Vytváření vizualizací klíčových vlivových faktorů
PLATÍ PRO:![]() Power BI Desktop
Power BI Desktop ![]() služba Power BI
služba Power BI
Vizuál klíčových vlivových faktorů vám pomůže pochopit faktory, které řídí metriku, která vás zajímá. Analyzuje vaše data, řadí faktory, které jsou důležité, a zobrazuje je jako klíčové vlivové faktory. Předpokládejme například, že chcete zjistit, co má vliv na obrat zaměstnanců, což se také označuje jako četnost změn. Jedním faktorem může být délka pracovní smlouvy a dalším faktorem může být doba dojíždět.
Kdy použít klíčové vlivové faktory
Vizuál klíčových vlivových faktorů je skvělou volbou, pokud chcete:
- Zjistěte, které faktory ovlivňují analyzovanou metriku.
- Porovnejte relativní důležitost těchto faktorů. Mají například krátkodobé smlouvy vliv na četnost změn více než dlouhodobé smlouvy?
Funkce vizuálu klíčových vlivových faktorů
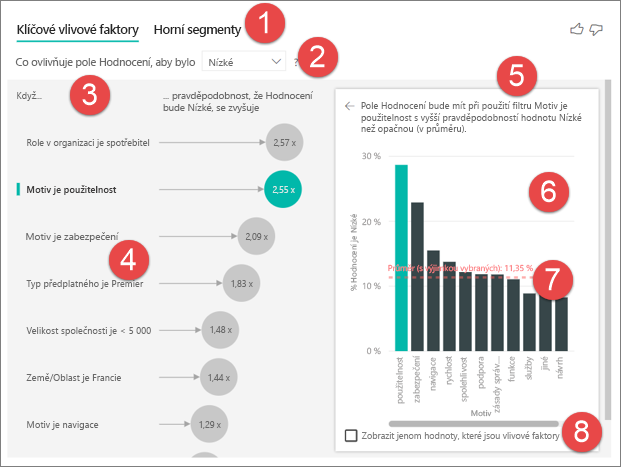
Karty: Výběrem karty můžete přepínat mezi zobrazeními. Klíčové vlivové faktory zobrazují hlavní přispěvatele vybrané hodnoty metriky. Horní segmenty zobrazují horní segmenty , které přispívají k vybrané hodnotě metriky. Segment se skládá z kombinace hodnot. Jedním segmentem může být například spotřebitelé, kteří byli zákazníky nejméně 20 let a žijí v oblasti západ.
Rozevírací seznam: Hodnota metriky, kterou prošetřete. V tomto příkladu se podívejte na hodnocení metrik. Vybraná hodnota je Nízká.
Přeformulování: Pomáhá interpretovat vizuál v levém podokně.
Levé podokno: Levé podokno obsahuje jeden vizuál. V tomto případě se v levém podokně zobrazí seznam hlavních klíčových vlivových faktorů.
Změna statistiky: Pomáhá interpretovat vizuál v pravém podokně.
Pravé podokno: Pravé podokno obsahuje jeden vizuál. V tomto případě sloupcový graf zobrazí všechny hodnoty motivu klíčového vlivového faktoru, který byl vybrán v levém podokně. Konkrétní hodnota použitelnosti z levého podokna je zobrazená zeleně. Všechny ostatní hodnoty motivu jsou zobrazeny černobílé.
Čára průměru: Průměr se vypočítá pro všechny možné hodnoty motivu s výjimkou použitelnosti (což je vybraný vlivový faktor). Výpočet se tedy vztahuje na všechny hodnoty v černé barvě. Řekne vám, jaké procento ostatních motivů mělo nízké hodnocení. V tomto případě mělo 11,35 % nízké hodnocení (zobrazené tečkovanou čárou).
Zaškrtávací políčko: Filtruje vizuál v pravém podokně tak, aby zobrazoval pouze hodnoty, které jsou vlivovými faktory pro dané pole. V tomto příkladu je vizuál filtrovaný tak, aby zobrazoval použitelnost, zabezpečení a navigaci.
Analýza metriky, která je kategorická
V tomto videu se dozvíte, jak vytvořit vizuál klíčových vlivových faktorů s metrikou kategorií. Potom ho vytvořte podle pokynů.
Poznámka:
Toto video může používat starší verze Power BI Desktopu nebo služba Power BI.
- Váš produktový manažer chce zjistit, které faktory vedou zákazníky k opuštění negativních recenzí o vaší cloudové službě. Pokud chcete postup sledovat v Power BI Desktopu , otevřete soubor PBIX pro názory zákazníků.
Poznámka:
Datová sada názorů zákazníků je založená na [Moro et al., 2014] S. Moro, P. Cortez a P. Rita. "Přístup řízený daty k predikci úspěchu bankovního telemarketingu." Decision Support Systems, Elsevier, 62:22-31, červen 2014.
V části Vytvořit vizuál v podokně Vizualizace vyberte ikonu Klíčové vlivové faktory.
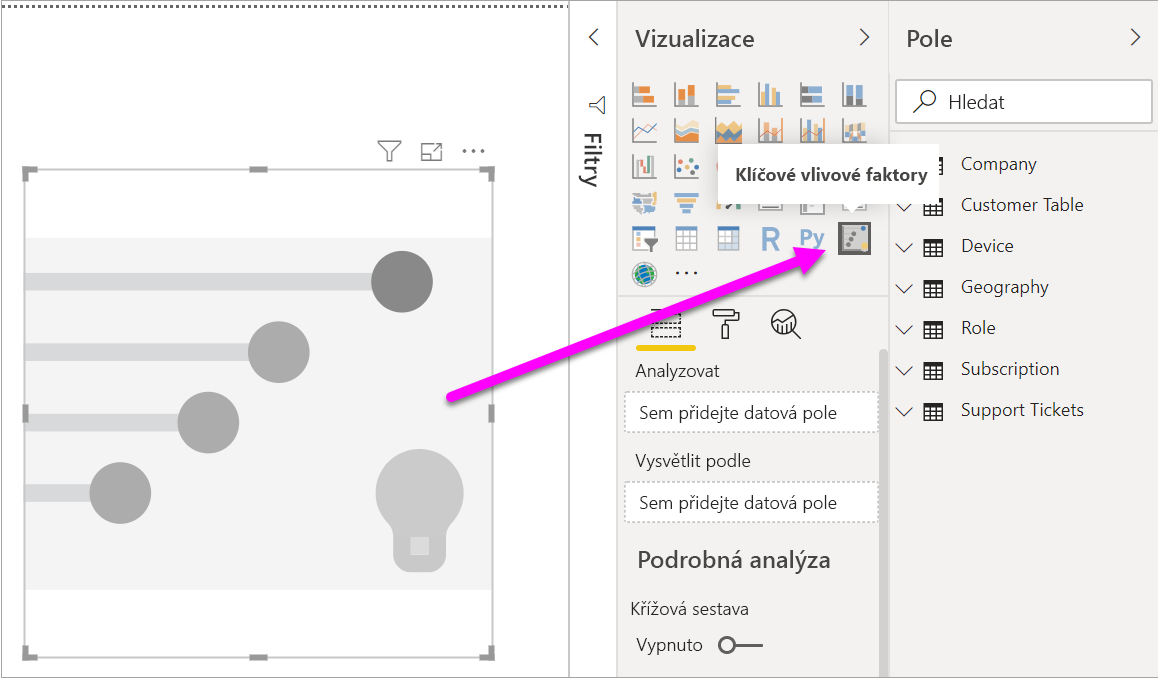
Přesuňte metriku, kterou chcete prozkoumat, do pole Analyzovat . Pokud chcete zjistit, co vede k nízkému hodnocení zákazníka služby, vyberte Hodnocení tabulky>zákazníků.
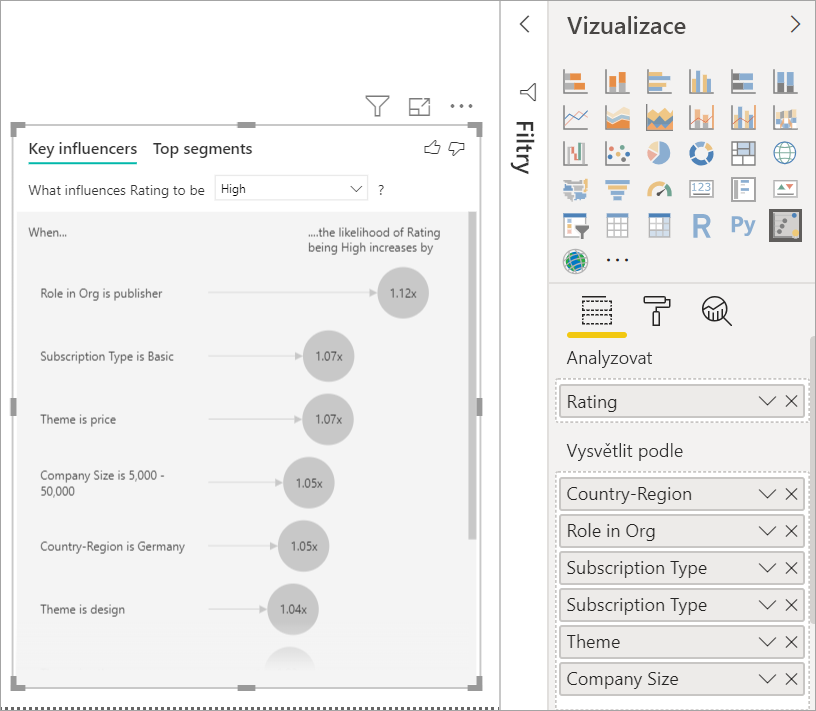
Přesuňte pole, která by podle vás mohla ovlivnit hodnocení, do pole Vysvětlit podle. Můžete přesunout libovolný počet polí. V tomto případě začněte takto:
- Country-Region (Země-oblast)
- Role v organizaci
- Typ předplatného
- Velikost společnosti
- Theme
Pole Rozbalit podle ponechte prázdné. Toto pole se používá pouze při analýze míry nebo souhrnného pole.
