DirectQuery v Power BI
V Power BI Desktopu nebo služba Power BI se můžete připojit k mnoha různým zdrojům dat různými způsoby. Data můžete importovat do Power BI, což je nejběžnější způsob, jak získat data. Můžete se také připojit přímo k některým datům v původním zdrojovém úložišti, které se nazývá DirectQuery. Tento článek se primárně zabývá možnostmi DirectQuery.
Tento článek popisuje:
- Různé možnosti připojení dat Power BI.
- Pokyny k použití DirectQuery místo importu
- Omezení a důsledky používání DirectQuery
- Doporučení pro úspěšné použití DirectQuery
- Postup diagnostiky problémů s výkonem DirectQuery
Článek se zaměřuje na pracovní postup DirectQuery při vytváření sestavy v Power BI Desktopu, ale také se zabývá připojením přes DirectQuery v služba Power BI.
Poznámka:
DirectQuery je také funkcí Služba Analysis Services serveru SQL. Tato funkce sdílí mnoho podrobností s DirectQuery v Power BI, ale existují i důležité rozdíly. Tento článek se primárně zabývá DirectQuery s Power BI, nikoli Služba Analysis Services serveru SQL.
Další informace o používání DirectQuery s Služba Analysis Services serveru SQL najdete v tématu Použití složených modelů v Power BI Desktopu). Můžete si také stáhnout PDF DirectQuery v SQL Serveru 2016 Analysis Services.
Režimy připojení dat Power BI
Power BI se připojuje k velkému počtu různých zdrojů dat, například:
- Online služby, jako je Salesforce a Dynamics 365.
- Databáze jako SQL Server, Access a Amazon Redshift.
- Jednoduché soubory v Excelu, JSON a dalších formátech
- Další zdroje dat, jako jsou Spark, weby a Microsoft Exchange.
Data z těchto zdrojů můžete importovat do Power BI. U některých zdrojů se můžete připojit také pomocí DirectQuery. Souhrn zdrojů, které podporují DirectQuery, najdete v tématu Zdroje dat Power BI. Zdroje s podporou DirectQuery jsou primárně zdroje, které můžou poskytovat dobrý výkon interaktivních dotazů.
Data byste měli importovat do Power BI všude, kde je to možné. Import využívá vysoce výkonný dotazovací modul Power BI a poskytuje vysoce interaktivní plně funkční prostředí.
Pokud nemůžete splnit své cíle importem dat, například pokud se data často mění a sestavy musí odrážet nejnovější data, zvažte použití DirectQuery. DirectQuery je možné pouze tehdy, když podkladový zdroj dat může poskytovat interaktivní výsledky dotazů za méně než pět sekund pro typický agregační dotaz a dokáže zpracovat vygenerované načtení dotazu. Pečlivě zvažte omezení a důsledky používání DirectQuery.
Možnosti importu a DirectQuery Power BI se v průběhu času vyvíjejí. Změny, které poskytují větší flexibilitu při použití importovaných dat, umožňují import častěji a eliminují některé nevýhody použití DirectQuery. Bez ohledu na vylepšení je při použití DirectQuery hlavním aspektem výkon podkladového zdroje dat. Pokud je podkladový zdroj dat pomalý, použití DirectQuery pro tento zdroj zůstane neproveditelné.
Následující části zahrnují tyto tři možnosti připojení k datům: import, DirectQuery a živé připojení. Zbývající část článku se zaměřuje na DirectQuery.
Import připojení
Když se připojíte ke zdroji dat, jako je SQL Server a importujete data v Power BI Desktopu, jsou k dispozici následující podmínky připojení:
Při počátečním použití funkce Získat data definuje každá sada vybraných tabulek dotaz, který vrátí sadu dat. Tyto dotazy můžete upravit před načtením dat, například použít filtry, agregovat data nebo spojit různé tabulky.
Po načtení se všechna data definovaná dotazy importují do mezipaměti Power BI.
Sestavení vizuálu v Power BI Desktopu se dotazuje na data uložená v mezipaměti. Úložiště Power BI zajišťuje, že dotaz je rychlý a že se všechny změny vizuálu projeví okamžitě.
Vizuály neodráží změny podkladových dat v úložišti dat. Abyste mohli data aktualizovat, musíte je znovu naimportovat.
Publikování sestavy do služba Power BI jako souboru .pbix vytvoří a nahraje sémantický model, který obsahuje importovaná data. Pak můžete naplánovat aktualizaci dat, aby se data každý den znovu naimportují. V závislosti na umístění původního zdroje dat může být nutné pro aktualizaci nakonfigurovat místní bránu dat.
Otevření existující sestavy nebo vytvoření nové sestavy v služba Power BI znovu dotazuje importovaná data a zajišťuje interaktivitu.
Vizuály nebo celé stránky sestavy můžete připnout jako dlaždice řídicího panelu v služba Power BI. Dlaždice se automaticky aktualizují při každé aktualizaci základního sémantického modelu.
Připojení DirectQuery
Když se pomocí DirectQuery připojíte ke zdroji dat v Power BI Desktopu, jsou k dispozici následující podmínky připojení k datům:
Zdroj vyberete pomocí funkce Získat data . U relačních zdrojů můžete stále vybrat sadu tabulek, které definují dotaz, který logicky vrátí sadu dat. U multidimenzionálních zdrojů, jako je SAP Business Warehouse (SAP BW), vyberete jenom zdroj.
Při načtení se do úložiště Power BI neimportují žádná data. Při vytváření vizuálu odesílá Power BI Desktop dotazy do podkladového zdroje dat, aby načetl potřebná data. Doba potřebná k aktualizaci vizuálu závisí na výkonu tohoto podkladového zdroje dat.
Všechny změny podkladových dat se okamžitě neprojeví v existujících vizuálech. Je stále nutné aktualizovat. Power BI Desktop znovu odešle potřebné dotazy pro každý vizuál a podle potřeby vizuál aktualizuje.
Publikování sestavy do služba Power BI vytvoří a nahraje sémantický model, který je stejný jako při importu. Tento sémantický model ale neobsahuje žádná data.
Otevření existující sestavy nebo vytvoření nové sestavy v služba Power BI dotazuje podkladový zdroj dat, aby načetl potřebná data. V závislosti na umístění původního zdroje dat může být nutné nakonfigurovat místní bránu dat pro získání dat.
Vizuály nebo celé stránky sestavy můžete připnout jako dlaždice řídicího panelu. Aby bylo zajištěno, že otevření řídicího panelu je rychlé, dlaždice se automaticky aktualizují podle plánu, například každou hodinu. Frekvenci aktualizace můžete řídit v závislosti na četnosti změn dat a důležitosti zobrazení nejnovějších dat.
Když otevřete řídicí panel, dlaždice odrážejí data v době poslední aktualizace, ne nutně nejnovější změny provedené v podkladovém zdroji. Můžete aktualizovat otevřený řídicí panel, abyste měli jistotu, že je aktuální.
Živá připojení
Když se připojíte k Služba Analysis Services serveru SQL, můžete importovat data nebo použít živé připojení k vybranému datovému modelu. Použití živého připojení je podobné DirectQuery. Neimportují se žádná data a podkladový zdroj dat se dotazuje na aktualizaci vizuálů.
Když například použijete import pro připojení k Služba Analysis Services serveru SQL, definujete dotaz na externí Služba Analysis Services serveru SQL zdroj a importujete data. Pokud se připojujete živě, nedefinujete dotaz a celý externí model se zobrazí v seznamu polí.
Tato situace platí i v případě, že se připojujete k následujícím zdrojům s výjimkou možnosti importu dat:
Sémantické modely Power BI, například připojení k sémantickému modelu Power BI, který je už ve službě publikovaný, pro vytvoření nové sestavy.
Microsoft Dataverse.
Při publikování Služba Analysis Services serveru SQL sestav, které používají živá připojení, chování v služba Power BI se podobá sestavám DirectQuery následujícími způsoby:
Otevření existující sestavy nebo vytvoření nové sestavy v služba Power BI dotazuje podkladový zdroj Služba Analysis Services serveru SQL, což může vyžadovat místní bránu dat.
Dlaždice řídicího panelu se automaticky aktualizují podle plánu, například každou hodinu.
Živé připojení se také liší od DirectQuery několika způsoby. Živá připojení například vždy předávají identitu uživatele, který sestavu otevírá, do podkladového Služba Analysis Services serveru SQL zdroje.
Případy použití DirectQuery
Připojení pomocí DirectQuery může být užitečné v následujících scénářích. V několika těchto případech je ponechání dat v původním zdrojovém umístění nezbytné nebo výhodné.
DirectQuery v Power BI nabízí největší výhody v následujících scénářích:
- Data se často mění a potřebujete vytváření sestav téměř v reálném čase.
- Musíte zpracovávat velká data, aniž byste museli předem agregovat.
- Podkladový zdroj definuje a použije pravidla zabezpečení.
- Platí omezení suverenity dat.
- Zdrojem je multidimenzionální zdroj obsahující míry, jako je SAP BW.
Často se mění data a potřebujete vytváření sestav téměř v reálném čase.
Modely s importovanými daty můžete aktualizovat maximálně jednou za hodinu nebo častěji s předplatnými Power BI Pro nebo Power BI Premium. Pokud se data neustále mění a je nutné, aby sestavy zobrazovaly nejnovější data, nemusí použití importu s plánovanou aktualizací vyhovovat vašim potřebám. Data můžete streamovat přímo do Power BI, i když pro tento případ platí omezení datových svazků.
Použití DirectQuery znamená, že otevření nebo aktualizace sestavy nebo řídicího panelu vždy zobrazuje nejnovější data ve zdroji. Dlaždice řídicího panelu je také možné aktualizovat častěji, jak často každých 15 minut.
Data jsou velmi velká
Pokud jsou data velmi velká, není možné je importovat. DirectQuery nevyžaduje velký přenos dat, protože se dotazuje na data na místě. Velké objemy dat ale můžou také zpomalovat výkon dotazů vůči danému podkladovému zdroji.
Nemusíte vždy importovat úplná podrobná data. Editor Power Query usnadňuje předběžné agregace dat během importu. Technicky vzato je možné importovat přesně agregovaná data, která potřebujete pro každý vizuál. I když je DirectQuery nejjednodušším přístupem k velkým datům, může import agregovaných dat nabídnout řešení, pokud je podkladový zdroj dat pro DirectQuery příliš pomalý.
Tyto podrobnosti se týkají samotného používání Power BI. Další informace o používání velkých modelů v Power BI najdete v tématu Velké sémantické modely v Power BI Premium. Neexistuje žádné omezení četnosti aktualizace dat.
Podkladový zdroj definuje pravidla zabezpečení.
Při importu dat se Power BI připojí ke zdroji dat pomocí přihlašovacích údajů k Power BI Desktopu aktuálního uživatele nebo přihlašovacích údajů nakonfigurovaných pro plánovanou aktualizaci z služba Power BI. Při publikováníach sestavách musíte být opatrní, abyste je mohli sdílet jenom s uživateli, kteří můžou data zobrazit, nebo je nutné definovat zabezpečení na úrovni řádků jako součást sémantického modelu.
DirectQuery umožňuje prohlížeči sestav předávat přihlašovací údaje do podkladového zdroje, který používá pravidla zabezpečení. DirectQuery podporuje jednotné přihlašování ke zdrojům dat Azure SQL a prostřednictvím brány dat k místním serverům SQL. Další informace najdete v tématu Přehled jednotného přihlašování (SSO) pro místní brány dat v Power BI.
Platí omezení suverenity dat.
Některé organizace mají zásady týkající se suverenity dat, což znamená, že data nemůžou opustit místně. Tato data představují problémy pro řešení založená na importu dat. S DirectQuery zůstanou data v podkladovém zdrojovém umístění. I v případě DirectQuery ale služba Power BI uchovává některé mezipaměti dat na úrovni vizuálu, a to kvůli plánované aktualizaci dlaždic.
Podkladový zdroj dat používá míry.
Podkladový zdroj dat, jako je SAP HANA nebo SAP BW, obsahuje míry. Míry znamenají, že importovaná data jsou již na určité úrovni agregace definovaná dotazem. Vizuál, který žádá o data na vyšší úrovni agregace, například TotalSales by Year, dále agreguje agregovanou hodnotu. Tato agregace je v pořádku u doplňkových měr, jako je suma a minimum, ale může to být problém u nesčítaných měr, například Average a DistinctCount.
Snadné získání správných agregačních dat potřebných pro vizuál přímo ze zdroje vyžaduje odesílání dotazů na vizuál stejně jako v DirectQuery. Když se připojíte k SAP BW, volba DirectQuery umožňuje tuto léčbu měr. Další informace najdete v tématu DirectQuery a SAP BW.
DirectQuery přes SAP HANA v současné době zpracovává data stejně jako relační zdroj a vytváří chování podobné importu. Další informace najdete v tématu DirectQuery a SAP HANA.
Omezení DirectQuery
Použití DirectQuery má některé potenciálně negativní důsledky. Některá z těchto omezení se mírně liší v závislosti na přesném používaném zdroji. Následující části obsahují obecné důsledky používání DirectQuery a omezení související s výkonem, zabezpečením, transformacemi, modelováním a generováním sestav.
Obecné důsledky
Některé obecné důsledky a omezení používání DirectQuery následují:
Pokud se data změní, musíte aktualizovat, aby se zobrazila nejnovější data. Vzhledem k použití mezipamětí neexistuje žádná záruka, že vizuály vždy zobrazují nejnovější data. Vizuál může například zobrazovat transakce za poslední den. Změna průřezu může vizuál aktualizovat tak, aby zobrazoval transakce za poslední dva dny, včetně nedávných nově příchozích transakcí. Vrácení průřezu do původní hodnoty by ale mohlo vést k tomu, že se znovu zobrazí předchozí hodnota uložená v mezipaměti. Výběrem možnosti Aktualizovat vymažete všechny mezipaměti a aktualizujete všechny vizuály na stránce, aby se zobrazila nejnovější data.
Pokud se data změní, neexistuje žádná záruka konzistence mezi vizuály. Různé vizuály, ať už na stejné stránce nebo na různých stránkách, se můžou aktualizovat v různou dobu. Pokud se data v podkladovém zdroji mění, není zaručeno, že každý vizuál zobrazuje data v daném časovém okamžiku.
Vzhledem k tomu, že pro jeden vizuál může být vyžadováno více než jeden dotaz, například k získání podrobností a součtů, není zaručena ani konzistence v rámci jednoho vizuálu. Pokud chcete zaručit, že tato konzistence bude vyžadovat režii při aktualizaci všech vizuálů při každé aktualizaci vizuálu, spolu s používáním nákladných funkcí, jako je izolace snímků v podkladovém zdroji dat.
Tento problém můžete zmírnit ve velkém rozsahu tak , že vyberete Aktualizovat , aby se aktualizovaly všechny vizuály na stránce. I v režimu importu existuje podobný problém při zachování konzistence při importu dat z více tabulek.
Aby se projevily změny schématu, musíte v Power BI Desktopu provést aktualizaci. Po publikování sestavy aktualizace v služba Power BI aktualizuje vizuály v sestavě. Pokud se ale podkladové zdrojové schéma změní, služba Power BI automaticky neaktualizuje seznam dostupných polí. Pokud se tabulky nebo sloupce odeberou z podkladového zdroje, může při aktualizaci dojít k selhání dotazu. Pokud chcete aktualizovat pole v modelu tak, aby odrážela změny, musíte sestavu otevřít v Power BI Desktopu a zvolit Aktualizovat.
