Trénování modelu strukturovaného nebo volného zpracování dokumentů v Microsoft Syntex
Postupujte podle pokynů v tématu Vytvoření modelu v syntexu a vytvořte strukturovaný nebo volný model zpracování dokumentů v centru obsahu. Nebo postupujte podle pokynů v tématu Vytvoření modelu na místním sharepointovém webu a vytvořte model na místním webu. Pak použijte tento článek k trénování modelu.

Pokud chcete vytrénovat strukturovaný nebo volný model zpracování dokumentů, postupujte takto:
- Krok 1: Přidání a analýza dokumentů
- Krok 2: Označení polí a tabulek
- Krok 3: Trénování a publikování modelu
- Krok 4: Použití modelu
Krok 1: Přidání a analýza dokumentů
Po vytvoření strukturovaného nebo volného modelu zpracování dokumentů se otevře stránka Zvolit informace k extrakci . Tady zobrazíte seznam všech informací, které má model AI extrahovat z dokumentů, například Jméno, Adresa nebo Částka.
Poznámka
Když hledáte například soubory, které se mají použít, podívejte se na požadavky modelu zpracování dokumentu na vstupní dokument a tipy pro optimalizaci.
Nejprve na stránce Zvolte informace k extrakci definujete pole a tabulky, které chcete model naučit extrahovat. Podrobný postup najdete v tématu Definování polí a tabulek, které se mají extrahovat.
Můžete vytvořit tolik kolekcí rozložení dokumentů, které má model zpracovat. Podrobný postup najdete v tématu Seskupení dokumentů podle kolekcí.
Po vytvoření kolekcí a přidání aspoň pěti ukázkových souborů pro každou z nich AI Builder na serveru Syntex prozkoumá nahrané dokumenty a zjistí pole a tabulky. Tento proces obvykle trvá několik sekund. Po dokončení analýzy můžete pokračovat v označování dokumentů.
Krok 2: Označení polí a tabulek
Abyste model naučili porozumět polím a tabulkovým datům, která chcete extrahovat, musíte dokumenty označit značkami. Podrobný postup najdete v tématu Označování dokumentů.
Krok 3: Trénování a publikování modelu
Jakmile vytvoříte a vytrénujete model, můžete ho publikovat a používat v SharePointu. Pokud chcete model publikovat, vyberte Publikovat. Podrobný postup najdete v tématu trénování a publikování modelu zpracování dokumentů.
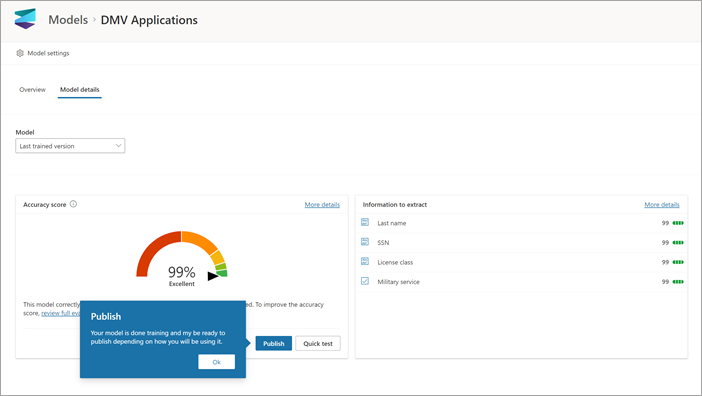
Po publikování modelu přejdete na domovskou stránku modelu. Pak budete mít možnost použít model na knihovnu dokumentů.
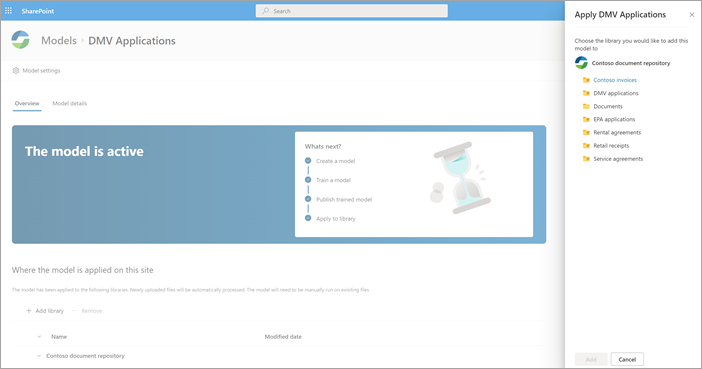
Krok 4: Použití modelu
V zobrazení modelu knihovny dokumentů si všimněte, že vybraná pole se teď zobrazují jako sloupce.
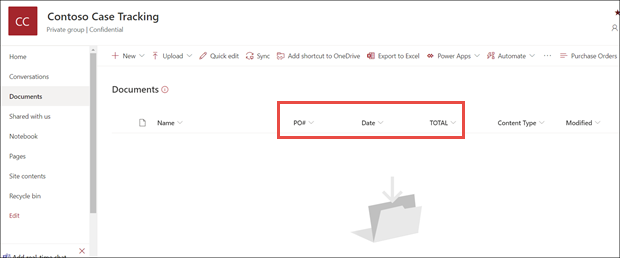
Všimněte si, že odkaz na informace vedle položky Dokumenty uvádí, že se na tuto knihovnu dokumentů používá model zpracování formulářů.
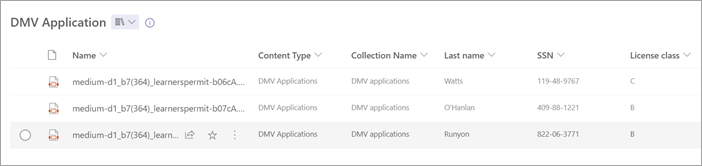
Nahrajte soubory do knihovny dokumentů. Všechny soubory, které model identifikuje jako svůj typ obsahu, vypíše soubory ve vašem zobrazení a zobrazí extrahovaná data ve sloupcích.
Poznámka
Pokud se ve stejné knihovně použije strukturovaný nebo volný model zpracování dokumentů a nestrukturovaný model zpracování dokumentů, soubor se klasifikuje pomocí nestrukturovaného modelu zpracování dokumentů a všech vytrénovaných extraktorů pro tento model. Pokud existují prázdné sloupce, které odpovídají modelu zpracování dokumentu, budou sloupce naplněny pomocí těchto extrahovaných hodnot.
Pole Data klasifikace
Při použití libovolného vlastního modelu na knihovnu dokumentů je do schématu knihovny zahrnuto pole Datum klasifikace . Ve výchozím nastavení je toto pole prázdné. Při zpracování a klasifikaci dokumentů modelem se však toto pole aktualizuje o datum a čas dokončení.
Když je model označený datem klasifikace, můžete pomocí příkazu Odeslat e-mail po zpracování toku souborů syntex upozornit uživatele, že model v knihovně dokumentů SharePointu zpracoval a klasifikoval nový soubor.
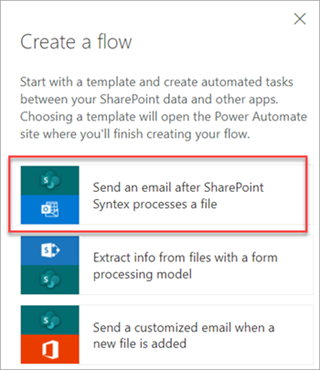
Spuštění toku:
Vyberte soubor a pak vyberte Integrovat>Power Automate>Vytvořit tok.
Na panelu Vytvořit tok vyberte Odeslat e-mail, jakmile Syntex zpracuje soubor.
Extrahování informací pomocí toků
Důležité
Informace v této části se nevztahují na nejnovější verzi syntexu. Je ponechán jako odkaz pouze pro modely zpracování formulářů, které byly vytvořeny v předchozích verzích. V nejnovější verzi už nemusíte konfigurovat toky pro zpracování existujících souborů.
K dispozici jsou dva toky pro zpracování vybraného souboru nebo dávky souborů v knihovně, ve které byl použit strukturovaný nebo volný model zpracování dokumentů.
Extrahování informací z obrázku nebo souboru PDF pomocí modelu zpracování dokumentu – Slouží k extrakci textu z vybraného obrázku nebo souboru PDF spuštěním modelu zpracování dokumentu. Podporuje současně jeden vybraný soubor a podporuje jenom soubory PDF a soubory obrázků (.png, .jpg a .jpeg). Pokud chcete tok spustit, vyberte soubor a pak vyberte Automatizovat>extrahování informací.
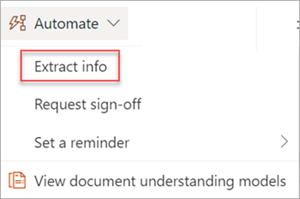
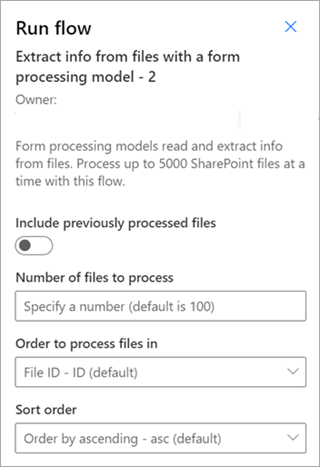
Extrahování informací ze souborů pomocí modelu zpracování dokumentů – Používá se s modely zpracování dokumentů ke čtení a extrahování informací ze dávky souborů. Zpracovává až 5 000 sharepointových souborů najednou. Při spuštění tohoto toku můžete nastavit určité parametry. Můžeš:
- Zvolte, jestli chcete zahrnout dříve zpracované soubory (výchozí nastavení není zahrnout dříve zpracované soubory).
- Vyberte počet souborů ke zpracování (výchozí hodnota je 100 souborů).
- Zadejte pořadí, ve kterém se mají soubory zpracovávat (volby jsou podle ID souboru, názvu souboru, času vytvoření souboru nebo času poslední změny).
- Určete, jak chcete pořadí seřadit (vzestupně nebo sestupně).
Poznámka
Tok Extrakce informací z obrázku nebo souboru PDF s modelem zpracování dokumentů je automaticky k dispozici pro knihovnu s přidruženým modelem zpracování dokumentů. Tok Extrakce informací ze souborů s modelem zpracování dokumentů je šablona, která se v případě potřeby musí přidat do knihovny.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro