Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
PLATÍ PRO: Platí pro. Machine Learning Studio (classic) Nevztahuje se na. Azure Machine Learning
Důležité
Podpora studia Machine Learning (Classic) skončí 31. srpna 2024. Doporučujeme do tohoto data přejít na službu Azure Machine Learning.
Od 1. prosince 2021 nebude možné vytvářet nové prostředky studia Machine Learning (Classic). Do 31. srpna 2024 můžete pokračovat v používání stávajících prostředků studia Machine Learning (Classic).
- Přečtěte si informace o přesunu projektů strojového učení ze sady ML Studio (classic) do služby Azure Machine Learning.
- Další informace o službě Azure Machine Learning
Dokumentace ke studiu ML (Classic) se vyřazuje z provozu a v budoucnu se nemusí aktualizovat.
Toto téma popisuje, jak zvolit správnou sadu hyperparametrů pro algoritmus v nástroji Machine Learning Studio (classic). Většina algoritmů strojového učení má parametry, které se mají nastavit. Při trénování modelu musíte zadat hodnoty pro tyto parametry. Účinnost natrénovaného modelu závisí na vámi zvolených parametrech modelu. Proces nalezení optimální sady parametrů se označuje jako výběr modelu.
Výběr modelu můžete provést různými způsoby. Ve strojovém učení je křížové ověřování jednou z nejčastěji používaných metod pro výběr modelu a jedná se o výchozí mechanismus výběru modelu v nástroji Machine Learning Studio (classic). Vzhledem k tomu, že Machine Learning Studio (classic) podporuje R i Python, můžete vždy implementovat vlastní mechanismy výběru modelu pomocí jazyka R nebo Python.
Při hledání nejlepší sady parametrů existují čtyři kroky:
- Definujte prostor parametrů: Pro algoritmus nejprve rozhodněte přesné hodnoty parametrů, které chcete zvážit.
- Definujte nastavení křížového ověření: Rozhodněte se, jak pro datovou sadu zvolit rozvrstvení křížového ověření.
- Definujte metriku: Rozhodněte se, jakou metriku použít k určení nejlepší sady parametrů, jako je přesnost, střední kvadratická chyba, přesnost, úplnost nebo f-skóre.
- Trénování, vyhodnocení a porovnání: Pro každou jedinečnou kombinaci hodnot parametrů se křížové ověření provádí a vychází z vámi definované metriky chyb. Po vyhodnocení a porovnání můžete zvolit nejvýkonnější model.
Následující obrázek znázorňuje, jak toho lze dosáhnout v nástroji Machine Learning Studio (classic).
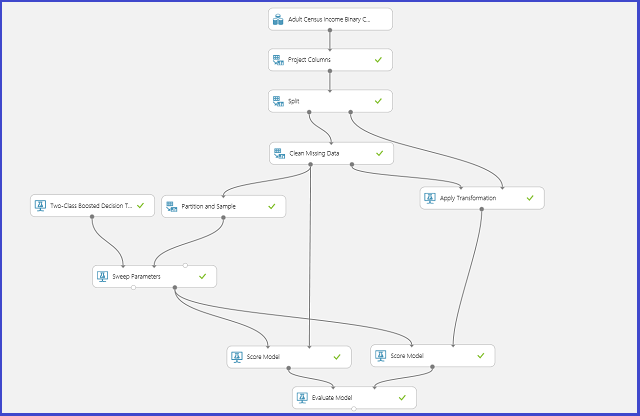
Definování prostoru parametrů
Sadu parametrů můžete definovat v kroku inicializace modelu. Podokno parametrů všech algoritmů strojového učení má dva režimy trenéra: jeden parametr a rozsah parametrů. Zvolte režim rozsahu parametrů. V režimu rozsahu parametrů můžete zadat více hodnot pro každý parametr. Do textového pole můžete zadat hodnoty oddělené čárkami.
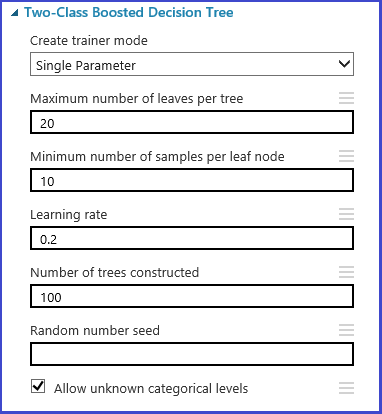
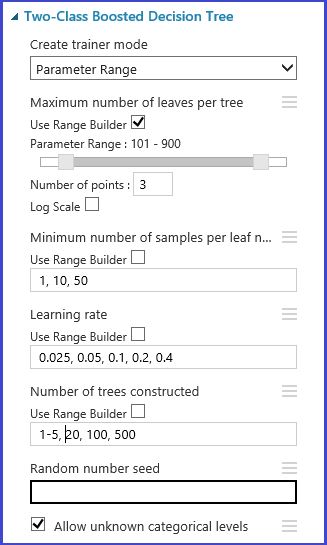
Alternativně můžete definovat maximální a minimální body mřížky a celkový počet bodů, které se mají vygenerovat pomocí nástroje Use Range Builder. Ve výchozím nastavení se hodnoty parametrů generují v lineárním měřítku. Pokud je ale zaškrtnuté měřítko protokolu, hodnoty se vygenerují ve měřítku protokolu (to znamená, že poměr sousedních bodů je místo jejich rozdílu konstantní). Pro celočíselné parametry můžete definovat rozsah pomocí spojovníku. Například "1-10" znamená, že všechna celá čísla mezi 1 a 10 (včetně) tvoří sadu parametrů. Podporuje se také smíšený režim. Například sada parametrů 1-10, 20, 50 by obsahovala celá čísla 1–10, 20 a 50.
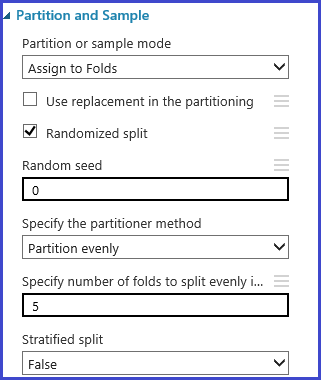
Definování záhybů křížového ověřování
Modul Partition and Sample lze použít k náhodnému přiřazení skupin k datům. V následující vzorové konfiguraci modulu definujeme pět složek a náhodně přiřadíme číslo složky instancím vzorku.
Definování metriky
Modul Hyperparametry Tune Model poskytuje podporu pro empirické výběr nejlepší sady parametrů pro daný algoritmus a datovou sadu. Kromě dalších informací týkajících se trénování modelu zahrnuje podokno Vlastnosti tohoto modulu metriku pro určení nejlepší sady parametrů. Pro klasifikační a regresní algoritmy má dvě různá rozevírací seznamy. Pokud je algoritmus zvažovaný klasifikačním algoritmem, metrika regrese se ignoruje a naopak. V tomto konkrétním příkladu je metrikou Přesnost.
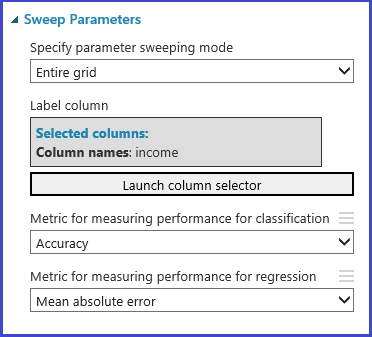
Trénování, vyhodnocení a porovnání
Stejný modul Tune Model Hyperparameters trénuje všechny modely, které odpovídají sadě parametrů, vyhodnocuje různé metriky a pak vytvoří model s nejlepším trénovaným modelem na základě metriky, kterou zvolíte. Tento modul má dva povinné vstupy:
- Nevyučený student
- Datová sada
Modul má také volitelný vstup datové sady. Připojte datovou sadu s informacemi o přeložení k povinnému vstupu datové sady. Ve výchozím nastavení se automaticky spustí 10-násobné křížové ověření, pokud datová sada nemá přiřazené žádné informace o skládání. Pokud přiřazení složení není dokončeno a ověřovací datová sada je dostupná na volitelném portu datové sady, zvolí se režim trénování a testování, přičemž první datová sada se použije k trénování modelu pro každou kombinaci parametrů.
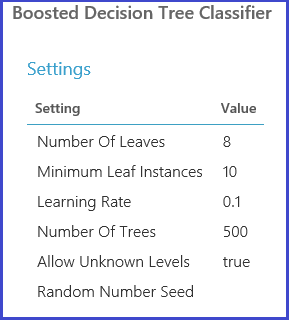
Model se pak vyhodnocuje na validačním datovém souboru. Levý výstupní port modulu zobrazuje různé metriky jako funkce hodnot parametrů. Správný výstupní port poskytuje natrénovaný model, který odpovídá nejvýkonnějšímu modelu podle zvolené metriky (v tomto případě přesnost ).
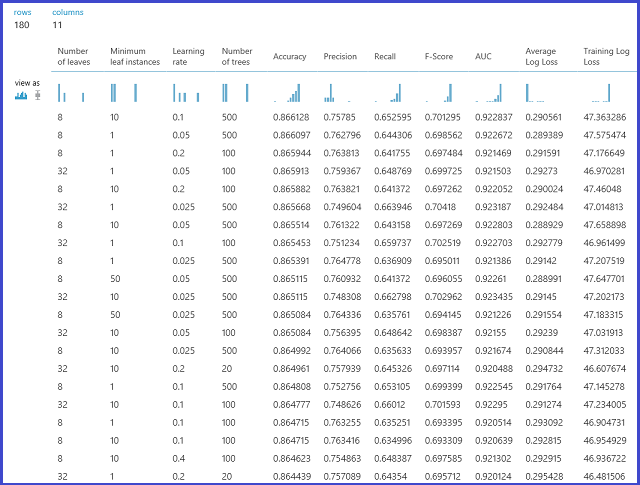
Přesné parametry zvolené vizualizací správného výstupního portu můžete zobrazit. Tento model lze použít pro hodnocení testovací sady nebo ve zprovozněné webové službě po uložení jako vytrénovaného modelu.