílů z jednoho operátoru SQL
Pomocí operátoru SQL můžete odesílat data do několika výstupních jímek nebo cílů přidáním více INTO klauzulí do dotazu SQL a definováním více výstupů.
Definování více výstupů v editoru dotazů
Výběrem možnosti Upravit (ikona tužky) na uzlu operátora SQL otevřete podokno kódu SQL .
V podokně Kód SQL vyberte Upravit dotaz a otevřete editor kódu na celé obrazovce.
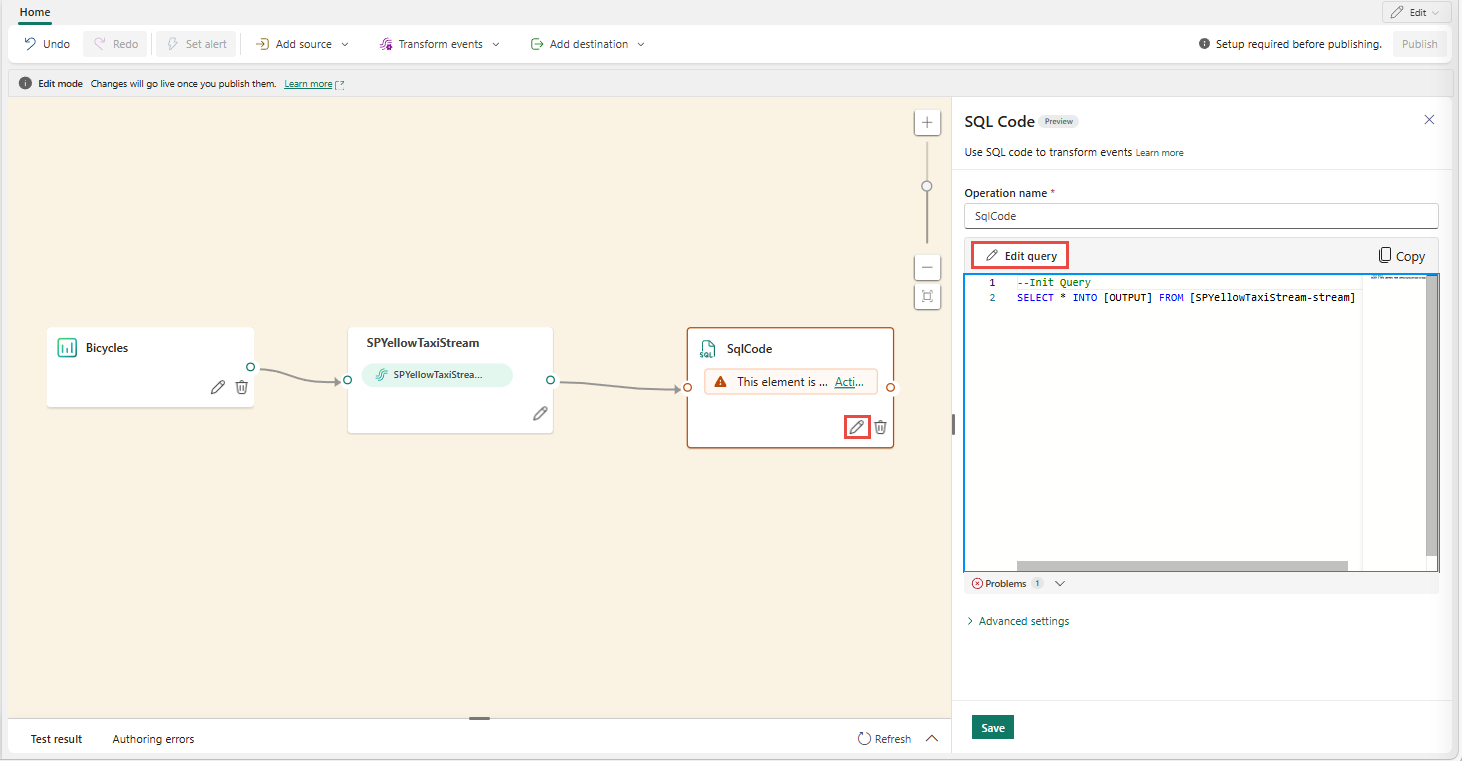
V editoru kódu na celé obrazovce vyberte + v části Výstupy a přidejte nový výstup. Vyberte typ výstupu podle vašeho výběru. Vytvoří alias výstupu, který můžete použít v dotazu. Vyberte název vytvořeného výstupu a zadejte požadovaný název.
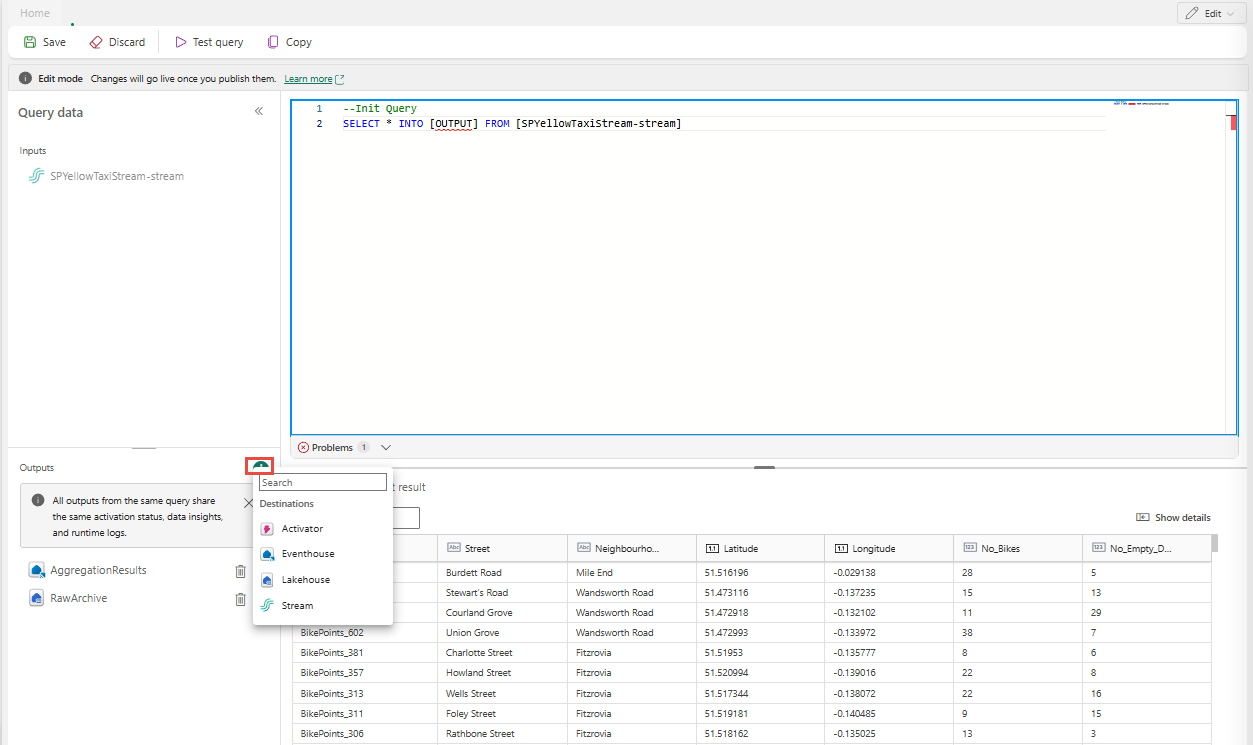


Použít příkazy SELECT ... INTO vícekrát
Každý SELECT příkaz může zapisovat do jiného výstupu. Přidejte dotaz pro zápis výstupu do více cílů.
V následujícím příkladu dotazu první SELECT příkaz zapíše do výstupu s názvem RawArchive (type: Lakehouse) a druhý SELECT příkaz zapíše do výstupu s názvem AggregationResults (type: Eventhouse).
-- Query 1: Archive all data to Lakehouse
SELECT *
INTO [RawArchive]
FROM [SQLDemoES-stream]
-- Query 2: Aggregate and filter data to create a real time dashboard to an Eventhouse
SELECT System.Timestamp() AS EventTime, COUNT(*) AS EventCount
INTO [AggregationResults]
FROM [SQLDemoES-stream]
GROUP BY TumblingWindow(minute, 1)
HAVING COUNT(*) > 100
Opakované použití zprostředkující logiky (osvědčený postup)
Pokud se chcete vyhnout duplikování logiky, použijte klauzuli WITH a rozvětvujte ji do několika výstupů odtud. V následujícím příkladu je společný výraz tabulky (CTE) definovaný tak, InputStream aby četl ze vstupního datového proudu jednou, a pak dva SELECT příkazy odkazují InputStream na CTE pro zápis do různých výstupů. Tento přístup je efektivnější, protože se vyhýbá opakovanému čtení ze vstupního proudu.
Do editoru kódu SQL zadejte následující dotaz, který načte ze vstupního datového proudu jednou a zapíše do více výstupů.
--Base query: Reading input stream once With InputStream AS( SELECT * FROM [SQLDemoES-stream] ) -- Query 1: Archive all data to Lakehouse SELECT * INTO [RawArchive] FROM InputStream -- Query 2: Aggregate and filter data to create a real time dashboard to an Eventhouse SELECT System.Timestamp() AS EventTime, COUNT(*) AS EventCount INTO [AggregationResults] FROM InputStream GROUP BY TumblingWindow(minute, 1) HAVING COUNT(*) > 100Výběrem testovacího dotazu ověřte výsledek dotazu. Každý výstup definovaný v dotazu má na panelu výsledků testu samostatnou kartu.
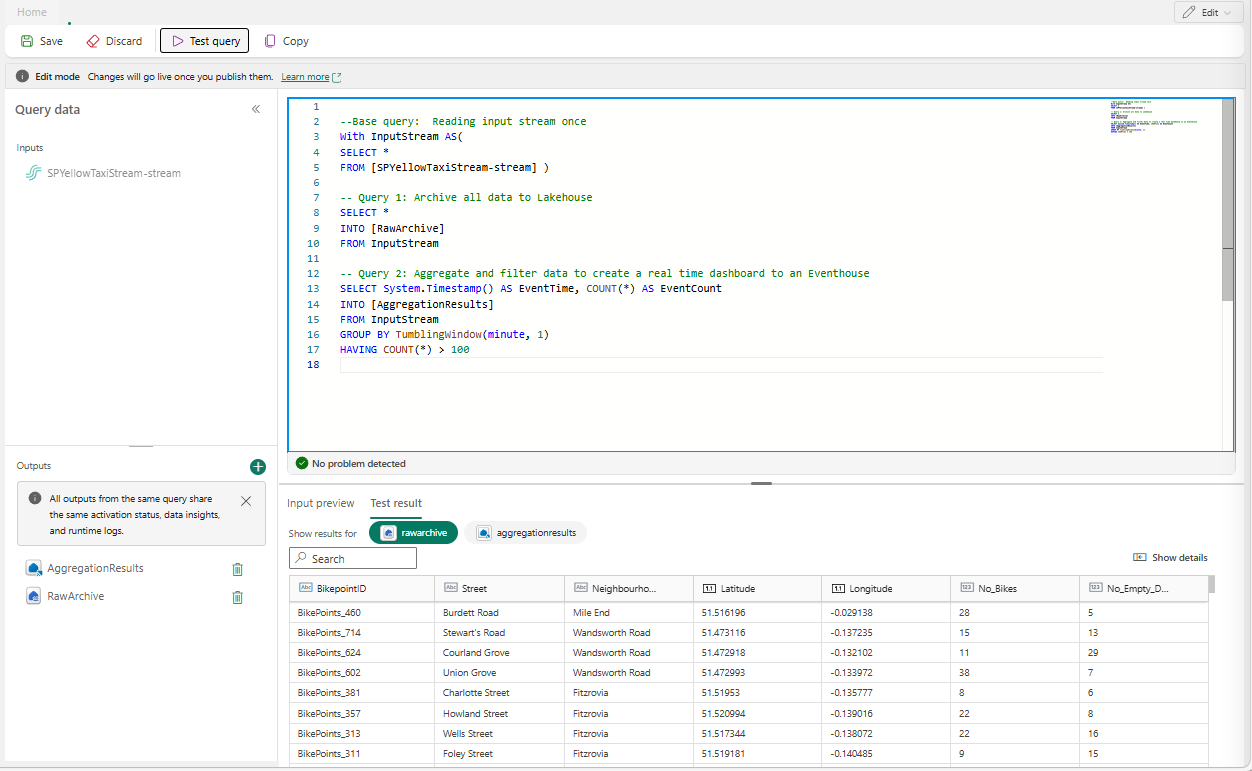
Výběrem možnosti Uložit dotaz uložte a ukončete editor.
V podokně Editor SQL znovu vyberte Uložit .
Vyberte každý cílový uzel vytvořený z operátoru SQL a pak nakonfigurujte nastavení cíle pro každý z nich.
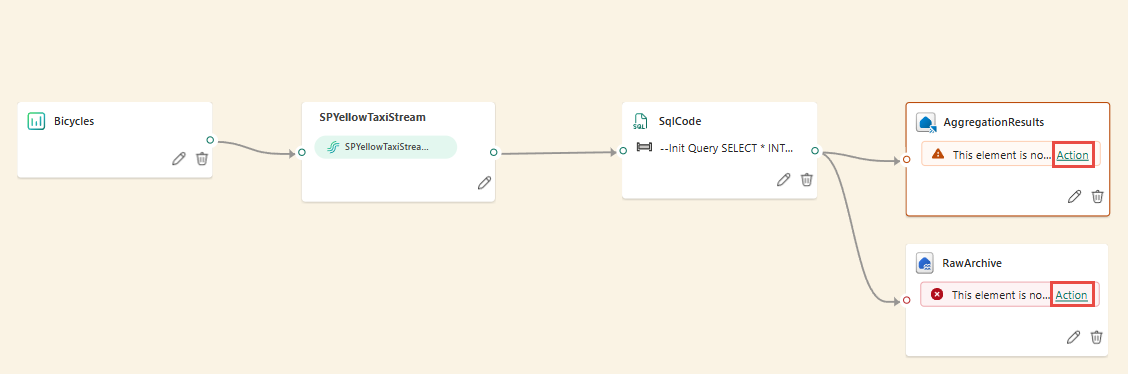
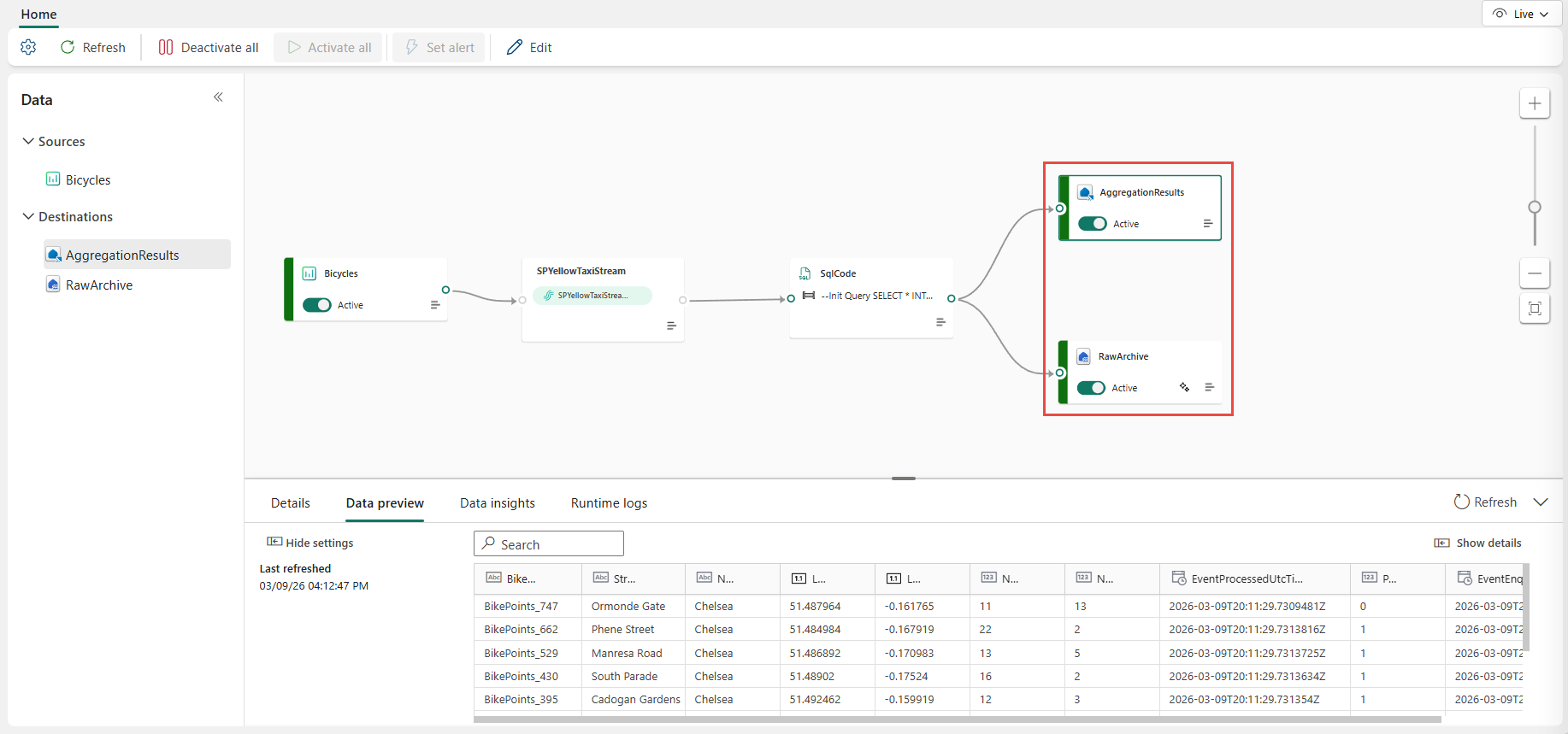
Po dokončení konfigurace by měl váš eventstream vypadat jako v následujícím příkladu, kde uzel operátoru SQL má dva výstupní cíle.




Konfigurace zásad řazení událostí v operátoru SQL
Pomocí operátoru SQL můžete zpracovávat data pomocí události nebo času aplikace. Ve výchozím nastavení eventstream používá čas příjezdu. Pokud chcete zpracovat čas události, musíte ho explicitně nakonfigurovat pomocí TIMESTAMP BY dotazu.
Ukázkový vstup
{
"deviceId": "device123",
"temperature": 72,
"eventTime": "2024-01-01T12:00:00Z"
}
Ukázkový dotaz s využitím času události
SELECT
deviceId,
temperature,
System.Timestamp() AS EventTimestamp
INTO
Output
FROM
Input
TIMESTAMP BY eventTime;
V upřesňujícím nastavení operátora SQL můžete také přidat prahové hodnoty pro pozdní příchod a události mimo objednávku.

Limitations
Operátor SQL je navržený tak, aby centralizovat veškerou logiku transformace. V důsledku toho ho nemůžete použít společně s jinými integrovanými operátory ve stejné cestě zpracování. Řetězení více operátorů SQL v jedné cestě se také nepodporuje.
Pokud do topologie přidáte operátor SQL, musíte vytvořit nové cílové uzly. Existující cílové uzly nelze znovu použít s operátorem SQL.