Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Návrh dimenzionálního modelu je jednou z nejběžnějších úloh, které můžete dělat s tokem dat. Tento článek popisuje některé z osvědčených postupů pro vytvoření dimenzionálního modelu pomocí toku dat.
Přípravné toky dat
Jedním z klíčových bodů v jakémkoli systému integrace dat je snížení počtu čtení ze zdrojového operačního systému. V tradiční architektuře integrace dat se toto snížení provádí vytvořením nové databáze označované jako pracovní databáze. Účelem přípravné databáze je načíst data as-is ze zdroje dat do pracovní databáze podle běžného plánu.
Zbývající integrace dat pak použije pracovní databázi jako zdroj pro další transformaci a převede ji na strukturu dimenzionálního modelu.
Doporučujeme postupovat podle stejného přístupu pomocí toků dat. Vytvořte sadu toků dat, které zodpovídají jenom za načítání dat as-is ze zdrojového systému (a jenom pro tabulky, které potřebujete). Výsledek se pak uloží do struktury úložiště toku dat (Azure Data Lake Storage nebo Dataverse). Tato změna zajišťuje, aby operace čtení ze zdrojového systému byla minimální.
Dále můžete vytvořit další toky dat, které čerpají svá data z přechodných toků dat. Mezi výhody tohoto přístupu patří:
- Snížení počtu operací čtení ze zdrojového systému a snížení zatížení zdrojového systému v důsledku toho.
- Snížení zatížení bran dat, pokud se používá místní zdroj dat.
- Pokud se zdrojová systémová data změní, bude mít zprostředkující kopii dat pro účely odsouhlasení.
- Zajištění, aby transformační toky dat byly nezávislé na zdroji
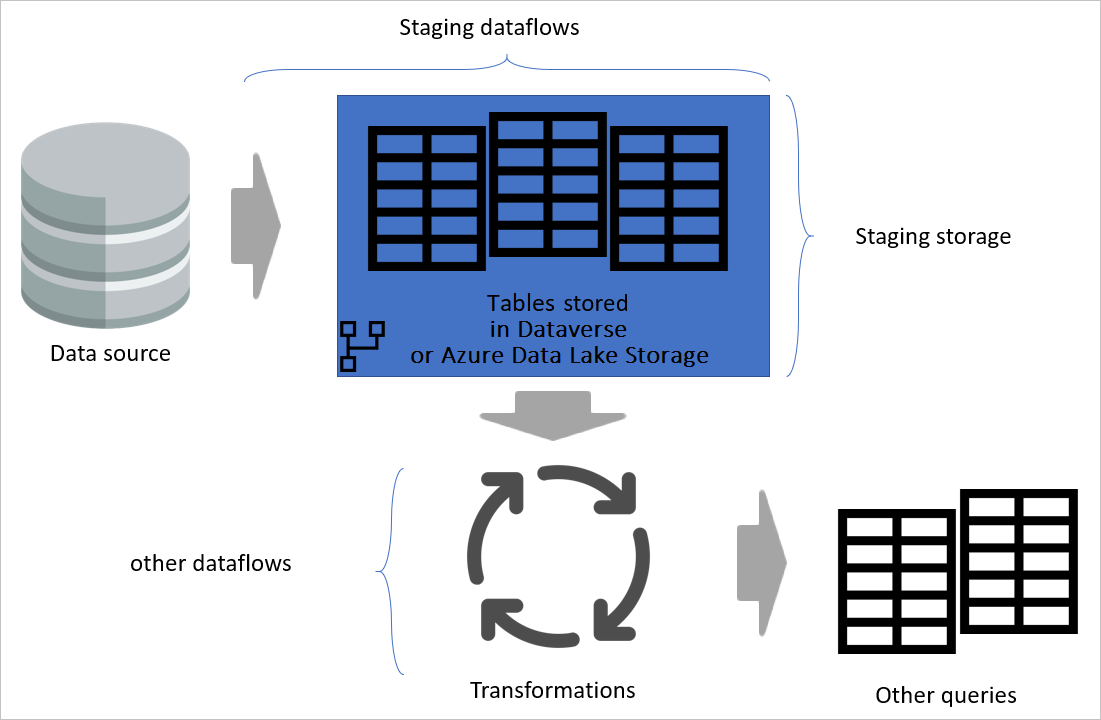
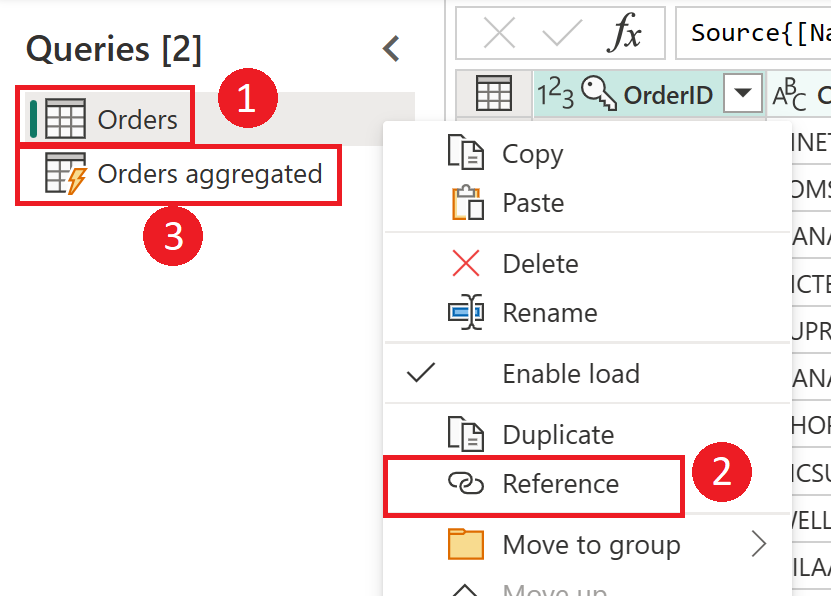
Diagram zdůrazňuje přípravné datové toky a přípravné úložiště. Diagram znázorňuje data, ke která se přistupuje ze zdroje dat přípravným tokem dat, a tabulky uložené v Cadavers nebo Azure Data Lake Storage. Tabulky se pak transformují spolu s dalšími toky dat, které se pak odesílají jako dotazy.
Transformace toků dat
Když oddělíte toky dat transformace od přípravných toků dat, transformace je nezávislá na zdroji. Toto oddělení pomáhá, pokud migrujete zdrojový systém do nového systému. V takovém případě stačí změnit pracovní toky dat. Datové toky transformace budou pravděpodobně fungovat bez problémů, protože jsou zdrojové pouze z datových toků ve stádiu.
Toto oddělení také pomáhá v případě, že je připojení ke zdrojovému systému pomalé. Datový tok transformace nemusí čekat dlouhou dobu, než získá záznamy přicházející přes pomalé připojení ze zdrojového systému. Přípravný tok dat už tuto část udělal a data jsou připravená pro transformační vrstvu.
Vícevrstvé architektury
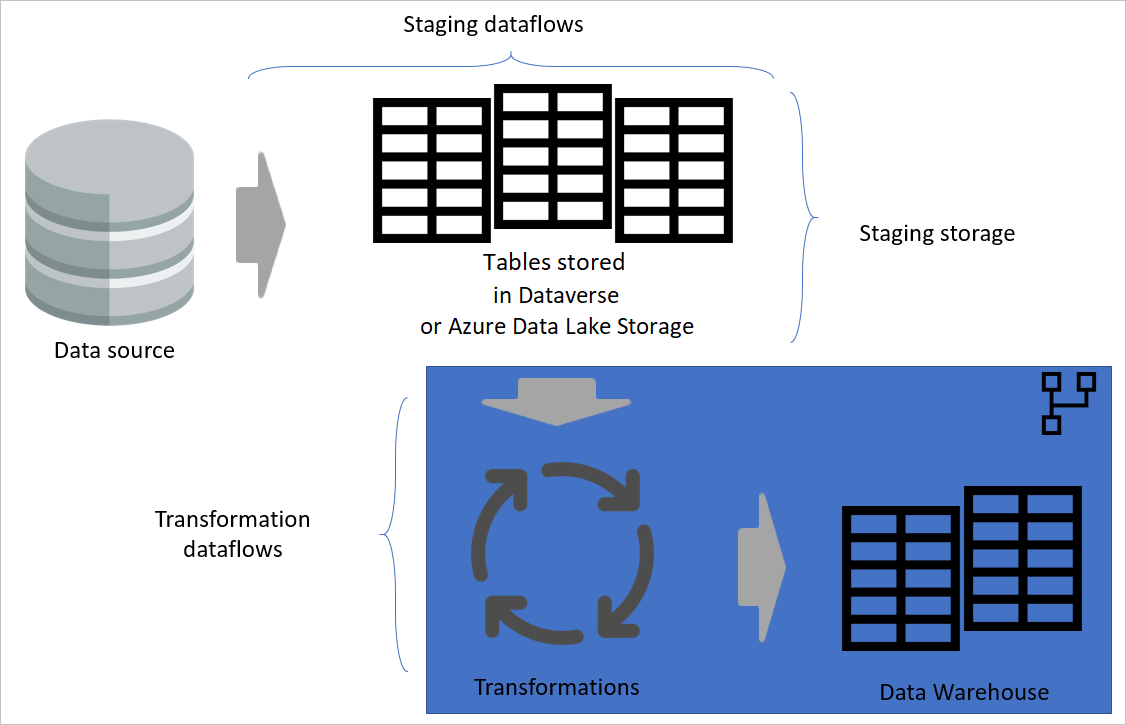
Vícevrstvá architektura je architektura, ve které provádíte akce v samostatných vrstvách. Pracovní a transformační datové toky mohou být dvě vrstvy vícevrstvé architektury toků dat. Provádění akcí ve vrstvách zajišťuje minimální požadovanou údržbu. Když chcete něco změnit, stačí ho změnit ve vrstvě, ve které se nachází. Ostatní vrstvy by měly dál fungovat správně.
Následující obrázek znázorňuje vícevrstvou architekturu pro datové toky, jejichž tabulky se pak používají v Power BI sémantických modelech.
Co nejvíce použijte počítanou tabulku.
Když použijete výsledek toku dat v jiném toku dat, používáte koncept počítané tabulky, což znamená získání dat z tabulky "již zpracovaných a uložených". Totéž se může stát uvnitř toku dat. Když odkazujete na tabulku z jiné tabulky, můžete použít vypočítanou tabulku. Tato metoda je užitečná, když máte sadu transformací, které je potřeba provést v několika tabulkách, které se nazývají běžné transformace.
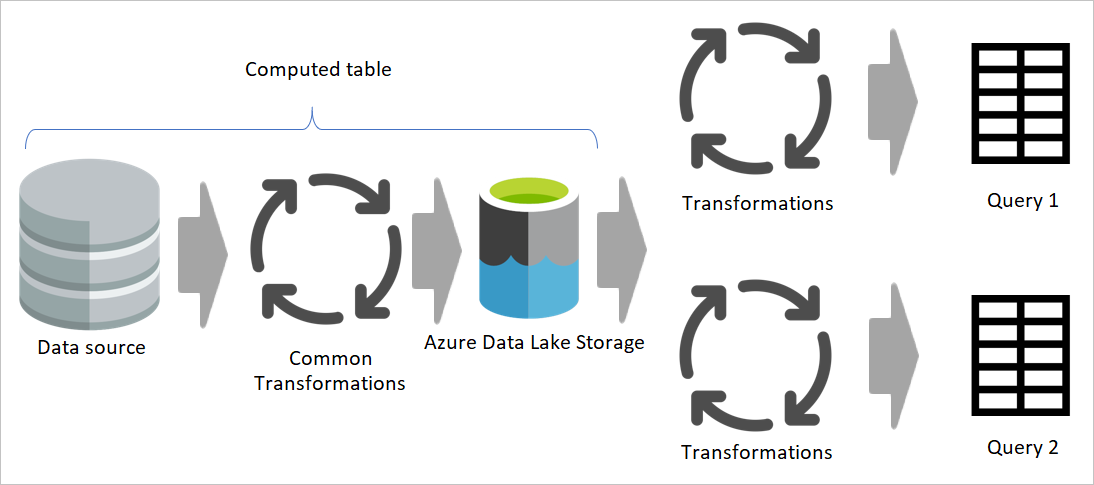
Na předchozím obrázku získá vypočítaná tabulka data přímo ze zdroje. V architektuře pracovních a transformačních toků dat je však pravděpodobné, že vypočítané tabulky pocházejí z pracovních toků dat.

Vytvoření hvězdicového schématu
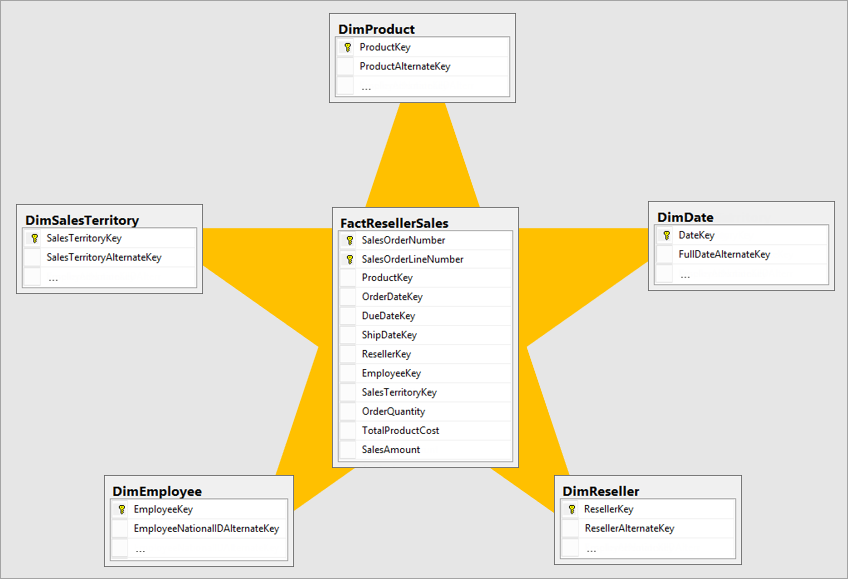
Nejlepším dimenzionálním modelem je hvězdicový model schématu, který má rozměry a tabulky faktů navržené způsobem, který minimalizuje dobu dotazování dat z modelu. Model hvězdicového schématu také usnadňuje pochopení vizualizéru dat.
Není ideální přenášet data ve stejném formátu, jaký má operační systém, do systému Business Intelligence. Tabulky dat by se měly přemodelovat. Některé tabulky by měly mít podobu tabulky dimenzí, která uchovává popisné informace. Některé tabulky by měly mít podobu tabulky faktů, aby se zachovala agregatable data. Nejlepším rozložením pro tabulky faktů a tabulky dimenzí, které se mají vytvořit, je hvězdicové schéma. Další informace najdete v tématu Vysvětlení hvězdicového schématu a důležitosti pro Power BI.
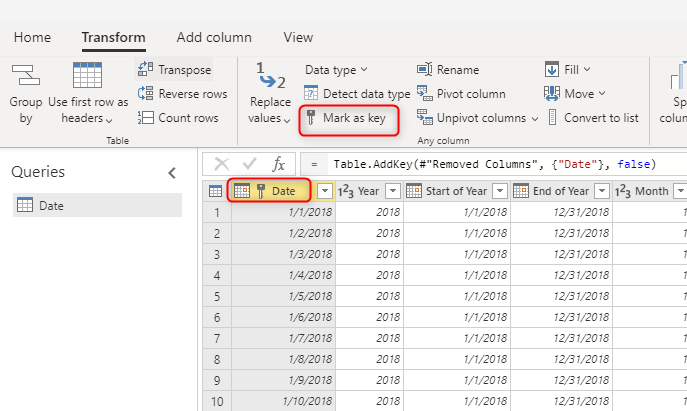
Použijte jedinečnou hodnotu klíče pro dimenze
Při vytváření tabulek dimenzí se ujistěte, že máte klíč pro každou z nich. Tento klíč zajišťuje, že mezi dimenzemi nejsou žádné mnoho-ku-mnoha (nebo jinými slovy, "slabé") vztahy. Klíč můžete vytvořit použitím určité transformace, abyste měli jistotu, že sloupec nebo kombinace sloupců vrací jedinečné řádky v dimenzi. Pak se tato kombinace sloupců může označit jako klíč v tabulce v toku dat.
Proveďte přírůstkovou aktualizaci pro velké tabulky faktů
Tabulky faktů jsou vždy největšími tabulkami v dimenzionálním modelu. Doporučujeme snížit počet řádků přenesených pro tyto tabulky. Pokud máte velmi velkou tabulku faktů, ujistěte se, že pro tuto tabulku používáte přírůstkovou aktualizaci. Přírůstkovou aktualizaci je možné provést v sémantickém modelu Power BI a také v tabulkách toku dat.
Přírůstkovou aktualizaci můžete použít k aktualizaci pouze části dat, která se změnila. Existuje několik možností, jak zvolit, kterou část dat chcete aktualizovat a kterou část chcete zachovat. Další informace najdete v tématu Použití přírůstkové aktualizace s toky dat Power BI.

Odkazování na tvorbu dimenzí a faktových tabulek
Ve zdrojovém systému často máte tabulku, kterou používáte ke generování tabulek faktů i dimenzí v datovém skladu. Tyto tabulky jsou vhodnými kandidáty pro počítané tabulky a také přechodné toky dat. Společnou část procesu, jako je čištění dat a odebrání dalších řádků a sloupců, je možné provést jednou. Pomocí odkazu z výstupu těchto akcí můžete vytvořit tabulky dimenzí a faktů. Tento přístup používá vypočítanou tabulku pro běžné transformace.