Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Důležité
Podpora studia Machine Learning (Classic) skončí 31. srpna 2024. Doporučujeme do tohoto data přejít na službu Azure Machine Learning.
Od 1. prosince 2021 nebude možné vytvářet nové prostředky studia Machine Learning (Classic). Do 31. srpna 2024 můžete pokračovat v používání stávajících prostředků studia Machine Learning (Classic).
- Projděte si informace o přesunu projektů strojového učení z ML Studia (Classic) do Azure Machine Learning.
- Přečtěte si další informace o službě Azure Machine Learning.
Dokumentace ke studiu ML (Classic) se vyřazuje z provozu a v budoucnu se nemusí aktualizovat.
Nakonfiguruje a inicializuje model clusteringu K-means.
Kategorie: Strojové učení / Inicializace modelu / Clustering
Poznámka
Platí pro: Pouze Machine Learning Studio (classic)
Podobné moduly přetahování jsou k dispozici v návrháři služby Azure Machine Learning.
Přehled modulu
Tento článek popisuje, jak pomocí modulu clusteringu K-Means v nástroji Machine Learning Studio (classic) vytvořit netrénovaný model clusteringu K-means.
K-means je jedním z nejjednodušších a nejznámějších algoritmů učení bez dohledu a dá se použít pro různé úlohy strojového učení, jako je zjišťování neobvyklých dat, shlukování textových dokumentů a analýza datové sady před použitím jiných klasifikačních nebo regresních metod. Pokud chcete vytvořit model clusteringu, přidáte tento modul do experimentu, připojíte datovou sadu a nastavíte parametry, jako je očekávaný počet clusterů, metrika vzdálenosti, která se má použít při vytváření clusterů atd.
Po nakonfigurování hyperparametrů modulu připojte netrénovaný model k trénování clusteringového modelu nebo moduly Uklidit clustering a vytrénujte model na vstupních datech, která zadáte. Vzhledem k tomu, že algoritmus K-means je metoda učení bez dohledu, je sloupec popisku volitelný.
- Pokud data obsahují popisek, můžete hodnoty popisků použít k výběru clusterů a optimalizaci modelu.
- Pokud vaše data nemají žádný popisek, algoritmus vytvoří clustery představující možné kategorie, a to výhradně na základě dat.
Tip
Pokud vaše trénovací data mají popisky, zvažte použití některé z metod klasifikace pod dohledem, které poskytuje Machine Learning. Můžete například porovnat výsledky clusteringu s výsledky při použití některého z algoritmů rozhodovacího stromu s více třídami.
Principy clusteringu k-means
Obecně platí, že clustering používá iterativní techniky k seskupení případů v datové sadě do clusterů, které obsahují podobné charakteristiky. Tato seskupení jsou užitečná pro zkoumání dat, identifikaci anomálií v datech a nakonec pro vytváření předpovědí. Modely clusteringu vám také můžou pomoct identifikovat relace v datové sadě, které nemusíte logicky odvodit procházením nebo jednoduchým pozorováním. Z těchto důvodů se clustering často používá v raných fázích úloh strojového učení k prozkoumání dat a zjišťování neočekávaných korelací.
Když konfigurujete model clusteringu pomocí metody k-means, musíte zadat cílové číslo k označující počet centroidů , které chcete v modelu použít. Centroid je bod, který je reprezentativní pro každý shluk. Algoritmus K-means přiřadí každý příchozí datový bod jednomu z clusterů minimalizací součtu čtverců v rámci clusteru.
Při zpracování trénovacích dat začíná algoritmus K-means počáteční sadou náhodně zvolených centroidů, které slouží jako výchozí body pro každý shluk, a používá Lloydův algoritmus k iterativnímu upřesnění umístění centroidů. Algoritmus K-means zastaví vytváření a zpřesňování clusterů, pokud splňuje jednu nebo více z těchto podmínek:
Centroidy se stabilizují, což znamená, že přiřazení shluků pro jednotlivé body se již nemění a algoritmus se sbližoval s řešením.