Limit 1 milion řádků se může vrátit pro jakýkoli dotaz. Existuje pevný limit 1 milion řádků, který se může vrátit v jakémkoli dotazu do podkladového zdroje. Tento limit obecně nemá žádné praktické důsledky a vizuály nebudou zobrazovat tolik bodů. K limitu ale může dojít v případech, kdy Power BI plně neoptimalizuje odesílané dotazy a požádá o určitý průběžný výsledek, který limit překročí.
K limitu může také dojít při vytváření vizuálu na cestě k rozumnému konečnému stavu. Pokud například existuje více než 1 milion zákazníků, může zahrnutí zákazníků a TotalSalesQuantity tomuto limitu dojít, dokud nepoužijete nějaký filtr. Chyba, která se vrátí: Sada výsledků dotazu na externí zdroj dat překročila maximální povolenou velikost řádků 1000000.
Poznámka:
Kapacity Premium umožňují překročit limit jednoho milionu řádků. Další informace naleznete v tématu Max Intermediate Row Set Count.
Model z importu nemůžete změnit do režimu DirectQuery. Pokud importujete všechna potřebná data, můžete model přepnout z režimu DirectQuery na režim importu. Není možné přepnout zpět do režimu DirectQuery, a to především kvůli sadě funkcí, kterou režim DirectQuery nepodporuje. U multidimenzionálních zdrojů, jako je SAP BW, není možné přepnout z DirectQuery na režim Import ani kvůli odlišnému zacházení s externími mírami.
Dopad na výkon a zatížení
Při použití DirectQuery závisí celkové prostředí na výkonu podkladového zdroje dat. Pokud aktualizace každého vizuálu, například po změně hodnoty průřezu, trvá méně než pět sekund, je tato zkušenost rozumná, i když se může zdát pomalá v porovnání s okamžitou odezvou s importovanými daty. Pokud zpomalení zdroje způsobí, že aktualizace jednotlivých vizuálů trvá déle než desítky sekund, bude prostředí nepřiměřeně špatné. Dotazy můžou dokonce vypršovat časový limit.
Spolu s výkonem podkladového zdroje má zatížení umístěné na zdroji vliv také na výkon. Každý uživatel, který otevře sdílenou sestavu, a každá dlaždice řídicího panelu, která se aktualizuje, odešle do podkladového zdroje aspoň jeden dotaz na vizuál. Zdroj musí být schopen takové zatížení dotazu zpracovat a přitom zachovat přiměřený výkon.
Vliv na zabezpečení
Pokud podkladový zdroj dat nepoužívá jednotné přihlašování, sestava DirectQuery vždy používá stejné pevné přihlašovací údaje pro připojení ke zdroji, jakmile je publikovaná do služba Power BI. Ihned po publikování sestavy DirectQuery musíte nakonfigurovat přihlašovací údaje uživatele, který má použít. Dokud nenakonfigurujete přihlašovací údaje, při pokusu o otevření sestavy v služba Power BI dojde k chybě.
Jakmile zadáte přihlašovací údaje uživatele, Power BI tyto přihlašovací údaje použije pro každého, kdo sestavu otevře, stejně jako pro importovaná data. Každý uživatel vidí stejná data, pokud není v sestavě definováno zabezpečení na úrovni řádků. Musíte věnovat stejnou pozornost sdílení sestavy jako u importovaných dat, i když jsou v podkladovém zdroji definovaná pravidla zabezpečení.
Připojení k sémantickým modelům Power BI a Analysis Services v režimu DirectQuery vždy používá jednotné přihlašování, takže zabezpečení se podobá živým připojením ke službě Analysis Services.
Alternativní přihlašovací údaje se nepodporují při vytváření připojení DirectQuery k SQL Serveru z Power BI Desktopu. Můžete použít aktuální přihlašovací údaje windows nebo přihlašovací údaje databáze.
V modelu DirectQuery můžete použít více zdrojů dat pomocí složených modelů. Když používáte více zdrojů dat, je důležité pochopit, jaký vliv má zabezpečení na to, jak se data mezi podkladovými zdroji dat pohybují tam a zpět.
Omezení transformace dat
DirectQuery omezuje transformace dat, které můžete použít v rámci Editor Power Query. S importovanými daty můžete snadno použít sofistikovanou sadu transformací, abyste data před vytvořením vizuálů vyčistili a přeformulili. Můžete například analyzovat dokumenty JSON nebo kontingenční data ze sloupce do formuláře řádku. Tyto transformace jsou v DirectQuery omezenější.
Když se připojíte ke zdroji online analytického zpracování (OLAP), jako je SAP BW, nemůžete definovat žádné transformace a celý externí model se převezme ze zdroje. U relačních zdrojů, jako je SQL Server, můžete stále definovat sadu transformací na dotaz, ale tyto transformace jsou omezené z důvodů výkonu.
Všechny transformace musí být použity u každého dotazu na podkladový zdroj, nikoli jednou při aktualizaci dat. Transformace musí být schopny přiměřeně překládat do jednoho nativního dotazu. Pokud použijete transformaci, která je příliš složitá, zobrazí se chyba s informací, že je nutné ji odstranit nebo že se model připojení musí přepnout na import.
Dialogové okno Načíst data nebo Editor Power Query použít dílčí výběry v dotazech, které vygenerují a odesílají, aby se načetla data vizuálu. Dotazy definované v Editor Power Query musí být v tomto kontextu platné. Konkrétně není možné použít dotaz s běžnými výrazy tabulky ani dotaz, který vyvolává uložené procedury.
Omezení modelování
Pojem modelování v tomto kontextu znamená zpřesnění a rozšiřování nezpracovaných dat v rámci vytváření sestavy pomocí těchto dat. Mezi příklady modelování patří:
- Definování relací mezi tabulkami
- Přidání nových výpočtů, jako jsou počítané sloupce a míry
- Přejmenování a skrytí sloupců a měr
- Definování hierarchií
- Definování formátování sloupců, výchozí shrnutí a pořadí řazení
- Seskupování nebo seskupení hodnot.
Při použití DirectQuery můžete stále provádět mnoho z těchto rozšíření modelu a použít princip obohacení nezpracovaných dat ke zlepšení pozdější spotřeby. Některé možnosti modelování ale nejsou k dispozici nebo jsou omezené na DirectQuery. Omezení se použijí, aby nedocházelo k problémům s výkonem.
Pro všechny zdroje DirectQuery platí následující omezení. Na jednotlivé zdroje se můžou vztahovat další omezení.
Žádná předdefinovaná hierarchie kalendářních dat: Při importovaných datech má každý sloupec date/datetime ve výchozím nastavení také integrovanou hierarchii kalendářních dat. Pokud například importujete tabulku prodejních objednávek, která obsahuje sloupec DatumObjednávky a ve vizuálu použijete DatumObjednávky, můžete zvolit odpovídající úroveň data, kterou chcete použít, například rok, měsíc nebo den. Tato předdefinovaná hierarchie kalendářních dat není v DirectQuery dostupná. Pokud je v podkladovém zdroji dostupná tabulka kalendářních dat, jak je běžné v mnoha datových skladech, můžete jako obvykle použít funkce časového měřítka DAX (Data Analysis Expressions).
Podpora data a času pouze na úrovni sekund: U sémantických modelů, které používají časové sloupce, power BI vydává dotazy na podkladový zdroj DirectQuery pouze až do úrovně podrobností sekund, nikoli milisekund. Odeberte data milisekund ze zdrojových sloupců.
