Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Při aktualizaci v Power Query se na pozadí hodně snažíte zajistit bezproblémové uživatelské prostředí a efektivně a bezpečně spouštět dotazy. V některých případech si ale můžete všimnout, že Power Query při aktualizaci dat aktivuje více požadavků na zdroj dat. Někdy jsou tyto požadavky normální, ale jindy je možné jim zabránit.
Když dojde k více žádostem
Následující části popisují několik instancí, kdy Power Query může odesílat více požadavků do zdroje dat.
Návrh spojnice
Konektory můžou provádět několik volání zdroje dat z různých důvodů, včetně metadat, ukládání výsledků do mezipaměti, stránkování atd. Toto chování je normální a je navržené tak, aby fungovalo tímto způsobem.
Více dotazů odkazujících na jeden zdroj dat
Pokud z daného zdroje dat načítá více dotazů, může dojít k více žádostem o stejný zdroj dat. K těmto požadavkům může dojít i v případě, že pouze jeden dotaz odkazuje na zdroj dat. Pokud jeden nebo více jiných dotazů odkazuje na tento dotaz, pak se každý dotaz (spolu se všemi dotazy, na nichž závisí), vyhodnotí nezávisle.
V desktopovém prostředí se jedna aktualizace všech tabulek v datovém modelu spouští pomocí jedné sdílené mezipaměti. Ukládání do mezipaměti může snížit pravděpodobnost více požadavků na stejný zdroj dat, protože jeden dotaz může těžit ze stejného požadavku, který už byl spuštěn a uložen v mezipaměti pro jiný dotaz. I když tady můžete získat více požadavků, protože:
- Zdroj dat není uložený v mezipaměti (například místní soubory CSV).
- Požadavek na zdroj dat se liší od požadavku, který byl již uložen v mezipaměti z důvodu podřízených operací (což může změnit posouvání).
- Mezipaměť je příliš malá (což je poměrně nepravděpodobné).
- Dotazy běží přibližně ve stejnou dobu.
V cloudovém prostředí se každý dotaz aktualizuje pomocí vlastní samostatné mezipaměti. Dotaz proto nemůže těžit ze stejného požadavku, který už byl uložen do mezipaměti pro jiný dotaz.
Skládací
V některých případech může skládací vrstva Power Query generovat více požadavků na zdroj dat na základě operací, které se provádějí v podřízené části. V takových případech se můžete vyhnout více požadavků pomocí .Table.Buffer Další informace: Uložení tabulky do vyrovnávací paměti
Načítání do modelu Power BI Desktopu
V Power BI Desktopu služba Analysis Services (AS) aktualizuje data pomocí dvou vyhodnocení: jedno pro načtení schématu – což dělá AS tím, že požádáte o nulové řádky – a jedno pro načtení dat. Pokud výpočet schématu nulového řádku vyžaduje načtení dat, může dojít k duplicitním požadavkům na zdroj dat.
Analýza ochrany osobních údajů dat
Ochranaosobních Toto vyhodnocení může někdy způsobit více požadavků na zdroj dat. Znaménko řekněte, že daný požadavek pochází z analýzy ochrany osobních údajů dat, je to, že má podmínku TOP 1000 (i když tyto podmínky nepodporují všechny zdroje dat). Obecně platí, že zakázání ochrany osobních údajů dat za předpokladu, že je to přijatelné, by během aktualizace eliminovalo "TOP 1000" nebo jiné požadavky související s ochranou osobních údajů. Další informace: Zakázání brány firewall ochrany osobních údajů dat
Stahování dat na pozadí (označované také jako "analýza na pozadí")
Podobně jako u vyhodnocení provedených pro ochranu osobních údajů editor Power Query ve výchozím nastavení stáhne náhled prvních 1 000 řádků každého kroku dotazu. Stažení těchto řádků pomáhá zajistit, aby se náhled dat zobrazil hned po výběru kroku, ale může také způsobit duplicitní žádosti o zdroj dat. Další informace: Zakázání analýzy na pozadí
Různé úlohy editoru Power Query na pozadí
Různé úlohy na pozadí editoru Power Query můžou také aktivovat další požadavky na zdroje dat (například analýza skládání dotazů, profilace sloupců, automatická aktualizace náhledu 1000 řádků, kterou Power Query aktivuje po načtení výsledků do Excelu atd.).
Izolace více dotazů
Instance více dotazů můžete izolovat vypnutím konkrétních částí procesu dotazu, abyste izolovali, odkud duplicitní požadavky přicházejí. Pokud například začnete:
- V editoru Power Query
- S vypnutou bránou firewall
- Když je analýza na pozadí zakázaná
- Profilace sloupců a všechny ostatní úlohy na pozadí jsou zakázané.
