Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Jednoduchost a snadné použití, které uživatelům Power BI umožňuje rychle shromažďovat data a generovat zajímavé a výkonné sestavy k provádění inteligentních obchodních rozhodnutí také umožňuje uživatelům snadno generovat špatně výkonné dotazy. K tomu často dochází, když existují dvě tabulky, které souvisejí způsobem, jakým cizí klíč souvisí s tabulkami SQL nebo sharepointovými seznamy. Jen pro záznam, tento problém není specifický pro SQL nebo SharePoint a dochází v mnoha scénářích extrakce back-endových dat, zejména v případě, že schéma je proměnlivé a přizpůsobitelné. S ukládáním dat do samostatných tabulek, které sdílejí společný klíč, není nic základně špatné – ve skutečnosti se jedná o základní princip návrhu a normalizace databází. Ale znamená to lepší způsob, jak rozšířit vztah.
Podívejte se na následující příklad seznamu zákazníků SharePointu.
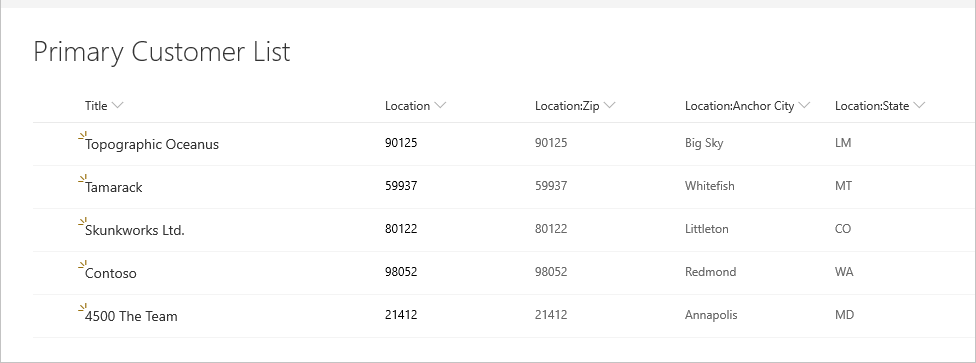
Seznam umístění, na který se odkazuje, je následující.
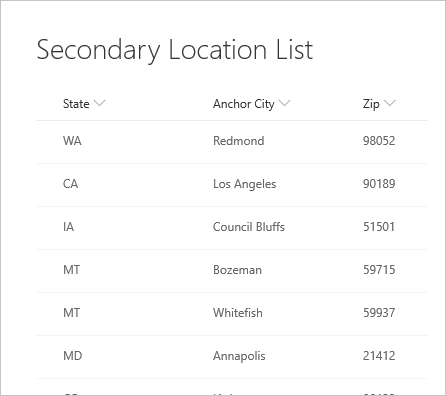
Při prvním připojení k seznamu se umístění zobrazí jako záznam.
Tato data nejvyšší úrovně se shromažďují prostřednictvím jediného volání HTTP rozhraní API služby SharePoint (bez ohledu na volání metadat), které můžete zobrazit v libovolném webovém ladicím programu.

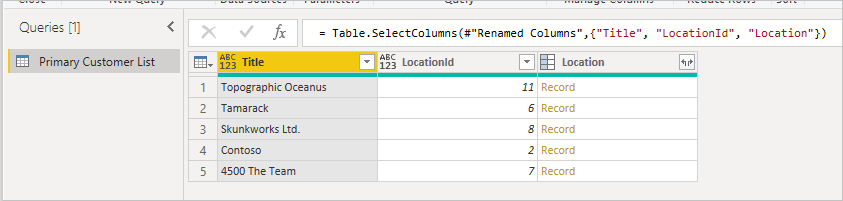
Když záznam rozbalíte, zobrazí se pole spojená ze sekundární tabulky.
Při rozbalování souvisejících řádků z jedné tabulky do druhé je ve výchozím nastavení v Power BI vygenerováno volání Table.ExpandTableColumn. Můžete to vidět v poli vygenerovaného vzorce. Tato metoda bohužel vygeneruje individuální volání druhé tabulky pro každý řádek v první tabulce.
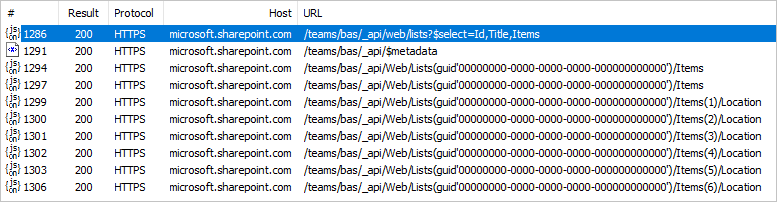
Tím se zvýší počet volání HTTP o jeden pro každý řádek v primárním seznamu. Nemusí to vypadat jako hodně v předchozím příkladu pěti nebo šesti řádků, ale v produkčních systémech, kde sharepointové seznamy dosáhnou stovek tisíc řádků, může to způsobit významné snížení výkonu.
Když dotazy dosáhnou tohoto kritického bodu, nejlepším řešením je vyhnout se chování volání na řádek pomocí klasického spojení tabulky. Tím je zajištěno, že bude pouze jedno volání k načtení druhé tabulky a zbytek rozšíření se může provést v paměti, a to pomocí společného klíče obou tabulek. Rozdíl v výkonu může být v některých případech obrovský.
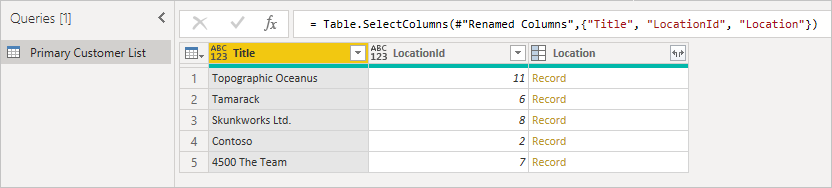
Nejprve začněte s původní tabulkou, zaznamenejte sloupec, který chcete rozšířit, a ujistěte se, že máte ID položky, abyste ji mohli odpovídajícím způsobem přiřadit. Cizí klíč se obvykle jmenuje podobně jako zobrazovaný název sloupce s připojeným ID . V tomto příkladu je to LocationId.
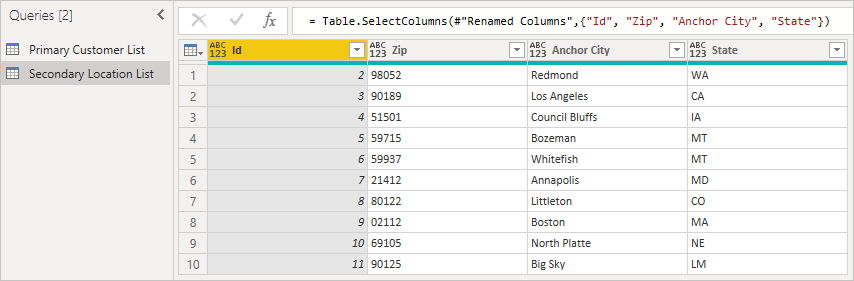
Za druhé načtěte sekundární tabulku a nezapomeňte zahrnout ID, což je cizí klíč. Kliknutím pravým tlačítkem myši na panel Dotazy vytvořte nový dotaz.
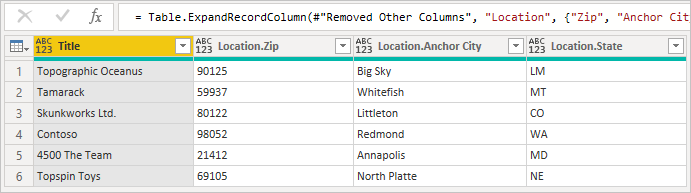
Nakonec obě tabulky spojte pomocí odpovídajících názvů sloupců. Toto pole můžete obvykle najít tak, že nejprve rozbalíte sloupec a pak vyhledáte odpovídající sloupce v náhledu.

V tomto příkladu vidíte, že ID umístění v primárním seznamu odpovídá ID v sekundárním seznamu. Uživatelské rozhraní toto přejmenuje na Location.Id , aby byl název sloupce jedinečný. Teď tyto informace použijeme ke sloučení tabulek.
Kliknutím pravým tlačítkem myši na panel dotazů a výběrem Nový dotaz>Spojit>Sloučit dotazy jako nový, se zobrazí přehledné uživatelské rozhraní, které vám pomůže tyto dva dotazy zkombinovat.
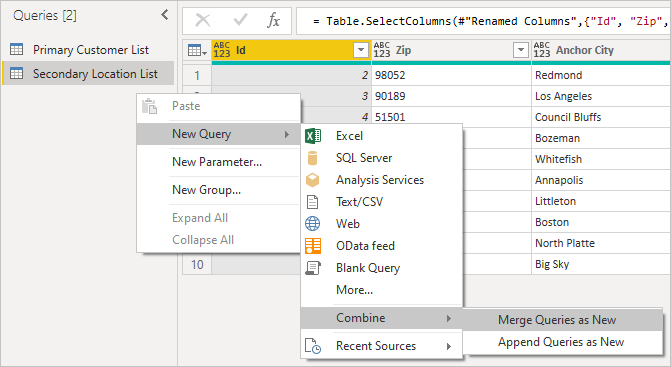
Výběrem každé tabulky v rozevíracím seznamu zobrazíte náhled dotazu.
Náhled sloučených dotazů
Jakmile vyberete obě tabulky, vyberte sloupec, který tabulky spojí logicky (v tomto příkladu je to LocationId z primární tabulky a ID ze sekundární tabulky). V dialogovém okně se dozvíte, kolik řádků odpovídá danému cizímu klíči. Pro tento druh dat budete pravděpodobně chtít použít výchozí typ spojení (levý vnější).
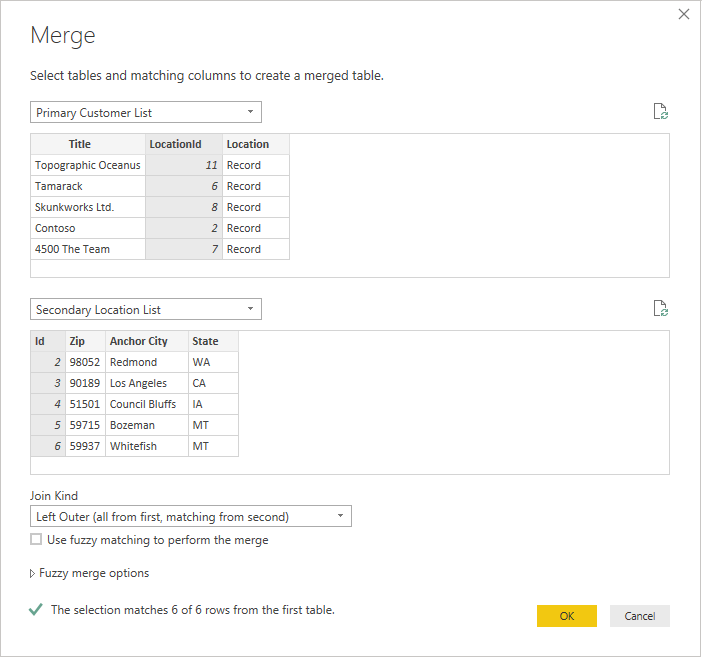
Vyberte OK a zobrazí se nový dotaz, což je výsledek spojení. Rozšíření záznamu teď neznamená další volání back-endu.

Aktualizace těchto dat bude mít za následek pouze dvě volání SharePointu – jedno pro primární seznam a jedno pro sekundární seznam. Spojení se provede v paměti, což výrazně snižuje počet volání na SharePoint.
Tento přístup lze použít pro všechny dvě tabulky v PowerQuery, které mají odpovídající cizí klíč.
Poznámka:
Seznamy uživatelů a taxonomie SharePointu jsou také přístupné jako tabulky a dají se připojit přesně způsobem popsaným výše, pokud má uživatel odpovídající oprávnění pro přístup k těmto seznamům.