Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Přepněte služby pomocí rozevíracího seznamu Verze . Přečtěte si další informace o navigaci.
Platí pro: ✅ Microsoft Fabric ✅ Azure Data Explorer ✅ Azure Monitor ✅ Microsoft Sentinel
Cloudové služby a zařízení IoT generují telemetrii, pomocí které můžete získat přehled o stavu služeb, produkčních procesech a trendech využití. Analýza časových řad pomáhá identifikovat odchylky od typických směrných vzorů.
Jazyk Kusto Query Language (KQL) má nativní podporu pro vytváření, manipulaci a analýzu více časových řad. Tento článek ukazuje, jak pomocí jazyka KQL vytvořit a analyzovat tisíce časových řad v sekundách, abyste umožnili řešení a pracovní postupy monitorování téměř v reálném čase.
Vytvoření časové řady
Vytvořte velkou sadu běžných časových řad pomocí operátoru make-series a podle potřeby vyplňte chybějící hodnoty.
Rozdělte a transformujte tabulku telemetrie na sadu časových řad. Tabulka obvykle obsahuje sloupec časového razítka, kontextové dimenze a volitelné metriky. Dimenze se používají k rozdělení dat. Cílem je vytvořit tisíce časových řad pro každý oddíl v pravidelných časových intervalech.
Vstupní tabulka demo_make_series1 obsahuje 600 tisíc záznamů libovolného provozu webové služby. K výběru 10 záznamů použijte následující příkaz:
demo_make_series1 | take 10
Výsledná tabulka obsahuje sloupec časového razítka, tři sloupce kontextové dimenze a žádné metriky:
| Časové razítko | BrowserVer | OsVer | Země/oblast |
|---|---|---|---|
| 2016-08-25 09:12:35.4020000 | Chrome 51.0 | Windows 7 | Spojené království |
| 2016-08-25 09:12:41.1120000 | Chrome 52.0 | Systém Windows 10 | |
| 2016-08-25 09:12:46.2300000 | Chrome 52.0 | Windows 7 | Spojené království |
| 2016-08-25 09:12:46.5100000 | Chrome 52.0 | Systém Windows 10 | Spojené království |
| 2016-08-25 09:12:46.5570000 | Chrome 52.0 | Systém Windows 10 | Litevská republika |
| 2016-08-25 09:12:47.0470000 | Chrome 52.0 | Windows 8.1 | Indie |
| 2016-08-25 09:12:51.3600000 | Chrome 52.0 | Systém Windows 10 | Spojené království |
| 2016-08-25 09:12:51.6930000 | Chrome 52.0 | Windows 7 | Nizozemsko |
| 2016-08-25 09:12:56.4240000 | Chrome 52.0 | Systém Windows 10 | Spojené království |
| 2016-08-25 09:13:08.7230000 | Chrome 52.0 | Systém Windows 10 | Indie |
Vzhledem k tomu, že neexistují žádné metriky, sestavte časové řady představující počet přístupů, rozdělené podle operačního systému.
let min_t = toscalar(demo_make_series1 | summarize min(TimeStamp));
let max_t = toscalar(demo_make_series1 | summarize max(TimeStamp));
demo_make_series1
| make-series num=count() default=0 on TimeStamp from min_t to max_t step 1h by OsVer
| render timechart
- Pomocí operátoru
make-seriesvytvořte tři časové řady, kde:-
num=count(): počet přenosů. -
from min_t to max_t step 1h: Vytvoří časovou řadu v hodinových úsecích od nejstaršího po nejnovější časové razítko v tabulce. -
default=0: Určuje metodu vyplnění pro chybějící koše k vytvoření pravidelné časové řady. Alternativně můžete použítseries_fill_const(),series_fill_forward(),series_fill_backward()aseries_fill_linear()pro jiné chování výplně. -
by OsVer: oddíly podle operačního systému.
-
- Datová struktura časových řad je číselná matice agregovaných hodnot pro každý časový interval. Používá se
render timechartpro vizualizaci.
Tabulka výše obsahuje tři oddíly (Windows 10, Windows 7 a Windows 8.1). Graf zobrazuje samostatnou časovou řadu pro každou verzi operačního systému:

Analytické funkce časových řad
V této části provedeme typické funkce zpracování řad. Po vytvoření sady časových řad podporuje KQL rostoucí seznam funkcí pro zpracování a analýzu. Pro zpracování a analýzu časových řad popíšeme několik reprezentativních funkcí.
Filtrování
Filtrování je běžný postup při zpracování signálu a užitečný pro úlohy zpracování časových řad (například hladký signál, detekce změn).
- Existují dvě obecné funkce filtrování:
-
series_fir(): Použití filtru FIR. Používá se pro jednoduchý výpočet klouzavého průměru a rozlišení časových řad pro detekci změn. -
series_iir(): Použití filtru IIR. Používá se pro exponenciální vyhlazování a kumulativní součet.
-
-
Extendčasové řady určené přidáním nové řady klouzavého průměru velikosti 5 binů (pojmenovaných ma_num) do dotazu:
let min_t = toscalar(demo_make_series1 | summarize min(TimeStamp));
let max_t = toscalar(demo_make_series1 | summarize max(TimeStamp));
demo_make_series1
| make-series num=count() default=0 on TimeStamp from min_t to max_t step 1h by OsVer
| extend ma_num=series_fir(num, repeat(1, 5), true, true)
| render timechart

Regresní analýza
Segmentovaná lineární regresní analýza se dá použít k odhadu trendu časové řady.
- Použijte series_fit_line() k přizpůsobení nejlepší čáry na časovou řadu pro obecnou detekci trendu.
- Pomocí series_fit_2lines() můžete detekovat změny trendu vzhledem ke základní linii, které jsou užitečné pro monitorovací scénáře.
Příklad funkcí series_fit_line() a series_fit_2lines() na dotazu časové řady:
demo_series2
| extend series_fit_2lines(y), series_fit_line(y)
| render linechart with(xcolumn=x)

- Modrá: původní časová řada
- Zelená: fitovaná čára
- Červená: dvě fitované čáry
Poznámka:
Funkce přesně zjistila bod skoku (změna úrovně).
Detekce sezónnosti
Mnoho metrik sleduje sezónní (periodické) vzory. Uživatelský provoz cloudových služeb obvykle obsahuje denní a týdenní vzory, které jsou nejvyšší uprostřed pracovního dne a nejnižší v noci a o víkendu. Senzory IoT měří v pravidelných intervalech. Fyzická měření, jako je teplota, tlak nebo vlhkost, můžou také ukazovat sezónní chování.
Následující příklad používá detekci sezónnosti u jednoměsíčního provozu webové služby (2hodinové intervaly):
demo_series3
| render timechart

- Pomocí series_periods_detect() můžete automaticky zjišťovat období v časové řadě, kde:
-
num: časová řada k analýze -
0.: minimální délka období ve dnech (0 znamená bez minimální délky) -
14d/2h: maximální délka období ve dnech, což je 14 dnů rozdělených do dvouhodinových intervalů -
2: počet časových intervalů, které se mají zjistit
-
- Pokud víme, že metrika by měla mít konkrétní jedinečná období a chceme ověřit, že existují, použijte series_periods_validate( ).
Poznámka:
Je to anomálie, pokud neexistují konkrétní jedinečná období.
demo_series3
| project (periods, scores) = series_periods_detect(num, 0., 14d/2h, 2) //to detect the periods in the time series
| mv-expand periods, scores
| extend days=2h*todouble(periods)/1d
| období | výsledky | Dny |
|---|---|---|
| 84 | 0.820622786055595 | 7 |
| 12 | 0.764601405803502 | 1 |
Funkce detekuje denní a týdenní sezónnost. Denní skóre je menší než týdenní, protože víkendové dny se liší od pracovních dnů.
Funkce po prvcích
Aritmetické a logické operace je možné provádět v časových řadách. Pomocí series_subtract() můžeme vypočítat reziduální časovou řadu, tedy rozdíl mezi původní nezpracovanou metrikou a vyhlazením a hledat anomálie v reziduálním signálu:
let min_t = toscalar(demo_make_series1 | summarize min(TimeStamp));
let max_t = toscalar(demo_make_series1 | summarize max(TimeStamp));
demo_make_series1
| make-series num=count() default=0 on TimeStamp from min_t to max_t step 1h by OsVer
| extend ma_num=series_fir(num, repeat(1, 5), true, true)
| extend residual_num=series_subtract(num, ma_num) //to calculate residual time series
| where OsVer == "Windows 10" // filter on Win 10 to visualize a cleaner chart
| render timechart

- Modrá: původní časová řada
- Červená: vyhlazená časová řada
- Zelená: reziduální časová řada
Pracovní postup časových řad ve velkém měřítku
Tento příklad ukazuje detekci anomálií spuštěnou ve velkém měřítku na tisících časových řad v sekundách. Pokud chcete zobrazit ukázkové záznamy telemetrie pro metriku počtu čtení služby DB za čtyři dny, spusťte následující dotaz:
demo_many_series1
| take 4
| ČASOVÁ ZNAČKA | Místo | Op | databáze | Čtení dat |
|---|---|---|---|---|
| 2016-09-11 21:00:00.0000000 | Loc 9 | 5117853934049630089 | 262 | 0 |
| 2016-09-11 21:00:00.0000000 | Loc 9 | 5117853934049630089 | 241 | 0 |
| 2016-09-11 21:00:00.0000000 | Loc 9 | -865998331941149874 | 262 | 279862 |
| 2016-09-11 21:00:00.0000000 | Loc 9 | 371921734563783410 | 255 | 0 |
Zobrazení jednoduchých statistik:
demo_many_series1
| summarize num=count(), min_t=min(TIMESTAMP), max_t=max(TIMESTAMP)
| Num | min_t | maximální_čas |
|---|---|---|
| 2177472 | 2016-09-08 00:00:00.0000000 | 2016-09-11 23:00:00.0000000 |
Časová řada v hodinových intervalech metriky čtení (čtyři dny × 24 hodin = 96 bodů) zobrazuje normální hodinové kolísání:
let min_t = toscalar(demo_many_series1 | summarize min(TIMESTAMP));
let max_t = toscalar(demo_many_series1 | summarize max(TIMESTAMP));
demo_many_series1
| make-series reads=avg(DataRead) on TIMESTAMP from min_t to max_t step 1h
| render timechart with(ymin=0)

Toto chování je zavádějící, protože jedna normální časová řada se agreguje z tisíců instancí, které můžou mít neobvyklé vzory. Vytvořte časovou řadu pro každou instanci definovanou Loc (umístění), Op (operace) a DB (konkrétní počítač).
Kolik časových řad můžete vytvořit?
demo_many_series1
| summarize by Loc, Op, DB
| count
| Počet |
|---|
| 18339 |
Vytvořte 18 339 časových řad pro metriku počtu čtení. Přidejte klauzuli by do příkazu make-series, použijte lineární regresi a vyberte horní dvě časové řady s nejvýznamnějším klesajícím trendem:
let min_t = toscalar(demo_many_series1 | summarize min(TIMESTAMP));
let max_t = toscalar(demo_many_series1 | summarize max(TIMESTAMP));
demo_many_series1
| make-series reads=avg(DataRead) on TIMESTAMP from min_t to max_t step 1h by Loc, Op, DB
| extend (rsquare, slope) = series_fit_line(reads)
| top 2 by slope asc
| render timechart with(title='Service Traffic Outage for 2 instances (out of 18339)')
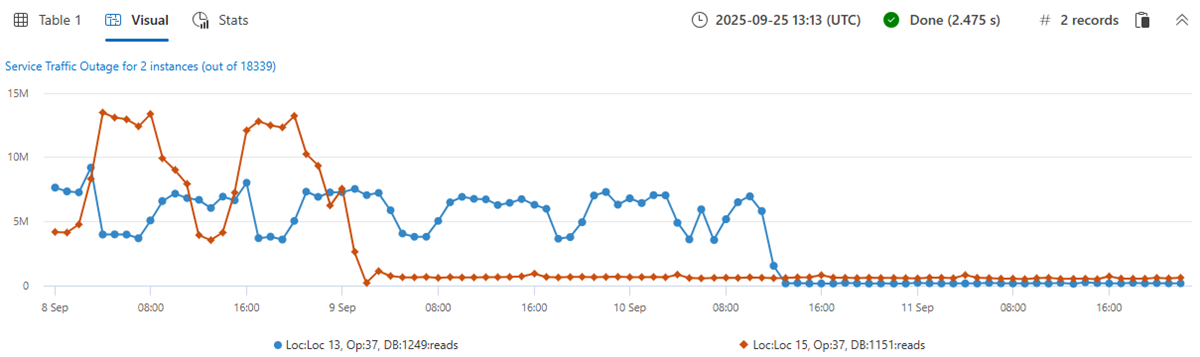
Zobrazte instance:
let min_t = toscalar(demo_many_series1 | summarize min(TIMESTAMP));
let max_t = toscalar(demo_many_series1 | summarize max(TIMESTAMP));
demo_many_series1
| make-series reads=avg(DataRead) on TIMESTAMP from min_t to max_t step 1h by Loc, Op, DB
| extend (rsquare, slope) = series_fit_line(reads)
| top 2 by slope asc
| project Loc, Op, DB, slope
| Místo | Op | databáze | svah |
|---|---|---|---|
| Loc 15 | 37 | 1151 | -104,498.46510358342 |
| Loc 13 | 37 | 1249 | -86,614.02919932814 |
Během dvou minut dotaz analyzuje téměř 20 000 časových řad a zjistí dva s náhlým poklesem počtu čtení.
Tyto funkce a výkon platformy poskytují výkonné řešení pro analýzu časových řad.
Související obsah
- Detekce a prognózy anomálií pomocí KQL
- Možnosti strojového učení s využitím KQL