Omezení v počítaných sloupcích: Počítané sloupce můžou být pouze uvnitř řádku, tj. mohou odkazovat pouze na hodnoty jiných sloupců stejné tabulky bez použití agregačních funkcí. Povolené skalární funkce jazyka DAX, například
LEFT(), jsou také omezené na ty funkce, které lze odeslat do podkladového zdroje. Funkce se liší v závislosti na přesných možnostech zdroje. Funkce, které nejsou podporované, nejsou uvedené v automatickém dokončování při vytváření dotazu DAX pro počítaný sloupec a v případě použití dojde k chybě.Nepodporuje funkce DAX nadřazenosti a podřízenosti: V režimu DirectQuery není možné používat řadu
DAX PATH()funkcí, které obvykle zpracovávají struktury nadřazený-podřízený, například grafy účtů nebo hierarchie zaměstnanců.Bez clusteringu: Pokud používáte DirectQuery, nemůžete pomocí funkce clusteringu automaticky najít skupiny.
Omezení vytváření sestav
U modelů DirectQuery se podporuje téměř všechny možnosti vytváření sestav. Pokud podkladový zdroj nabízí vhodnou úroveň výkonu, můžete použít stejnou sadu vizualizací jako pro importovaná data.
Jedním z obecných omezení je, že maximální délka dat v textovém sloupci pro sémantické modely DirectQuery je 32 764 znaků. Hlášení delších textů způsobí chybu.
Následující možnosti vytváření sestav Power BI můžou způsobit problémy s výkonem v sestavách založených na DirectQuery:
Filtry měr: Vizuály, které používají míry nebo agregace sloupců, můžou v těchto mírách obsahovat filtry. Například následující obrázek zobrazuje SalesAmount by Category (Částka prodeje podle kategorie), ale pouze pro kategorie s více než 20M prodeje.
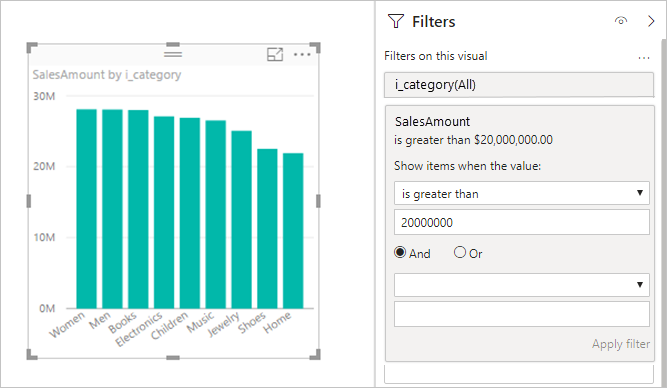
Tento přístup způsobí, že se do podkladového zdroje odešlou dva dotazy:
- První dotaz načte kategorie, které splňují podmínku SalesAmount větší než 20 milionů.
- Druhý dotaz načte potřebná data vizuálu, která zahrnují kategorie, které podmínky splnily
WHERE.
Tento přístup obecně funguje dobře, pokud existují stovky nebo tisíce kategorií, jako v tomto příkladu. Výkon může snížit, pokud je počet kategorií mnohem větší. Dotaz selže, pokud existuje více než milion kategorií.
Filtry topn: Můžete definovat rozšířené filtry, které se mají filtrovat jenom podle nejvyšších nebo nejnižších
Nhodnot seřazených podle určité míry. Filtry můžou například obsahovat prvních 10 kategorií. Tento přístup znovu odešle do podkladového zdroje dva dotazy. První dotaz však vrátí všechny kategorie z podkladového zdroje a pakTopNse určí na základě vrácených výsledků. V závislosti na kardinalitě daného sloupce může tento přístup vést k problémům s výkonem nebo selháním dotazů kvůli limitu jednoho milionu řádků u výsledků dotazu.Medián: Jakákoli agregace, například
SumneboCount Distinct, se vloží do podkladového zdroje.medianAgregace ale podkladový zdroj obvykle nepodporuje. Vmedianpřípadě se data podrobností načtou z podkladového zdroje a medián se vypočítá z vrácených výsledků. Tento přístup je přiměřený pro výpočet mediánu oproti relativně malému počtu výsledků.Problémy s výkonem nebo selhání dotazů můžou nastat, pokud je kardinalita velká kvůli limitu jednoho milionu řádků. Například dotazování na mediánovou zemi nebo populaci oblastí může být rozumné, ale medián prodejní ceny nemusí být rozumné.
Rozšířené textové filtry jako "contains": Rozšířené filtrování v textovém sloupci umožňuje filtry jako
containsabegins with. Tyto filtry můžou způsobit snížení výkonu některých zdrojů dat. Konkrétně nepoužívejte výchozícontainsfiltr, pokud potřebujete přesnou shodu. I když výsledky můžou být stejné v závislosti na skutečných datech, výkon se kvůli indexům může výrazně lišit.Průřezy s vícenásobným výběrem: Ve výchozím nastavení umožňují průřezy provádět pouze jeden výběr. Povolení vícenásobného výběru ve filtrech může způsobit problémy s výkonem. Pokud například uživatel vybere 10 zajímavých produktů, výsledkem každého nového výběru bude odeslání dotazů do zdroje. I když uživatel může vybrat další položku před dokončením dotazu, výsledkem tohoto přístupu je dodatečné zatížení podkladového zdroje.
Součty ve vizuálech tabulek: Ve výchozím nastavení se v tabulkách a maticích zobrazují součty a mezisoučty. V mnoha případech získání hodnot těchto součtů vyžaduje odesílání samostatných dotazů do podkladového zdroje. Tento požadavek platí vždy, když použijete
DistinctCountagregaci nebo ve všech případech, které používají DirectQuery přes SAP BW nebo SAP HANA. Tyto součty můžete vypnout pomocí podokna Formát .
Doporučení DirectQuery
Tato část obsahuje základní pokyny k úspěšnému použití DirectQuery vzhledem k jeho důsledkům.
Výkon podkladového zdroje dat
Ověřte, že se jednoduché vizuály aktualizují během pěti sekund a poskytují rozumné interaktivní prostředí. Pokud aktualizace vizuálů trvá déle než 30 sekund, je pravděpodobné, že další problémy po publikování sestavy způsobí, že řešení nebude možné.
Pokud jsou dotazy pomalé, prozkoumejte dotazy odeslané do podkladového zdroje a důvod pomalého výkonu. Další informace najdete v tématu Diagnostika výkonu.
Tento článek se nezabývá širokou škálou doporučení pro optimalizaci databáze v celé sadě potenciálních podkladových zdrojů. Ve většině situací platí následující standardní databázové postupy:
Kvůli lepšímu výkonu se relace založí na celočíselném sloupci místo spojení sloupců jiných datových typů.
Vytvořte odpovídající indexy. Vytváření indexů obecně znamená použití indexů úložiště sloupců ve zdrojích, které je podporují, například SQL Server.
Aktualizujte všechny potřebné statistiky ve zdroji.
Návrh modelu
Při definování modelu postupujte podle těchto pokynů:
Vyhněte se složitým dotazům v Editor Power Query. Editor Power Query přeloží složitý dotaz do jednoho dotazu SQL. Jeden dotaz se zobrazí v dílčím výběru každého dotazu odeslaného do této tabulky. Pokud je tento dotaz složitý, může dojít k problémům s výkonem u každého odeslaného dotazu. Skutečný dotaz SQL pro sadu kroků získáte tak, že kliknete pravým tlačítkem na poslední krok v části Použitý postup v Editor Power Query a zvolíte Zobrazit nativní dotaz.
Udržujte míry jednoduché. Alespoň zpočátku omezte míry na jednoduché agregace. Pokud míry fungují uspokojivým způsobem, můžete definovat složitější míry, ale věnovat pozornost výkonu.
Vyhněte se relacím u počítaných sloupců. V databázích, kde potřebujete provádět spojení s více sloupci, Power BI neumožňuje zakládat relace na více sloupcích jako primární klíč nebo cizí klíč. Běžným alternativním řešením je zřetězení sloupců pomocí počítaného sloupce a vytvoření spojení na daném sloupci.
Toto alternativní řešení je vhodné pro importovaná data, ale pro DirectQuery způsobí spojení ve výrazu. Tento výsledek obvykle brání použití jakýchkoli indexů a vede k nízkému výkonu. Jediným alternativním řešením je ve skutečnosti materializovat více sloupců do jednoho sloupce v podkladovém zdroji dat.
Vyhněte se relacím ve sloupcích uniqueidentifier. Power BI nativně nepodporuje
uniqueidentifierdatový typ. Definování relace meziuniqueidentifiersloupci vede k dotazu s spojením, které zahrnuje přetypování. Tento přístup obvykle vede k nízkému výkonu. Jediným alternativním řešením je materializovat sloupce alternativního typu v podkladovém zdroji dat.Skryjte sloupec to u relací. Sloupec
torelací je obvykle primárním klíčem vtotabulce. Tento sloupec by měl být skrytý, ale pokud je skrytý, nezobrazí se v seznamu polí a nedá se použít ve vizuálech. Sloupce, na kterých jsou relace založené, jsou ve skutečnosti systémové sloupce, například náhradní klíče v datovém skladu. Stále je nejlepší takové sloupce skrýt.Pokud sloupec má význam, představte si počítaný sloupec, který je viditelný a který má jednoduchý výraz, který se rovná primárnímu klíči, například:
ProductKey_PK (Destination of a relationship, hidden) ProductKey (= [ProductKey_PK], visible) ProductName ...Prozkoumejte všechny počítané sloupce a změny datového typu. Počítané tabulky můžete použít při použití DirectQuery se složenými modely. Tyto funkce nemusí být nutně škodlivé, ale výsledkem jsou dotazy obsahující výrazy, nikoli jednoduché odkazy na sloupce. Tyto dotazy můžou vést k tomu, že se nepoužívají indexy.
Vyhněte se obousměrnému křížovému filtrování relací. Použití obousměrného křížového filtrování může vést k příkazům dotazů, které nefungují dobře. Další informace o obousměrném křížovém filtrování najdete v tématu Povolení obousměrného křížového filtrování pro DirectQuery v Power BI Desktopu nebo stažení obousměrného křížového filtrování dokumentu white paper. Příklady v dokumentu jsou určené pro Služba Analysis Services serveru SQL, ale základní body platí i pro Power BI.
Experimentujte s nastavením Předpokládat referenční integritu. Nastavení Předpokládat referenční integritu u relací umožňuje, aby dotazy používaly
INNER JOINmístoOUTER JOINpříkazů. Tyto pokyny obecně zvyšují výkon dotazů, i když závisí na specifikách zdroje dat.Nepoužívejte v Editor Power Query filtrování relativního data. V Editor Power Query je možné definovat filtrování relativního data. Můžete například filtrovat řádky, ve kterých je datum za posledních 14 dnů.
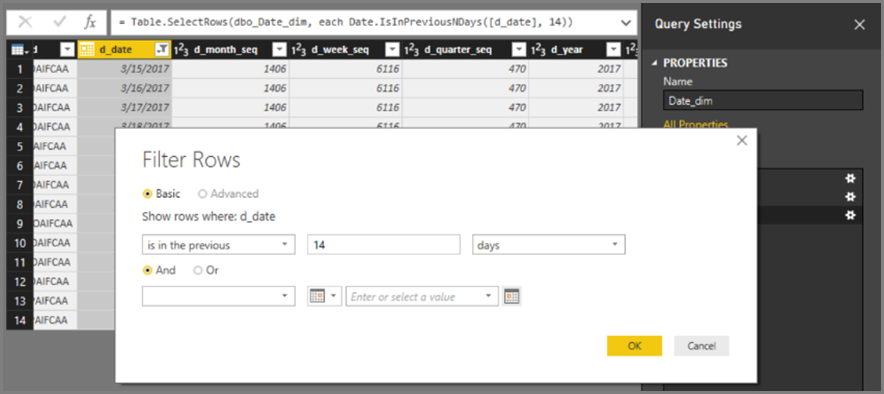
Tento filtr se ale přeloží do filtru na základě pevného data, například času vytvoření dotazu, jak můžete vidět v nativním dotazu.

Tato data pravděpodobně nejsou to, co chcete. Pokud chcete zajistit, aby se filtr použil na základě data v době spuštění sestavy, použijte v sestavě filtr kalendářních dat. Pomocí funkce můžete vytvořit počítaný sloupec, který vypočítá počet dní před
DAX DATE()funkcí, a použít tento počítaný sloupec ve filtru.
Návrh sestavy
Při vytváření sestavy, která používá připojení DirectQuery, postupujte podle těchto pokynů:
Zvažte použití možností redukce dotazů: Power BI nabízí možnosti sestavy pro odesílání méně dotazů a zakázání určitých interakcí, které způsobují špatné prostředí, pokud výsledné dotazy poběží dlouho. Tyto možnosti platí při interakci se sestavou v Power BI Desktopu a také platí, když uživatelé sestavu spotřebovávají v služba Power BI.
Pokud chcete získat přístup k těmto možnostem v Power BI Desktopu, přejděte na Možnosti souboru>a nastavení>Možnosti a vyberte Snížení počtu dotazů.
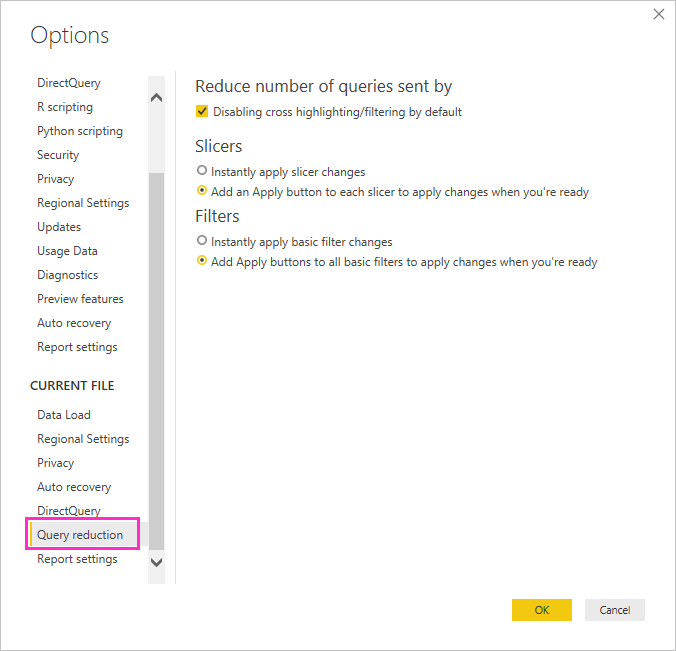
Výběry na obrazovce redukce dotazu umožňují zobrazit tlačítko Použít pro průřezy nebo výběry filtru. Dokud ve filtru nebo průřezu nevyberete tlačítko Použít , nebudou se odesílat žádné dotazy. Dotazy pak pomocí výběrů vyfiltrují data. Toto tlačítko vám umožní vytvořit několik výběrů průřezů a filtrů, než je použijete.
Nejprve použijte filtry: Vždy použijte všechny příslušné filtry na začátku vytváření vizuálu. Například místo přetažení v totalSalesAmount a ProductName a následné filtrování na určitý rok použijte filtr na Začátku roku.
Každý krok sestavení vizuálu odešle dotaz. I když je možné provést další změnu před dokončením prvního dotazu, tento přístup stále ponechá nepotřebné zatížení podkladového zdroje. Použití filtrů v rané fázi obecně snižuje náklady na tyto přechodné dotazy. Neúspěšné použití filtrů může vést k dosažení limitu jednoho milionu řádků.
