Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento dokument obsahuje pokyny specifické pro konkrétní prostředí pro obnovení dat Fabric v případě regionální havárie.
Ukázkový scénář
Mnoho částí s pokyny v tomto dokumentu používá následující ukázkový scénář pro účely vysvětlení a ilustrace. Podle potřeby se vraťte k tomuto scénáři.
Řekněme, že máte kapacitu C1 v oblasti A, která má pracovní prostor W1. Pokud jste zapnuli zotavení po havárii pro kapacitu C1, data OneLake se replikují do zálohy v oblasti B. Pokud oblast A čelí přerušení, služba Fabric v C1 přepne se do oblasti B.
Poznámka:
Tyto pokyny k obnovení platí jen v případě, že primární oblast má sekundární oblast spárovanou s Azure a Fabric je podporován v podporované spárované oblasti.
Tento scénář znázorňuje následující obrázek. V poli vlevo se zobrazí přerušená oblast. Pole uprostřed představuje nepřetržitou dostupnost dat po převzetí služeb při selhání a pole na pravé straně ukazuje plně pokrytou situaci poté, co zákazník jedná o obnovení služeb do plné funkce.
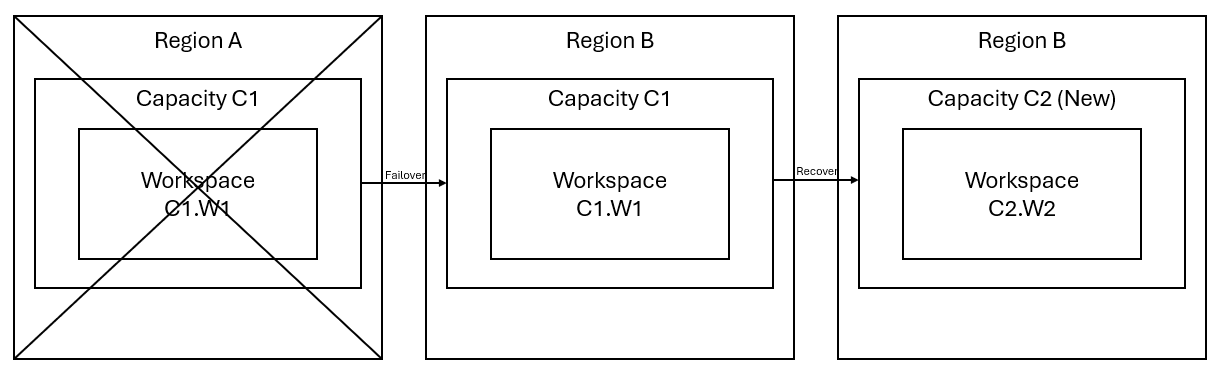
Tady je obecný plán obnovení:
Vytvořte novou kapacitu C2 Fabric v nové oblasti.
Vytvořte nový pracovní prostor W2 v jazyce C2, včetně odpovídajících položek se stejnými názvy jako v C1. W1.
Zkopírujte data z nefunkčního C1.W1 do C2.W2.
Postupujte podle vyhrazených pokynů pro každou komponentu a obnovte položky do své úplné funkce.
Tento plán obnovení předpokládá, že domovská oblast tenanta zůstává funkční. Pokud domovská oblast tenanta dojde k výpadku, kroky popsané v tomto dokumentu jsou podmíněny jeho obnovením, které musí být zahájeny a dokončeny Microsoft.
Plány obnovení specifické pro konkrétní prostředí
Následující části obsahují podrobné pokyny pro každou zkušenost s Fabric, které pomohou zákazníkům během procesu obnovy.
Datové Inženýrství
Tato příručka vás provede postupy obnovy pro oblast datového inženýrství. Zahrnuje definice úloh pro lakehouse, poznámkové bloky a definice úloh pro Spark.
Jezero
Lakehouses z původní oblasti zůstávají zákazníkům nedostupné. Pokud chtějí zákazníci obnovit lakehouse, mohou ho znovu vytvořit v pracovním prostoru C2.W2. Pro obnovení jezera doporučujeme dva přístupy:
Přístup 1: Kopírování tabulek a souborů Lakehouse Delta pomocí vlastního skriptu
Zákazníci můžou znovu vytvořit jezera pomocí vlastního skriptu Scala.
V nově vytvořeném pracovním prostoru C2.W2 vytvořte lakehouse (například LH1).
Vytvořte nový poznámkový blok v pracovním prostoru C2. W2.
Pokud chcete obnovit tabulky a soubory z původního lakehouse, projděte si data pomocí cest OneLake, jako jsou abfss (viz Připojení k Microsoft OneLake). Následující příklad kódu (viz Introduction ke Microsoft Spark Nástrojům) v poznámkovém bloku můžete použít k získání ABFS cest souborů a tabulek z původního lakehouse. (Nahraďte C1. W1 se skutečným názvem pracovního prostoru)
notebookutils.fs.ls('abfs[s]://<C1.W1>@onelake.dfs.fabric.microsoft.com/<item>.<itemtype>/<Tables>/<fileName>')Pomocí následujícího příkladu kódu přesuňte tabulky a soubory do nového Lakehouse.
U tabulek Delta je potřeba tabulku zkopírovat po jednom, aby se obnovila v novém jezeře. V případě souborů Lakehouse můžete zkopírovat kompletní strukturu souborů se všemi podkladovými složkami s jediným spuštěním.
Spojte se s týmem podpory pro časové razítko potřebné pro přepnutí na záložní systém ve skriptu.
%%spark val source="abfs path to original Lakehouse file or table directory" val destination="abfs path to new Lakehouse file or table directory" val timestamp= //timestamp provided by Support notebookutils.fs.cp(source, destination, true) val filesToDelete = notebookutils.fs.ls(s"$source/_delta_log") .filter{sf => sf.isFile && sf.modifyTime > timestamp} for(fileToDelete <- filesToDelete) { val destFileToDelete = s"$destination/_delta_log/${fileToDelete.name}" println(s"Deleting file $destFileToDelete") notebookutils.fs.rm(destFileToDelete, false) } notebookutils.fs.write(s"$destination/_delta_log/_last_checkpoint", "", true)Po spuštění skriptu se tabulky zobrazí v novém jezeře.