- [Volitelné] Dělá se
Table.Buffer
V tomto příkladu máte jenom jedno vyhodnocení jazyka M, ke kterému dochází při aktualizaci náhledu editoru Power Query. Pokud v tomto okamžiku dojde k duplicitním požadavkům, jsou nějakým způsobem vnitřně vytvořeného dotazu. Pokud ne, a pokud povolíte dříve popsaná nastavení 1 po druhém, můžete sledovat, v jakém okamžiku se začnou objevovat duplicitní požadavky.
Následující části popisují tyto kroky podrobněji.
Nastavení editoru Power Query
Dotaz nemusíte znovu připojovat ani znovu vytvářet, stačí otevřít dotaz, který chcete otestovat v editoru Power Query. Dotaz můžete duplikovat v editoru, pokud nechcete s existujícím dotazem pokazit.
Zakázání brány firewall ochrany osobních údajů dat
Dalším krokem je zakázání brány firewall ochrany osobních údajů dat. Tento krok předpokládá, že vás nezajímá únik dat mezi zdroji, takže zakázání brány firewall ochrany osobních údajů dat je možné provést pomocí nastavení Úrovně ochrany osobních údajů vždy ignorovat popsané v možnosti Nastavit rychlou kombinování v Excelu nebo pomocí úrovní Ignorovat úroveň ochrany osobních údajů a potenciálně zlepšit nastavení výkonu popsané v úrovních ochrany osobních údajů v Power BI Desktopu v Power BI Desktopu.
Před obnovením normálního testování nezapomeňte tento krok vrátit zpět.
Zakázání analýzy na pozadí
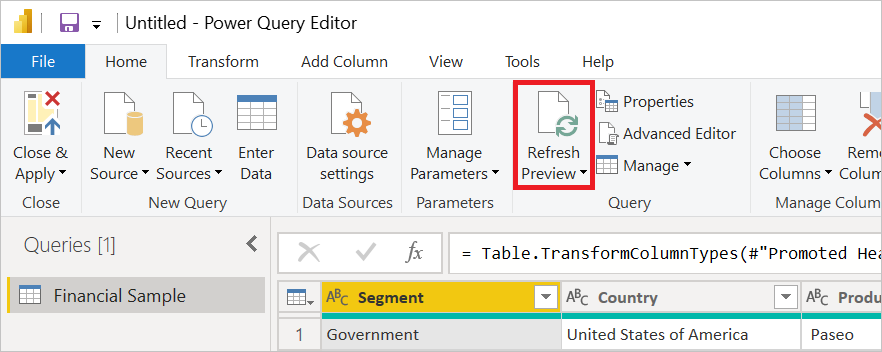
Dalším krokem je zakázání analýzy na pozadí. Analýza na pozadí se řídí nastavením Povolit stažení náhledu dat v nastavení na pozadí popsaném v části Zakázání aktualizace pozadí Power Query pro Power BI. Tuto možnost můžete také zakázat v Excelu.
Uložení tabulky do vyrovnávací paměti
Volitelně můžete také použít Table.Buffer k vynucení čtení všech dat, která napodobují to, co se stane během zatížení. Table.Buffer Použití v editoru Power Query:
Na řádku vzorců editoru Power Query vyberte tlačítko fx a přidejte nový krok.
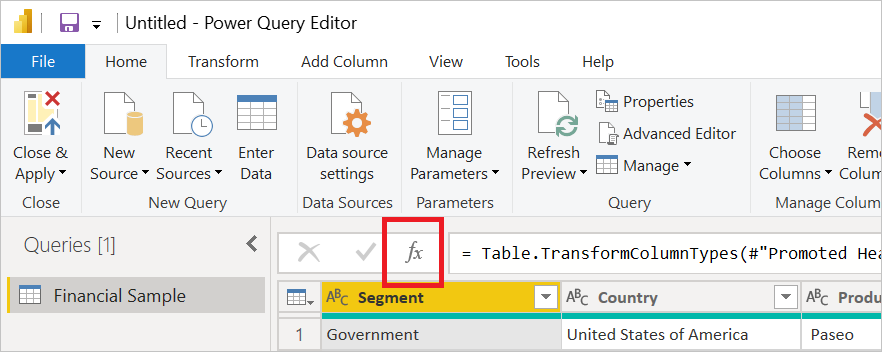
Do řádku vzorců zadejte název předchozího kroku do table.Buffer(<předchozí název kroku).> Pokud byl například předchozí krok pojmenován
Source, zobrazí= Sourcese řádek vzorců . Upravte krok v řádku vzorců tak, aby řekl= Table.Buffer(Source).
Další informace: Table.Buffer
Spuštění testu
Pokud chcete test spustit, proveďte aktualizaci v editoru Power Query.