Identifikace zpráv o chybách zabezpečení na základě názvů sestav a hlučných dat
| Mayana Pereira | Scott Christiansen |
|---|---|
| Datové vědy CELA | Zabezpečení a důvěra zákazníků |
| Microsoft | Microsoft |
Abstrakt – Identifikace zpráv o chybách zabezpečení je zásadním krokem v rámci životního cyklu vývoje softwaru. V případě přístupů založených na strojovém učení se supervizí se obvykle předpokládá, že jsou pro účely trénování k dispozici celé zprávy o chybách a jejich popisky jsou bez šumu. Pokud víme, toto je první studie, která ukazuje, že je možné přesně předpovídat popisky zpráv o chybách zabezpečení, i když je k dispozici pouze název a v popiscích je šum.
Deskriptory – strojové učení, chybné popisování, šum, zpráva o chybách zabezpečení, úložiště chyb
I. ÚVOD
Identifikace problémů souvisejících se zabezpečením mezi nahlášenými chybami je pro týmy softwarových vývojářů naléhavou potřebou, protože takové problémy volají po rychlejší opravě, aby se zajistilo splnění požadavků na dodržování předpisů a integrita softwarových a zákaznických dat.
Nástroje pro strojové učení a umělou inteligenci slibují zajistit rychlejší, flexibilní a správný vývoj softwaru. Strojové učení na problém identifikace chyb zabezpečení již aplikovalo několik výzkumníků [2], [7], [8], [18]. Dříve publikované studie předpokládaly, že je pro účely trénování a bodování modelu strojového učení k dispozici celá zpráva o chybách. To není nutně tento případ. Existují situace, kdy není možné zpřístupnit celou zprávu o chybách. Zpráva o chybách například může obsahovat hesla, identifikovatelné osobní údaje (PII) nebo jiný druh citlivých dat, což je případ, kterému aktuálně čelíme v Microsoftu. Proto je důležité stanovit, do jaké míry je možné provést identifikaci chyb zabezpečení při použití menšího množství informací, například v případě, že je k dispozici pouze název zprávy o chybách.
Úložiště chyb navíc často obsahují chybně popsané položky [7]: zprávy o chybách nesouvisejících se zabezpečením klasifikovaných jako chyby související se zabezpečením a naopak. K chybnému popisování může docházet z několika důvodů, od nedostatku odborných znalostí týmu v oblasti zabezpečení až po nejasnost určitých problémů (např. chyby nesouvisející se zabezpečením je možné nepřímo zneužít tak, aby to mělo vliv na zabezpečení). Jedná se o vážný problém, protože kvůli chybnému popisování zpráv o chybách zabezpečení musí odborníci na zabezpečení ručně kontrolovat databázi chyb, což je nákladné a časově náročné. Porozumění způsobu, jakým šum ovlivňuje různé klasifikátory, a jak robustní (nebo křehké) jsou různé techniky strojového učení v případě sad dat kontaminovaných různými typy šumu, je problém, který je potřeba vyřešit, aby bylo možné v rámci postupů vytváření softwaru zavést automatickou klasifikaci.
Předběžné práce ukazují, že úložiště chyb ze své podstaty obsahují šum, který může mít nepříznivý vliv na klasifikátory výkonu strojového učení [7]. Neexistuje však žádná systematická kvantitativní studie zabývající se tím, jak různé úrovně a typy šumu ovlivňují výkon různých algoritmů strojového učení se supervizí v případě problému s identifikací zpráv o chybách zabezpečení.
V této studii ukazujeme, že je možné provádět klasifikaci zpráv o chybách i v případě, že je pro účely trénování a bodování k dispozici pouze název. Pokud víme, jedná se o vůbec první práci na toto téma. Kromě toho nabízíme první systematickou studii vlivu šumu na klasifikaci zpráv o chybách. Provádíme srovnávací studii odolnosti tří technik strojového učení (logistická regrese, algoritmus Naive Bayes a AdaBoost) vůči šumu nezávislému na třídě.
Přestože existují některé analytické modely, které zachycují obecný vliv šumu na několik jednoduchých klasifikátorů [5], [6], tyto výsledky neposkytují pevné meze vlivu šumu na přesnost a platí pouze pro konkrétní techniky strojového učení. Přesná analýza vlivu šumu na modely strojového učení se obvykle provádí na základě spouštění výpočetních experimentů. Takové analýzy se provedly pro několik scénářů od dat softwarového měření [4] až po klasifikaci satelitních snímků [13] a zdravotní data [12]. Tyto výsledky však není možné přenést na náš konkrétní problém, a to kvůli vysoké závislosti na povaze sad dat a základním problému s klasifikací. Pokud víme, neexistují žádné publikované výsledky týkající se problému s vlivem sad dat s šumem konkrétně na klasifikaci zpráv o chybách zabezpečení.