Algoritmus dokončil spuštění zadaného počtu iterací.
Po dokončení trénovací fáze použijete modul Přiřadit data ke clusterům k přiřazení nových případů k jednomu z clusterů, který byl nalezen algoritmem k-means. Přiřazení clusteru se provádí výpočtem vzdálenosti mezi novým případem a centroidem každého clusteru. Každý nový případ je přiřazen clusteru s nejbližším centroidem.
Konfigurace clusteringu K-Means
Přidejte do experimentu modul clusteringu K-Means .
Nastavením možnosti Vytvořit režim školitele určete, jak má být model vytrénován.
Jeden parametr: Pokud znáte přesné parametry, které chcete použít v modelu clusteringu, můžete jako argumenty zadat konkrétní sadu hodnot.
Rozsah parametrů: Pokud si nejste jisti nejlepšími parametry, můžete najít optimální parametry zadáním více hodnot a pomocí modulu Uklidit clustering najít optimální konfiguraci.
Školitel iteruje více kombinací nastavení, která jste zadali, a určí kombinaci hodnot, která vede k optimálním výsledkům clusteringu.
Do pole Počet centroidů zadejte počet shluků, na které má algoritmus začínat.
Model nezaručuje, že vytvoří přesně tento počet clusterů. Algorithn začíná tímto počtem datových bodů a iteruje k nalezení optimální konfigurace, jak je popsáno v části Technické poznámky .
Pokud provádíte úklid parametrů, název vlastnosti se změní na Rozsah pro počet centroidů. Pomocí Tvůrce rozsahů můžete určit oblast nebo můžete zadat řadu čísel představujících různé počty clusterů, které se mají vytvořit při inicializaci každého modelu.
Vlastnosti Inicializace nebo Inicializace pro úklid se používají k určení algoritmu, který se použije k definování počáteční konfigurace clusteru.
První N: Ze sady dat se vybere určitý počáteční počet datových bodů a použije se jako počáteční prostředek.
Označuje se také jako metoda Forgy.
Náhodný: Algoritmus náhodně umístí datový bod do clusteru a pak vypočítá počáteční střední hodnotu jako centroid náhodně přiřazených bodů clusteru.
Označuje se také jako metoda náhodného oddílu .
K-Means++: Toto je výchozí metoda inicializace clusterů.
Algoritmus K-means ++ byl navržen v roce 2007 Davidem Arthurem a Sergejem Vassilvitskiim, aby se zabránilo špatnému shlukování standardním algoritmem k-means. K-means ++ zlepšuje standardní K-means použitím jiné metody pro výběr počátečních center clusteru.
K-Means++Fast: Varianta algoritmu K-means ++ optimalizovaná pro rychlejší clustering.
Rovnoměrně: Centroidy jsou umístěné v d-dimenzionálním prostoru n datových bodů.
Použít sloupec popisku: Hodnoty ve sloupci popisku slouží k vodítku výběru centroidů.
V části Náhodné počáteční číslo volitelně zadejte hodnotu, která se použije jako počáteční hodnota pro inicializaci clusteru. Tato hodnota může mít významný vliv na výběr clusteru.
Pokud použijete úklid parametrů, můžete určit, aby se vytvořilo více počátečních semen, aby se hledala nejlepší počáteční hodnota. Do pole Počet semen, která se mají zametat, zadejte celkový počet náhodných hodnot semen, které se mají použít jako výchozí body.
V části Metrika zvolte funkci, která se má použít k měření vzdálenosti mezi vektory shluků nebo mezi novými datovými body a náhodně zvoleným centroidem. Machine Learning podporuje následující metriky vzdálenosti clusteru:
Euklidovské: Euklidovské vzdálenosti se běžně používá jako míra shlukového rozptylu pro shlukování K-means. Tato metrika je upřednostňovaná, protože minimalizuje střední vzdálenost mezi body a centroidy.
Kosinus: Funkce kosinus se používá k měření podobnosti shluků. Kosinus podobnost je užitečná v případech, kdy se nezajímáte o délku vektoru, pouze o jeho úhel.
V části Iterace zadejte, kolikrát má algoritmus iterovat trénovací data před dokončením výběru centroidů.
Tento parametr můžete upravit tak, aby vyvažovaly přesnost a dobu trénování.
V části Přiřadit režim popisku zvolte možnost, která určuje způsob zpracování sloupce popisku, pokud je v datové sadě.
Vzhledem k tomu, že clustering K-means je metoda strojového učení bez dohledu, jsou popisky volitelné. Pokud už ale datová sada obsahuje sloupec popisku, můžete tyto hodnoty použít k vodítku výběru clusterů nebo můžete zadat, aby se hodnoty ignorovaly.
Ignorovat sloupec popisku: Hodnoty ve sloupci popisku se ignorují a nepoužívají se při sestavování modelu.
Vyplnění chybějících hodnot: Hodnoty sloupce popisků se používají jako funkce, které pomáhají vytvářet clustery. Pokud některé řádky chybí popisek, hodnota se přičte pomocí jiných funkcí.
Přepsání z nejbližšího na střed: Hodnoty sloupce popisku jsou nahrazeny hodnotami predikovaných popisků pomocí popisku bodu, který je nejblíže k aktuálnímu centroidu.
Trénování modelu
Pokud nastavíte Vytvořit režim školitele na jeden parametr, přidejte označenou datovou sadu a vytrénujte model pomocí modulu Train Clustering Model .
Pokud nastavíte Vytvořit režim školitele na Rozsah parametrů, přidejte označenou datovou sadu a vytrénujte model pomocí funkce Uklidit clustering. Můžete použít model vytrénovaný pomocí těchto parametrů nebo si můžete poznamenat nastavení parametrů, která se mají použít při konfiguraci žáka.
Výsledky
Po dokončení konfigurace a trénování modelu máte model, který můžete použít ke generování skóre. Existuje ale několik způsobů, jak model vytrénovat, a několik způsobů, jak zobrazit a použít výsledky:
Zachycení snímku modelu v pracovním prostoru
Pokud jste použili modul Trénování modelu clusteringu
- Klikněte pravým tlačítkem na modul Trénování modelu clusteringu .
- Vyberte Natrénovaný model a pak klikněte na Uložit jako trénovaný model.
Pokud jste k trénování modelu použili modul Uklidit clustering
- Klikněte pravým tlačítkem na modul Uklidit clustering .
- Vyberte Nejlépe vytrénovaný model a pak klikněte na Uložit jako trénovaný model.
Uložený model bude představovat trénovací data v okamžiku, kdy jste model uložili. Pokud později aktualizujete trénovací data použitá v experimentu, uložený model se neaktualizuje.
Zobrazení vizuální reprezentace clusterů v modelu
Pokud jste použili modul Trénování modelu clusteringu
- Klikněte pravým tlačítkem na modul a vyberte Datová sada výsledků.
- Vyberte Vizualizovat.
Pokud jste použili modul Uklidit clustering
Přidejte instanci modulu Přiřadit data ke clusterům a vygenerujte skóre pomocí nejlépe vytrénovaného modelu.
Klikněte pravým tlačítkem na modul Přiřadit data ke clusterům , vyberte Datová sada výsledků a vyberte Vizualizovat.
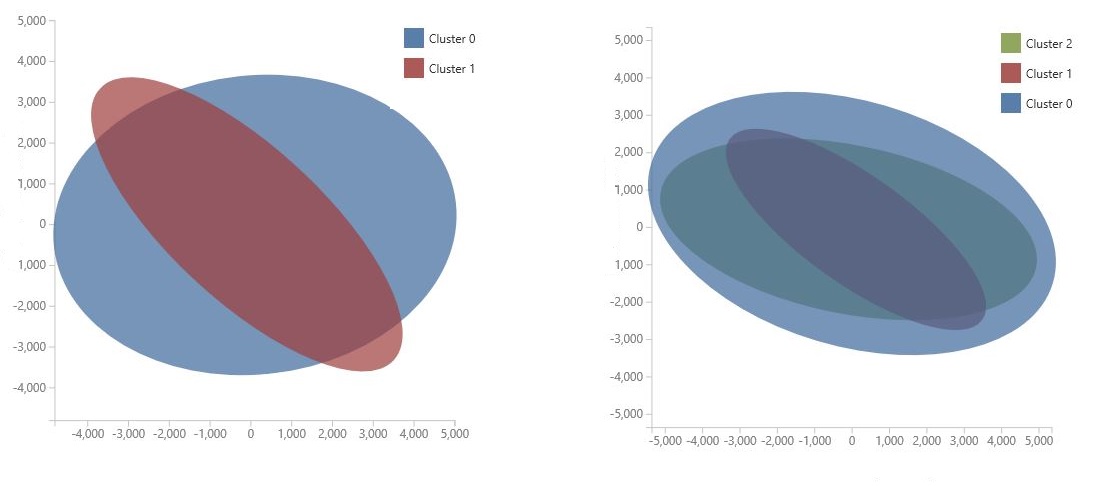
Graf se generuje pomocí analýzy hlavních komponent, což je technika v datových vědách pro kompresi prostoru funkcí modelu. Graf zobrazuje několik funkcí komprimovaných do dvou dimenzí, které nejlépe charakterizují rozdíl mezi shluky. Vizuální kontrolou obecné velikosti prostoru funkcí pro jednotlivé clustery a jejich překrytí získáte představu o tom, jak dobře může model fungovat.
Například následující grafy PCA představují výsledky ze dvou modelů natrénovaných pomocí stejných dat: první byl nakonfigurován tak, aby vystavoval dva clustery, a druhý na výstup tří clusterů. Z těchto grafů vidíte, že zvýšení počtu shluků nemusí nutně zlepšit oddělení tříd.
Tip
Pomocí modulu Uklidit clustering můžete zvolit optimální sadu hyperparametrů, včetně náhodného osiva a počtu počátečních centroidů.
Zobrazení seznamu datových bodů a clusterů, do nichž patří
Existují dvě možnosti zobrazení datové sady s výsledky v závislosti na tom, jak jste model vytrénovali:
Pokud jste k trénování modelu použili modul Uklidit clustering
- Pomocí zaškrtávacího políčka v modulu Uklidit clustering určete, jestli chcete zobrazit vstupní data společně s výsledky, nebo jenom výsledky.
- Po dokončení trénování klikněte pravým tlačítkem na modul a vyberte Datová sada výsledků (výstup číslo 2).
- Klikněte na Vizualizovat.
Pokud jste použili modul Trénování modelu clusteringu
- Přidejte modul Přiřadit data ke clusterům a připojte trénovaný model k levému vstupu. Připojte datovou sadu ke vstupu zprava.
- Přidejte do experimentu modul Convert to Dataset (Převést na datovou sadu ) a připojte ho k výstupu Přiřazení dat ke clusterům.
- Pomocí zaškrtávacího políčka v modulu Přiřadit data ke clusterům určete, jestli chcete zobrazit vstupní data společně s výsledky, nebo jenom výsledky.
- Spusťte experiment nebo spusťte jenom modul Převést na datovou sadu .
- Klikněte pravým tlačítkem na Převést na datovou sadu, vyberte Datová sada výsledků a klikněte na Vizualizovat.
Výstup obsahuje nejprve sloupce vstupních dat, pokud jste je zahrnuli, a následující sloupce pro každý řádek vstupních dat:
Přiřazení: Přiřazení je hodnota mezi 1 a n, kde n je celkový počet clusterů v modelu. Každý řádek dat může být přiřazen pouze k jednomu clusteru.
DistancesToClusterCenter č.n: Tato hodnota měří vzdálenost od aktuálního datového bodu k centroidu clusteru. Samostatný sloupec ve výstupu pro každý cluster v natrénovaného modelu.
Hodnoty vzdálenosti clusteru jsou založené na metrikě vzdálenosti, kterou jste vybrali v možnosti Metrika pro měření výsledku clusteru. I když na modelu clusteringu provedete úklid parametrů, může být během úklidu použita pouze jedna metrika. Pokud metriku změníte, můžete získat jiné hodnoty vzdálenosti.
Vizualizace vzdáleností v rámci clusteru
V datové sadě výsledků z předchozí části klikněte na sloupec vzdáleností pro každý cluster. Studio (classic) zobrazí histogram, který vizualizuje rozdělení vzdáleností pro body v rámci clusteru.
Například následující histogramy ukazují rozdělení vzdáleností clusterů ze stejného experimentu pomocí čtyř různých metrik. Všechna ostatní nastavení pro úklid parametrů byla stejná. Změna metriky měla za následek jiný počet clusterů v jednom modelu.
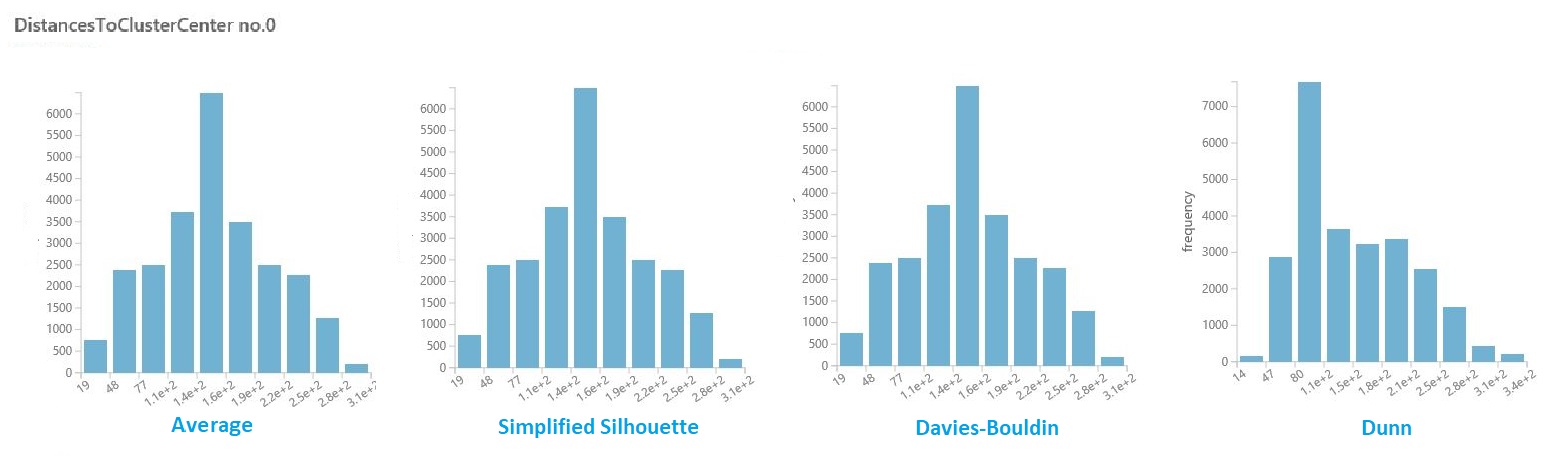
Obecně byste měli zvolit metriku, která maximalizuje vzdálenost mezi datovými body v různých třídách a minimalizuje vzdálenosti v rámci třídy. K tomuto rozhodnutí můžete použít předpočítané prostředky a další hodnoty v podokně Statistiky .
Tip
Prostředky a další hodnoty používané ve vizualizacích můžete extrahovat pomocí modulu PowerShellu pro Machine Learning.
Nebo použijte modul Execute R Script k výpočtu vlastní matice vzdálenosti.
Tipy pro generování nejlepšího modelu clusteringu
Je známo, že proces seedingu použitý během clusteringu může výrazně ovlivnit model. Seeding znamená počáteční umístění bodů do potencálních centroidů.
Pokud například datová sada obsahuje mnoho odlehlých hodnot a vybere se odlehlejší hodnota, která clustery zasadí, nebudou se do tohoto clusteru dobře vejít žádné jiné datové body a cluster by mohl být jediný: cluster s pouze jedním bodem.
Existují různé způsoby, jak se tomuto problému vyhnout:
Pomocí úklidu parametrů můžete změnit počet centroidů a vyzkoušet více počátečních hodnot.
Vytvořte více modelů, které budou měnit metriku nebo iterovat více.
K vyhledání proměnných, které mají nepříznivý vliv na clustering, použijte metodu PCA. Ukázku této techniky najdete v ukázce Najít podobné společnosti .
Obecně platí, že u modelů clusteringu je možné, že jakákoli daná konfigurace bude mít za následek místně optimalizovanou sadu clusterů. Jinými slovy, sada clusterů vrácená modelem vyhovuje pouze aktuálním datovým bodům a není generalizovatelná na jiná data. Pokud jste použili jinou počáteční konfiguraci, metoda K-means může najít jinou, možná lepší konfiguraci.
Důležité
Doporučujeme vždy experimentovat s parametry, vytvářet více modelů a porovnávat výsledné modely.
Příklady
Příklady použití clusteringu K-means ve službě Machine Learning najdete v těchto experimentech v galerii Azure AI:
Data duhovky skupiny: Porovná výsledky clusteringu K-Means a logistické regrese s více třídami pro úlohu klasifikace.
Ukázka kvantování barev: Vytvoří několik modelů K-means s různými parametry, aby se našla optimální komprese obrazu.
Clustering: Podobné společnosti: Mění počet centroidů, aby se našli skupiny podobných společností v S&P500.
Technické poznámky
Vzhledem k určitému počtu shluků (K), které se mají najít pro sadu datových bodů dimenzí D s datovými body N , algoritmus K-means sestaví clustery následujícím způsobem:
Modul inicializuje pole K-by-D s konečnými centroidy, které definují nalezené clustery K.
Ve výchozím nastavení modul přiřadí prvním datovým bodům K clusterům K .
Počínaje počáteční sadou centroidů K metoda používá Lloydův algoritmus k iterativnímu upřesnění umístění centroidů.
Algoritmus se ukončí při stabilizaci centroidů nebo při dokončení zadaného počtu iterací.
Metrika podobnosti (ve výchozím nastavení Euklidova vzdálenost) se používá k přiřazení každého datového bodu ke clusteru, který má nejbližší centroid.
Upozornění
- Pokud do trénování modelu clusteringu předáte rozsah parametrů, použije se pouze první hodnota v seznamu rozsahů parametrů.
- Pokud do modulu Uklidit clustering předáte jednu sadu hodnot parametrů, pokud očekáváte rozsah nastavení pro každý parametr, ignoruje hodnoty a použije výchozí hodnoty pro učícího se.
- Pokud vyberete možnost Rozsah parametrů a zadáte jednu hodnotu pro libovolný parametr, použije se tato jedna hodnota, kterou jste zadali, v průběhu úklidu, a to i v případě, že se jiné parametry v rozsahu hodnot mění.
Parametry modulu
| Name | Rozsah | Typ | Výchozí | Description |
|---|---|---|---|---|
| Počet centroidů | >=2 | Integer | 2 | Počet centroidů |
| Metric | Seznam (podmnožina) | Metric | Euklidovském | Vybraná metrika |
| Inicializace | Seznam | Metoda inicializace centroid | K-Means++ | Algoritmus inicializace |
| Iterace | >=1 | Integer | 100 | Počet iterací |
Výstupy
| Název | Typ | Description |
|---|---|---|
| Netrénovaný model | ICluster – rozhraní | Netrénovaný model clusteringu K-Means |
Výjimky
Seznam všech výjimek najdete v tématu Kódy chyb modulu strojového učení.
| Výjimka | Description |
|---|---|
| Chyba 0003 | K výjimce dochází, pokud je jeden nebo více vstupů null nebo prázdných. |
Viz také
Clustering
Přiřazení dat do clusterů
Trénování modelu clusteringu
Uklidit clustering