Pokud se chcete zaměřit na negativní hodnocení, vyberte v rozevíracím seznamu Co ovlivňuje hodnocení.
Analýza se spouští na úrovni tabulky analyzovaného pole. V tomto případě se jedná o metriku Hodnocení . Tato metrika je definována na úrovni zákazníka. Každý zákazník zadal vysoké skóre nebo nízké skóre. Všechny vysvětlující faktory musí být definovány na úrovni zákazníka, aby je vizuál využil.
V předchozím příkladu mají všechny vysvětlující faktory vztah 1:1 nebo relace M:1 s metrikou. V tomto případě každý zákazník přiřadil ke svému hodnocení jeden motiv. Podobně zákazníci pocházejí z jedné země nebo oblasti, mají jeden typ členství a mají jednu roli ve své organizaci. Vysvětlující faktory jsou již atributy zákazníka a nejsou potřeba žádné transformace. Vizuál je může okamžitě používat.
Později v tomto kurzu se podíváte na složitější příklady, které mají relace 1:N. V takových případech je potřeba nejprve agregovat sloupce na úrovni zákazníka, než budete moct analýzu spustit.
Míry a agregace používané jako vysvětlující faktory se také vyhodnocují na úrovni tabulky metriky Analyzovat . Některé příklady jsou uvedeny dále v tomto článku.
Interpretace klíčových vlivových faktorů kategorií
Pojďme se podívat na klíčové vlivové faktory s nízkými hodnoceními.
Hlavní jeden faktor, který ovlivňuje pravděpodobnost nízkého hodnocení
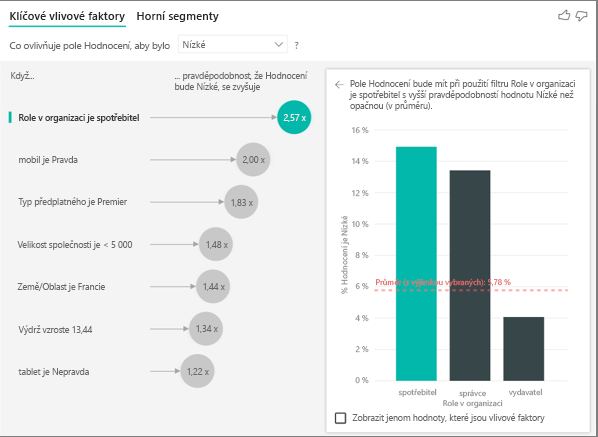
Zákazník v tomto příkladu může mít tři role: příjemce, správce a vydavatele. Uživatel je hlavním faktorem, který přispívá k nízkému hodnocení.
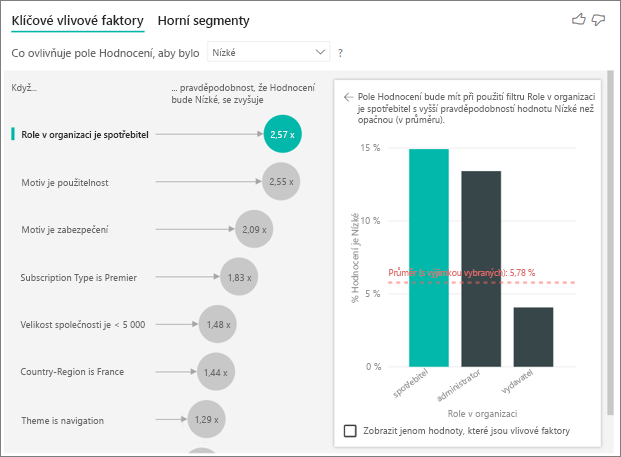
Přesněji řečeno, vaši spotřebitelé jsou 2,57krát pravděpodobnější, že vaše služba poskytne záporné skóre. Graf klíčových vlivových faktorů uvádí role v organizaci jako první v seznamu na levé straně. Výběrem role v organizaci je uživatel, Power BI zobrazí v pravém podokně další podrobnosti. Zobrazí se srovnávací účinek každé role na pravděpodobnost nízkého hodnocení.
- 14,93 % spotřebitelů dává nízké skóre.
- V průměru všechny ostatní role poskytují nízké skóre 5,78 % času.
- Spotřebitelé mají 2,57krát větší pravděpodobnost, že v porovnání se všemi ostatními rolemi poskytnou nízké skóre. Toto skóre můžete určit rozdělením zeleného pruhu červenou tečkovanou čárou.
Druhý jediný faktor, který ovlivňuje pravděpodobnost nízkého hodnocení
Vizuál klíčových vlivových faktorů porovnává a řadí faktory z mnoha různých proměnných. Druhý vlivový faktor nemá nic společného s rolí v organizaci. V seznamu vyberte druhý vlivový faktor, což je motiv použitelnosti.
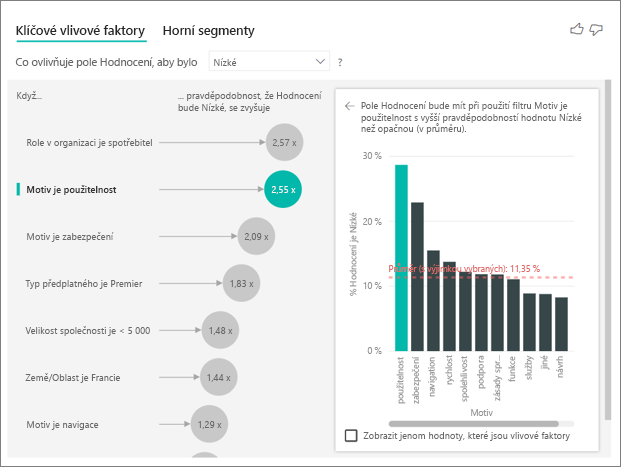
Druhý nejdůležitější faktor souvisí s motivem kontroly zákazníka. Zákazníci, kteří vyjádřili komentář k použitelnosti produktu, byli 2,55krát pravděpodobnější, že v porovnání s zákazníky, kteří komentovali jiné motivy, jako je spolehlivost, návrh nebo rychlost.
Mezi vizuály se průměr zobrazený červenou tečkovanou čárou změnil z 5,78 % na 11,35 %. Průměr je dynamický, protože je založený na průměru všech ostatních hodnot. U prvního vlivového faktoru průměr vyloučil roli zákazníka. U druhého vlivového faktoru vyloučil motiv použitelnosti.
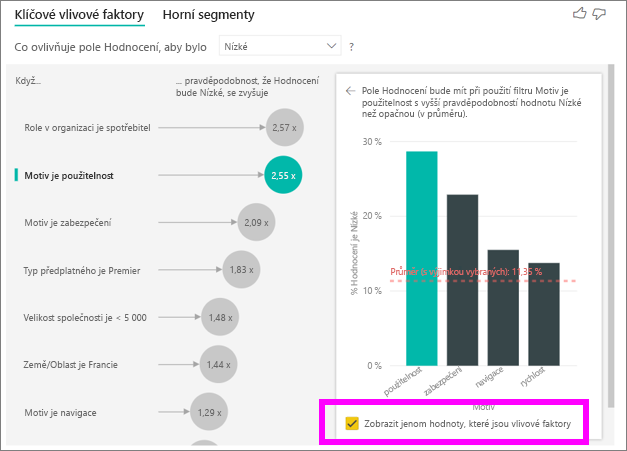
Zaškrtněte políčko Zobrazit pouze hodnoty, které jsou vlivovými faktory k filtrování pouze pomocí vlivných hodnot. V tomto případě se jedná o role, které řídí nízké skóre. 12 motivů se sníží na čtyři motivy, které Power BI identifikoval jako motivy, které řídí nízké hodnocení.
Interakce s jinými vizuály
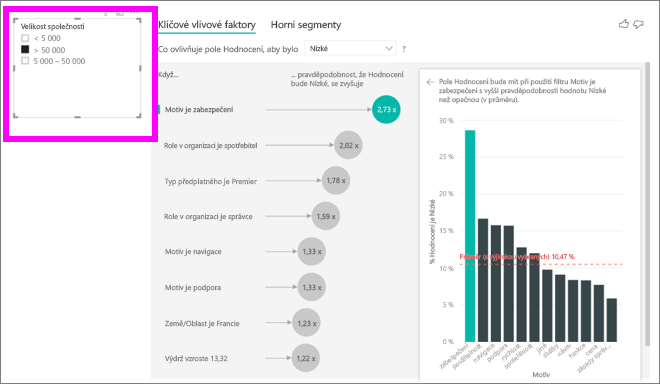
Pokaždé, když na plátně vyberete průřez, filtr nebo jiný vizuál, vizuál klíčových vlivových faktorů znovu spustí analýzu nové části dat. Můžete například přesunout velikost společnosti do sestavy a použít ji jako průřez. Použijte ho k tomu, abyste zjistili, jestli se klíčové vlivové faktory pro podnikové zákazníky liší od obecné populace. Podniková společnost je větší než 50 000 zaměstnanců.
Pokud chcete analýzu spustit znovu, vyberte >50 000 a uvidíte, že se vlivové faktory změnily. U velkých podnikových zákazníků má hlavní vlivový faktor nízkého hodnocení motiv související se zabezpečením. Možná budete chtít podrobněji prozkoumat, abyste zjistili, jestli jsou specifické funkce zabezpečení, se které vaši velké zákazníci nespokojí.