Přístup 2: Kopírování souborů a tabulek pomocí Azure Storage Explorer
Pokud chcete obnovit pouze konkrétní soubory nebo tabulky Lakehouse z původního jezera, použijte Azure Storage Explorer. Podrobné kroky najdete v odkazu na Integrate OneLake s Azure Storage Explorer. V případě velkých objemů dat použijte přístup 1.
Poznámka:
Dva přístupy popsané výše obnoví metadata i data tabulek ve formátu Delta, protože metadata jsou společně umístěna a uložena s daty v OneLake. U neformátovaných tabulek (například CSV, Parquet atd.), které se vytvářejí pomocí skriptů a příkazů DDL (Spark Data Definition Language), zodpovídá uživatel za údržbu a opětovné spuštění skriptů/příkazů Spark DDL, aby je obnovil.
Obnovení Fabric materializovaných zobrazení jezera
Materializovaná zobrazení datového jezera z původního regionu zůstávají po převzetí služeb při selhání zákazníkům nedostupná. Plány aktualizace a historie spouštění se nereplikují do sekundární oblasti. Pokud je chcete obnovit, proveďte následující kroky po obnovení dat Lakehouse.
- Obnovení tabulek Lakehouse pomocí přístupu 1 nebo přístupu 2 popsaného výše Zkopírujte pouze zdrojové tabulky.
- Obnovte zápisníky obsahující definice MLV. Postup obnovení najdete v části Poznámkový blok .
- Spuštěním obnovených poznámkových bloků znovu vytvořte MLVs v novém Lakehouse. Informace o vytváření MLV naleznete v tématu Vytvoření materializovaného jezera zobrazení. Pokud byly MLV také zkopírovány v předchozím kroku, spusťte CREATE OR REPLACE a znovu je vytvořte.
- Znovu vytvořte plány aktualizace MLV ručně v novém pracovním prostoru. Metriky historie plánu a spouštění se nedají obnovit.
- Pokud vaše MLV slouží k napájení sémantických modelů nebo sestav, podle potřeby ověřte a aktualizujte odkazy na ID Lakehouse a ID datové sady. Znovu připojte sestavy k aktualizovanému sémantickému modelu a ověřte, zda jsou data aktuální.
Návod
Chcete-li minimalizovat změny kódu při spouštění poznámkových bloků po převzetí služeb při selhání, používejte stejné názvy pracovního prostoru a Lakehouse v nové oblasti (zejména pokud je v konvencích pojmenování použit název pracovního prostoru či Lakehouse). Plány aktualizace, historie spuštění a provozní metriky začínají znovu v obnovené oblasti. Při vytváření nových prahových hodnot monitorování naplánujte základní období.
Notebook (počítač)
Notebooky z primární oblasti jsou zákazníkům nedostupné a kód v těchto noteboocích se nereplikuje do sekundární oblasti. Pokud chcete obnovit kód poznámkového bloku v nové oblasti, existují dva přístupy k obnovení obsahu kódu poznámkového bloku.
Přístup 1: Redundance spravovaná uživatelem s integrací Gitu (ve verzi Public Preview)
Nejlepším způsobem, jak to snadno a rychle udělat, je použít integraci Fabric Gitu a pak synchronizovat poznámkový blok s úložištěm ADO. Když dojde k selhání služby a přenesení do jiné oblasti, můžete použít úložiště k opětovnému sestavení poznámkového bloku v novém pracovním prostoru, který jste již vytvořili.
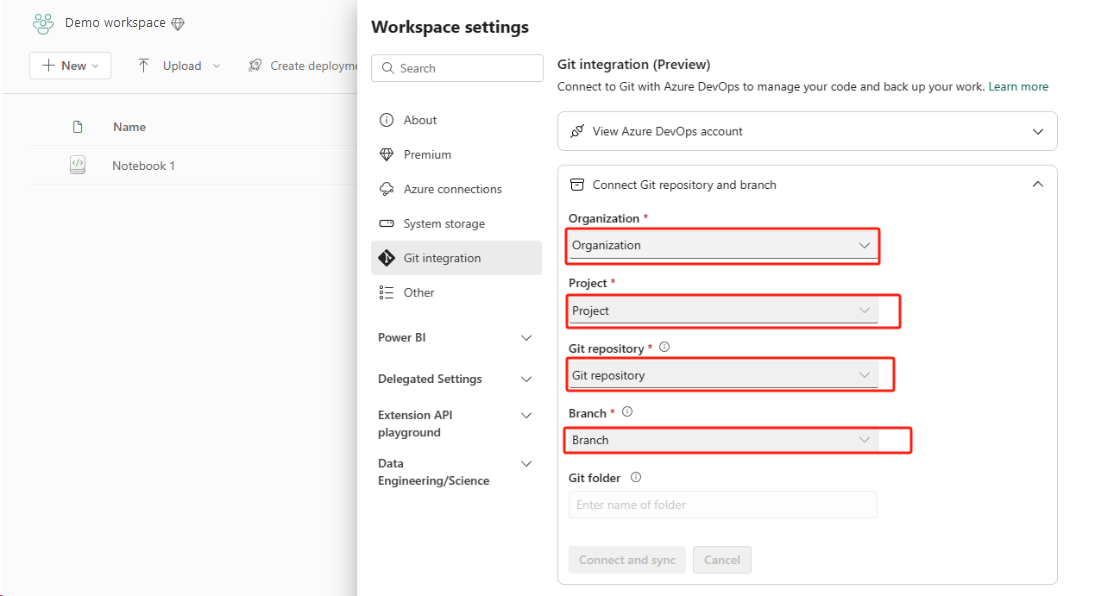
Nakonfigurujte integraci Gitu pro váš pracovní prostor a vyberte Připojit a synchronizovat s úložištěm ADO.
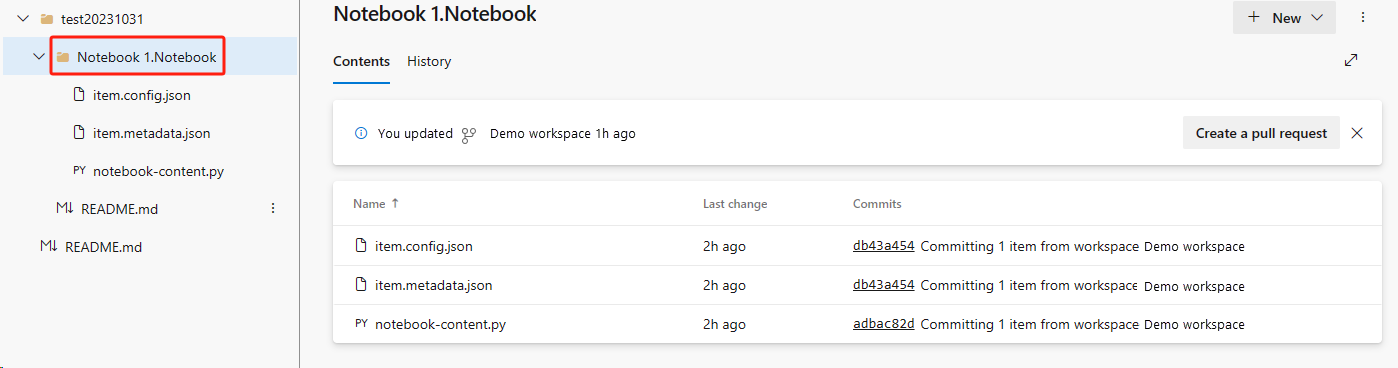
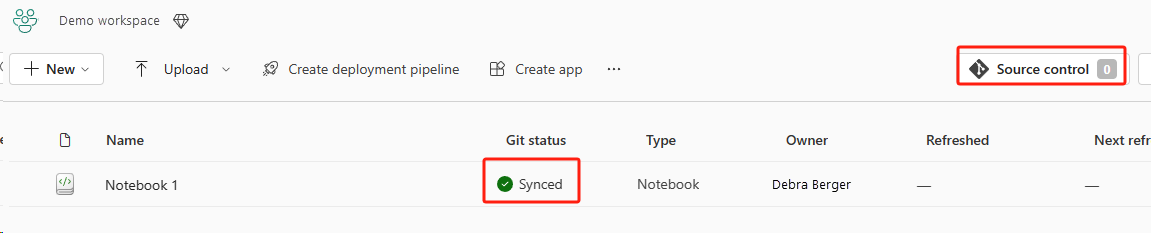
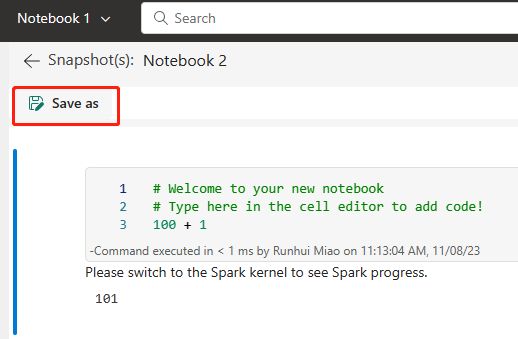
Následující obrázek znázorňuje synchronizovaný poznámkový blok.
Obnovte poznámkový blok z úložiště ADO.
V nově vytvořeném pracovním prostoru se znovu připojte ke svému Azure úložišti ADO.
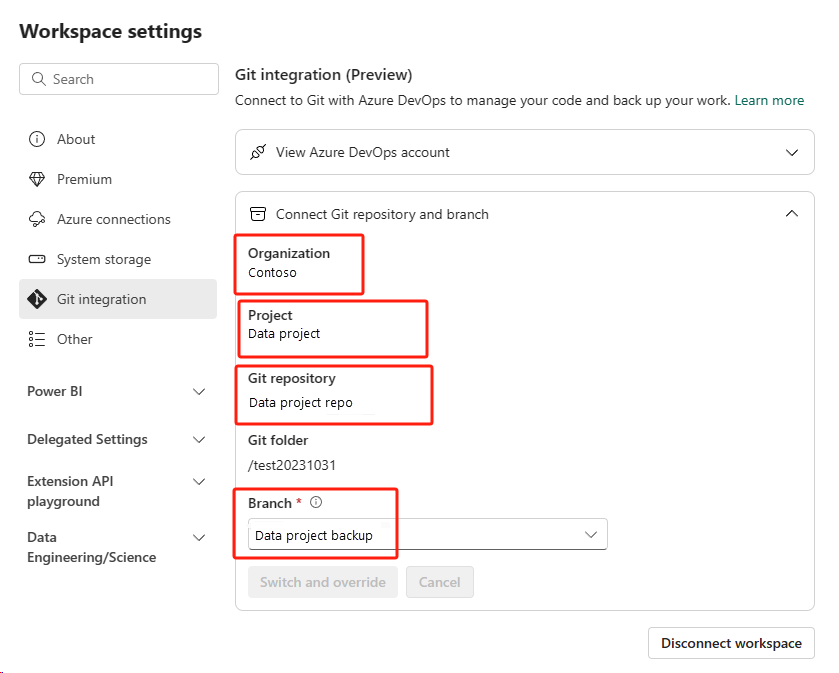
Vyberte tlačítko Správy zdrojového kódu. Pak vyberte příslušnou větev úložiště. Pak vyberte Aktualizovat vše. Zobrazí se původní poznámkový blok.
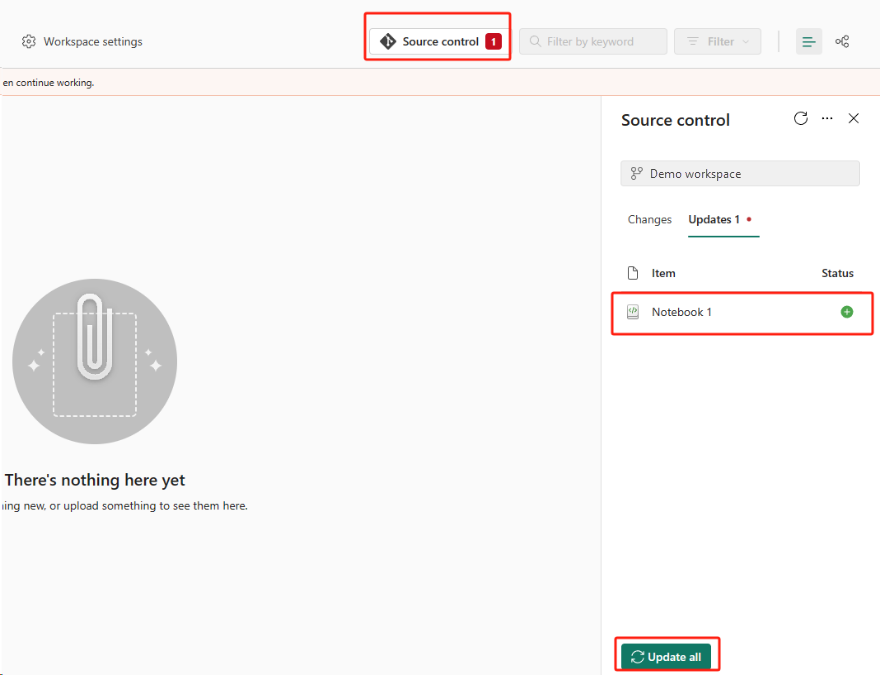
Pokud má původní poznámkový blok výchozí lakehouse, mohou uživatelé odkazovat na sekci Lakehouse a obnovit lakehouse, a potom nově obnovený lakehouse připojit k nově obnovenému poznámkovému bloku.
Integrace Gitu nepodporuje synchronizaci souborů, složek nebo snímků poznámkových bloků v Průzkumníku prostředků poznámkového bloku.
Pokud má původní poznámkový blok soubory v Průzkumníku prostředků poznámkového bloku:
Nezapomeňte uložit soubory nebo složky na místní disk nebo na jiné místo.
Znovu nahrajte soubor z místního disku nebo z cloudových jednotek do obnoveného poznámkového bloku.
Pokud má původní poznámkový blok snímek poznámkového bloku, uložte ho také do vlastního systému správy verzí nebo místního disku.
Další informace o integraci Gitu najdete v tématu Úvod do integrace Gitu.
Přístup 2: Ruční přístup k zálohování obsahu kódu
Pokud nepoužíváte přístup k integraci Gitu, můžete uložit nejnovější verzi kódu, soubory v Průzkumníku prostředků a snímek poznámkového bloku do systému správy verzí, jako je Git, a po havárii ručně obnovit obsah poznámkového bloku:
Pomocí funkce Importovat poznámkový blok naimportujte kód poznámkového bloku, který chcete obnovit.
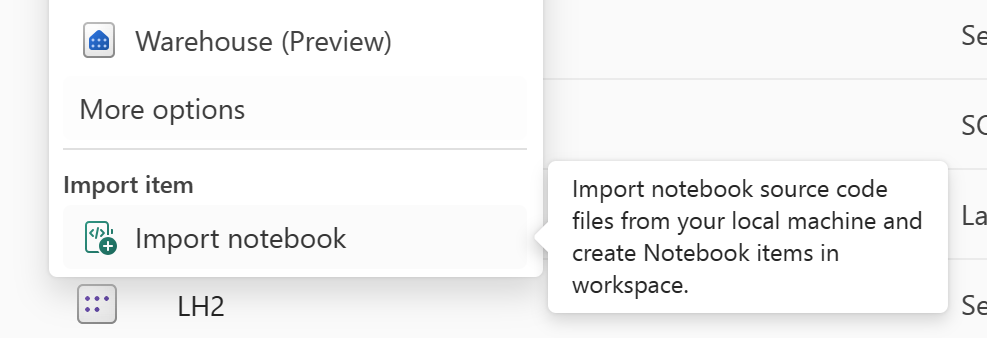
Po importu přejděte do požadovaného pracovního prostoru (například C2. W2") pro přístup k němu.
Pokud má původní poznámkový blok výchozí Lakehouse, odkazujte na sekci Lakehouse. Pak připojte nově obnovený datový úložiště (které má stejný obsah jako původní výchozí lakehouse) k nově obnovenému notebooku.
Pokud má původní poznámkový blok soubory nebo složky v Prohlížeči prostředků, znovu nahrajte soubory nebo složky uložené v uživatelském systému řízení verzí.
Definice úlohy Sparku
Definice úloh Sparku (SJD) z primární oblasti zůstávají pro zákazníky nedostupné a hlavní definiční soubor a referenční soubor v poznámkovém bloku se replikují do sekundární oblasti prostřednictvím OneLake. Pokud chcete obnovit SJD v nové oblasti, můžete provést ruční kroky popsané níže. Historická spuštění SJD se neobnoví.
Položky SJD můžete obnovit zkopírováním kódu z původní oblasti pomocí Azure Storage Explorer a ručním opětovným připojením odkazů Lakehouse po havárii.
V novém pracovním prostoru C2 vytvořte novou položku SJD (například SJD1). W2 se stejnými nastaveními a konfiguracemi jako původní položka SJD (například jazyk, prostředí atd.).
Pomocí Azure Storage Explorer zkopírujte knihovny, hlavní objekty a snímky z původní položky SJD do nové položky SJD.
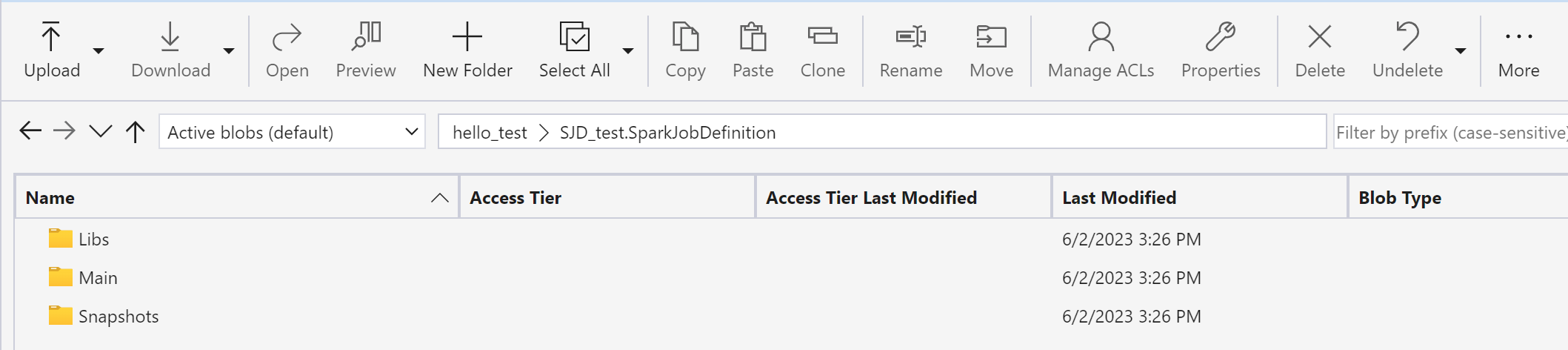
Obsah kódu se zobrazí v nově vytvořené SJD. K úloze budete muset ručně přidat nově obnovený odkaz na Lakehouse (viz kroky obnovení Lakehouse). Uživatelé budou muset znovu zadat původní argumenty příkazového řádku ručně.
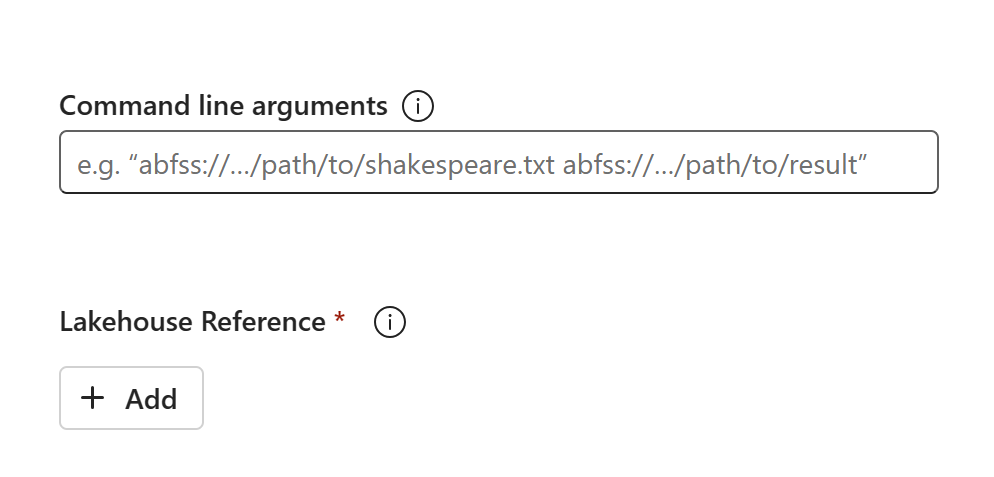
Teď můžete spustit nebo naplánovat nově obnovenou SJD.
Podrobnosti o Azure Storage Explorer najdete v tématu Integrace OneLake s Azure Storage Explorer.
Datová Věda
Tato příručka vás provede postupy obnovení pro prostředí Data Science. Zahrnuje modely ML a experimenty.
ML model a experiment
Položky vědy o datech z primární oblasti zůstanou pro zákazníky nedostupné a obsah a metadata v modelech ML a experimentech se nebudou replikovat do sekundární oblasti. Pokud je chcete plně obnovit v nové oblasti, uložte obsah kódu do systému správy verzí (například Git) a po havárii ručně znovu spusťte obsah kódu.
Obnovte poznámkový blok. Projděte si kroky obnovení poznámkového bloku.
Konfigurace, historicky spuštěné metriky a metadata se nebudou replikovat do spárované oblasti. Abyste mohli plně obnovit modely ML a experimenty po havárii, budete muset znovu spustit každou verzi kódu datové vědy.
Data Warehouse
Tato příručka vás provede postupy obnovení pro Data Warehouse prostředí. Pokrývá sklady.
Sklad
Sklady z původní oblasti zůstanou zákazníkům nedostupné. K obnovení skladů použijte následující dva kroky.
Vytvořte nový dočasný lakehouse v pracovním prostoru C2.W2 pro data, která zkopírujete z původního datového skladu.
Naplňte tabulky Delta skladu využitím Průzkumníka skladu a možností T-SQL (viz Tables v datových skladech v Microsoft Fabric).
Poznámka:
Doporučujeme, abyste kód skladu (schéma, tabulku, zobrazení, uloženou proceduru, definice funkcí a kódy zabezpečení) ponechal ve verzi a uložili ho do bezpečného umístění (jako je Git) v souladu s vašimi postupy vývoje.
Příjem dat přes Lakehouse a kód T-SQL
V nově vytvořeném pracovním prostoru C2. W2:
Vytvořte dočasné jezero "LH2" v C2. W2.
Pomocí kroků obnovení Lakehouse obnovte tabulky Delta v dočasném lakehouse z původního skladu.
V jazyce C2 vytvořte nový sklad WH2. W2.
Připojte dočasné jezero v průzkumníku skladu.
V závislosti na tom, jak nasadíte definice tabulek před importem dat, se skutečný T-SQL použitý pro import může lišit. K obnovení tabulek Warehouse z lakehouse můžete použít přístup INSERT INTO, SELECT INTO nebo CREATE TABLE AS SELECT. Dále bychom v tomto příkladu používali příchuť INSERT INTO. (Pokud použijete následující kód, nahraďte ukázky skutečnými názvy tabulek a sloupců.
USE WH1 INSERT INTO [dbo].[aggregate_sale_by_date_city]([Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit]) SELECT [Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit] FROM [LH11].[dbo].[aggregate_sale_by_date_city] GONakonec změňte připojovací řetězec v aplikacích, které používají váš Fabric sklad.
Poznámka:
Zákazníkům, kteří potřebují zotavení po havárii mezi oblastmi a plně automatizovanou kontinuitu podnikových procesů, doporučujeme udržovat dvě nastavení Fabric Warehouse v samostatných Fabric oblastech a udržovat paritu kódu a dat díky pravidelnému nasazení a příjmu dat do obou lokalit.