Omezit počet vizuálů na stránce: Když otevřete stránku nebo změníte průřez nebo filtr na úrovni stránky, aktualizují se všechny vizuály na stránce. Počet paralelních dotazů je omezený. S rostoucím počtem vizuálů se některé vizuály aktualizují sériově, což zvyšuje dobu potřebnou k aktualizaci stránky. Proto je nejlepší omezit počet vizuálů na jedné stránce a místo toho mít více jednodušších stránek.
Zvažte vypnutí interakce mezi vizuály: Ve výchozím nastavení je možné vizualizace na stránce sestavy použít k křížovému filtrování a křížovému zvýraznění ostatních vizualizací na stránce. Pokud například ve výsečovém grafu vyberete 1999 , křížový graf se zvýrazní a zobrazí prodej podle kategorie pro 1999.
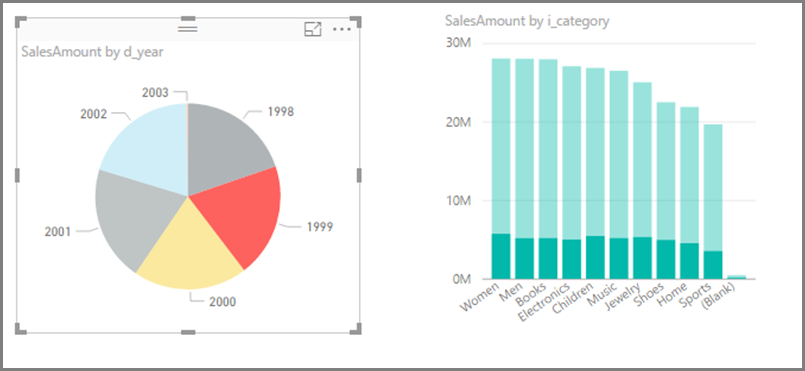
Křížové filtrování a křížové zvýraznění v DirectQuery vyžadují odeslání dotazů do podkladového zdroje. Tuto interakci byste měli vypnout, pokud je doba reakce na výběr uživatelů nepřiměřeně dlouhá.
Pomocí nastavení redukce dotazů můžete zakázat křížové zvýraznění v celé sestavě nebo případ od případu. Další informace najdete v tématu Jak se vizuály křížově filtrují v sestavě Power BI.
Maximální počet připojení
Pro každý podkladový zdroj dat můžete nastavit maximální počet připojení DirectQuery, která řídí počet dotazů současně odesílaných do každého zdroje dat.
DirectQuery otevře výchozí maximální počet 10 souběžných připojení. Pokud chcete změnit maximální počet aktuálního souboru v Power BI Desktopu, přejděte na Možnosti souboru>a Možnosti nastavení>a v části Aktuální soubor v levém podokně vyberte DirectQuery.
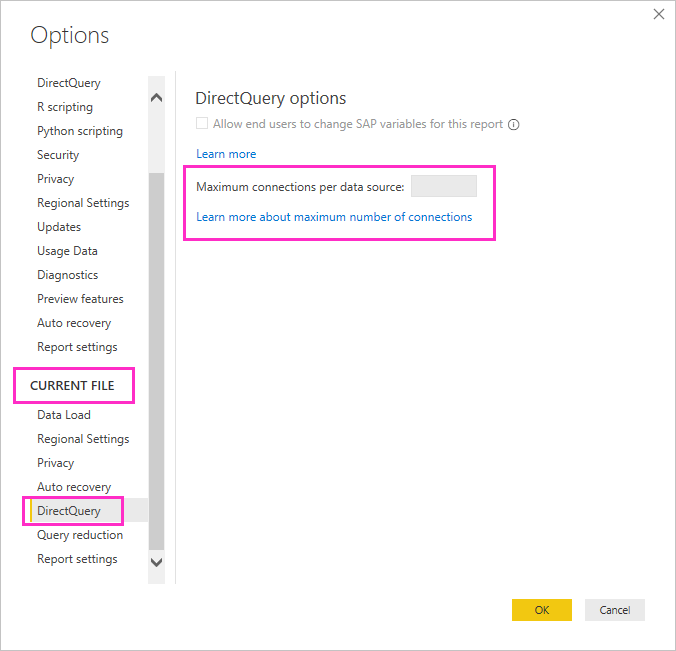
Nastavení je povoleno pouze v okamžiku, kdy je v aktuální sestavě alespoň jeden zdroj DirectQuery. Hodnota se vztahuje na všechny zdroje DirectQuery a na všechny nové zdroje DirectQuery přidané do této sestavy.
Zvýšení maximálního počtu připojení na zdroj dat umožňuje odesílat více dotazů do podkladového zdroje dat až do zadaného maximálního počtu. Tento přístup je užitečný, když je mnoho vizuálů na jedné stránce nebo mnoho uživatelů přistupuje k sestavě najednou. Po dosažení maximálního počtu připojení se další dotazy zařadí do fronty, dokud nebude připojení dostupné. Vyšší limit vede k většímu zatížení podkladového zdroje, takže není zaručeno, že se zlepší celkový výkon.
Po publikování sestavy do služba Power BI závisí maximální počet souběžných dotazů také na pevných omezeních nastavených v cílovém prostředí, ve kterém je sestava publikovaná. Power BI, Power BI Premium a Server sestav Power BI ukládají různá omezení. Následující tabulka uvádí horní limity aktivních připojení na zdroj dat pro každé prostředí Power BI. Tato omezení platí pro cloudové zdroje dat a místní zdroje dat, jako jsou SQL Server, Oracle a Teradata.
| Prostředí | Horní limit pro zdroj dat |
|---|---|
| Power BI Pro | 10 aktivních připojení |
| Power BI Premium | Závisí na omezení SKU sémantického modelu. |
| Server sestav Power BI | 10 aktivních připojení |
Poznámka:
Maximální počet připojení DirectQuery platí pro všechny zdroje DirectQuery, když povolíte rozšířená metadata, což je výchozí nastavení pro všechny modely vytvořené v Power BI Desktopu.
DirectQuery v služba Power BI
Power BI Desktop podporuje všechny zdroje dat DirectQuery a některé zdroje jsou dostupné také přímo z služba Power BI. Podnikový uživatel se může pomocí Power BI připojit ke svým datům v Salesforce, například a okamžitě získat řídicí panel bez použití Power BI Desktopu.
Přímo v služba Power BI jsou k dispozici pouze následující dva zdroje s podporou DirectQuery:
- Spark
- Azure Synapse Analytics (dříve SQL Data Warehouse)
I pro tyto dva zdroje je stále nejlepší spustit DirectQuery v Power BI Desktopu. I když je snadné na začátku vytvořit připojení v služba Power BI, existují omezení pro další vylepšení výsledné sestavy. Ve službě například není možné vytvářet žádné výpočty nebo používat mnoho analytických funkcí nebo aktualizovat metadata tak, aby odrážela změny základního schématu.
Výkon sestavy DirectQuery v služba Power BI závisí na stupni zatížení podkladového zdroje dat. Zatížení závisí na:
- Počet uživatelů, kteří sdílejí sestavu a řídicí panel
- Složitost sestavy.
- Určuje, jestli sestava definuje zabezpečení na úrovni řádků.
Chování sestavy v služba Power BI
Když otevřete sestavu v služba Power BI, aktualizují se všechny vizuály na aktuálně viditelné stránce. Každý vizuál vyžaduje alespoň jeden dotaz na podkladový zdroj dat. Některé vizuály můžou vyžadovat více než jeden dotaz. Vizuál může například zobrazit agregované hodnoty ze dvou různých tabulek faktů nebo obsahovat složitější míru nebo souhrny nesčítá míry, jako je Count Distinct. Přechod na novou stránku tyto vizuály aktualizuje. Aktualizace odešle do podkladového zdroje novou sadu dotazů.
Každá interakce uživatele v sestavě může vést k aktualizaci vizuálů. Například výběr jiné hodnoty v průřezu vyžaduje odeslání nové sady dotazů, aby se aktualizovaly všechny ovlivněné vizuály. Totéž platí pro výběr vizuálu, který křížově zvýrazní jiné vizuály nebo změní filtr. Podobně vytvoření nebo úprava sestavy vyžaduje odeslání dotazů pro každý krok na cestě k vytvoření konečného vizuálu.
Výsledky se ukládají do mezipaměti. Aktualizace vizuálu je okamžitá, pokud byly nedávno získány úplně stejné výsledky. Pokud je definováno zabezpečení na úrovni řádků, tyto mezipaměti se mezi uživateli nesdílí.
Použití DirectQuery má některá důležitá omezení v některých možnostech, které služba Power BI nabízí pro publikované sestavy:
Rychlé přehledy nejsou podporované: Rychlé přehledy Power BI prohledávají různé podmnožiny sémantického modelu a používají sadu sofistikovaných algoritmů ke zjišťování potenciálně zajímavých přehledů. Vzhledem k tomu, že rychlé přehledy vyžadují vysoce výkonné dotazy, není tato funkce dostupná u sémantických modelů, které používají DirectQuery.
Použití funkce Prozkoumat v Excelu vede k nízkému výkonu: Sémantický model můžete prozkoumat pomocí funkce Prozkoumat v Excelu , která umožňuje vytvářet kontingenční tabulky a kontingenční grafy v Excelu. Tato funkce je podporovaná pro sémantické modely, které používají DirectQuery, ale výkon je pomalejší než vytváření vizuálů v Power BI. Pokud je použití Excelu pro vaše scénáře důležité, zvažte tento problém při rozhodování, jestli se má Použít DirectQuery.
Excel nezobrazuje hierarchie: Když například použijete funkci Analyzovat v aplikaci Excel, excel nezobrazuje žádné hierarchie definované v modelech služby Azure Analysis Services ani v sémantických modelech Power BI, které používají DirectQuery.
Aktualizace řídicího panelu
V služba Power BI můžete jednotlivé vizuály nebo celé stránky připnout na řídicí panely jako dlaždice. Dlaždice založené na sémantických modelech DirectQuery se automaticky aktualizují odesláním dotazů do podkladových zdrojů dat podle plánu. Ve výchozím nastavení se sémantické modely aktualizují každou hodinu, ale jako součást nastavení sémantického modelu můžete nakonfigurovat intervaly plánu aktualizace mezi týdenním a každých 15 minut.
Pokud v modelu není definováno žádné zabezpečení na úrovni řádků, každá dlaždice se aktualizuje jednou a výsledky se sdílejí napříč všemi uživateli. Pokud používáte zabezpečení na úrovni řádků, každá dlaždice vyžaduje, aby se do podkladového zdroje odesílaly samostatné dotazy na uživatele.
Může existovat velký násobitel. Řídicí panel s 10 dlaždicemi sdílenými s 100 uživateli vytvořenými v sémantickém modelu pomocí DirectQuery se zabezpečením na úrovni řádků vede k odeslání alespoň 1 000 dotazů do podkladového zdroje dat pro každou aktualizaci. Pečlivě zvažte použití zabezpečení na úrovni řádků a konfiguraci plánu aktualizace.
Časové limity dotazů
Časový limit čtyř minut platí pro jednotlivé dotazy v služba Power BI. Dotazy, které trvá déle než čtyři minuty, selžou. Cílem tohoto limitu je zabránit problémům způsobeným příliš dlouhou dobou provádění. DirectQuery byste měli použít jenom pro zdroje, které můžou poskytovat výkon interaktivních dotazů.
Po dosažení časového limitu selhává načítání vizuálů s následující chybou: The query has exceeded the available resources. Try filtering to decrease the amount of data requested. The XML for Analysis request timed out before it was completed. Timeout value: 225 sec.
Diagnostika výkonu
Tato část popisuje, jak diagnostikovat problémy s výkonem nebo jak získat podrobnější informace pro optimalizaci sestav.
Začněte diagnostikovat problémy s výkonem v Power BI Desktopu, a ne v služba Power BI. Problémy s výkonem jsou často založené na výkonu podkladového zdroje. V izolovaném prostředí Power BI Desktopu můžete snadněji identifikovat a diagnostikovat problémy.
Tento přístup zpočátku eliminuje určité komponenty, jako je brána Power BI. Pokud v Power BI Desktopu nedochází k problémům s výkonem, můžete prozkoumat specifika sestavy v služba Power BI.
Analyzátor výkonu Power BI Desktopu je užitečný nástroj pro identifikaci problémů. Pokuste se izolovat všechny problémy s jedním vizuálem místo mnoha vizuálů na stránce. Pokud je jeden vizuál na stránce Power BI Desktopu pomalý, analyzujte dotazy, které Power BI Desktop odesílá do podkladového zdroje, pomocí analyzátoru výkonu.
Můžete také zobrazit trasování a diagnostické informace, které některé podkladové zdroje dat generují. I když zdroj neobsahuje žádné trasování, může trasovací soubor obsahovat užitečné podrobnosti o tom, jak se dotaz spustí a jak ho můžete vylepšit. Následující postup můžete použít k zobrazení dotazů, které Power BI odesílá, a jejich doby provádění.
Použití SQL Server Profileru k zobrazení dotazů
Power BI Desktop ve výchozím nastavení protokoluje události během dané relace do trasovacího souboru s názvem FlightRecorderCurrent.trc. Trasovací soubor je ve složce Power BI Desktopu pro aktuálního uživatele ve složce s názvem AnalysisServicesWorkspaces.
U některých zdrojů DirectQuery obsahuje tento trasovací soubor všechny dotazy odeslané do podkladového zdroje dat. Následující zdroje dat odesílají dotazy do protokolu:
- SQL Server
- Azure SQL Database
- Azure Synapse Analytics (dříve SQL Data Warehouse)
- Oracle
- Teradata
- SAP HANA
Trasovací soubory můžete číst pomocí NÁSTROJE SQL Server Profiler, který je součástí bezplatného stažení aplikace SQL Server Management Studio.
Otevření trasovacího souboru pro aktuální relaci:
Během relace Power BI Desktopu vyberte Možnosti souboru>a nastavení>Možnosti a pak vyberte Diagnostika.
V části Shromažďování výpisu stavu systému vyberte Otevřít složku výpisu stavu systému nebo trasování.
Otevře se složka Power BI Desktop\Traces .
Přejděte do nadřazené složky a pak do složky AnalysisServicesWorkspaces , která obsahuje jednu složku pracovního prostoru pro každou otevřenou instanci Power BI Desktopu. Tyto složky mají název s celočíselnou příponou, například AnalysisServicesWorkspace2058279583. Složka pracovního prostoru se odstraní, když skončí přidružená relace Power BI Desktopu.
Ve složce pracovního prostoru pro aktuální relaci Power BI složka \Data obsahuje trasovací soubor FlightRecorderCurrent.trc . Poznamenejte si toto místo.
Otevřete SQL Server Profiler a vyberte Soubor>Otevřít>trasovací soubor.
Přejděte nebo zadejte cestu k trasovacímu souboru pro aktuální relaci Power BI a otevřete FlightRecorderCurrent.trc.
SQL Server Profiler zobrazí všechny události z aktuální relace. Následující snímek obrazovky zvýrazní skupinu událostí dotazu. Každá skupina dotazů má následující události:
A
Query BeginaQuery Endudálost, která představuje začátek a konec dotazu DAX vygenerovaného změnou vizuálu nebo filtru v uživatelském rozhraní Power BI nebo filtrováním nebo transformací dat v Editor Power Query.Jedna nebo více dvojic
DirectQuery BeginaDirectQuery Endudálostí, které představují dotazy odeslané do podkladového zdroje dat jako součást vyhodnocení dotazu DAX.

Paralelně může běžet více dotazů DAX, takže je možné prokládání událostí z různých skupin. Pomocí hodnoty můžete ActivityID určit, které události patří do stejné skupiny.
Zajímají se také následující sloupce:
-
TextData: Textové podrobnosti události. Podrobnosti pro
Query BeginaQuery Endudálosti jsou dotazem DAX.DirectQuery BeginPodrobnostiDirectQuery Enda události jsou dotazEM SQL odesílaný do podkladového zdroje. TextData pro aktuálně vybranou událost se také zobrazí v podokně v dolní části obrazovky. - EndTime: Čas dokončení události.
- Doba trvání: Doba trvání v milisekundách trvala spuštění dotazu DAX nebo SQL.
- Chyba: Zda došlo k chybě, v takovém případě se událost zobrazuje červeně.
Zachycení trasování, které vám pomůže diagnostikovat potenciální problém s výkonem:
Otevřete jednu relaci Power BI Desktopu, abyste se vyhnuli nejasnostem více složek pracovního prostoru.
Proveďte sadu akcí, které jsou v Power BI Desktopu zajímavé. Zahrňte několik dalších akcí, abyste zajistili, že se události zájmu zaplní do trasovacího souboru.
Otevřete SQL Server Profiler a prozkoumejte trasování. Nezapomeňte, že zavření Power BI Desktopu odstraní trasovací soubor. Další akce v Power BI Desktopu se také okamžitě nezobrazí. Abyste viděli nové události, musíte trasovací soubor zavřít a znovu otevřít.
Udržujte jednotlivé relace přiměřeně malé, možná 10 sekund akcí, ne stovky. Tento přístup usnadňuje interpretaci trasovacího souboru. Existuje také omezení velikosti trasovacího souboru. U dlouhých relací existuje šance, že dojde k předčasnému vyřazení událostí.
Vysvětlení formátu dotazů
Obecný formát dotazů Power BI Desktopu používá dílčí výběry pro každou tabulku, na kterou odkazují. Dotaz Editor Power Query definuje dílčí výběr dotazů. Předpokládejme například, že máte v SQL Serveru následující tabulky TPC-DS :
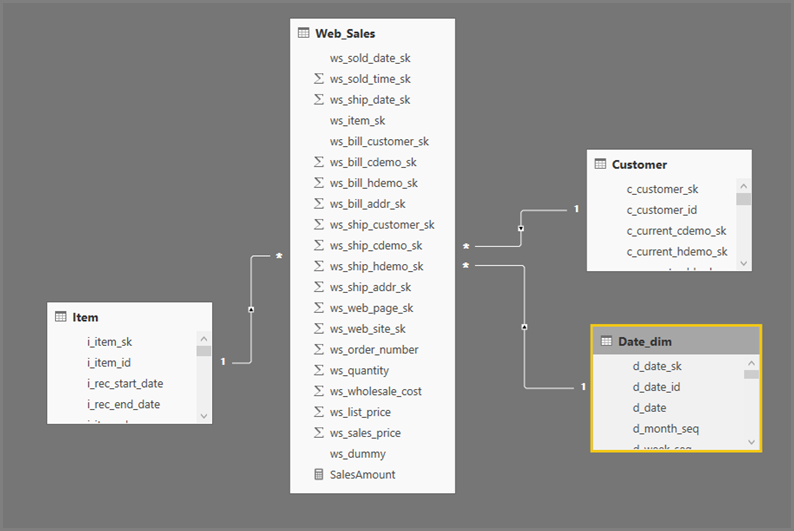
Spuštění následujícího dotazu:
SalesAmount (SUMX(Web_Sales, [ws_sales_price]*[ws_quantity]))
by Item[i_category]
for Date_dim[d_year] = 2000
Výsledkem je následující vizuál v Power BI:
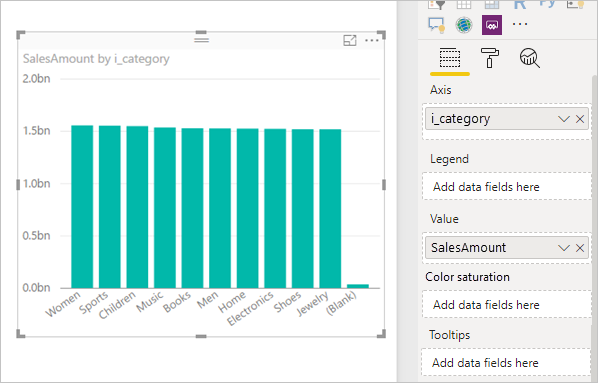
Aktualizace vizuálu vytvoří dotaz SQL na následujícím obrázku. Existují tři dílčí výběrové dotazy pro Web_Sales, Itema Date_dim, které vrátí všechny sloupce v příslušné tabulce, i když vizuál odkazuje pouze na čtyři sloupce.
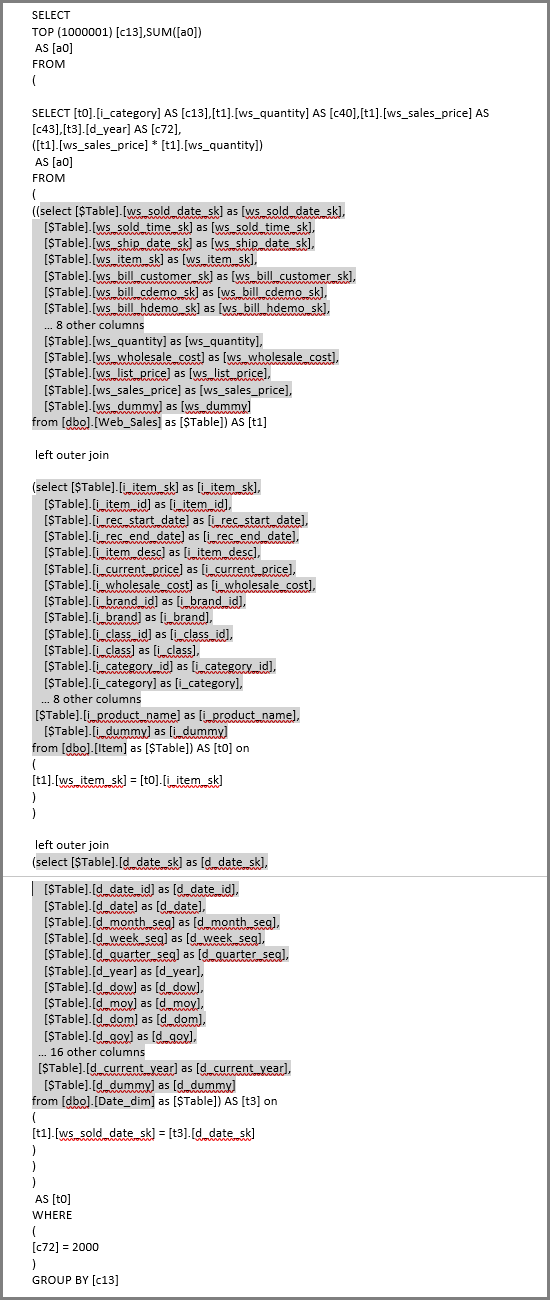
Editor Power Query definuje přesné dílčí výběrové dotazy. Toto použití dotazů dílčího výběru se nezobjevilo, aby ovlivnilo výkon pro zdroje dat, které DirectQuery podporuje. Zdroje dat, jako je SQL Server, optimalizují odkazy na ostatní sloupce.
Power BI tento model používá, protože analytik poskytuje dotaz SQL přímo. Power BI dotaz použije podle potřeby, aniž by se ho pokusil přepsat.
Související obsah
Další informace o DirectQuery v Power BI najdete tady:
Tento článek popisuje aspekty DirectQuery, které jsou společné pro všechny zdroje dat. Podrobnosti o konkrétních zdrojích najdete v následujících článcích: