Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
V Power Query můžete hodnoty v různých řádcích seskupit do jedné hodnoty seskupením řádků podle hodnot v jednom nebo více sloupcích. Můžete si vybrat ze dvou typů operací seskupení:
Seskupování sloupců
Seskupování řádků
Pro účely tohoto kurzu používáte následující ukázkovou tabulku.
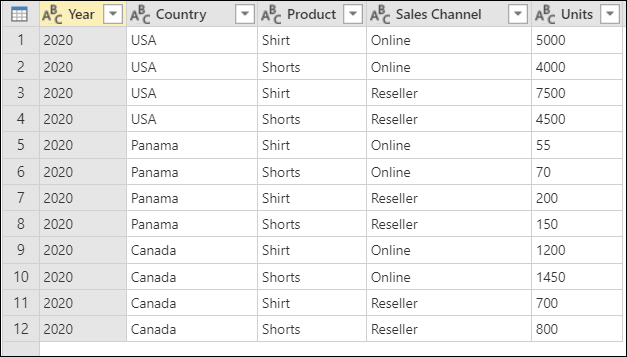
Snímek obrazovky tabulky se sloupci zobrazující rok (2020), zemi (USA, Panamu nebo Kanadu), produkt (košile nebo shorts), prodejní kanál (online nebo prodejce) a jednotky (různé hodnoty od 55 do 7500)
Kde najít tlačítko Seskupit podle
Tlačítko Seskupit podle najdete na třech místech:
Na kartě Domů ve skupině Transformace

Na kartě Transformace ve skupině Tabulka
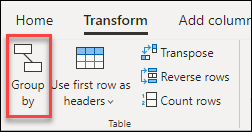
Ve zkrácené nabídce, když kliknete pravým tlačítkem myši pro výběr sloupců.
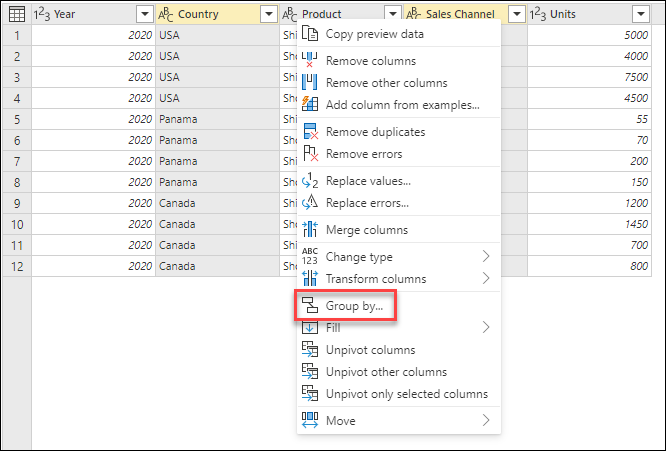
Použití agregační funkce k seskupení podle jednoho nebo více sloupců
V tomto příkladu je vaším cílem sumarizovat celkové jednotky prodané na úrovni země a prodejního kanálu. Pomocí sloupců Country and Sales Channel provedete seskupení podle operace.
- Vyberte možnost Seskupit podle na kartě Domů.
- Vyberte možnost Upřesnit , abyste mohli vybrat více sloupců, podle kterých se má seskupit.
- Vyberte sloupec Země .
- Vyberte Přidat seskupení.
- Vyberte sloupec Prodejní kanál .
- Do pole Nový název sloupce zadejte celkový počet jednotek, v operaci, vyberte Součet a ve sloupci vyberte Jednotky.
- Vyberte OK.
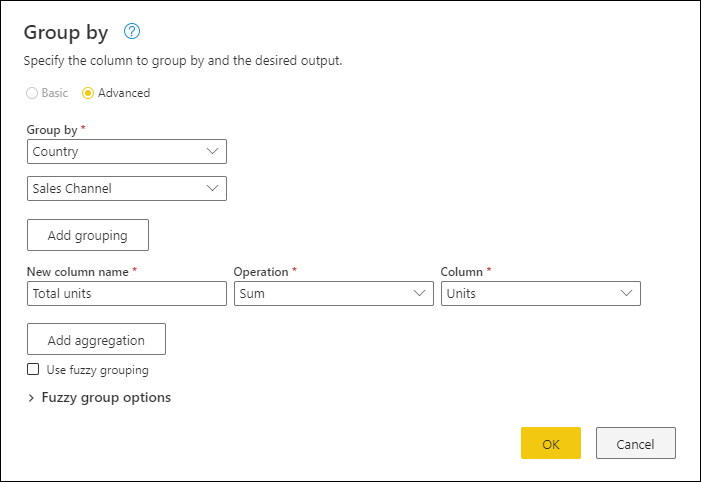
Tato operace poskytuje následující tabulku.

Dostupné operace
Díky funkci Seskupit podle je možné dostupné operace kategorizovat dvěma způsoby:
- Operace na úrovni řádků
- Operace na úrovni sloupce
Následující tabulka popisuje každou z těchto operací.
| Název operace | Kategorie | Description |
|---|---|---|
| Součet | Operace sloupce | Sečte všechny hodnoty ze sloupce. |
| Average | Operace sloupce | Vypočítá průměrnou hodnotu ze sloupce. |
| Medián | Operace sloupce | Vypočítá medián ze sloupce. |
| Min | Operace sloupce | Vypočítá minimální hodnotu ze sloupce. |
| Max | Operace sloupce | Vypočítá maximální hodnotu ze sloupce. |
| Percentil | Operace sloupce | Vypočítá percentil pomocí vstupní hodnoty od 0 do 100 ze sloupce. |
| Počet jedinečných hodnot | Operace sloupce | Vypočítá počet jedinečných hodnot ze sloupce. |
| Počet řádků | Řádková operace | Vypočítá celkový počet řádků z dané skupiny. |
| Počet jedinečných řádků | Řádková operace | Vypočítá počet jedinečných řádků z dané skupiny. |
| Všechny řádky | Řádková operace | Vypíše všechny seskupené řádky ve formátu tabulky bez agregací. |
Poznámka:
Operace počet jedinečných hodnot a percentilu jsou dostupné pouze v Power Query Online.
Provedení operace seskupování podle jednoho nebo více sloupců
Počínaje původní ukázkou vytvoříte v tomto příkladu sloupec obsahující celkový počet jednotek a dva další sloupce, které vám poskytnou název a jednotky prodané pro produkt s nejvyšším výkonem, shrnuté na úrovni země a prodejního kanálu.

Jako seskupení podle sloupců použijte následující sloupce:
- Country
- Prodejní kanál
Pomocí následujících kroků vytvořte dva nové sloupce:
- Agregujte sloupec Jednotky pomocí operace Sum . Pojmenujte sloupec Celkový počet jednotek.
- Přidejte nový sloupec Products pomocí operace Všechny řádky .
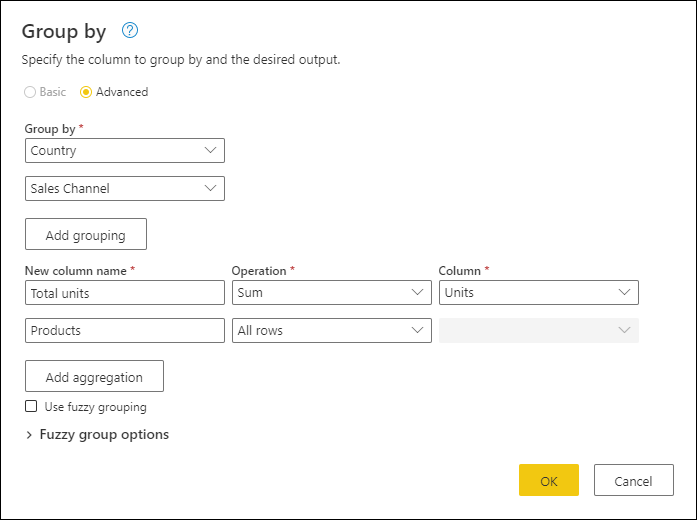
Po dokončení této operace si všimněte, jak sloupec Products obsahuje hodnoty [Table] v každé buňce. Každá hodnota [Tabulka] obsahuje všechny řádky, které byly seskupeny podle sloupců Country and Sales Channel z původní tabulky. Pokud chcete zobrazit náhled obsahu tabulky v dolní části dialogového okna, můžete vybrat prázdné místo ve vnitřku buňky.
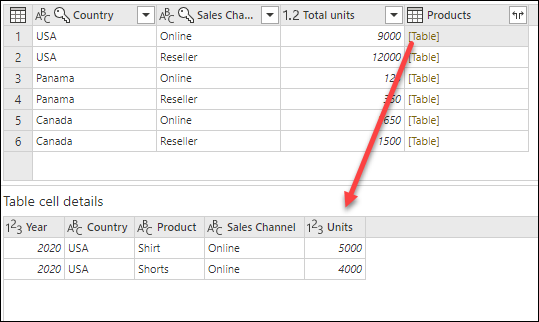
Poznámka:
V podokně náhledu podrobností se nemusí zobrazit všechny řádky, které byly použity pro operaci seskupování. Výběrem hodnoty [Tabulka] můžete zobrazit všechny řádky týkající se odpovídající operace seskupování.
Dále je potřeba extrahovat řádek, který má nejvyšší hodnotu ve sloupci Jednotky v tabulkách uvnitř nového sloupce Produkty , a volat tento nový sloupec Nejlépe výkonný produkt.
Extrahování informací o nejvýkonnějších produktech
S novým sloupcem Produkty s hodnotami [Tabulka] vytvoříte nový vlastní sloupec tak, že přejdete na kartu Přidat sloupec na pásu karet a vyberete Vlastní sloupec ze skupiny Obecné .
![]()
Pojmenujte nový sloupec Produkt s nejvyšším výkonem. Zadejte vzorec do pole Vlastní vzorec sloupceTable.Max([Products], "Units" ).
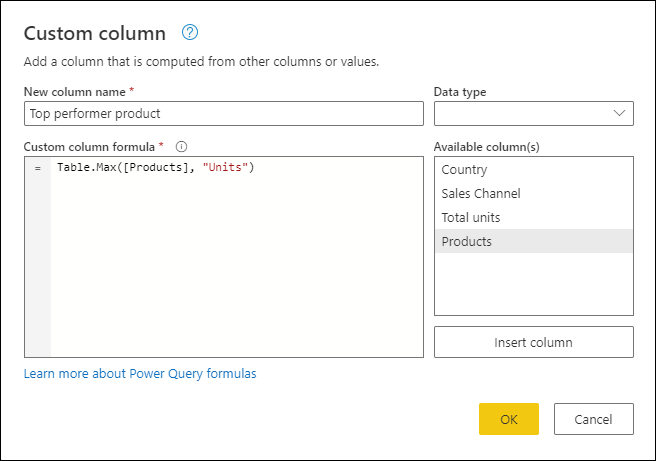
Výsledek tohoto vzorce vytvoří nový sloupec s hodnotami [Record]. Tyto hodnoty záznamů jsou v podstatě tabulka s pouhým jedním řádkem. Tyto záznamy obsahují řádek s maximální hodnotou sloupce Jednotky každé hodnoty [Tabulka] ve sloupci Produkty .
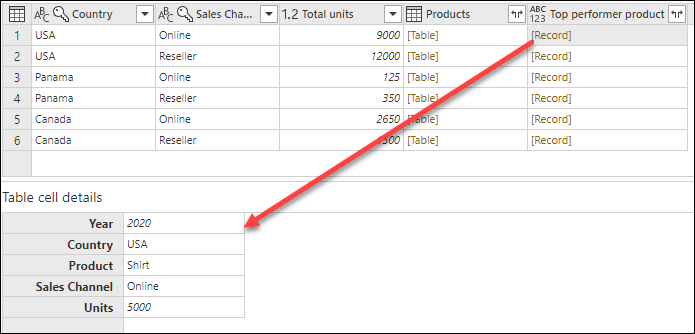
S tímto novým sloupcem produktu Top Performer, který obsahuje hodnoty [Záznam], můžete vybrat ikonu ![]() rozbalení, zvolit pole Produkt a Jednotky, a poté stisknout OK.
rozbalení, zvolit pole Produkt a Jednotky, a poté stisknout OK.
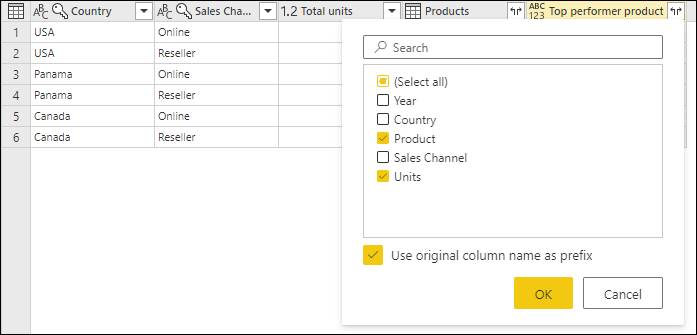
Po odebrání sloupce Produkty a nastavení datových typů pro oba nově rozbalené sloupce se výsledek podobá následujícímu obrázku.

Seskupování podle neurčitosti
Poznámka:
Následující funkce je dostupná jenom v Power Query Online.
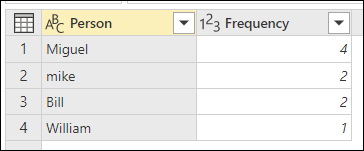
K demonstraci, jak provést "přibližné seskupení", vezměte v úvahu ukázkovou tabulku zobrazenou na následujícím obrázku.
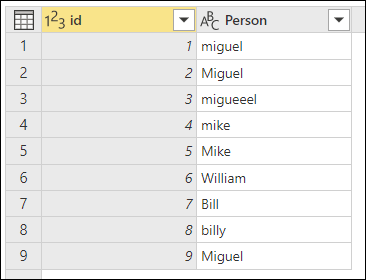
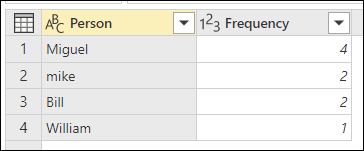
Cílem přibližného seskupení je provést operaci seskupování, která používá přibližný algoritmus shody pro textové řetězce. Power Query používá algoritmus podobnosti Jaccard k měření podobnosti mezi páry instancí. Potom použije aglomerativní hierarchické klastrování pro seskupení instancí. Následující obrázek znázorňuje očekávaný výstup, kde je tabulka seskupována podle sloupce Osoba .
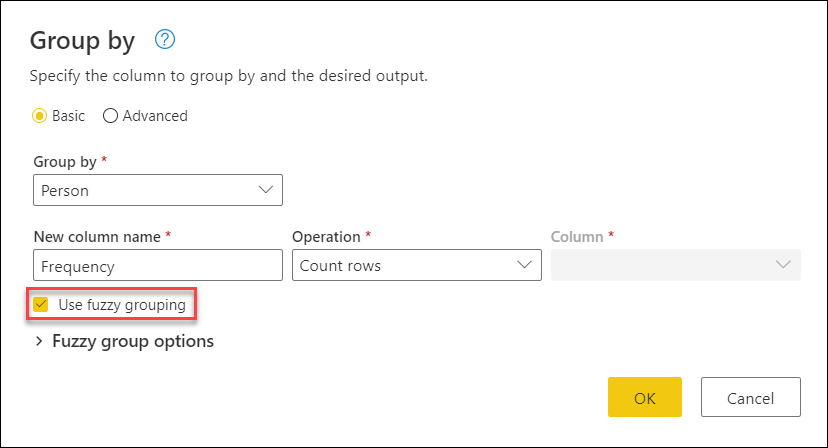
Pokud chcete provést přibližné seskupení, proveďte stejné kroky popsané v tomto článku. Jediným rozdílem je, že tentokrát v dialogovém okně Seskupování podle zaškrtnete políčko Použít přibližné seskupení .
Pro každou skupinu řádků Power Query vybere nejčastější instanci jako "kanonickou" instanci. Pokud se s stejnou frekvencí vyskytuje více instancí, Power Query vybere první z nich. Jakmile v dialogovém okně Seskupit podle vyberete OK, zobrazí se výsledek, který jste očekávali.
Máte ale větší kontrolu nad operací seskupování přibližných shod tím, že rozbalíte možnosti přibližného seskupování.
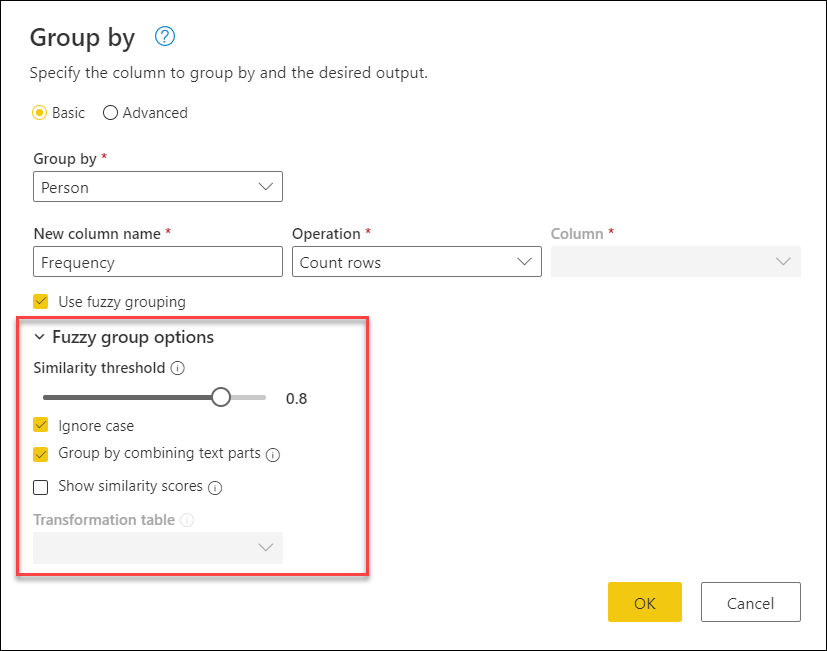
Pro fuzzy slučování jsou k dispozici tyto možnosti:
- Prahová hodnota podobnosti (volitelná):: Tato možnost označuje, jak podobné dvě hodnoty musí být seskupené dohromady. Minimální nastavení nuly (0) způsobí seskupení všech hodnot. Maximální nastavení 1 umožňuje seskupit pouze hodnoty, které přesně odpovídají. Výchozí hodnota je 0,8.
- Ignorovat malá a velká písmena: Při porovnávání textových řetězců se velká a malá písmena ignorují. Tato možnost je ve výchozím nastavení povolená.
- Seskupit pomocí kombinování textových částí: Algoritmus se pokusí zkombinovat textové části (například zkombinovat Mikro a soft do Microsoftu) a seskupit hodnoty.
- Zobrazit skóre podobnosti: Zobrazit skóre podobnosti mezi vstupními hodnotami a vypočítaným reprezentativními hodnotami po přibližné seskupování Vyžaduje přidání operace, například všechny řádky , aby se tyto informace ukázaly na úrovni řádků po řádcích.
- Transformační tabulka (volitelné): Můžete vybrat transformační tabulku, která mapuje hodnoty (například mapování MSFT na Microsoft), aby je seskupila dohromady.
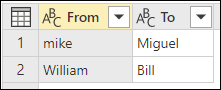
V tomto příkladu se transformační tabulka používá k předvedení způsobu mapování hodnot. Tabulka transformace má dva sloupce:
- From: Textový řetězec, který chcete vyhledat v tabulce.
- To: Textový řetězec, který se má použít k nahrazení textového řetězce ve sloupci Od .
Následující obrázek znázorňuje transformační tabulku použitou v tomto příkladu.
Důležité
Je důležité, aby tabulka transformace měla stejné sloupce a názvy sloupců, jak je znázorněno na předchozím obrázku (musí být označeny jako Od a Komu). Jinak Power Query tabulku nerozpozná jako transformační tabulku.
Vraťte se do dialogového okna Seskupit podle , rozbalte možnosti skupiny Fuzzy, změňte operaci z Count rows na Všechny řádky, povolte možnost Zobrazit skóre podobnosti a pak vyberte rozevírací nabídku Transformační tabulka .
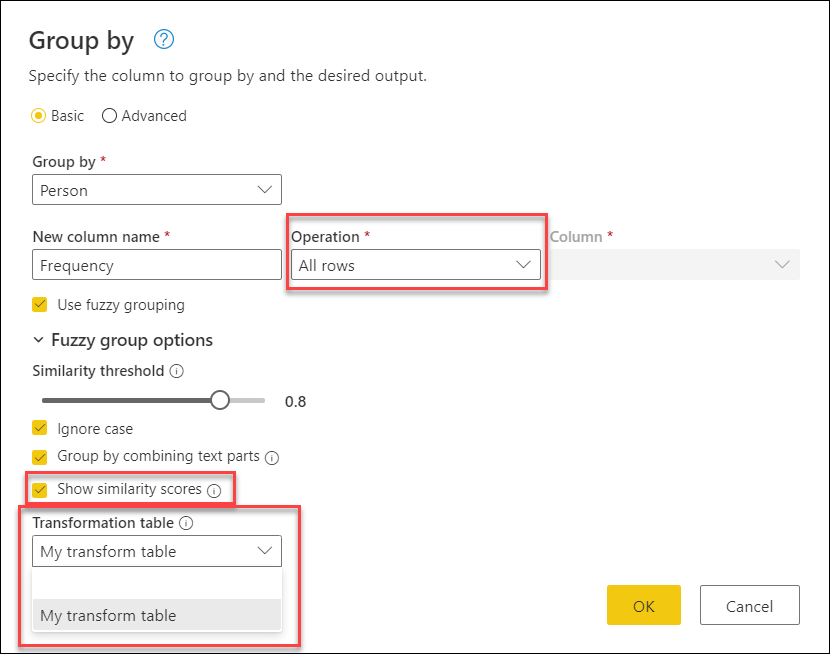
Po výběru transformační tabulky vyberte OK. Výsledek této operace vám poskytne následující informace:
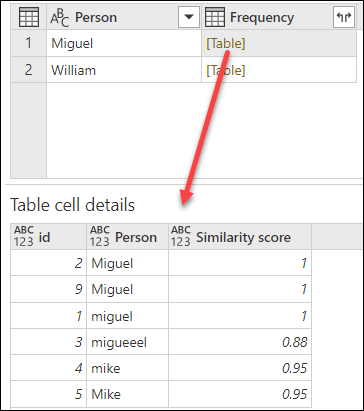
V tomto příkladu byla povolena možnost Ignorovat malá a velká písmena , takže hodnoty ve sloupci Od v transformační tabulce slouží k vyhledání textového řetězce bez ohledu na případ řetězce. Nejprve proběhne tato transformační operace, a poté se provede operace fuzzy seskupování.
Skóre podobnosti se také zobrazuje v tabulce vedle sloupce osoby, která odráží přesně to, jak byly hodnoty seskupeny, a jejich odpovídající skóre podobnosti. Tento sloupec můžete v případě potřeby rozbalit nebo použít hodnoty z nových sloupců Frekvence pro jiné druhy transformací.
Poznámka:
Při seskupování podle více sloupců provede transformační tabulka operaci nahrazení ve všech sloupcích, pokud nahrazení hodnoty zvýší skóre podobnosti.
Další informace o fungování transformačních tabulek najdete v tématu Precepty transformační tabulky.