Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Práce s textovými daty může být někdy nepořádná. Například název města Redmond může být reprezentován v databázi pomocí různých velikostí ("Redmond", "redmond" a "REDMOND"). To může způsobit problém při transformaci dat v Power Query, protože jazyk vzorců Power Query M rozlišuje malá a velká písmena.
Naštěstí Power Query M poskytuje funkce pro čištění a normalizaci písmen textových dat. Existují funkce pro převod textu na malá písmena (abc), velká písmena (ABC) nebo na počáteční velká písmena (Abc). Power Query M navíc nabízí několik způsobů, jak úplně ignorovat velká a malá písmena.
V tomto článku se dozvíte, jak změnit velká písmena v textu, seznamech a tabulkách. Popisuje také různé způsoby, jak ignorovat velká a malá písmena při manipulaci s daty v textu, seznamech a tabulkách. Kromě toho tento článek popisuje, jak řadit podle případu.
Změna velikosti písmen v textu
Existují tři funkce, které převádějí text na malá písmena, velká písmena a správnou velikost písmen. Funkce jsou Text.Lower, Text.Uppera Text.Proper. Následující jednoduché příklady ukazují, jak lze tyto funkce použít v textu.
Převod všech znaků v textu na malá písmena
Následující příklad ukazuje, jak převést všechny znaky v řetězci na malá písmena.
let
Source = Text.Lower("The quick brown fox jumps over the lazy dog.")
in
Source
Tento kód vytvoří následující výstup:
the quick brown fox jumps over the lazy dog.
Převod všech znaků v textu na velká písmena
Následující příklad ukazuje, jak převést všechny znaky v textovém řetězci na velká písmena.
let
Source = Text.Upper("The quick brown fox jumps over the lazy dog.")
in
Source
Tento kód vytvoří následující výstup:
THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG.
Převést všechna slova na počáteční velká písmena.
Následující příklad ukazuje, jak převést všechna slova ve větě na počáteční velká písmena.
let
Source = Text.Proper("The quick brown fox jumps over the lazy dog.")
in
Source
Tento kód vytvoří následující výstup:
The Quick Brown Fox Jumps Over The Lazy Dog.
Změna velikosti písmen v seznamech
Při změně velikosti písmen v seznamech je nejběžnější funkcí, která se má použít List.Transform. Následující jednoduché příklady ukazují, jak se tato funkce dá použít v seznamech.
Převod všech položek na malá písmena
Následující příklad ukazuje, jak změnit všechny položky v seznamu na malá písmena.
let
Source = {"Squash", "Pumpkin", "ApPlE", "pear", "orange", "APPLE", "Pear", "pear"},
#"Lower Case" = List.Transform(Source, Text.Lower)
in
#"Lower Case"
Tento kód vytvoří následující výstup:
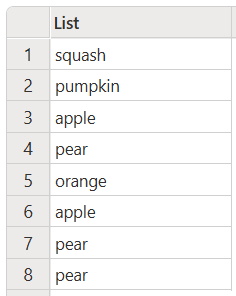
Převést všechny položky na velká písmena
Následující příklad ukazuje, jak změnit všechny položky v seznamu na velká písmena.
let
Source = {"Squash", "Pumpkin", "ApPlE", "pear", "orange", "APPLE", "Pear", "pear"},
#"Upper Case" = List.Transform(Source, Text.Upper)
in
#"Upper Case"
Tento kód vytvoří následující výstup:
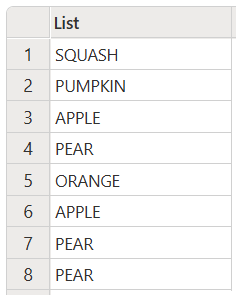
Převést všechny položky na správný formát zápisu
Následující příklad ukazuje, jak změnit všechny položky v seznamu na správný formát.
let
Source = {"Squash", "Pumpkin", "ApPlE", "pear", "orange", "APPLE", "Pear", "pear"},
#"Proper Case" = List.Transform(Source, Text.Proper)
in
#"Proper Case"
Tento kód vytvoří následující výstup:
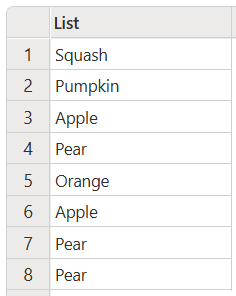
Změna velikosti písmen v tabulkách
Při změně velikosti písmen v tabulkách je nejběžnější funkcí, která se má použít Table.TransformColumns. K dispozici je také funkce, kterou můžete použít ke změně velikosti písmen textu obsaženého v řádku s názvem Table.TransformRows. Tato funkce se ale nepoužívá tak často.
Následující jednoduché příklady ukazují, jak Table.TransformColumns lze funkci použít ke změně případu v tabulkách.
Převedení všech položek ve sloupci tabulky na malá písmena
Následující příklad ukazuje, jak změnit všechny položky ve sloupci tabulky na malá písmena, v tomto případě jména zákazníků.
let
Source = #table(type table [CUSTOMER = text, FRUIT = text],
{
{"Tulga", "Squash"},
{"suSanna", "Pumpkin"},
{"LESLIE", "ApPlE"},
{"Willis", "pear"},
{"Dilbar", "orange"},
{"ClaudiA", "APPLE"},
{"afonso", "Pear"},
{"SErgio", "pear"}
}),
#"Lower Case" = Table.TransformColumns(Source, {"CUSTOMER", Text.Lower})
in
#"Lower Case"
Tento kód vytvoří následující výstup:
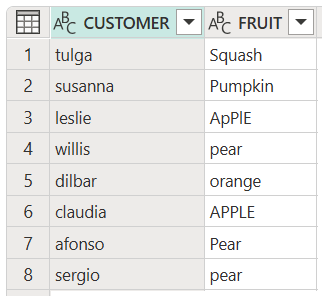
Převedení všech položek ve sloupci tabulky na velká písmena
Následující příklad ukazuje, jak změnit všechny položky ve sloupci tabulky na velká písmena, v tomto případě názvy ovoce.
let
Source = #table(type table [CUSTOMER = text, FRUIT = text],
{
{"Tulga", "Squash"},
{"suSanna", "Pumpkin"},
{"LESLIE", "ApPlE"},
{"Willis", "pear"},
{"Dilbar", "orange"},
{"ClaudiA", "APPLE"},
{"afonso", "Pear"},
{"SErgio", "pear"}
}),
#"Upper Case" = Table.TransformColumns(Source, {"FRUIT", Text.Upper})
in
#"Upper Case"
Tento kód vytvoří následující výstup:
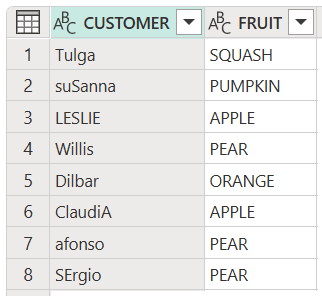
Převedení všech položek v tabulce na správné písmo
Následující příklad ukazuje, jak změnit všechny položky v obou sloupcích tabulky do správného formátu.
let
Source = #table(type table [CUSTOMER = text, FRUIT = text],
{
{"Tulga", "Squash"},
{"suSanna", "Pumpkin"},
{"LESLIE", "ApPlE"},
{"Willis", "pear"},
{"Dilbar", "orange"},
{"ClaudiA", "APPLE"},
{"afonso", "Pear"},
{"SErgio", "pear"}
}),
#"Customer Case" = Table.TransformColumns(Source, {"CUSTOMER", Text.Proper}),
#"Proper Case" = Table.TransformColumns(#"Customer Case", {"FRUIT", Text.Proper})
in
#"Proper Case"
Tento kód vytvoří následující výstup:
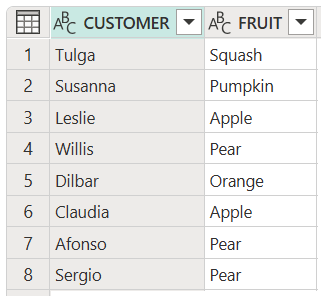
Ignorování velikosti písmen
V mnoha případech při hledání nebo nahrazování položek možná budete muset ignorovat případ hledané položky. Vzhledem k tomu, že jazyk vzorců Power Query M rozlišuje malá a velká písmena, porovnání mezi položkami, které jsou identické, ale mají různé případy, mají za následek identifikaci položek jako odlišných, ne identických. Jedna metoda ignorování případu zahrnuje použití Comparer.OrdinalIgnoreCase funkce ve funkcích, které zahrnují parametr equationCriteria nebo comparer parametr. Další metodou ignorování případu je použití IgnoreCase možnosti (pokud je k dispozici) ve funkcích, které obsahují options parametr.
Ignorování velikosti písmen v textu
Hledání v textu někdy vyžaduje ignorování velikosti písma, abyste mohli najít všechny výskyty hledaného textu. Textové funkce obecně používají funkci Comparer.OrdinalIgnoreCase v parametru comparer, aby velikost písma byla ignorována při testování rovnosti.
Následující příklad ukazuje, jak ignorovat případ při určování, zda věta obsahuje konkrétní slovo bez ohledu na velikost písmen.
let
Source = Text.Contains(
"The rain in spain falls mainly on the plain.",
"Spain",
Comparer.OrdinalIgnoreCase
)
in
Source
Tento kód vytvoří následující výstup:
true
Následující příklad ukazuje, jak načíst počáteční pozici posledního výskytu slova "the" ve větě bez ohledu na velká a malá písmena.
let
Source = Text.PositionOf(
"THE RAIN IN SPAIN FALLS MAINLY ON THE PLAIN.",
"the",
Occurrence.Last,
Comparer.OrdinalIgnoreCase
)
in
Source
Tento kód vytvoří následující výstup:
34
Ignorování velkých a malých písmen v seznamech
Libovolná funkce seznamu, která obsahuje volitelný equationCriteria parametr, může použít funkci Comparer.OrdinalIgnoreCase k ignorování rozdílů mezi velkými a malými písmeny v seznamu.
Následující příklad zkontroluje, zda seznam obsahuje určitou položku, přičemž ignoruje velikost písmen. V tomto příkladu List.Contains můžete porovnat pouze jednu položku v seznamu, nemůžete porovnat seznam se seznamem. K tomu musíte použít List.ContainsAny.
let
Source = List.Contains(
{"Squash", "Pumpkin", "ApPlE", "pear", "orange", "APPLE", "Pear", "pear"},
"apple",
Comparer.OrdinalIgnoreCase
)
in
Source
Tento kód vytvoří následující výstup:
true
Následující příklady ověřují, zda seznam obsahuje všechny zadané položky ve druhém parametru (value), přičemž se nebere ohled na velikost písmen. Pokud některá položka není obsažena v seznamu, například cucumber v druhém příkladu, vrátí funkce hodnotu NEPRAVDA.
let
Source = List.ContainsAll(
{"Squash", "Pumpkin", "ApPlE", "pear", "orange", "APPLE", "Pear", "pear"},
{"apple", "pear", "squash", "pumpkin"},
Comparer.OrdinalIgnoreCase
)
in
Source
Tento kód vytvoří následující výstup:
true
let
Source = List.ContainsAll(
{"Squash", "Pumpkin", "ApPlE", "pear", "orange", "APPLE", "Pear", "pear"},
{"apple", "pear", "squash", "pumpkin", "cucumber"},
Comparer.OrdinalIgnoreCase
)
in
Source
Tento kód vytvoří následující výstup:
false
Následující příklad zkontroluje, zda některé položky v seznamu jsou jablka nebo hrušně, zatímco ignoruje velká písmena.
let
Source = List.ContainsAny(
{"Squash", "Pumpkin", "ApPlE", "PEAR", "orange", "APPLE", "Pear", "peaR"},
{"apple","pear"},
Comparer.OrdinalIgnoreCase
)
in
Source
Tento kód vytvoří následující výstup:
true
Následující příklad zachovává pouze jedinečné položky a ignoruje velikost písmen.
let
Source = List.Distinct(
{"Squash", "Pumpkin", "ApPlE", "PEAR", "orange", "APPLE", "Pear", "peaR"},
Comparer.OrdinalIgnoreCase
)
in
Source
Tento kód vytvoří následující výstup:
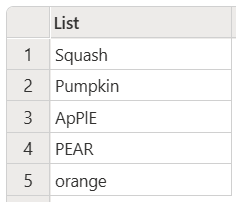
V předchozím příkladu výstup zobrazí případ první jedinečné položky nalezené v seznamu. Takže i když existují dvě jablka (ApPlE a APPLE), zobrazí se pouze první nalezený příklad.
Následující příklad uchovává pouze jedinečné položky při ignorování velkých a malých písmen, ale také vrátí všechny výsledky malých písmen.
let
Source = List.Distinct(
{"Squash", "Pumpkin", "ApPlE", "PEAR", "orange", "APPLE", "Pear", "peaR"},
Comparer.OrdinalIgnoreCase
),
#"Lower Case" = List.Transform(Source, Text.Lower)
in
#"Lower Case"
Tento kód vytvoří následující výstup:
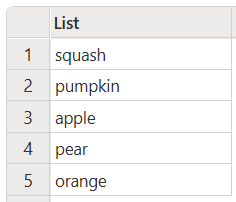
Ignorování velikosti písmen v tabulkách
Tabulky mají několik způsobů, jak ignorovat velikost písmen. Tabulkové funkce jako Table.Contains, Table.Distinct a Table.PositionOf všechny obsahují equationCriteria parametry. Tyto parametry mohou používat funkci Comparer.OrdinalIgnoreCase k ignorování velkých a malých písmen v tabulkách, a to podobným způsobem jako seznamy v předchozích částech. Tabulkové funkce, jako je Table.MatchesAnyRows, které obsahují parametr condition, mohou také použít Comparer.OrdinalIgnoreCase, zabalené v jiných tabulkových funkcích, k ignorování velkých a malých písmen. Další funkce tabulky, konkrétně pro přibližné porovnávání, můžou tuto možnost použít IgnoreCase .
Následující příklad ukazuje, jak vybrat konkrétní řádky, které obsahují slovo "hrušeň" při ignorování písmen. V tomto příkladu se parametr condition používá s Text.Contains jako podmínkou pro porovnání a zároveň se ignoruje velikost písmen.
let
Source = #table(type table[CUSTOMER = text, FRUIT = text],
{
{"Tulga", "Squash"},
{"suSanna", "Pumpkin"},
{"LESLIE", "ApPlE"},
{"Willis", "pear"},
{"Dilbar", "orange"},
{"ClaudiA", "APPLE"},
{"afonso", "Pear"},
{"SErgio", "pear"}
}),
#"Select Rows" = Table.SelectRows(
Source, each Text.Contains([FRUIT], "pear", Comparer.OrdinalIgnoreCase))
in
#"Select Rows"
Tento kód vytvoří následující výstup:

Následující ukázka ukazuje, jak určit, zda některý z řádků v tabulce obsahuje pear ve sloupci FRUIT. Tento příklad používá Comparer.OrdinalIgnoreCase v rámci funkce Text.Contains s použitím parametru condition funkce Table.MatchesAnyRows.
let
Source = #table(type table [CUSTOMER = text, FRUIT = text],
{
{"Tulga", "Squash"},
{"suSanna", "Pumpkin"},
{"LESLIE", "ApPlE"},
{"Willis", "PEAR"},
{"Dilbar", "orange"},
{"ClaudiA", "APPLE"},
{"afonso", "Pear"},
{"SErgio", "peAR"}
}),
#"Select Rows" = Table.MatchesAnyRows(Source,
each Text.Contains([FRUIT], "pear", Comparer.OrdinalIgnoreCase))
in
#"Select Rows"
Tento kód vytvoří následující výstup:
true
Následující příklad ukazuje, jak vzít tabulku s hodnotami zadanými uživateli, kteří obsahují sloupec se seznamem svých oblíbených plodů, bez nastaveného formátu. Tento sloupec je nejprve přibližně porovnán, aby se z něj extrahovaly názvy jejich oblíbeného ovoce, které se pak zobrazí ve vlastním sloupci s názvem Cluster. Pak se prověří sloupec Cluster a určí různé odlišné plody, které jsou ve sloupci. Jakmile se určí jedinečné ovoce, je posledním krokem změna všech názvů ovoce na malá písmena.
let
// Load a table of user's favorite fruits into Source
Source = #table(type table [Fruit = text], {{"blueberries"},
{"Blue berries are simply the best"}, {"strawberries"}, {"Strawberries = <3"},
{"Apples"}, {"'sples"}, {"4ppl3s"}, {"Bananas"}, {"fav fruit is bananas"},
{"Banas"}, {"My favorite fruit, by far, is Apples. I simply love them!"}}
),
// Create a Cluster column and fuzzy match the fruits into that column
#"Cluster fuzzy match" = Table.AddFuzzyClusterColumn(
Source, "Fruit", "Cluster",
[IgnoreCase = true, IgnoreSpace = true, Threshold = 0.5]
),
// Find the distinct fruits from the Cluster column
#"Ignore cluster case" = Table.Distinct(
Table.SelectColumns(#"Cluster fuzzy match", "Cluster"),
Comparer.OrdinalIgnoreCase
),
// Set all of the distinct fruit names to lower case
#"Set lower case" = Table.TransformColumns(#"Ignore cluster case",
{"Cluster", Text.Lower}
)
in
#"Set lower case"
Tento kód vytvoří následující výstup:
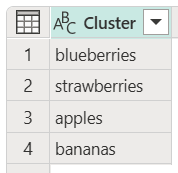
Velikost písmen a řazení
Seznamy i tabulky je možné řadit pomocí List.Sort nebo Table.Sort, a to v uvedeném pořadí. Řazení textu ale závisí na velikosti přidružených položek v seznamu nebo tabulce, aby bylo možné určit skutečné pořadí řazení (vzestupně nebo sestupně).
Nejběžnější forma řazení používá text, který je buď malými písmeny, velkými písmeny, nebo s velkým písmenem na začátku každého slova. Pokud existuje kombinace těchto případů, vzestupné pořadí řazení je následující:
- Jakýkoli text v seznamu nebo sloupci tabulky, který začíná velkým písmenem, je první.
- Pokud existuje odpovídající text, ale jeden je ve správném tvaru a druhý je všechna velká písmena, verze s velkými písmeny je první.
- Potom se seřadí malá písmena.
V sestupném pořadí se předchozí kroky zpracovávají obráceně.
Například následující ukázka obsahuje kombinaci textu s malými písmeny, textu s velkými písmeny a textu s velkými počátečními písmeny, které mají být seřazeny vzestupně.
let
Source = { "Alpha", "Beta", "Zulu", "ALPHA", "gamma", "alpha",
"beta", "Gamma", "Sierra", "zulu", "GAMMA", "ZULU" },
SortedList = List.Sort(Source, Order.Ascending)
in
SortedList
Tento kód vytvoří následující výstup:
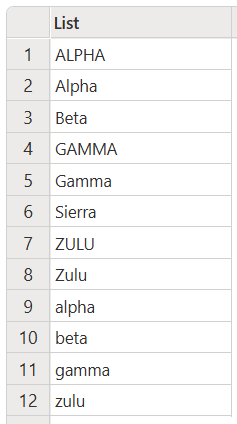
Ačkoli to není běžné, můžete narazit na kombinaci velkých a malých písmen v textu, které je třeba seřadit. Vzestupné pořadí řazení v tomto případě je:
- Jakýkoli text v seznamu nebo sloupci tabulky, který začíná velkým písmenem, je první.
- Pokud existuje odpovídající text, dále se provede text s největším počtem velkých písmen, který se nachází nejvíce vlevo.
- Poté se malá písmena seřadí tak, že nejprve je provedeno seřazení s maximálním počtem velkých písmen napravo.
V každém případě může být vhodnější před řazením převést text na konzistentní případ.
Normalizace Power BI Desktopu
Power Query M rozlišuje malá a velká písmena a rozpoznává různé kapitalizace stejného textu. Například "Foo", "foo" a "FOO" jsou považovány za odlišné. Pokud se ale data načtou do Power BI Desktopu, textové hodnoty se normalizují, což znamená, že Power BI Desktop je považuje za stejnou hodnotu bez ohledu na jejich velká písmena. Proto pokud potřebujete transformovat data při zachování citlivosti na malá a velká písmena v datech, měli byste před načtením dat do Power BI Desktopu zpracovat transformaci dat v Power Query.
Například následující tabulka v Power Query zobrazuje různé případy v každém řádku tabulky.
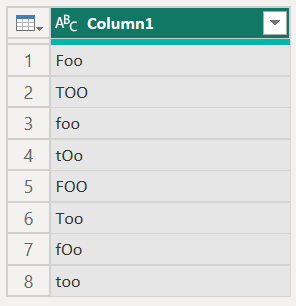
Když se tato tabulka načte do Power BI Desktopu, textové hodnoty se normalizují, což vede k následující tabulce.
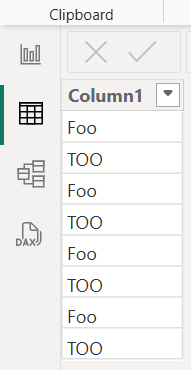
První instance "foo" a první instance "too" určují formát "foo" a "too" ve zbývajících řádcích v tabulce Power BI Desktopu. V tomto příkladu jsou všechny instance "foo" normalizovány na hodnotu "Foo" a všechny instance "too" jsou normalizovány na hodnotu "TOO".