Interpretace souvislých klíčových vlivových faktorů
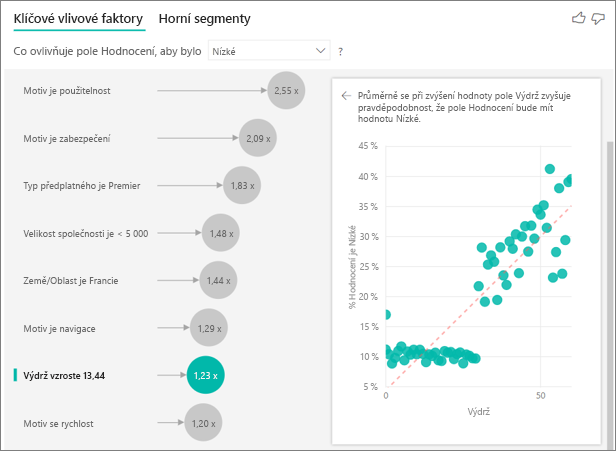
Zatím jste viděli, jak pomocí vizuálu prozkoumat, jak různá pole kategorií ovlivňují nízké hodnocení. V poli Vysvětlit podle je také možné mít průběžné faktory, jako je věk, výška a cena. Pojďme se podívat, co se stane, když se tenure přesune z tabulky zákazníků do funkce Explain by. Tenure znázorňuje, jak dlouho zákazník službu využil.
S nárůstem výdrže se zvyšuje také pravděpodobnost, že obdržíte nižší hodnocení. Tento trend naznačuje, že dlouhodobější zákazníci budou pravděpodobně poskytovat záporné skóre. Tento přehled je zajímavý a ten, který byste mohli později chtít zpracovat.
Vizualizace ukazuje, že pokaždé, když se výdrž zvýší o 13,44 měsíců, v průměru se pravděpodobnost nízkého hodnocení zvýší o 1,23krát. V tomto případě 13,44 měsíců znázorňuje směrodatnou odchylku výdrže. Díky přehledu, který dostanete, se podíváme na to, jak zvýšení výdrže o standardní množství, což je směrodatná odchylka výdrže, ovlivňuje pravděpodobnost příjmu nízkého hodnocení.
Bodový graf v pravém podokně vykreslí průměrné procento nízkých hodnocení pro každou hodnotu výdrže. Zvýrazní sklon s přímkou trendu.
Intervalované průběžné klíčové vlivové faktory
V některých případech můžete zjistit, že vaše průběžné faktory byly automaticky převedeny na kategorické. Pokud vztah mezi proměnnými není lineární, nemůžeme tuto relaci popsat jako jednoduše rostoucí nebo klesající (jako jsme to udělali v předchozím příkladu).
Spustíme korelační testy, abychom zjistili, jak lineární vlivový faktor souvisí s cílem. Pokud je cíl průběžný, spustíme Pearsonova korelace a pokud je cíl kategorický, spustíme testy korelace Point Biserial. Pokud zjistíme, že vztah není dostatečně lineární, provádíme binning pod dohledem a generujeme maximálně pět intervalů. Abychom zjistili, které intervaly mají největší smysl, používáme metodu binningu pod dohledem, která sleduje vztah mezi vysvětlujícím faktorem a analyzovaným cílem.
Interpretace měr a agregací jako klíčových vlivových faktorů
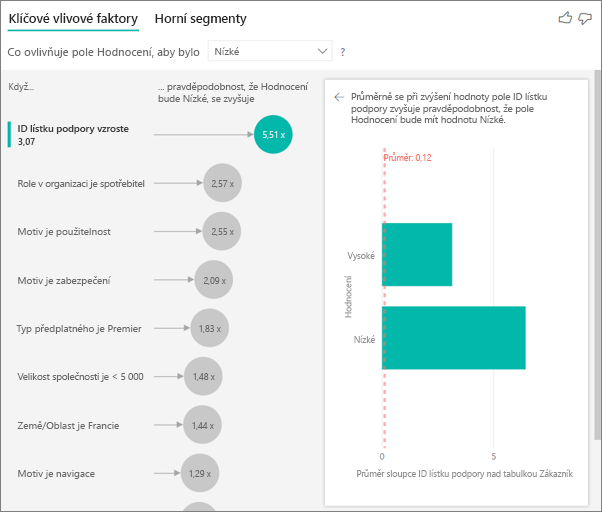
Míry a agregace můžete použít jako vysvětlující faktory v rámci analýzy. Můžete například chtít zjistit, jaký vliv má počet lístků zákaznické podpory nebo průměrná doba trvání otevřeného lístku na skóre, které obdržíte.
V tomto případě chcete zjistit, jestli počet lístků podpory, které zákazník zadal, ovlivňuje skóre, které poskytne. Teď z tabulky lístků podpory přivezete ID lístku podpory. Vzhledem k tomu, že zákazník může mít více lístků podpory, agregujete ID na úrovni zákazníka. Agregace je důležitá, protože analýza běží na úrovni zákazníka, takže všechny ovladače musí být definované na této úrovni členitosti.
Pojďme se podívat na počet ID. Každý řádek zákazníka má přidružený počet lístků podpory. V tomto případě se s rostoucím počtem lístků podpory pravděpodobnost nízkého hodnocení zvýší o 4,08krát. Vizuál na pravé straně zobrazuje průměrný počet lístků podpory podle různých hodnot hodnocení vyhodnocených na úrovni zákazníka.
Interpretace výsledků: Horní segmenty
Kartu Klíčové vlivové faktory můžete použít k individuálnímu vyhodnocení jednotlivých faktorů. Na kartě Horní segmenty můžete také zjistit, jak kombinace faktorů ovlivňuje metriku, kterou analyzujete.
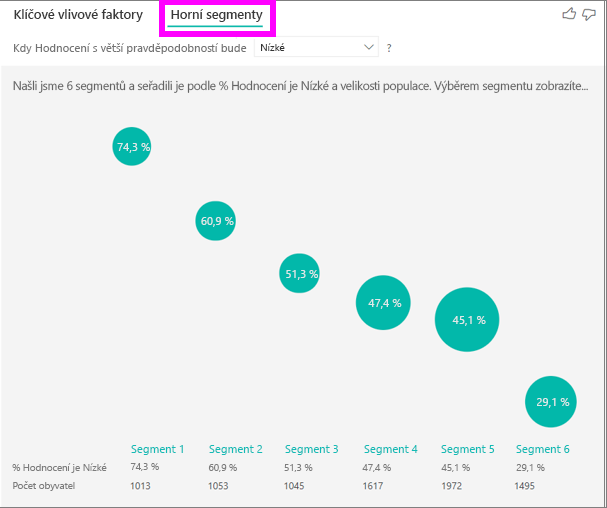
Horní segmenty zpočátku zobrazují přehled všech segmentů, které Služba Power BI zjistila. Následující příklad ukazuje, že bylo nalezeno šest segmentů. Tyto segmenty jsou seřazené podle procenta nízkých hodnocení v rámci segmentu. Segment 1 má například 74,3% hodnocení zákazníků, které jsou nízké. Čím vyšší je bublina, tím vyšší je poměr nízkých hodnocení. Velikost bubliny představuje, kolik zákazníků je v daném segmentu.
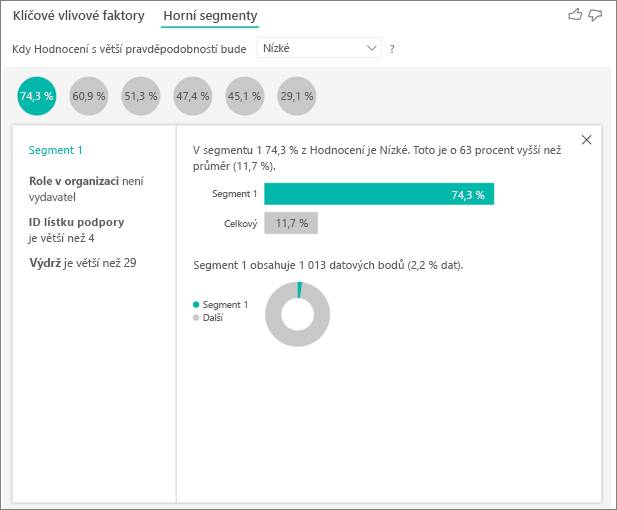
Výběrem bubliny se zobrazí podrobnosti o daném segmentu. Pokud například vyberete Segment 1, zjistíte, že se skládá z relativně zavedených zákazníků. Byli zákazníci více než 29 měsíců a mají více než čtyři lístky podpory. Nakonec nejsou vydavateli, takže jsou spotřebiteli nebo správci.
V této skupině uvedlo 74,3 % zákazníků nízké hodnocení. Průměrný zákazník zadal nízké hodnocení 11,7 % času, takže tento segment má větší podíl nízkých hodnocení. Je to 63 procentních bodů vyšší. Segment 1 obsahuje také přibližně 2,2 % dat, takže představuje adresovatelnou část populace.
Přidávání počtů
Někdy může vlivový faktor mít významný vliv, ale představuje jen málo dat. Motiv je například použitelnost třetí největší vlivový faktor nízkého hodnocení. Mohlo však existovat jen několik zákazníků, kteří si stěžovali na použitelnost. Počty vám můžou pomoct určit prioritu, na které vlivové faktory se chcete zaměřit.
Počty můžete zapnout na kartě Analýza podokna formátování.
Po povolení počtů uvidíte kolem bubliny každého vlivového faktoru kruh, který představuje přibližné procento dat, která vlivový faktor obsahuje. Čím větší je bublina kruhů, tím více dat obsahuje. Vidíme, že motiv je použitelnost, obsahuje malý podíl dat.
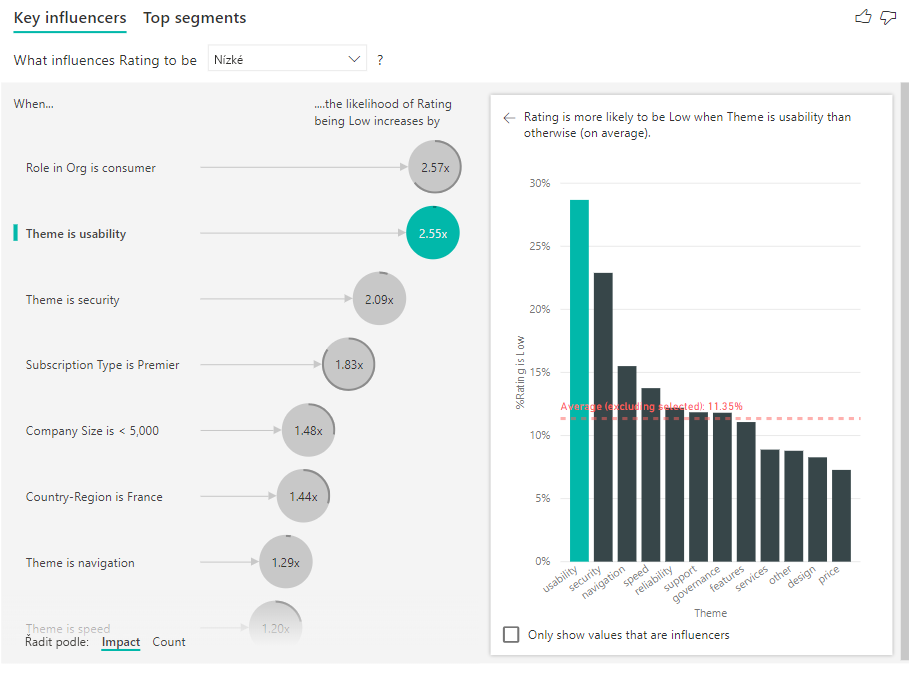
Bubliny můžete seřadit podle počtu, a ne podle dopadu, můžete také použít přepínač Seřadit podle v levém dolním rohu vizuálu. Typ předplatného je Premier je hlavní vlivový faktor založený na počtu.
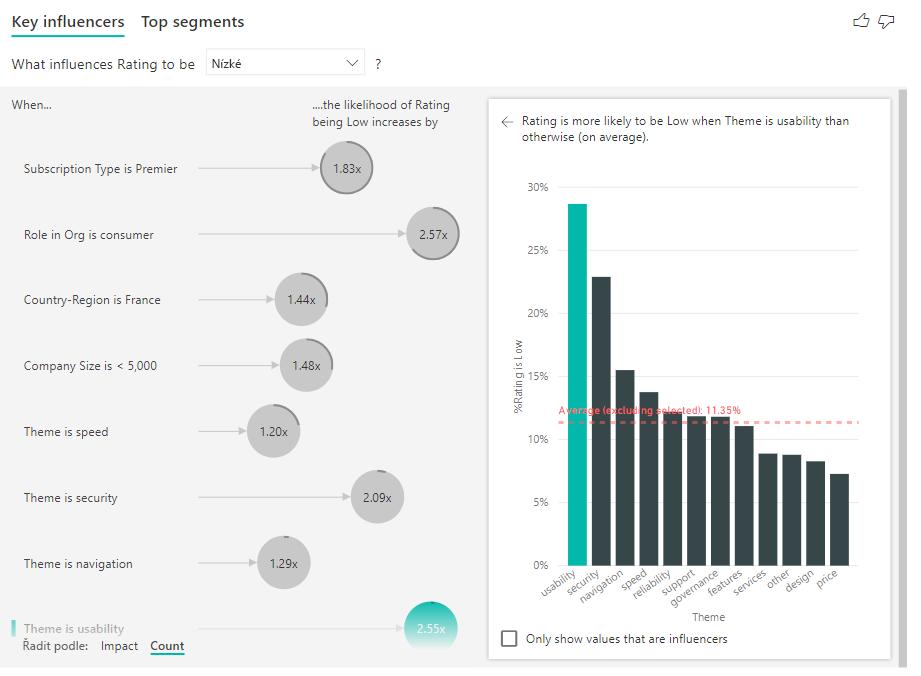
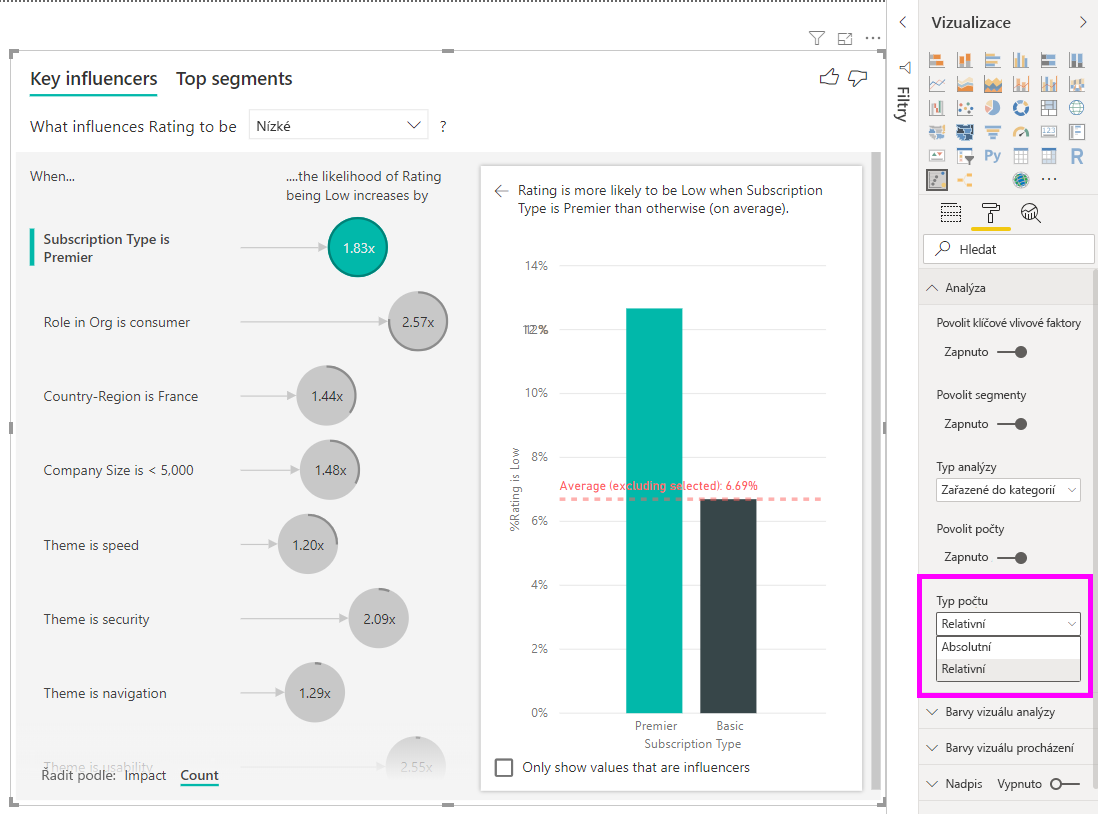
Plný kruh kolem kruhu znamená, že vlivový faktor obsahuje 100 % dat. Typ počtu můžete změnit tak, aby byl relativní k maximálnímu vlivovém faktoru pomocí rozevíracího seznamu Typ počtu na kartě Analýza v podokně formátování. Vlivový faktor s největším množstvím dat bude reprezentován úplným kruhem a všechny ostatní počty budou relativní.
Analýza metriky, která je číselná
Pokud přesunete nesummarizované číselné pole do pole Analyzovat , máte na výběr, jak tento scénář zpracovat. Chování vizuálu můžete změnit tak, že přejdete do podokna Formátování a přepnete mezi typem analýzy kategorií a typem průběžné analýzy.
Typ analýzy kategorií se chová, jak je popsáno výše. Pokud jste se například dívali na skóre průzkumu v rozsahu od 1 do 10, mohli byste se zeptat, co ovlivňuje skóre průzkumu být 1?
Typ průběžné analýzy změní otázku na souvislou. V předchozím příkladu by naše nová otázka byla "Co ovlivňuje skóre průzkumu zvýšit nebo snížit?".
Toto rozlišení je užitečné, když máte v analyzovaných polích spoustu jedinečných hodnot. V následujícím příkladu se podíváme na ceny domů. Není smysluplné se zeptat ,Co ovlivňuje House Price to be 156,214?' vzhledem k tomu, že je to velmi specifické a pravděpodobně nebudeme mít dostatek dat k odvození vzoru.
Místo toho bychom se mohli chtít zeptat, "Co má vliv na zvýšení ceny domu"? což nám umožňuje zacházet s cenami domů jako s rozsahem, nikoli jako s odlišnými hodnotami.
Interpretace výsledků: Klíčové vlivové faktory
Poznámka:
Příklady v této části používají data o cenách domu veřejné domény. Ukázkovou datovou sadu si můžete stáhnout, pokud chcete postup sledovat.
V tomto scénáři se podíváme na to, co ovlivňuje zvýšení ceny domu. Řada vysvětlujících faktorů může mít vliv na cenu domu, jako je Year Built (rok, kdy byl dům postaven), KitchenQual (kvalita kuchyně) a YearRemodAdd (rok, kdy byl dům remodelován).
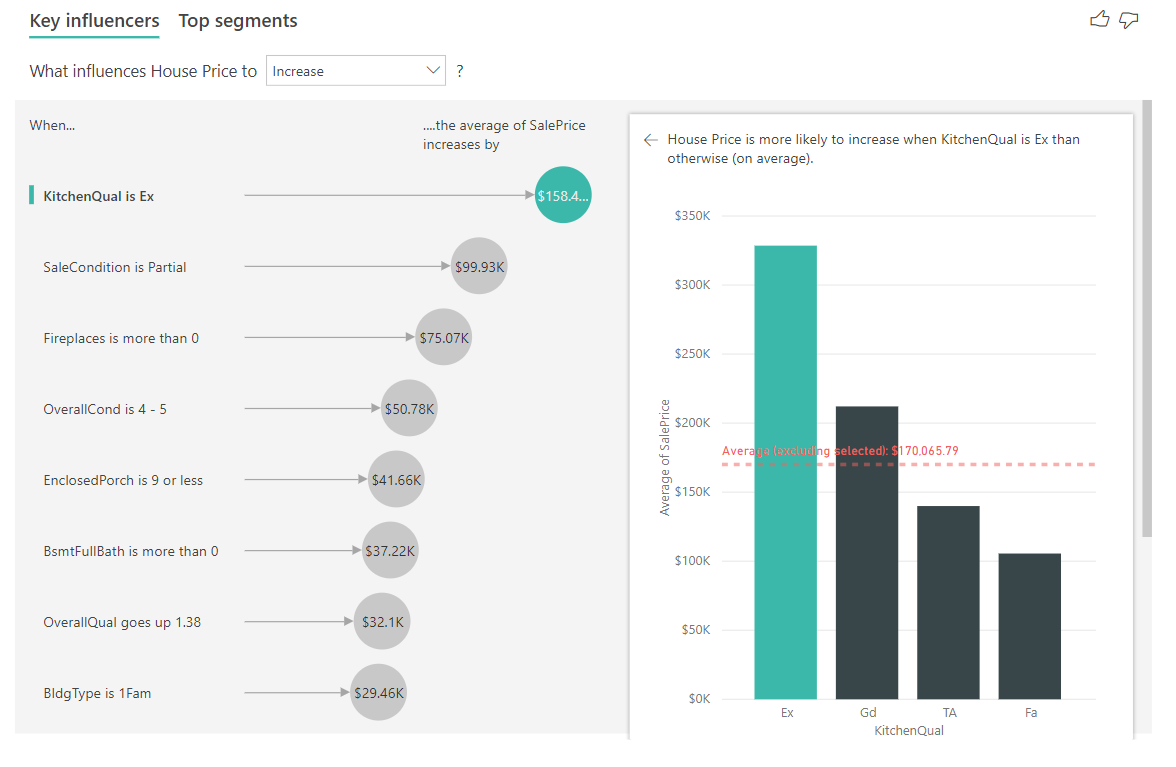
V následujícím příkladu se podíváme na náš hlavní vlivový faktor, což je kvalita kuchyně vynikající. Výsledky jsou podobné těm, které jsme viděli při analýze metrik kategorií s několika důležitými rozdíly:
- Sloupcový graf na pravé straně se dívá na průměry, nikoli na procenta. Proto nám ukazuje, jaká je průměrná cena domu s vynikající kuchyní (zelený pruh) ve srovnání s průměrnou cenou domu bez vynikající kuchyně (tečkovaná čára).
- Číslo v bublině je stále rozdíl mezi červenou tečkovanou čárou a zeleným pruhem, ale vyjadřuje se jako číslo (158,49 K) místo pravděpodobnosti (1,93x). Takže v průměru jsou domy s vynikajícími kuchyněmi téměř $160K dražší než domy bez vynikajících kuchyní.
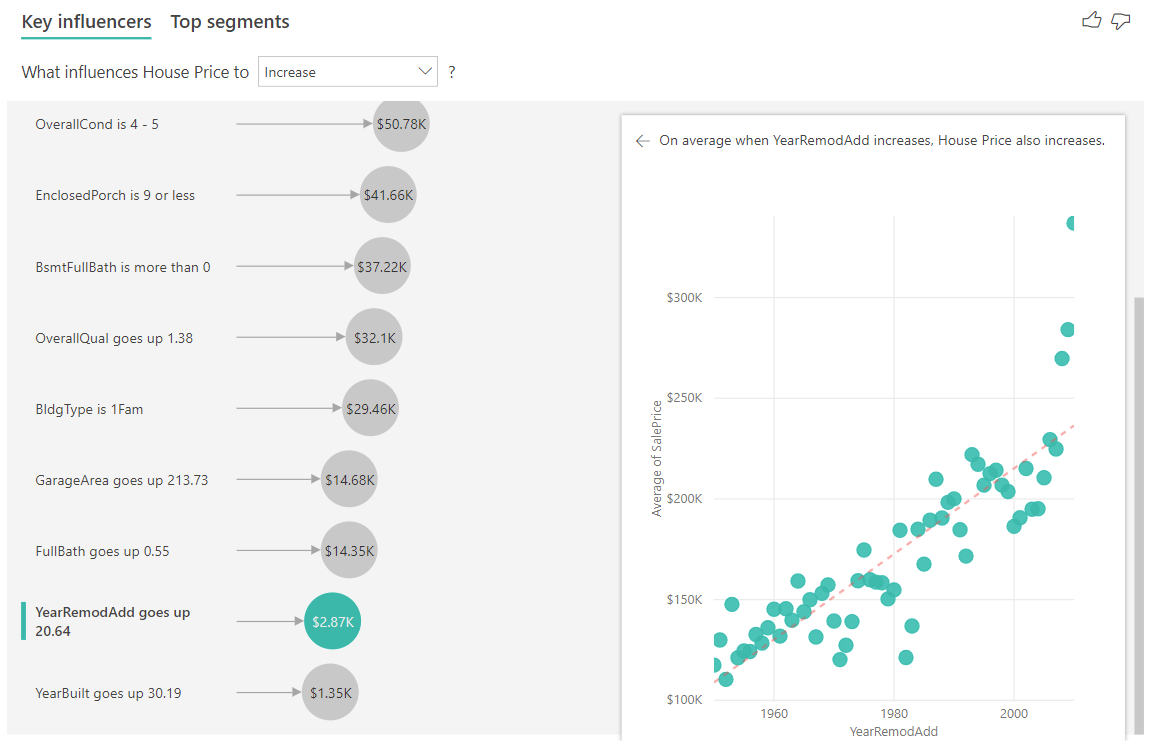
V následujícím příkladu se podíváme na dopad průběžného faktoru (rok byl remodelován) na cenu domu. Rozdíly ve srovnání s analýzou průběžných vlivových faktorů pro kategorické metriky jsou následující:
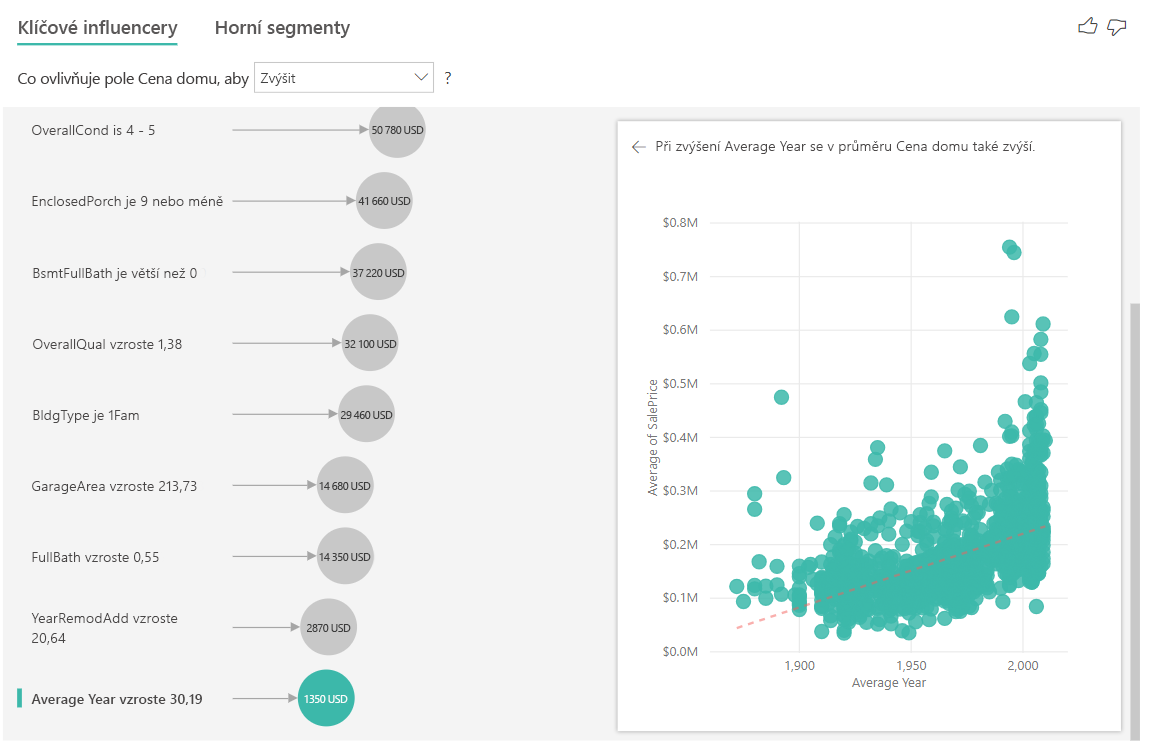
- Bodový graf v pravém podokně vykreslí průměrnou cenu domu pro každou jedinečnou hodnotu roku remodelovanou.
- Hodnota v bublině ukazuje, o kolik se průměrná cena domu zvýší (v tomto případě 2,87k), když se rok, kdy byl dům remodelován, zvyšuje o svou směrodatnou odchylku (v tomto případě 20 let).
A konečně, v případě měr se díváme na průměrný rok, kdy byl dům postaven. Analýza je následující:
- Bodový graf v pravém podokně vykreslí průměrnou cenu domu pro každou jedinečnou hodnotu v tabulce.
- Hodnota v bublině ukazuje, o kolik se průměrná cena domu zvýší (v tomto případě 1,35 K), když se průměrný rok zvýší o směrodatnou odchylku (v tomto případě 30 let).
Interpretace výsledků: Horní segmenty
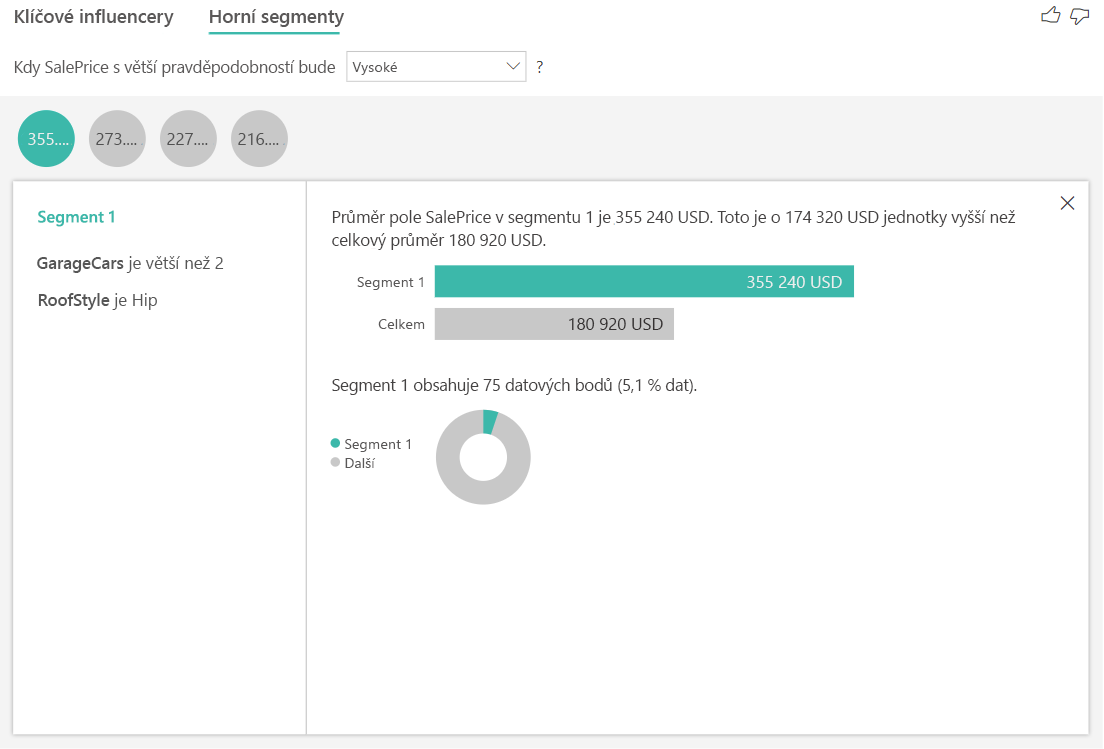
Hlavní segmenty pro číselné cíle zobrazují skupiny, ve kterých jsou ceny domů v průměru vyšší než v celkové datové sadě. Níže vidíme například, že Segment 1 se skládá z domů, kde garageCars (počet aut, které se vejdou) je větší než 2 a RoofStyle je Hip. Domy s těmito charakteristikami mají průměrnou cenu 355 000 Kč v porovnání s celkovým průměrem v datech, což je 180 000 Kč.
Analýza metriky, která je mírou nebo souhrnným sloupcem
V případě míry nebo souhrnného sloupce se ve výchozím nastavení analýzy používá typ průběžné analýzy popsaný výše. Tento údaj nelze změnit. Největší rozdíl mezi analýzou sloupce míry a souhrnného sloupce a nesummarizovaným číselným sloupcem je úroveň, na které se analýza spouští.
V případě nesummarizovaných sloupců se analýza vždy spouští na úrovni tabulky. V příkladu cen domu výše jsme analyzovali metriku Cena domu, abychom zjistili, co má vliv na zvýšení nebo snížení ceny domu. Analýza se automaticky spustí na úrovni tabulky. Naše tabulka má jedinečné ID pro každý dům, takže analýza běží na úrovni domu.
U měr a souhrnných sloupců okamžitě nevíme, na jakou úroveň se mají analyzovat. Pokud by byla cena domu sumarována jako průměr, museli bychom zvážit, jakou úroveň bychom chtěli vypočítat tuto průměrnou cenu domu. Je to průměrná cena domu na úrovni sousedství? Nebo možná regionální úroveň?
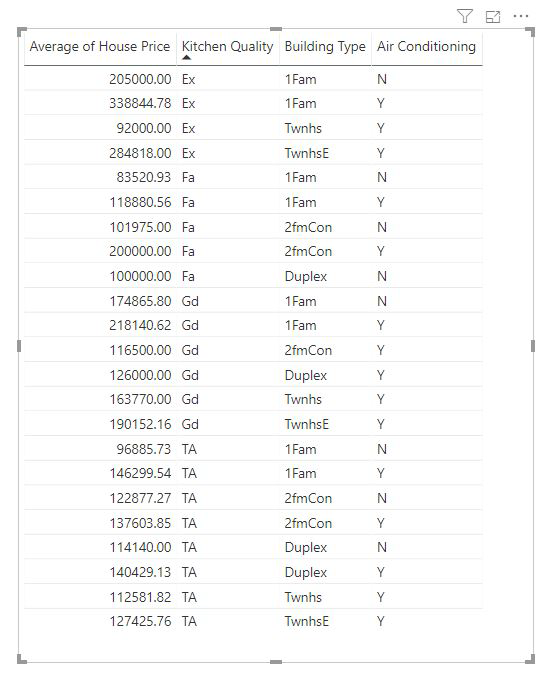
Míry a souhrnné sloupce se automaticky analyzují na úrovni pole Vysvětlit podle použitých polí. Představte si, že máme tři pole v části Vysvětlit podle toho, co nás zajímá: Kvalita kuchyně, typ budovy a klimatizace. Průměrná cena domu by se vypočítala pro každou jedinečnou kombinaci těchto tří polí. Často je užitečné přepnout do zobrazení tabulky a podívat se, jak vypadají data, která se vyhodnocují.
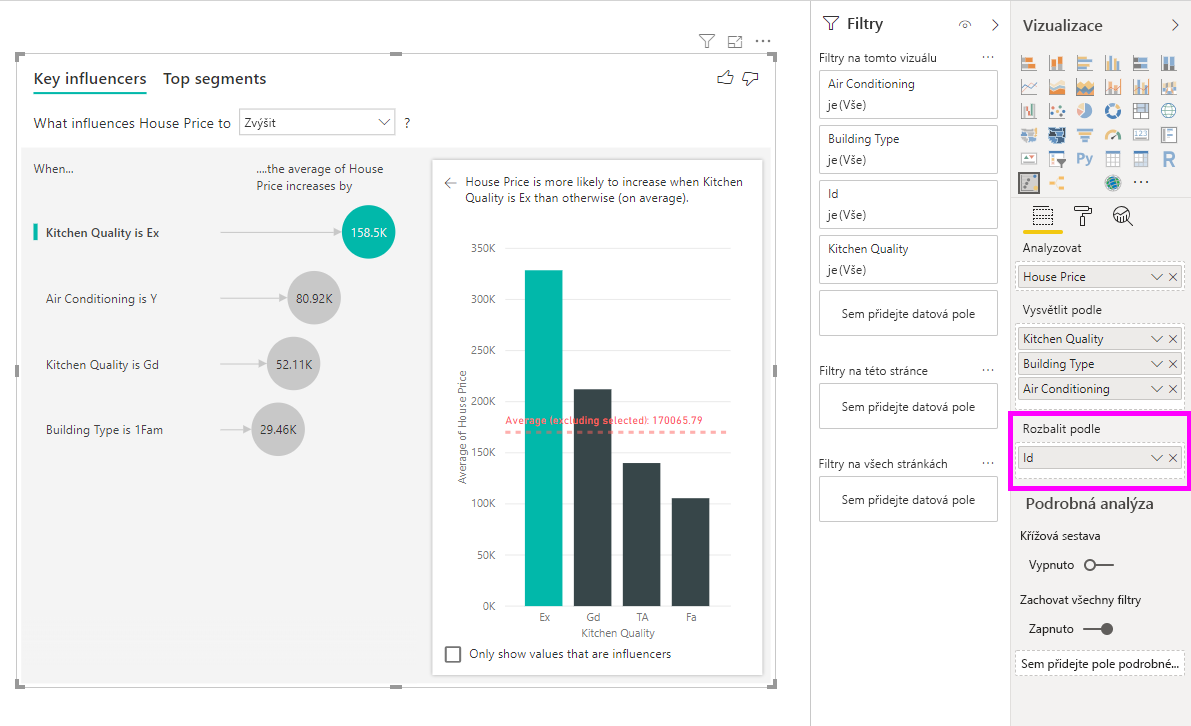
Tato analýza je velmi sumarizovat a proto bude pro regresní model obtížné najít v datech, ze kterých se může poučit. Analýzu bychom měli spustit na podrobnější úrovni, abychom získali lepší výsledky. Pokud bychom chtěli analyzovat cenu domu na úrovni domu, museli bychom do analýzy explicitně přidat pole ID . Nicméně nechceme, aby ID domu bylo považováno za vlivový faktor. Není užitečné se dozvědět, že se při nárůstu ID domu, zvýšení ceny domu. Možnost Rozbalit podle pole sem přijde vhod. Rozbalit podle můžete použít k přidání polí, která chcete použít k nastavení úrovně analýzy, aniž byste hledali nové vlivové faktory.
Podívejte se, jak vizualizace vypadá, jakmile přidáme ID do funkce Rozbalit podle. Jakmile definujete úroveň, na které chcete míru vyhodnotit, bude interpretace vlivových faktorů úplně stejná jako u nesummarizovaných číselných sloupců.
Pokud se chcete dozvědět více o tom, jak analyzovat míry pomocí vizualizace klíčových vlivových faktorů, podívejte se na následující video. Pokud se chcete dozvědět, jak Power BI používá ML.NET na pozadí k zdůvodnění dat a přirozeným způsobem zpřístupňuje přehledy, podívejte se, jak Power BI identifikuje klíčové vlivové faktory pomocí ML.NET.
Poznámka:
Toto video může používat starší verze Power BI Desktopu nebo služba Power BI.
Důležité informace a řešení potíží
Jaká jsou omezení vizuálu?
Vizuál klíčových vlivových faktorů má určitá omezení:
- Přímý dotaz se nepodporuje.
- Živá Připojení pro Službu Azure Analysis Services a Služba Analysis Services serveru SQL se nepodporuje.
- Publikování na webu se nepodporuje.
- Vyžaduje se rozhraní .NET Framework 4.6 nebo vyšší.
- Vkládání SharePointu Online se nepodporuje.
Zobrazuje se chyba, že nebyly nalezeny žádné vlivové faktory nebo segmenty. Proč?
K této chybě dochází při zahrnutí polí do pole Vysvětlit podle , ale nebyly nalezeny žádné vlivové faktory.
- Zahrnuli jste metriku, kterou jste analyzovali, do funkce Analyzovat i Vysvětlit. Odeberte ho z funkce Vysvětlit podle.
- Vysvětlující pole mají příliš mnoho kategorií s několika pozorováními. Tato situace znesnadňuje vizualizaci určit, které faktory jsou vlivovými faktory. Je těžké generalizovat pouze na základě několika pozorování. Pokud analyzujete číselné pole, možná budete chtít přepnout z analýzy kategorií na průběžnou analýzu v podokně Formátování na kartě Analýza.
- Vysvětlující faktory mají dostatek pozorování ke generalizaci, ale vizualizace nenašla žádné smysluplné korelace k sestavě.
Zobrazuje se chyba, že metrika, kterou analyzuji, nemá dostatek dat ke spuštění analýzy. Proč?

Vizualizace funguje tak, že se podíváte na vzory v datech pro jednu skupinu ve srovnání s jinými skupinami. Hledá například zákazníky, kteří zadali nízké hodnocení v porovnání se zákazníky, kteří zadali vysoké hodnocení. Pokud data v modelu mají jenom několik pozorování, obtížně se hledají vzory. Pokud vizualizace nemá dostatek dat k vyhledání smysluplných vlivových faktorů, znamená to, že ke spuštění analýzy je potřeba více dat.
Doporučujeme, abyste pro vybraný stav měli alespoň 100 pozorování. V tomto případě se jedná o zákazníky, kteří se chytnou. Pro stavy, které používáte k porovnání, potřebujete alespoň 10 pozorování. V tomto případě je stav porovnání zákazníky, kteří nechutná.
Pokud analyzujete číselné pole, možná budete chtít přepnout z analýzy kategorií na průběžnou analýzu v podokně Formátování na kartě Analýza.
Zobrazuje se mi chyba, že když analýza není sumarizovat, analýza se vždy spustí na úrovni řádku nadřazené tabulky. Změna této úrovně prostřednictvím polí Rozbalit podle není povolená. Proč?
Při analýze číselného nebo kategorického sloupce se analýza vždy spouští na úrovni tabulky. Pokud například analyzujete ceny domů a tabulka obsahuje sloupec ID, analýza se automaticky spustí na úrovni ID domu.
Při analýze míry nebo souhrnného sloupce je potřeba explicitně uvést, na jaké úrovni chcete analýzu spustit. Funkci Rozbalit můžete použít ke změně úrovně analýzy měr a souhrnných sloupců bez přidání nových vlivových faktorů. Pokud byla cena domu definována jako míra, můžete přidat sloupec ID domu k rozbalení změnou úrovně analýzy.
Zobrazuje se mi chyba, že pole v části Vysvětlit podle není jedinečně spojené s tabulkou, která obsahuje metriku, kterou analyzuji. Proč?
Analýza se spouští na úrovni tabulky analyzovaného pole. Pokud například analyzujete zpětnou vazbu zákazníků pro vaši službu, můžete mít tabulku s informacemi o tom, jestli zákazník zadal vysoké hodnocení nebo nízké hodnocení. V tomto případě je vaše analýza spuštěná na úrovni tabulky zákazníků.
Pokud máte související tabulku definovanou na podrobnější úrovni než tabulka obsahující vaši metriku, zobrazí se tato chyba. Tady je příklad:
- Analyzujete, co vede zákazníky k poskytování nízkých hodnocení vaší služby.
- Chcete zjistit, jestli zařízení, na kterém zákazník využívá vaši službu, ovlivňuje recenze, které poskytuje.
- Zákazník může službu využívat několika různými způsoby.
- V následujícím příkladu zákazník 10000000 používá prohlížeč i tablet k interakci se službou.
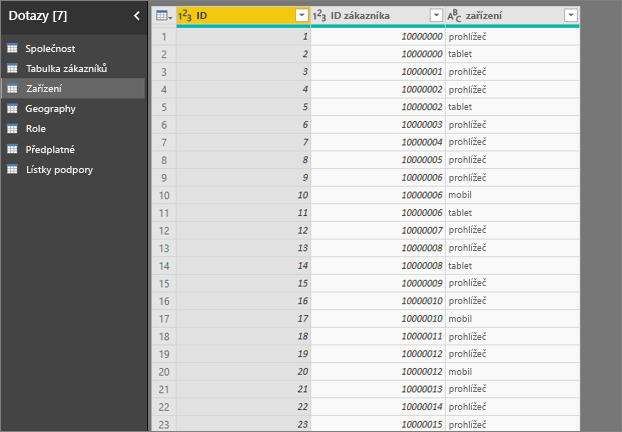
Pokud se pokusíte použít sloupec zařízení jako vysvětlující faktor, zobrazí se následující chyba:

Tato chyba se zobrazí, protože zařízení není definované na úrovni zákazníka. Jeden zákazník může službu využívat na více zařízeních. Aby vizualizace našla vzory, musí být zařízení atributem zákazníka. Existuje několik řešení, která závisí na porozumění vaší firmě:
- Můžete změnit souhrn zařízení tak, aby počítaly. Pokud například počet zařízení může ovlivnit skóre, které zákazník poskytne.
- Sloupec zařízení můžete otočit a zjistit, jestli využívání služby na konkrétním zařízení ovlivňuje hodnocení zákazníka.
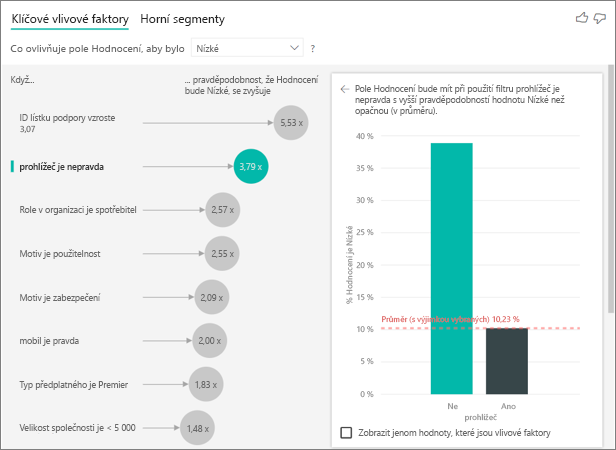
V tomto příkladu se data přetáhla tak, aby vytvářela nové sloupce pro prohlížeč, mobilní zařízení a tablet (nezapomeňte odstranit a znovu vytvořit relace v zobrazení modelování po kontingenčním zobrazení dat). Tato konkrétní zařízení teď můžete použít v části Vysvětlit podle. Všechna zařízení můžou být vlivovými faktory a prohlížeč má největší vliv na skóre zákazníka.
Přesněji řečeno, zákazníci, kteří nepoužívají prohlížeč k využívání služby, jsou 3,79krát větší pravděpodobnost, že poskytnou nízké skóre než zákazníci, kteří to dělají. Dole v seznamu platí inverzní funkce pro mobilní zařízení. Zákazníci, kteří používají mobilní aplikaci, mají větší pravděpodobnost nízké skóre než zákazníci, kteří ne.
Zobrazuje se mi upozornění, že do analýzy nebyly zahrnuty míry. Proč?
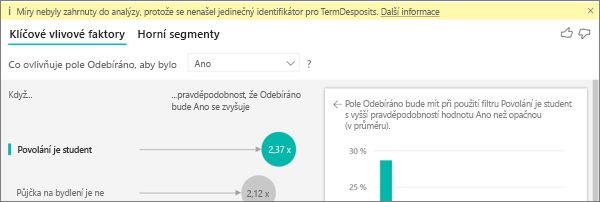
Analýza se spouští na úrovni tabulky analyzovaného pole. Pokud analyzujete četnost změn zákazníků, můžete mít tabulku s informacemi o tom, jestli zákazník churnal nebo ne. V tomto případě se vaše analýza spustí na úrovni tabulky zákazníků.
Míry a agregace se ve výchozím nastavení analyzují na úrovni tabulky. Pokud by byla míra průměrné měsíční útraty, byla by analyzována na úrovni tabulky zákazníků.
Pokud tabulka zákazníků nemá jedinečný identifikátor, nemůžete míru vyhodnotit a analýza ji ignoruje. Pokud se chcete této situaci vyhnout, ujistěte se, že tabulka s vaší metrikou má jedinečný identifikátor. V tomto případě se jedná o tabulku zákazníka a jedinečný identifikátor je ID zákazníka. Pomocí Power Query můžete také snadno přidat indexový sloupec.
Zobrazuje se upozornění, že metrika, kterou analyzuji, má více než 10 jedinečných hodnot a že tato částka může ovlivnit kvalitu analýzy. Proč?
Vizualizace AI může analyzovat pole kategorií a číselná pole. V případě polí kategorií může být příkladem četnost změn Ano nebo Ne a spokojenost zákazníka je Vysoká, Střední nebo Nízká. Zvýšení počtu kategorií k analýze znamená, že pro každou kategorii existuje méně pozorování. Tato situace znesnadňuje vizualizaci hledání vzorů v datech.
Při analýze číselnýchpolíchm polím máte při analýze číselných polí na výběr mezi číselnými poli, jako je text. Pokud máte velké množství jedinečných hodnot, doporučujeme přepnout analýzu na průběžnou analýzu , protože to znamená, že můžeme odvodit vzory z toho, kdy se čísla zvětší nebo sníží, a nedají se s nimi zacházet jako s jedinečnými hodnotami. V podokně Formátování na kartě Analýza můžete přepnout z kategorické analýzy na průběžnou analýzu.
Pokud chcete najít silnější vlivové faktory, doporučujeme seskupit podobné hodnoty do jedné jednotky. Pokud máte například metriku pro cenu, pravděpodobně získáte lepší výsledky seskupením podobných cen do kategorií Vysoká, Střední a Nízká oproti použití jednotlivých cenových bodů.
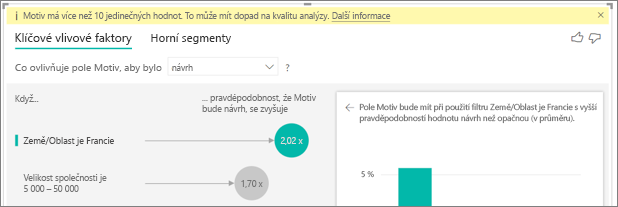
V datech existují faktory, které vypadají, jako by měly být klíčové vlivové faktory, ale nejsou. Jak se to může stát?
V následujícím příkladu zákazníci, kteří jsou spotřebiteli, řídí nízké hodnocení s 14,93 % hodnocení, která jsou nízká. Role správce má také vysoký podíl nízkých hodnocení na 13,42 %, ale nepovažuje se za vlivový faktor.
Důvodem tohoto určení je, že vizualizace při hledání vlivových faktorů bere v úvahu také počet datových bodů. Následující příklad obsahuje více než 29 000 uživatelů a 10krát méně správců, přibližně 2 900. Jen 390 z nich dal nízké hodnocení. Vizuál nemá dostatek dat k určení, jestli našel vzor s hodnocením správce nebo jestli je to jen náhodná nalezení.
Jaké jsou limity datových bodů pro klíčové vlivové faktory? Analýzu provádíme na vzorku 10 000 datových bodů. Bubliny na jedné straně zobrazují všechny nalezené vlivové faktory. Sloupcové grafy a bodové grafy na druhé straně se řídí strategiemi vzorkování těchto základních vizuálů.
Jak vypočítat klíčové vlivové faktory pro kategorickou analýzu?
Vizualizace AI na pozadí používá ML.NET ke spuštění logistické regrese k výpočtu klíčových vlivových faktorů. Logistická regrese je statistický model, který porovnává různé skupiny mezi sebou.
Pokud chcete zjistit, co vede k nízkému hodnocení, logistická regrese se podívá na to, jak se zákazníci, kteří zadali nízké skóre, liší od zákazníků, kteří zadali vysoké skóre. Pokud máte více kategorií, například vysoké, neutrální a nízké skóre, podívejte se, jak se zákazníci, kteří zadali nízké hodnocení, liší od zákazníků, kteří nedali nízké hodnocení. Jak se v tomto případě liší zákazníci, kteří zadali nízké skóre, od zákazníků, kteří zadali vysoké hodnocení nebo neutrální hodnocení?
Logistická regrese hledá vzory v datech a hledá, jak se zákazníci, kteří zadali nízké hodnocení, můžou lišit od zákazníků, kteří zadali vysoké hodnocení. Může například zjistit, že zákazníci s více lístky podpory poskytují vyšší procento nízkých hodnocení než zákazníci s několika lístky podpory nebo žádné lístky podpory.
Logistická regrese také bere v úvahu, kolik datových bodů je přítomen. Pokud například zákazníci, kteří hrají roli správce, dávají proporcionálně více negativních skóre, ale existuje jen několik správců, tento faktor se nepovažuje za vlivný. Toto určení je provedeno, protože pro odvození vzoru není k dispozici dostatek datových bodů. Statistický test označovaný jako Waldův test se používá k určení, zda je faktor považován za vlivový faktor. Vizuál k určení prahové hodnoty používá p-hodnotu 0,05.
Jak vypočítáte klíčové vlivové faktory pro číselnou analýzu?
Vizualizace AI na pozadí používá ML.NET ke spuštění lineární regrese k výpočtu klíčových vlivových faktorů. Lineární regrese je statistický model, který zkoumá výsledek pole, které analyzujete změny na základě vysvětlujících faktorů.
Pokud například analyzujeme ceny domů, lineární regrese se podívá na účinek, který bude mít vynikající kuchyň na cenu domu. Mají domy s vynikajícími kuchyněmi obecně nižší nebo vyšší ceny domu v porovnání s domy bez vynikajících kuchyní?
Lineární regrese také bere v úvahu počet datových bodů. Pokud mají například domy s tenisovými kurty vyšší ceny, ale máme několik domů s tenisovým kurtem, tento faktor se nepovažuje za vlivný. Toto určení je provedeno, protože pro odvození vzoru není k dispozici dostatek datových bodů. Statistický test označovaný jako Waldův test se používá k určení, zda je faktor považován za vlivový faktor. Vizuál k určení prahové hodnoty používá p-hodnotu 0,05.
Jak vypočítáte segmenty?
Vizualizace AI na pozadí používá ML.NET ke spuštění rozhodovacího stromu, aby našla zajímavé podskupiny. Cílem rozhodovacího stromu je skončit podskupinou datových bodů, která je relativně vysoká v metrikě, kterou vás zajímá. Může to být zákazníci s nízkými hodnoceními nebo domy s vysokými cenami.
Rozhodovací strom přijímá každý vysvětlující faktor a snaží se zjistit, který faktor dává nejlepší rozdělení. Pokud například vyfiltrujete data tak, aby zahrnovala jenom velké podnikové zákazníky, oddělí se zákazníky, kteří zadali vysoké hodnocení vs. nízké hodnocení? Nebo je lepší data filtrovat tak, aby zahrnovala jenom zákazníky, kteří se vyjádřili k zabezpečení?
Jakmile rozhodovací strom provede rozdělení, vezme podskupinu dat a určí další nejlepší rozdělení pro tato data. V tomto případě je podskupina zákazníky, kteří okomentovali zabezpečení. Po každém rozdělení rozhodovací strom také bere v úvahu, jestli má pro tuto skupinu dostatek datových bodů, aby byl dostatečně reprezentativní, aby odvozoval vzor z dat nebo jestli se jedná o anomálii v datech, a ne skutečný segment. Dalším statistickým testem je kontrola statistické významnosti rozdělené podmínky s p-hodnotou 0,05.
Jakmile rozhodovací strom skončí, převezme všechna rozdělení, jako jsou komentáře zabezpečení a velké podniky, a vytvoří filtry Power BI. Tato kombinace filtrů je zabalena jako segment ve vizuálu.
Proč se některé faktory stanou vlivovými faktory nebo přestanou být vlivovými faktory, když přesunu více polí do pole Vysvětlit podle pole?
Vizualizace vyhodnocuje všechny vysvětlující faktory společně. Faktor může být vlivový faktor sám o sobě, ale když se považuje za jiné faktory, nemusí. Předpokládejme, že chcete analyzovat, co vede k vysoké ceně domu, s ložnicemi a velikostí domu jako vysvětlujícími faktory:
- Sama o sobě může být větší počet ložnic řidičem, aby ceny domů byly vysoké.
- Zahrnutí velikosti domu do analýzy znamená, že se teď podíváte na to, co se stane s ložnicemi, zatímco velikost domu zůstává konstantní.
- Pokud je velikost domu pevná na 1 500 metrů čtverečních, je nepravděpodobné, že průběžné zvýšení počtu ložnic výrazně zvýší cenu domu.
- Ložnice nemusí být tak důležité, jako tomu bylo před velikostí domu.
Sdílení sestavy s kolegou Power BI vyžaduje, abyste měli jednotlivé licence Power BI Pro nebo aby se sestava uložila do kapacity Premium. Podívejte se na sdílení sestav.
Související obsah
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro