Maloobchodní prodejci a spotřebitelé se zaměřují na to, aby měli správné produkty a služby, které spotřebitelé chtějí zakoupit na marketplace. Při pohledu na maximalizaci prodeje jsou hlavní součástí nákupního prostředí produkty (nebo kombinace produktů). Dostupnost nabídek – inventář – je trvalým zájmem o značky spotřebitelů.
Inventář produktů, označovaný také jako sortiment skladových položek, je složitý problém, který se týká dodavatelského a logistického hodnotového řetězce. V tomto článku se zaměříme konkrétně na problém optimalizace sortimentu skladových položek, abychom maximalizovali výnosy ze spotřebního zboží.
Puzzle optimalizace sortimentu skladových položek lze vyřešit vývojem algoritmů, které odpovídají na následující otázky:
- Které skladové položky fungují nejlépe na daném trhu nebo v obchodě?
- Které skladové položky by měly být přiděleny danému trhu nebo úložišti na základě jejich výkonu?
- Které skladové položky mají nízké výkon a měly by být nahrazeny vyššími výkonovými skladovými jednotkami?
- Jaké další přehledy můžeme odvozovat o našich segmentech pro spotřebitele a trh?
Automatizace rozhodování
Značky spotřebitelů tradičně přistupovaly k problému poptávky spotřebitelů zvýšením počtu skladových položek v portfoliu skladových položek. Jak se zvýšil počet skladových položek a konkurence, odhaduje se, že 90 procent výnosů je přiděleno pouze 10 procent skladových položek produktů v rámci portfolia. Obvykle 80 procent výnosů nabíhá z 20 procent skladových položek. A tento poměr je kandidátem na zlepšení ziskovosti.
Tradiční metody statického vytváření sestav používají historická data, která omezují přehledy. V nejlepším případě se rozhodnutí stále provádějí a implementují ručně. To znamená lidský zásah a dobu zpracování. S pokrokem umělé inteligence a cloud computingu je možné využít pokročilou analýzu k poskytování řady možností a předpovědí. Tento druh automatizace zlepšuje výsledky a rychlost zákazníka.
Optimalizace sortimentu skladových položek
Řešení sortimentu skladových položek (SKU) musí zpracovávat miliony skladových položek segmentací prodejních dat do smysluplných a podrobných porovnání. Cílem řešení je využít pokročilou analýzu k maximalizaci prodeje v každé prodejně nebo obchodě laděním sortimentu produktů. Druhým cílem je eliminovat nedostatek zásob a zlepšit sortiment. Fiskálním cílem je zvýšení prodeje o 5 až deset procent. Za tímto účelem umožňují přehledy:
- Seznamte se s výkonem portfolia skladových položek a spravujte nízké výkony.
- Optimalizujte distribuci skladových položek, abyste snížili nedostatek zásob.
- Seznamte se s tím, jak nové skladové položky podporují krátkodobé a dlouhodobé strategie.
- Vytvářejte opakovatelné, škálovatelné a použitelné přehledy z existujících dat.
Popisná analýza
Popisné modely agregují datové body a prozkoumávají vztahy mezi faktory, které můžou ovlivnit prodej produktů. Tyto informace je možné rozšířit o některé externí datové body, jako jsou údaje o poloze, počasí a sčítání lidu. Vizualizace pomáhají lidem odvozovat přehledy interpretací dat. Při tom je ale pochopení omezené na to, co se stalo v předchozím prodejním cyklu nebo co se v aktuálním období děje (v závislosti na tom, jak často se data aktualizují).
Tradiční přístup k datovým skladům a vytváření sestav v tomto případě stačí k pochopení toho, jaké skladové položky byly v určitém časovém období nejlepší a nejhorší.
Následující obrázek znázorňuje typickou sestavu historických prodejních dat. Obsahuje několik bloků se zaškrtávacími políčky pro výběr kritérií pro filtrování výsledků. Střed zobrazuje dva pruhové grafy, které zobrazují prodej v průběhu času. První graf zobrazuje průměrný prodej podle týdne. Druhá zobrazuje množství po týdnech.

Prediktivní analýza
Historické generování sestav pomáhá pochopit, co se stalo. Nakonec chceme předpovědět, co se pravděpodobně stane. Pro tento účel můžou být užitečné předchozí informace. Můžeme například identifikovat sezónní trendy. Nemůže ale pomoct s scénáři citlivostní citlivosti, například při modelování zavedení nového produktu. Abychom to mohli udělat, musíme se zaměřit na modelování chování zákazníků, protože to je konečný faktor, který určuje prodej.
Podrobný pohled na problém: modely voleb
Začněme definováním toho, co hledáme a jaká data máme:
Optimalizace sortimentu znamená nalezení podmnožina produktů k prodeji, která maximalizuje očekávané výnosy. To je to, co hledáme.
Data transakcí se pravidelně shromažďují pro finanční účely.
Sortiment dat může obsahovat cokoli, co se týká skladových položek: Tady je příklad toho, co chceme:
- Počet skladových položek
- Popisy skladových položek
- Přidělená množství
- Zakoupená skladová položka a množství
- Časová razítka událostí (například nákupy)
- Cena skladové položky
- Cena skladové položky za POS
- Skladová úroveň každé skladové položky v libovolném časovém okamžiku
Tato data se bohužel neshromažďuje tak spolehlivě jako transakční data.
V tomto článku pro zjednodušení budeme zvažovat pouze data transakcí a data skladové položky, nikoli externí faktory.
I tak si všimněte, že vzhledem k množině n výrobků existuje 2n možných sortimentů. Díky tomu je problém optimalizace výpočetně náročný proces. Vyhodnocení všech možných kombinací je nepraktické s velkým počtem produktů. Proto jsou sortimenty obvykle segmentovány podle kategorie (například obilovin), umístění a dalších kritérií pro snížení počtu proměnných. Modely optimalizace se snaží vyříznout počet permutací na funkční podmnožinu.
Podstata problému spočívá v modelování chování spotřebitelů efektivně. V dokonalém světě budou produkty prezentované jim odpovídat těm, které chtějí koupit.
Matematické modely k předpovídání spotřebitelských voleb byly vyvinuty v průběhu desetiletí. Volba modelu nakonec určí nejvhodnější implementační technologii. Proto je shrneme a nabídneme několik aspektů.
Parametrické modely
Parametrické modely odhadují chování zákazníků pomocí funkce s omezenou sadou parametrů. Sadu parametrů odhadneme tak, aby co nejlépe vyhovovala datům, která máme k dispozici. Jednou z nejstarších a nejznámějších je multinomická logistická regrese (označovaná také jako MNL, logit více tříd nebo regrese softmaxu). Používá se k výpočtu pravděpodobností několika možných výsledků v klasifikačních problémech. V tomto případě můžete k výpočtu použít MNL:
Pravděpodobnost, že spotřebitel (c) zvolí položku (i) v určitém čase (t), vzhledem k množině položek dané kategorie v sortimentu (a) se známým nástrojem pro zákazníka (v).
Předpokládáme také, že nástroj položky může být funkcí jeho funkcí. Vnější informace mohou být také zahrnuty do míry utility (například deštník je užitečnější, když prší).
MNL často používáme jako srovnávací test pro jiné modely z důvodu jeho čitelnosti při odhadování parametrů a při vyhodnocování výsledků. Jinými slovy, pokud uděláte horší než MNL, váš algoritmus se nepoužívá.
Z MNL bylo odvozeno několik modelů, ale je nad rámec tohoto dokumentu, který je probírá.
Existují knihovny pro programovací jazyky R a Python. Pro R můžete použít glm (a deriváty). V Pythonu jsou scikit-learn, biogeme a larch. Tyto knihovny nabízejí nástroje pro určení problémů MNL a paralelních řešitelů, kteří hledají řešení na různých platformách.
V nedávné době byla navržena implementace modelů MNL na GPU pro výpočty složitých modelů s řadou parametrů, které by je jinak nespočítaly.
Neurální sítě s výstupní vrstvou softmaxu se efektivně používaly u velkých problémů s více třídami. Tyto sítě vytvářejí vektor výstupů, které představují rozdělení pravděpodobnosti nad řadou různých výsledků. V porovnání s jinými implementacemi jsou pomalé, ale dokážou zpracovat velký počet tříd a parametrů.
Neparametrické modely
I přes jeho popularitu MNL umístí některé významné předpoklady k lidskému chování, které mohou omezit jeho užitečnost. Konkrétně se předpokládá, že relativní pravděpodobnost osoby, která si zvolí mezi dvěma možnostmi, je nezávislá na dalších alternativách zavedených v sadě později. Ve většině případů je to nepraktické.
Pokud se vám například líbí produkt A a produkt B, vyberete si jednu z dalších 50 % času. Pojďme do mixu představit produkt C. Stále můžete zvolit produkt A 50 % času, ale nyní rozdělíte své preference 25% na produkt B a 25% na produkt C. Relativní pravděpodobnost se změnila.
MNL a deriváty také nemají žádný jednoduchý způsob, jak zohlednit náhrady, které jsou způsobeny zásobou nebo sortimentem (to znamená, že pokud nemáte jasnou představu a vybrat náhodnou položku mezi těmi, které jsou na polici).
Neparametrické modely jsou navržené tak, aby zohlednily náhrady a uložily méně omezení chování zákazníků.
Představují koncept hodnocení, kdy spotřebitelé vyjadřují striktní preference produktů v sortimentu. Jejich nákupní chování lze proto modelovat řazením produktů v sestupném pořadí podle preference.
Problém optimalizace sortimentu lze vyjádřit jako maximalizaci výnosů:
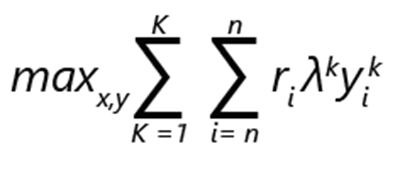
- ri označuje výnosy produktu i.
- yik je 1, pokud je produkt i vybrán v pořadí k. Jinak je to 0.
- λk je pravděpodobnost, že zákazník provede volbu podle pořadí k.
- xi je 1, pokud je výrobek součástí sortimentu. Jinak je to 0.
- K je počet hodnocení.
- n je počet výrobků.
Poznámka:
S výhradou omezení:
- Pro každé hodnocení může být přesně 1 volba.
- Pod hodnocením k lze produkt i vybrat pouze v případě, že je součástí sortimentu.
- Pokud je produkt i zahrnut v sortimentu, žádný z méně vhodnějších možností v pořadí k lze zvolit.
- Bez nákupu je možnost a jako takový žádný z méně vhodnějších možností v pořadí je možné zvolit.
V takové formulaci lze problém považovat za optimalizaci smíšených celých čísel.
Předpokládejme, že pokud existuje n produktů, maximální počet možných hodnocení, včetně možnosti bez výběru, je faktoriál: (n+1)!
Omezení ve formulaci umožňují relativně efektivní vyřezávání možných možností. Například je zvolena pouze nejvhodnější možnost a nastavena na hodnotu 1. Zbytek je nastavený na hodnotu 0. Můžete si představit, že škálovatelnost implementace bude důležitá vzhledem k počtu možných alternativ.
Důležitost dat
Zmínili jsme se, že prodejní data jsou snadno dostupná. Chceme ho použít k informování našeho modelu optimalizace sortimentu. Konkrétně chceme najít rozdělení pravděpodobnosti λ.
Data o prodeji z prodejního systému se skládají z transakcí, které mají časová razítka a sadu produktů, které se zobrazují zákazníkům v daném okamžiku a místě. Z těchto možností můžeme vytvořit vektor skutečného prodeje, jehož prvky vi,m představují pravděpodobnost prodeje položky i zákazníkovi vzhledem k sortimentu Sm
Můžeme také vytvořit matici:
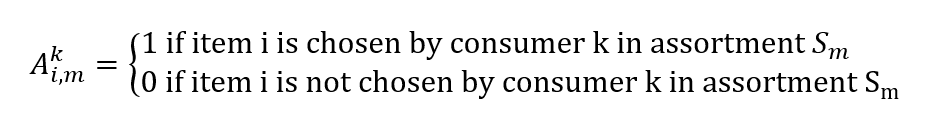
Nalezení rozdělení pravděpodobnosti λ vzhledem k prodejním datům se stává dalším problémem optimalizace. Chceme najít vektor λ, abychom minimalizovali chybu odhadu prodeje:
minλ |Λλ - v|
Všimněte si, že výpočet lze vyjádřit také jako regresi a jako takové lze použít modely jako rozhodovací stromy s více variatemi.
Podrobnosti implementace
Jak můžeme odvodit z předchozí formulace, optimalizační modely jsou náročné na data i výpočty.
Partneři Microsoftu, jako je Neal Analytics, vyvinuli robustní architektury, které splňují tyto podmínky. Viz Optimalizace sortimentu skladových položek. Tyto architektury použijeme jako příklad a nabídneme několik aspektů.
- Za prvé, spoléhají na robustní a škálovatelný datový kanál, který bude pouštět modely a robustní a škálovatelnou spouštěcí infrastrukturu.
- Za druhé jsou výsledky snadno využitelné plánovači prostřednictvím řídicího panelu.
Obrázek 2 znázorňuje ukázkovou architekturu. Zahrnuje čtyři hlavní bloky: zachytávání, zpracování, modelování a zprovoznění. Každý blok obsahuje hlavní procesy. Zachytávání zahrnuje předběžné zpracování dat; proces zahrnuje funkci ukládání dat; model zahrnuje funkci trénování modelu strojového učení; a zprovoznění zahrnuje možnosti ukládání dat a generování sestav (například řídicí panely).

Obrázek 2: Architektura optimalizace skladové položky, se svolením Neal Analytics
Datový kanál
Architektura zdůrazňuje důležitost vytvoření datového kanálu pro trénování i provoz modelu. Aktivity v kanálu orchestrujeme pomocí služby Azure Data Factory, spravované služby extrakce, transformace a načítání (ETL), která umožňuje navrhovat a spouštět vaše pracovní postupy integrace.
Azure Data Factory je spravovaná služba s komponentami označovanými jako aktivity , které spotřebovávají nebo vytvářejí datové sady.
Aktivity je možné rozdělit na:
- Přesun dat (například kopírování ze zdroje do cíle)
- Transformace dat (například agregace pomocí dotazu SQL nebo spuštění uložené procedury)
Pracovní postupy, které propojují sady aktivit, je možné naplánovat, monitorovat a spravovat pomocí služby datové továrny. Celý pracovní postup se nazývá kanál.
Ve fázi zachycení můžeme pomocí aktivity kopírování služby Data Factory přenášet data z různých zdrojů (místně i v cloudu) do Azure SQL Data Warehouse. Příklady toho, jak to udělat v dokumentaci:
Následující obrázek znázorňuje definici kanálu. Skládá se ze tří stejně velkých bloků v řádku. První dva jsou datová sada a aktivita propojená šipkami, která označuje toky dat. Třetí je označený kanál a odkazuje na první dva, aby indikoval zapouzdření.

Obrázek 3: Základní koncepty služby Azure Data Factory
Příklad formátu dat, který používá řešení Neal Analytics, najdete na stránce komerčního marketplace Microsoftu. Řešení obsahuje následující datové sady:
- Data historie prodejů pro každou kombinaci obchodu a skladové položky
- Ukládání a zaznamenávání příjemců
- Kódy a popis skladové položky
- Atributy skladové položky, které zachycují funkce produktů (například velikost a materiál). Ty se obvykle používají v parametrických modelech k rozlišení mezi variantami produktu.
Pokud zdroje dat nejsou vyjádřeny v konkrétním formátu, služba Data Factory nabízí řadu transformačních aktivit.
Ve fázi procesu je SQL Data Warehouse hlavním modulem úložiště. Takovou transformační aktivitu můžete vyjádřit jako uloženou proceduru SQL, kterou lze automaticky vyvolat jako součást kanálu. V dokumentaci najdete podrobné pokyny:
Služba Data Factory vás neomezuje na uložené procedury SQL Data Warehouse a SQL. Ve skutečnosti se integruje s celou řadou platforem. Můžete například použít Databricks a místo toho spustit skript Pythonu pro transformaci. To je výhoda, protože můžete použít jednu platformu pro ukládání, transformaci a trénování algoritmů strojového učení v následující fázi modelu.
Trénování algoritmu ML
Existuje několik nástrojů, které vám můžou pomoct s implementací parametrických a neparametrických modelů. Vaše volba závisí na vašich požadavcích na škálovatelnost a výkon.
Azure ML Studio je skvělý nástroj pro vytváření prototypů. Poskytuje snadný způsob, jak vytvořit a spustit trénovací pracovní postup pomocí modulů kódu (v R nebo Pythonu) nebo s předem definovanými komponentami ML (například klasifikátory s více třídami a zesílenou regresí rozhodovacího stromu) v grafickém prostředí. Také usnadňuje publikování natrénovaného modelu jako webové služby pro další spotřebu a generování rozhraní REST za vás.
Velikost dat, která dokáže zpracovat, je v současné době omezená na 10 GB a počet jader dostupných pro každou komponentu je omezen na dvě.
Pokud potřebujete provést další škálování, ale přesto chcete použít některé z rychlých paralelních implementací běžných algoritmů strojového učení (jako je multinomická logistická regrese), můžete zvážit, že Microsoft ML Server běží na virtuálním počítači Azure Datová Věda.
U velmi velkých objemů dat (TB) je vhodné zvolit platformu, kde úložiště a výpočetní prvek mohou:
- Nezávisle škálujte, abyste omezili náklady, když modely nevytrénujete.
- Distribuujte výpočet napříč několika jádry.
- Spuštěním výpočtu v blízkosti úložiště omezte přesun dat.
Azure HDInsight i Databricks tyto požadavky splňují. Kromě toho se jedná o obě platformy spouštění, které jsou podporované v editoru služby Azure Data Factory. Integrace jednoho z nich do pracovního postupu je poměrně jednoduchá.
ML Server a jeho knihovny je možné nasadit nad HDInsight, ale abyste plně využili výhod možností platformy, můžete implementovat zvolený algoritmus ML pomocí SparkML, knihoven Microsoft ML Spark v Pythonu nebo jiných specializovaných řešitelů lineárního programování, jako jsou TFoCS, Spark-LP nebo SolveDF.
Spuštěním procesu trénování se pak stane otázkou vyvolání příslušného skriptu pySpark nebo poznámkového bloku z pracovního postupu služby Data Factory. To je plně podporováno v grafickém editoru. Další podrobnosti najdete v tématu Spuštění poznámkového bloku Databricks s aktivitou poznámkového bloku Databricks ve službě Azure Data Factory.
Následující obrázek znázorňuje uživatelské rozhraní služby Data Factory, jak je přístupné prostřednictvím webu Azure Portal. Obsahuje bloky pro různé procesy v pracovním postupu.

Obrázek 4: Příklad kanálu služby Data Factory s aktivitou poznámkového bloku Databricks
Všimněte si také, že v našem řešení pro optimalizaci inventáře navrhujeme implementaci řešitelů na základě kontejneru, která se škáluje prostřednictvím služby Azure Batch. Specializované optimalizační knihovny, jako je pyomo , umožňují vyjádřit problém optimalizace pomocí programovacího jazyka Python a pak vyvolávat nezávislé řešitele, jako je bonmin (open source) nebo gurobi (komerční), aby našli řešení.
Dokumentace k optimalizaci zásob se zabývá jiným problémem (množství objednávek), než je optimalizace sortimentu, ale implementace řešitelů v Azure je podobně použitelná.
I když jsou zatím složitější než navrhované metody, umožňuje tato technika maximální škálovatelnost, která je omezená většinou počtem jader, které si můžete dovolit.
Spuštění modelu (zprovoznění)
Po vytrénování modelu obvykle vyžaduje jinou infrastrukturu, než je ta, která se používá k nasazení. Abyste ji mohli snadno použít, můžete ji nasadit jako webovou službu s rozhraním REST. Azure ML Studio i ML Server automatizují proces vytváření těchto služeb. V případě ML Serveru poskytuje Microsoft šablony pro nasazení podpůrné infrastruktury. Projděte si příslušnou dokumentaci.
Následující obrázek znázorňuje architekturu nasazení. Zahrnuje reprezentaci serverů, na kterých běží jazyk R a Python. Oba servery komunikují s dílčí částí webových uzlů, které provádějí výpočty. Velké úložiště dat je připojené k výpočetnímu bloku.

Obrázek 5: Příklad nasazení serveru ML
Modely vytvořené ve službě HDInsight nebo Databricks závisí na prostředí Sparku (knihovny, paralelní funkce atd.). Můžete je spustit v clusteru. Tady najdete pokyny. To má výhodu, že provozní model může být vyvolán prostřednictvím aktivity kanálu data Factory pro bodování.
Pokud chcete používat kontejnery, můžete modely zabalit a nasadit je ve službě Azure Kubernetes Service. Prototypy vyžadují použití virtuálního počítače Azure Datová Věda. Na virtuální počítač musíte také nainstalovat nástroje příkazového řádku Azure ML.
Výstup a generování sestav dat
Po nasazení může model zpracovávat pracovní postupy finančních transakcí a čtení zásob a generovat optimální predikce sortimentu. Takto vytvořená data je možné uložit zpět do Azure SQL Data Warehouse pro účely další analýzy. Konkrétně je možné prozkoumat historický výkon různých skladových položek, identifikovat nejlepší generátory výnosů a tvůrce ztrát. Pak je můžete porovnat s sortimenty, které modely navrhují, a vyhodnotit výkon a potřebu opětovného trénování.
Power BI nabízí způsob, jak analyzovat a zobrazit data vytvořená v procesu.
Následující obrázek znázorňuje typický řídicí panel Power BI. Obsahuje dva grafy, které zobrazují informace o skladové posílané skladové položky.
Bezpečnostní aspekty
Řešení, které se zabývá citlivými daty, obsahuje finanční záznamy, úrovně zásob a informace o cenách. Tato citlivá data musí být chráněna. Obavy týkající se zabezpečení a ochrany osobních údajů dat můžete zabezpečit následujícími způsoby:
- Některé kanály Azure Data Factory můžete spustit místně pomocí prostředí Azure Integration Runtime. Modul runtime provádí aktivity přesunu dat do místních zdrojů a z místních zdrojů. Odesílá také aktivity pro místní spouštění.
- Můžete vyvíjet vlastní aktivitu, která anonymizuje data pro přenos do Azure, a spouštět je místně.
- Všechny uvedené služby podporují šifrování během přenosu a neaktivních uložených dat. Pokud se rozhodnete data ukládat pomocí Azure Data Lake, šifrování je ve výchozím nastavení povolené. Pokud používáte Azure SQL Data Warehouse, můžete povolit transparentní šifrování dat (TDE).
- Všechny uvedené služby s výjimkou nástroje ML Studio podporují integraci s ID Microsoft Entra pro ověřování a autorizaci. Pokud píšete vlastní kód, musíte tuto integraci sestavit do své aplikace.
Další informace o obecném nařízení o ochraně osobních údajů (GDPR), nařízení o ochraně osobních údajů a ochraně osobních údajů v Evropské unii najdete na naší stránce dodržování předpisů .
Komponenty
V tomto článku byly uvedeny následující technologie:
- Azure Batch
- Microsoft Entra ID
- Azure Data Factory
- HDInsight
- Databricks
- Datová Věda Virtual Machines
- Azure Kubernetes Service
- Microsoft Power BI
Přispěvatelé
Tento článek spravuje Microsoft. Původně byla napsána následujícími přispěvateli.
Hlavní autor:
- Scott Seely | Softwarový architekt
Pokud chcete zobrazit neveřejné profily LinkedIn, přihlaste se na LinkedIn.
Další kroky
- Co je Azure Data Factory?
- Prostředí Integration Runtime ve službě Azure Data Factory
- Co je vyhrazený fond SQL (dříve SQL DW) ve službě Azure Synapse Analytics?
- Microsoft Machine Učení Studio (classic)
- Co je Machine Učení Server
- Jazyk modelování optimalizace Pyomo
- Řešitel Bonminu
- Řešitel TFoCS pro Spark
Související prostředky
Související pokyny pro maloobchod:
- Řešení pro maloobchod
- Migrace vašeho řešení elektronického obchodování do Azure
- Vizuální vyhledávání v maloobchodě s využitím služby Azure Cosmos DB
- Nasazení řešení detekce zápatí založeného na umělé inteligenci s využitím Azure a služby Azure Stack Hub
Související architektury: