Řešení problémů se nerovnoměrnou distribucí dat v Azure Data Lake Analytics pomocí Nástroje Azure Data Lake pro Visual Studio
Důležité
Azure Data Lake Analytics vyřazena 29. února 2024. Další informace najdete v tomto oznámení.
Pro analýzu dat může vaše organizace používat Azure Synapse Analytics nebo Microsoft Fabric.
Co je nerovnoměrná distribuce dat?
Stručně řečeno, nerovnoměrná distribuce dat je nadměrně reprezentovaná hodnota. Představte si, že jste k auditování daňových přiznání přiřadili 50 daňových kontrolérů, jednoho pro každý stát USA. Wyomingův zkoušeč, protože tamní populace je malá, nemá moc co dělat. V Kalifornii je však zkoušecí zaneprázdněný kvůli velké populaci státu.

V našem scénáři jsou data rovnoměrně rozdělena mezi všechny správce daně, což znamená, že někteří kontrolátoři musí pracovat více než jiní. Ve své vlastní práci se často setkáte se situacemi, jako je příklad daňového zkoušeče. Technicky řečeno, jeden vrchol získá mnohem více dat než jeho peers, což je situace, kdy vrchol funguje více než ostatní a která nakonec zpomalí celou úlohu. A co je horší, úloha může selhat, protože vrcholy můžou mít například 5hodinové omezení běhu a 6 GB paměti.
Řešení problémů se nerovnoměrnou distribucí dat
Nástroje Azure Data Lake pro Visual Studio a Visual Studio Code vám můžou pomoct zjistit, jestli vaše úloha nemá problém se nerovnoměrnou distribuci dat.
- Instalace nástrojů Azure Data Lake pro Visual Studio
- Instalace Nástroje Azure Data Lake pro Visual Studio kódu
Pokud problém existuje, můžete ho vyřešit vyzkoušením řešení v této části.
Řešení 1: Vylepšení dělení tabulek
Možnost 1: Předem vyfiltrujte hodnotu zkosené klíče.
Pokud to nemá vliv na obchodní logiku, můžete hodnoty s vyšší frekvencí předem filtrovat. Pokud je například v identifikátoru GUID sloupce mnoho hodnot 000-000-000, možná nebudete chtít tuto hodnotu agregovat. Před agregací můžete zapsat "WHERE GUID != "000-000-000"" pro filtrování hodnoty vysoké frekvence.
Možnost 2: Výběr jiného oddílu nebo distribučního klíče
Pokud chcete v předchozím příkladu zkontrolovat jenom úlohu daňového auditu v celé zemi nebo oblasti, můžete zlepšit distribuci dat tak, že jako klíč vyberete číslo ID. Výběr jiného oddílu nebo distribučního klíče může někdy distribuovat data rovnoměrněji, ale musíte se ujistit, že tato volba nemá vliv na obchodní logiku. Pokud například chcete vypočítat součet daně pro každý stát, můžete jako klíč oddílu určit State . Pokud k tomuto problému dochází i nadále, zkuste použít možnost 3.
Možnost 3: Přidání dalších oddílů nebo distribučních klíčů
Místo použití pouze State jako klíče oddílu můžete k dělení použít více než jeden klíč. Zvažte například přidání PSČ jako dalšího klíče oddílu, abyste snížili velikost datových oddílů a distribuují data rovnoměrněji.
Možnost 4: Použití distribuce kruhového dotazování
Pokud nemůžete najít vhodný klíč pro oddíl a distribuci, můžete zkusit použít distribuci kruhového dotazování. Rozdělení kruhového dotazování zachází se všemi řádky stejně a náhodně je umístí do odpovídajících kbelíků. Data se rovnoměrně distribuují, ale ztratí informace o lokalitě, což je nevýhoda, která může také snížit výkon úloh u některých operací. Kromě toho platí, že pokud přesto provádíte agregaci pro zkosený klíč, problém se nerovnoměrnou distribuce dat bude přetrvávat. Další informace o distribuci pomocí kruhového dotazování najdete v části Distribuce tabulek U-SQL v tématu VYTVOŘENÍ TABULKY (U-SQL): Vytvoření tabulky se schématem.
Řešení 2: Vylepšení plánu dotazů
Možnost 1: Použití příkazu CREATE STATISTICS
U-SQL poskytuje příkaz CREATE STATISTICS v tabulkách. Tento příkaz poskytuje optimalizátoru dotazů další informace o charakteristikách dat (například rozdělení hodnot), které jsou uložené v tabulce. U většiny dotazů už optimalizátor dotazů generuje potřebné statistiky pro vysoce kvalitní plán dotazů. Někdy může být potřeba zvýšit výkon dotazů vytvořením více statistik pomocí příkazu CREATE STATISTICS nebo úpravou návrhu dotazu. Další informace najdete na stránce CREATE STATISTICS (U-SQL).
Příklad kódu:
CREATE STATISTICS IF NOT EXISTS stats_SampleTable_date ON SampleDB.dbo.SampleTable(date) WITH FULLSCAN;
Poznámka
Informace o statistikách se neaktualizují automaticky. Pokud aktualizujete data v tabulce bez opětovného vytvoření statistiky, může se výkon dotazu zmenšit.
Možnost 2: Použití SKEWFACTOR
Pokud chcete sečíst daň pro každý stát, musíte použít metodu GROUP BY state, která se problému se nerovnoměrnou distribuci dat nevyhne. V dotazu ale můžete zadat nápovědu k datům, která identifikuje nerovnoměrnou distribuci dat v klíčích, aby vám optimalizátor mohl připravit plán provádění.
Obvykle můžete parametr nastavit jako 0,5 a 1, přičemž hodnota 0,5 znamená přílišnou nerovnoměrnou distribuci a jedna znamená velkou nerovnoměrnou distribuci. Vzhledem k tomu, že tato nápověda ovlivňuje optimalizaci plánu provádění pro aktuální příkaz a všechny podřízené příkazy, nezapomeňte přidat nápovědu před potenciální zkosenou agregaci podle klíče.
SKEWFACTOR (columns) = x
Naznačuje, že dané sloupce mají faktor nerovnoměrné distribuce x od 0 (bez nerovnoměrné distribuce) do 1 (velká nerovnoměrná distribuce).
Příklad kódu:
//Add a SKEWFACTOR hint.
@Impressions =
SELECT * FROM
searchDM.SML.PageView(@start, @end) AS PageView
OPTION(SKEWFACTOR(Query)=0.5)
;
//Query 1 for key: Query, ClientId
@Sessions =
SELECT
ClientId,
Query,
SUM(PageClicks) AS Clicks
FROM
@Impressions
GROUP BY
Query, ClientId
;
//Query 2 for Key: Query
@Display =
SELECT * FROM @Sessions
INNER JOIN @Campaigns
ON @Sessions.Query == @Campaigns.Query
;
Možnost 3: Použití funkce ROWCOUNT
Pokud víte, že druhá sada spojených řádků je malá, můžete kromě SKEWFACTOR pro konkrétní případy spojení s zkoseným klíčem zjistit, že optimalizátor přidáte do příkazu U-SQL před JOIN nápovědu ROWCOUNT. Optimalizátor tak může zvolit strategii připojení k vysílání, která pomůže zlepšit výkon. Mějte na paměti, že funkce ROWCOUNT problém se nerovnoměrnou distribuci dat nevyřeší, ale může nabídnout další pomoc.
OPTION(ROWCOUNT = n)
Identifikujte malou sadu řádků před join zadáním odhadovaného počtu celých řádků.
Příklad kódu:
//Unstructured (24-hour daily log impressions)
@Huge = EXTRACT ClientId int, ...
FROM @"wasb://ads@wcentralus/2015/10/30/{*}.nif"
;
//Small subset (that is, ForgetMe opt out)
@Small = SELECT * FROM @Huge
WHERE Bing.ForgetMe(x,y,z)
OPTION(ROWCOUNT=500)
;
//Result (not enough information to determine simple broadcast JOIN)
@Remove = SELECT * FROM Bing.Sessions
INNER JOIN @Small ON Sessions.Client == @Small.Client
;
Řešení 3: Vylepšení uživatelem definované redukce a kombinátoru
Někdy můžete napsat operátor definovaný uživatelem, který se bude zabývat složitou logikou procesu, a dobře napsaný redukce a kombinátor může v některých případech zmírnit problém se nerovnoměrnou distribuci dat.
Možnost 1: Pokud je to možné, použijte rekurzivní redukční nástroj.
Ve výchozím nastavení se redukční nástroj definovaný uživatelem spouští v nerekurzivním režimu, což znamená, že redukce práce pro klíč se distribuuje do jednoho vrcholu. Pokud jsou ale data nerovnoměrná, můžou se obrovské datové sady zpracovávat v jednom vrcholu a běžet dlouhou dobu.
Pokud chcete zvýšit výkon, můžete do kódu přidat atribut, který definuje redukci pro spuštění v rekurzivním režimu. Pak je možné obrovské datové sady distribuovat do několika vrcholů a běžet paralelně, což vaši úlohu zrychlí.
Pokud chcete změnit nerekurzivní redukci na rekurzivní, musíte se ujistit, že váš algoritmus je asociativní. Například součet je asociativní a medián není. Musíte také zajistit, aby vstup a výstup redukce zachovály stejné schéma.
Atribut rekurzivního redukčního reduktoru:
[SqlUserDefinedReducer(IsRecursive = true)]
Příklad kódu:
[SqlUserDefinedReducer(IsRecursive = true)]
public class TopNReducer : IReducer
{
public override IEnumerable<IRow>
Reduce(IRowset input, IUpdatableRow output)
{
//Your reducer code goes here.
}
}
Možnost 2: Pokud je to možné, použijte režim kombinátoru na úrovni řádků.
Podobně jako u nápovědy ROWCOUNT pro konkrétní případy spojení se zkoseným klíčem se režim kombinátoru pokouší distribuovat velké sady hodnot zkosených klíčů do více vrcholů, aby bylo možné práci provést souběžně. Režim kombinátoru nemůže vyřešit problémy se nerovnoměrnou distribucemi dat, ale může nabídnout další pomoc pro velké sady hodnot s nerovnoměrnou zkosenou velikostí.
Ve výchozím nastavení je režim kombinátoru Plný, což znamená, že sada levého řádku a pravá sada řádků nelze oddělit. Nastavením režimu vlevo/vpravo/vnitřní povolíte spojení na úrovni řádků. Systém odděluje odpovídající sady řádků a distribuuje je do více vrcholů, které běží paralelně. Než ale nakonfigurujete režim kombinátoru, ujistěte se, že je možné oddělit odpovídající sady řádků.
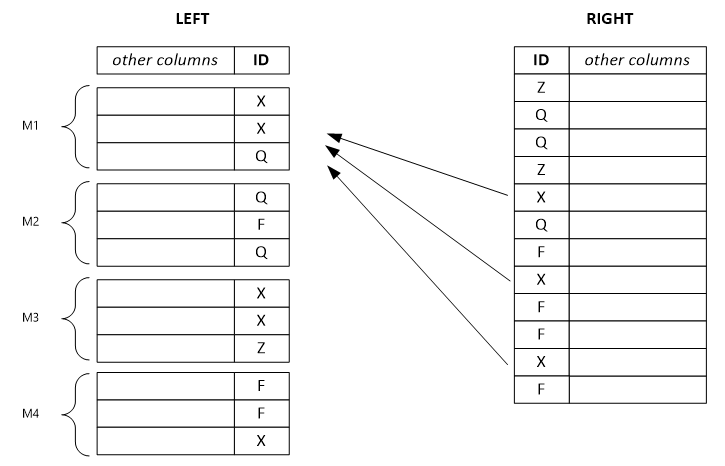
Následující příklad ukazuje oddělenou sadu levého řádku. Každý výstupní řádek závisí na jednom vstupním řádku zleva a potenciálně závisí na všech řádcích zprava se stejnou hodnotou klíče. Pokud nastavíte režim kombinátoru nalevo, systém rozdělí velkou sadu levého řádku na malé a přiřadí je k několika vrcholům.
Poznámka
Pokud nastavíte nesprávný režim kombinátoru, bude kombinace méně efektivní a výsledky můžou být chybné.
Atributy režimu kombinátoru:
SqlUserDefinedCombiner(Mode=CombinerMode.Full): Každý výstupní řádek potenciálně závisí na všech vstupních řádcích zleva a zprava se stejnou hodnotou klíče.
SqlUserDefinedCombiner(Mode=CombinerMode.Left): Každý výstupní řádek závisí na jednom vstupním řádku zleva (a potenciálně všechny řádky zprava se stejnou hodnotou klíče).
qlUserDefinedCombiner(Mode=CombinerMode.Right): Každý výstupní řádek závisí na jednom vstupním řádku zprava (a potenciálně všechny řádky zleva se stejnou hodnotou klíče).
SqlUserDefinedCombiner(Mode=CombinerMode.Inner): Každý výstupní řádek závisí na jednom vstupním řádku zleva a zprava se stejnou hodnotou.
Příklad kódu:
[SqlUserDefinedCombiner(Mode = CombinerMode.Right)]
public class WatsonDedupCombiner : ICombiner
{
public override IEnumerable<IRow>
Combine(IRowset left, IRowset right, IUpdatableRow output)
{
//Your combiner code goes here.
}
}