Zrcadlené databáze
Zrcadlené databáze z primární oblasti zůstávají pro zákazníky nedostupné a nastavení se nereplikuje do sekundární oblasti. Pokud ho chcete obnovit v případě selhání oblasti, musíte znovu vytvořit zrcadlenou databázi v jiném pracovním prostoru z jiné oblasti.
Data Factory
Položky služby Data Factory z primární oblasti zůstanou pro zákazníky nedostupné a nastavení a konfigurace v kanálech nebo položkách toku dat Gen2 se nebudou replikovat do sekundární oblasti. Pokud chcete tyto položky obnovit v případě selhání regionu, budete muset znovu vytvořit položky Integračních dat v jiném pracovním prostoru v jiném regionu. Podrobnosti najdete v následujících částech.
Datové toky Gen2
Pokud chcete obnovit položku Dataflow Gen2 v nové oblasti, musíte exportovat soubor PQT do systému správy verzí, jako je Git, a po havárii ručně obnovit obsah Toku dat Gen2.
V položce Dataflow Gen2 na kartě Domů v editoru Power Query vyberte Exportovat šablonu.
V dialogovém okně Exportovat šablonu zadejte název (povinné) a popis (volitelné) pro tuto šablonu. Jakmile budete hotovi, vyberte OK.
Po havárii vytvořte novou položku Toku dat Gen2 v novém pracovním prostoru C2. W2".
V aktuálním podokně zobrazení editoru Power Query vyberte Import ze šablony Power Query.
V dialogovém okně Otevřít přejděte do výchozí složky pro stahování a vyberte soubor .pqt , který jste uložili v předchozích krocích. Pak vyberte Otevřít.
Šablona se pak naimportuje do nové položky Toku dat Gen2.
Funkce Uložit jako u toků dat není podporována v případě obnovy po havárii.
Pipelines
Zákazníci nemají přístup k kanálům v případě regionální havárie a konfigurace se nereplikují do spárované oblasti. Doporučujeme vytvářet kritická potrubí v několika pracovních prostorech v různých regionech.
Úloha kopírování
Uživatelé služby CopyJob musí provádět proaktivní opatření k ochraně před regionální katastrofou. Následující přístup zajišťuje, že po regionální havárii zůstanou uživatelovy CopyJobs dostupné.
Redundance spravovaná uživatelem s integrací Gitu (ve verzi Public Preview)
Nejlepší způsob, jak tento proces rychle a snadno usnadnit, je použít integraci s Fabric Gitem a poté synchronizovat CopyJob se svým úložištěm ADO. Poté, co služba selže a přejde do jiné oblasti, můžete úložiště použít k opětovnému sestavení úlohy CopyJob v novém pracovním prostoru, který jste vytvořili.
Nakonfigurujte integraci Gitu v pracovním prostoru a vyberte spojte a synchronizujte s úložištěm ADO.
Následující obrázek ukazuje synchronizovanou úlohu CopyJob.
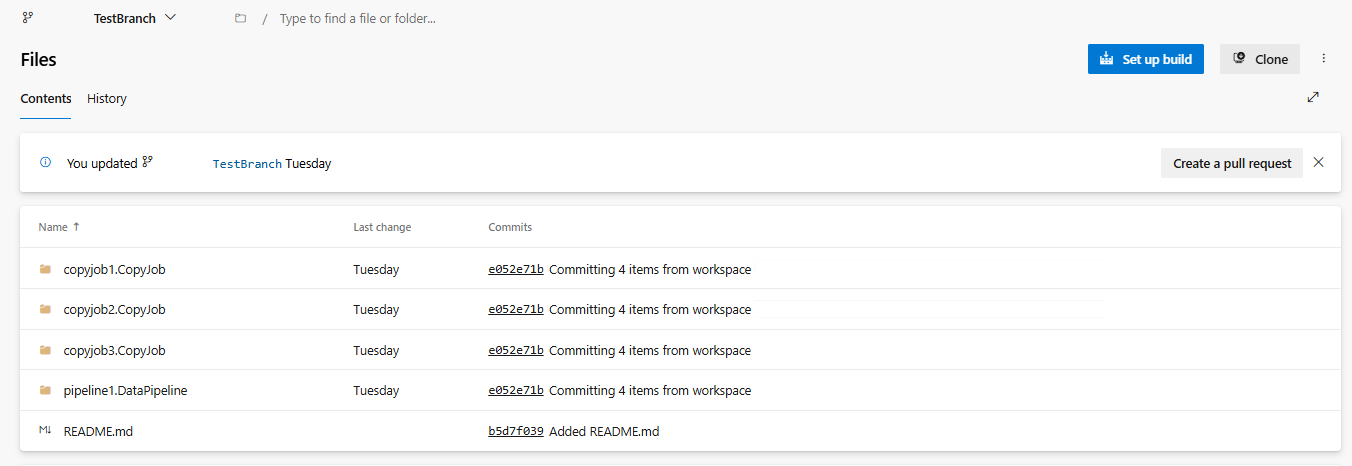
Obnovte úlohu CopyJob z úložiště ADO.
V nově vytvořeném pracovním prostoru se znovu připojte a synchronizujte s úložištěm Azure ADO. Všechny Fabric položky v tomto úložišti se automaticky stáhnou do nového pracovního prostoru.
Pokud původní CopyJob používá službu Lakehouse, mohou uživatelé odkazovat na oddíl Lakehouse, aby obnovili Lakehouse, a poté připojit nově obnovený CopyJob k nově obnovené službě Lakehouse.
Další informace o integraci Gitu najdete v tématu Úvod do integrace Gitu.
Úloha Apache Airflow
Uživatelé, kteří pracují s úlohami Apache Airflow v rámci platformy Fabric, musí provádět proaktivní opatření k ochraně před regionální katastrofou.
Doporučujeme spravovat redundanci pomocí integrace Fabric Gitu. Nejprve synchronizujte úlohu Airflow s úložištěm ADO. Pokud služba přepne při selhání do jiného regionu, můžete pomocí úložiště znovu sestavit úlohu Airflow v novém pracovním prostoru, který jste vytvořili.
Tady je postup, jak toho dosáhnout:
Nakonfigurujte integraci systému Git ve vašem pracovním prostoru a vyberte možnost „připojit a synchronizovat“ s úložištěm ADO.
Potom uvidíte, že se vaše úloha Airflow synchronizovala s vaším úložištěm ADO.
Pokud potřebujete obnovit úlohu Airflow z úložiště ADO, vytvořte nový pracovní prostor, připojte se a synchronizujte s úložištěm Azure ADO znovu. Všechny položky Fabricu, včetně Airflow, budou automaticky staženy do vašeho nového pracovního prostoru.
Analýza v reálném čase
Tato příručka vás provede postupy obnovy pro zážitek z inteligentních funkcí v reálném čase. Zabývá se databázemi a sadami dotazů KQL a datovými proudy událostí.
Grafový model/Queryset
Položky grafového modelu a sady dotazů grafu z primární oblasti zůstanou zákazníkům nedostupné a tyto položky se nereplikují do sekundární oblasti. Pokud chcete provést obnovení, vytvořte nebo použijte kapacitu v jiné oblasti a znovu vytvořte položky grafového modelu a sady dotazů grafů.
Vytvořte nebo použijte existující kapacitu Fabric v jiném regionu, který nebyl ovlivněn havárií.
Vytvořte nový pracovní prostor nebo použijte existující pracovní prostor v této kapacitě.
Znovu vytvořte položku modelu grafu v sekundárním pracovním prostoru (odkazované v kroku 2). Překonfigurujte definici modelu, včetně uzlů, hran atd., tak, aby odpovídala původnímu grafu modelu.
Pokud je původní lakehouse v selhávající oblasti, nejprve ji obnovte podle části Lakehouse.
Připojte lakehouse jako zdroj dat OneLake pro nově vytvořenou položku Graph Model. Použijte obnovený lakehouse, pokud byl v selhávající oblasti, nebo se znovu připojte k existujícímu lakehouse, pokud zůstane k dispozici.
Překonfigurujte plány načítání dat nebo připojení pro grafový model v novém pracovním prostoru.
Znovu vytvořte položku Graph Queryset v sekundárním pracovním prostoru. Ručně znovu zadejte dotazy a všechny uložené konfigurace dotazů z původní sady Graph Queryset.
Databáze nebo sada dotazů KQL
Uživatelé databáze nebo sady dotazů KQL musí provádět proaktivní opatření k ochraně před regionální katastrofou. Následující přístup zajistí, že v případě regionální havárie zůstanou data v databázích KQL bezpečná a přístupná.
Následující postup vám umožní zaručit efektivní řešení zotavení po havárii pro databáze a sady dotazů KQL.
Konfigurujte nezávislé databáze KQL: Nakonfigurujte dvě nebo více nezávislých databází AQL nebo sad dotazů pro vyhrazené kapacity Fabric. Ty by se měly nastavit napříč dvěma různými regiony Azure (nejlépe spárované regiony Azure) pro maximalizaci odolnosti.
Replikace aktivit správy: Všechny akce správy provedené v jedné databázi KQL by se měly zrcadlit v druhé. Tím zajistíte, že obě databáze zůstanou synchronizované. Mezi klíčové aktivity, které se mají replikovat, patří:
Tabulky: Ujistěte se, že struktury tabulek a definice schématu jsou v databázích konzistentní.
Mapování: Duplikuje všechna požadovaná mapování. Ujistěte se, že zdroje a cíle dat odpovídají správně.
Zásady: Ujistěte se, že obě databáze mají podobné uchovávání dat, přístup a další relevantní zásady.
Správa ověřování a autorizace: Pro každou repliku nastavte požadovaná oprávnění. Ujistěte se, že jsou zavedeny správné úrovně autorizace, které poskytují přístup požadovaným pracovníkům při zachování standardů zabezpečení.
Paralelní příjem dat: Aby byla data konzistentní a připravená ve více oblastech, načtěte stejnou datovou sadu do každé databáze KQL současně s příjmem dat.
Eventstream
Eventstream je centralizované místo na platformě Fabric pro zachytávání, transformaci a směrování událostí v reálném čase do různých cílů (například lakehouses, databází a sad dotazů KQL) s prostředím bez nutnosti kódování. Pokud jsou cíle podporovány zotavením po havárii, streamy událostí nepřijdou o data. Zákazníci by proto měli využít možnosti zotavení po havárii těchto cílových systémů k zajištění dostupnosti dat.
Zákazníci mohou také dosáhnout geografické redundance nasazením identických úloh Eventstream do více regionů Azure v rámci aktivní/aktivní strategie pro více lokalit. Díky multisitovému aktivnímu/aktivnímu přístupu můžou zákazníci přistupovat ke svým pracovním zátěžím v libovolné z nasazených oblastí. Tento přístup je nejsložitější a nákladnější přístup k zotavení po havárii, ale ve většině situací může zkrátit dobu obnovení na téměř nulu. Aby byli zákazníci plně geograficky zálohovaní, mohou
Vytvořte repliky svých zdrojů dat v různých oblastech.
Vytvořte položky eventstreamu v odpovídajících oblastech.
Připojte tyto nové položky ke stejným zdrojům dat.
Přidejte identické cíle pro každý eventstream v různých oblastech.
Map
Položky mapování z primární oblasti zůstanou pro zákazníky nedostupné a položky mapy se nereplikují do sekundární oblasti.
Pokud chcete obnovit položku Mapy, když dojde k havárii, nastavte integraci Gitu s Fabricem a synchronizujte položku Mapy s vaším Git úložištěm.
Během obnovení, po nastavení nové oblasti nebo kapacity ve Fabricu, můžete použít repozitář k obnovení položky mapy v novém pracovním prostoru, který jste vytvořili. Vzhledem k tomu, že je nový pracovní prostor prázdný, Git sync získá obsah z úložiště do prázdného pracovního prostoru. Tento krok vrátí položku mapy zpět do života.
Poznámka:
Pokud má původní položka mapy nakonfigurovanou sadu dotazů lakehouse nebo KQL, projděte si část Lakehouse a oddíl sady dotazů KQL a nejprve je obnovte. Po vyřešení těchto závislostí připojte nově obnovený lakehouse a sadu dotazů k nově obnovenému Map objektu.
Ontologie
Uživatelé ontologie musí podniknout proaktivní kroky k přípravě na regionální zotavení po havárii. Níže popsaný přístup zajišťuje, že po regionální havárii zůstane vaše ontologie obnovitelná a dá se rychle obnovit.
Nejjednodušším a nejrychlejším způsobem, jak povolit obnovení, je použít integraci Fabric Gitu a synchronizovat vaši ontologii s úložištěm Azure DevOps (ADO). Pokud služba přejde při selhání do jiného regionu, můžete toto úložiště použít k opětovnému sestavení Ontologie v nově vytvořeném pracovním prostoru.
Položky ontologie v primární oblasti nejsou k dispozici zákazníkům po havárii v oblasti a položky ontologie se nereplikují do sekundární oblasti.
Pokud chcete obnovit položku ontologie během havárie, nakonfigurujte integraci Fabric Git a synchronizujte položku ontologie s úložištěm ADO předem.
Během obnovení můžete po nastavení nové oblasti a kapacity v Fabric použít úložiště k opětovnému sestavení položky ontologie v novém pracovním prostoru. Vzhledem k tomu, že nový pracovní prostor je prázdný, Git sync načte obsah z úložiště do pracovního prostoru a efektivně obnoví položku Ontology.
Poznámka:
Pokud má původní položka ontologie nakonfigurovaný lakehouse, nejprve se podívejte do části Lakehouse a obnovte ho. Po vyřešení těchto závislostí připojte nově obnovený lakehouse k nově obnovené ontologické položce.
Transakční databáze
Tato příručka popisuje postupy obnovení pro prostředí transakční databáze.
databáze SQL
Kvůli ochraně před regionálním selháním můžou uživatelé databází SQL provádět proaktivní opatření k pravidelnému exportu dat a k opětovnému vytvoření databáze v novém pracovním prostoru v případě potřeby použít exportovaná data.
Toho lze dosáhnout pomocí nástroje SqlPackage CLI, který poskytuje přenositelnost databáze a usnadňuje nasazení databází.
- K exportu databáze do
.bacpacsouboru použijte nástroj SqlPackage. Další podrobnosti najdete v tématu Export databáze pomocí sqlPackage . -
.bacpacUložte soubor do zabezpečeného umístění, které je v jiné oblasti než databáze. Mezi příklady patří uložení souboru.bacpacdo lakehouse, který je v jiné oblasti, pomocí geograficky redundantního účtu Azure Storage nebo pomocí jiného zabezpečeného média úložiště, které je v jiné oblasti. - Pokud databáze SQL a oblast nejsou k dispozici, můžete soubor s sqlPackage použít
.bacpack opětovnému vytvoření databáze v pracovním prostoru v nové oblasti – Pracovní prostor C2. W2 v oblasti B, jak je popsáno ve výše uvedeném scénáři. Postupujte podle kroků popsaných v části Import databáze pomocí sqlPackage a znovu vytvořte databázi se souborem.bacpac.
Znovu vytvořená databáze je nezávislá databáze z původní databáze a odráží stav dat v době operace exportu.
Úvahy o návratu k původnímu stavu po přepnutí systému
Znovu vytvořená databáze je nezávislá databáze. Data přidaná do znovu vytvořených databází se v původní databázi neprojeví. Pokud plánujete návrat k původní databázi, jakmile bude domovská oblast dostupná, budete muset zvážit ruční sloučení dat z nově vytvořené databáze do původní databáze.
Platforma
Platforma odkazuje na základní sdílené služby a architekturu, které platí pro všechny úlohy. Tato část vás provede postupy obnovení pro sdílené zážitky. Pokrývá knihovny proměnných.
Knihovna proměnných
Microsoft Fabric knihovny proměnných umožňují vývojářům přizpůsobit a sdílet konfigurace položek v rámci pracovního prostoru, které zjednodušují správu životního cyklu obsahu. Z hlediska zotavení po havárii se musí uživatelé knihovny proměnných aktivně chránit proti regionální katastrofě. Toto lze provést prostřednictvím integrace Fabric Gitu, která zajišťuje, že po regionální katastrofě zůstane knihovna proměnných uživatele dostupná. Pokud chcete obnovit knihovnu proměnných, doporučujeme následující:
Pomocí integrace Gitu ve Fabricu synchronizujte svou knihovnu proměnných s ADO repozitářem. V případě havárie můžete pomocí úložiště znovu sestavit knihovnu proměnných v novém pracovním prostoru, který jste vytvořili. Použijte následující kroky:
- Připojte svůj pracovní prostor k úložišti Git, jak je popsáno tady.
- Nezapomeňte zachovat synchronizaci WS a úložiště s potvrzením a aktualizací.
- Obnovení – V případě havárie použijte úložiště k opětovnému sestavení knihovny proměnných v novém pracovním prostoru:
V nově vytvořeném pracovním prostoru se znovu připojte a synchronizujte s úložištěm Azure ADO.
Všechny Fabric položky v tomto úložišti se automaticky stáhnou do nového pracovního prostoru.
Po synchronizaci položek z Gitu otevřete knihovny proměnných v novém pracovním prostoru a ručně vyberte požadovanou sadu aktivních hodnot.
Klíče spravované zákazníkem pro pracovní prostory Fabric
Pomocí klíčů spravovaných zákazníkem (CMK) uložených v Azure Key Vault můžete přidat další vrstvu šifrování nad klíči spravovanými Microsoft pro neaktivní uložená data. V případě, že se Fabric stane nepřístupným nebo nefunkčním v určité oblasti, jeho komponenty přejdou na záložní instanci. Funkce CMK podporuje při přepínání služeb jen operace pro čtení. Dokud služba Azure Key Vault zůstane v pořádku a oprávnění k trezoru zůstanou nedotčená, Fabric se bude dál připojovat k vašemu klíči a umožní vám normální čtení dat. To znamená, že během přepnutí při selhání nejsou podporované následující operace: povolení nastavení CMK v pracovním prostoru, zakázání nastavení CMK v pracovním prostoru a aktualizace klíče.