PŘÍNOSY NAŠEHO VÝZKUMU:
Trénujeme klasifikátory na identifikaci zpráv o chybách zabezpečení pouze na základě názvu zpráv. Pokud víme, jedná se o první práci na toto téma. Předchozí práce využívaly kompletní zprávy o chybách nebo vylepšovaly zprávy o chybách o další doplňující funkce. Klasifikace chyb pouze na základě názvu je důležitá zejména v případě, že kvůli ochraně osobních údajů není možné zpřístupnit kompletní zprávy o chybách. Notoricky známým příkladem jsou případy zpráv o chybách, které obsahují hesla a další citlivá data.
Poskytujeme také první systematickou studii tolerance různých modelů strojového učení a technik využívaných k automatické klasifikaci zpráv o chybách zabezpečení vůči šumu v popiscích. Provádíme srovnávací studii odolnosti tří různých technik strojového učení (logistická regrese, algoritmus Naive Bayes a AdaBoost) vůči šumu závislému i nezávislému na třídě.
Zbývající část dokumentu je prezentována takto: V části II prezentujeme některé z předchozích děl v literaturě. V části III popisujeme sadu dat a způsob předběžného zpracování dat. V části IV popisujeme metodologie a v části V analyzujeme výsledky našich experimentů. A konečně, v části VI představujeme závěry, ke kterým jsme došli, a budoucí práce.
II. PŘEDCHOZÍ PRÁCE
VYUŽITÍ STROJOVÉHO UČENÍ PRO ÚLOŽIŠTĚ KÓDU
Existuje rozsáhlá odborná literatura zabývající se využitím dolování z textu, zpracování přirozeného jazyka a strojového učení pro úložiště kódu s cílem automatizovat pracné úlohy, jako jsou mimo jiné detekce chyb zabezpečení [2], [7], [8], [18], identifikace duplicitních chyb [3] nebo posuzování chyb [1], [11]. V ideálním případě může spojení strojového učení a zpracování přirozeného jazyka snížit množství ruční práce, která se vyžaduje ke kurátorování databází chyb, zkrátit dobu požadovanou k dokončení těchto úloh a zvýšit spolehlivost výsledků.
Ve studii [7] autoři navrhují model zpracování přirozeného jazyka, který automatizuje klasifikaci zpráv o chybách zabezpečení na základě popisu chyby. Autoři ze všech popisů chyb v trénovací sadě dat extrahují slovník a ručně ho rozdělují do tří seznamů slov: relevantní slova, nevýznamová slova (běžná slova, která se pro klasifikaci zdají být irelevantní) a synonyma. Porovnávají výkon klasifikátoru chyb zabezpečení natrénovaného na datech vyhodnocených techniky zabezpečení a klasifikátoru natrénovaného na datech obecně popsaných oznamovateli chyb. Přestože je jejich model jednoznačně efektivnější, když je natrénovaný na datech zkontrolovaných techniky zabezpečení, navrhovaný model je založený na ručně odvozeném slovníku a proto je závislý na lidském kurátorování. Kromě toho neexistuje žádná analýza toho, jaký vliv na jejich model mají různé úrovně šumu, jak na šum reagují různé klasifikátory a jestli má šum v jednotlivých třídách jiný vliv na výkon.
Zou et. Al [18] využívá více typů informací obsažených ve zprávě o chybě, které zahrnují netextová pole zprávy o chybě (meta funkce, např. čas, závažnost a priorita) a textový obsah zprávy o chybě (textové funkce, tj. textová pole souhrnu). Na základě těchto vlastností vytvářejí model, který automaticky identifikuje zprávy o chybách zabezpečení prostřednictvím technik strojového učení a zpracování přirozeného jazyka. Ve studii [8] autoři provádějí podobnou analýzu, ale navíc porovnávají výkon technik strojového učení se supervizí a bez supervize a zkoumají, kolik dat je potřeba k natrénování jejich modelů.
Ve studii [2] autoři také zkoumají různé techniky strojového učení sloužící ke klasifikaci chyb v závislosti na jejich popisu do zpráv o chybách zabezpečení nebo zpráv o chybách nesouvisejících se zabezpečením. Navrhují kanál zpracování dat a trénování modelů založený na metodice TFIDF. Navrhovaný kanál porovnávají s modelem založeným na množině slov a algoritmu Naive Bayes. Wijayasekara a kol. [16] také s využitím technik dolování z dat vygenerovali vektory vlastností jednotlivých zpráv o chybách na základě častých slov, které umožňují identifikovat chyby se skrytým dopadem. Yang a kol. [17] tvrdí, že identifikovali zprávy o chybách s vysokým dopadem (např. zprávy o chybách zabezpečení) s využitím četnosti termínů (TF) a algoritmu Naive Bayes. Ve studii [9] autoři navrhují model, který předpovídá závažnost chyb.
ŠUM V POPISCÍCH
Problém práce se sadami dat s šumem v popiscích je předmětem rozsáhlého studia. Frenay a Verleysen ve studii [6] navrhují taxonomii šumu v popiscích, aby bylo možné rozlišovat mezi různými typy popisků s šumem. Autoři navrhují tři různé typy šumu: šum v popiscích, ke kterému dochází nezávisle na skutečné třídě a hodnotách vlastností instance, šum v popiscích, který závisí pouze na skutečném popisku, a šum v popiscích, kde pravděpodobnost chybného popisku také závisí na hodnotách vlastností. V naší práci zkoumáme první dva typy šumu. Z teoretického hlediska šum v popiscích obvykle snižuje výkon modelu [10] s výjimkou některých konkrétních případů [14]. Obecně platí, že spolehlivé metody při zpracování šumu v popiscích spoléhají na vyhýbání se přeučování [15]. Již dříve proběhly studie vlivu šumu na klasifikaci v řadě oblastí, jako jsou klasifikace satelitních snímků [13], klasifikace kvality softwaru [4] nebo klasifikace v oblasti zdravotnictví [12]. Pokud víme, neexistují žádné publikované práce zkoumající přesnou kvantifikaci vlivu popisků s šumem na problém s klasifikací zpráv o chybách zabezpečení. V tomto scénáři se neprokázala přesná souvislost mezi úrovněmi šumu, typy šumu a snížením výkonu. Kromě toho je užitečné pochopit, jak se různé klasifikátory chovají v případě šumu. Obecněji řečeno nevíme o žádné práci, která by systematicky zkoumala vliv sad dat s šumem na výkon různých algoritmů strojového učení v kontextu zpráv o softwarových chybách.
III. POPIS SADY DAT
Naše sada dat se skládá z 1 073 149 názvů chyb, z nichž 552 073 odpovídá zprávám o chybách zabezpečení a 521 076 odpovídá zprávám o chybách nesouvisejících se zabezpečením. Tato data se shromáždila od různých týmů napříč Microsoftem v letech 2015, 2016, 2017 a 2018. Všechny popisky pocházejí ze systémů pro ověřování chyb na základě podpisu nebo jsou vytvořené člověkem. Názvy chyb v naší sadě dat jsou velmi krátké texty, obsahující přibližně 10 slov, s přehledem konkrétního problému.
A. Předběžné zpracování dat: Jednotlivé názvy chyb parsujeme podle mezer a tím získáme seznam tokenů. Jednotlivé seznamy tokenů zpracováváme následujícím způsobem:
Odebereme všechny tokeny, které představují cesty k souborům.
Rozdělíme tokeny, které obsahují následující symboly: { , (, ), -, }, {, [, ], }.
Odebereme nevýznamová slova, tokeny skládající se pouze z číselných znaků a tokeny, které se v celém korpusu vyskytují méně než 5krát.
IV. METODOLOGIE
Proces trénování našich modelů strojového učení se skládá ze dvou hlavních kroků: kódování dat do vektorů vlastností a trénování klasifikátorů strojového učení se supervizí.
A. Vektory vlastností a techniky strojového učení
První část zahrnuje kódování dat do vektorů vlastností pomocí algoritmu TF-IDF (Term Frequency – Inverse Document Frequency), který se použil i ve studii [2]. TF-IDF je technika získávání informací, při které se zvažuje četnost termínů (TF) a převrácená četnost termínů v dokumentech (IDF). Každé slovo nebo termín má odpovídající skóre TF a IDF. Algoritmus TF-IDF přiřazuje ke slovům důležitost na základě toho, kolikrát se v dokumentu vyskytují, a co je důležitější, kontroluje, jak relevantní jsou klíčová slova v celé kolekci dokumentů v sadě dat. Natrénovali a porovnali jsme tři techniky klasifikace: Naive Bayes (NB), posílené rozhodovací stromy (AdaBoost) a logistickou regresi (LR). Tyto techniky jsme zvolili proto, že se podle všech zpráv v odborné literatuře ukázalo, že dobře fungují v případě související úlohy identifikace zpráv o chybách zabezpečení. Tyto výsledky potvrdila i předběžná analýza, kdy tyto tři klasifikátory vykázaly vyšší výkon než metoda podpůrných vektorů a náhodné rozhodovací lesy. Při našich experimentech ke kódování a trénování modelů využíváme knihovnu scikit-learn.
B. Typy šumu
Šum, kterým se zabývá tato práce, označuje šum v popisku třídy v trénovacích datech. Důsledkem takového šumu je oslabení procesu učení a výsledného modelu kvůli chybně popsaným příkladům. Analyzujeme vliv různých úrovní šumu v informacích o třídách. Typy šumu v popiscích se již dříve probíraly v odborné literatuře s využitím různých terminologií. V naší práci analyzujeme vliv dvou různých šumů v popiscích na naše klasifikátory: šum v popiscích nezávislý na třídě, ke kterému dochází při náhodném vybírání instancí a obracení jejich popisků, a šum závislý na třídě, kdy třídy mají různou pravděpodobnost, že obsahují šum.
a) Šum nezávislý na třídě: Šum nezávislý na třídě odkazuje na šum, který se vyskytuje nezávisle na skutečné třídě instancí. V případě tohoto typu šumu je pravděpodobnost chybného popisku pbr stejná pro všechny instance v sadě dat. Do našich sad dat zavádíme šum nezávislý na třídě tím, že náhodně obracíme jednotlivé popisky v sadě dat s pravděpodobností pbr.
b) Šum závislý na třídě: Šum závislý na třídě odkazuje na šum, který závisí na skutečné třídě instancí. V případě tohoto typu šumu je pravděpodobnost chybného popisku ve třídě zpráv o chybách zabezpečení psbr a pravděpodobnost chybného popisku ve třídě zpráv o chybách zabezpečení nesouvisejících se zabezpečením pnsbr. Do našich sad dat zavádíme šum závislý na třídě tím, že obracíme jednotlivé položky v sadě dat, pro které je skutečný popisek Zpráva o chybě zabezpečení, s pravděpodobností psbr. Obdobně obracíme popisky tříd u instancí zpráv o chybách nesouvisejících se zabezpečením s pravděpodobností pnsbr.
c) Šum v jedné třídě: Šum v jedné třídě je zvláštní případ šumu závislého na třídě, kde pnsbr = 0 a psbr> 0. Všimněte si, že pro šum nezávislý na třídě platí psbr = pnsbr = pbr.
C. Generování šumu
Naše experimenty zkoumají vliv různých typů a úrovní šumu na trénování klasifikátorů zpráv o chybách zabezpečení. Pro naše experimenty jsme nastavili 25 % sady dat jako testovací data, 10 % jako ověřovací data a 65 % jako trénovací data.
Do trénovací a ověřovací sady dat přidáváme šum pro různé úrovně pbr, psbr a pnsbr . Testovací sadu dat nijak neupravujeme. Použité různé úrovně šumu jsou P = {0,05 × i|0 < i < 10}.
V případě experimentů se šumem nezávislým na třídě pro pbr ∈ P postupujeme následovně:
Vygenerujeme šum pro trénovací a ověřovací sadu dat.
S využitím trénovací sady dat (s šumem) natrénujeme modely logistické regrese, Naive Bayes a AdaBoost a s využitím ověřovací sady dat (s šumem) modely vyladíme.
S využitím testovací sady dat (bez šumu) modely otestujeme.
V případě experimentů se šumem závislým na třídě pro psbr ∈ P a pnsbr ∈ P postupujeme u všech kombinací psbr a pnsbr následovně:
Vygenerujeme šum pro trénovací a ověřovací sadu dat.
S využitím trénovací sady dat (s šumem) natrénujeme modely logistické regrese, Naive Bayes a AdaBoost.
S využitím ověřovací sady dat (s šumem) modely vyladíme.
S využitím testovací sady dat (bez šumu) modely otestujeme.
V. VÝSLEDKY EXPERIMENTŮ
V této části analyzujeme výsledky experimentů provedených podle metodologie popsané v části IV.
a) Výkon modelu bez šumu v trénovací sadě dat: Jedním z příspěvků tohoto dokumentu je návrh modelu strojového učení k identifikaci chyb zabezpečení pomocí pouze názvu chyby jako dat pro rozhodování. Díky tomu je možné trénovat modely strojového učení i v případě, že vývojové týmy nechtějí sdílet kompletní zprávy o chybách kvůli tomu, že obsahují citlivá data. Porovnáváme výkon tří modelů strojového učení natrénovaných pouze na základě názvů chyb.
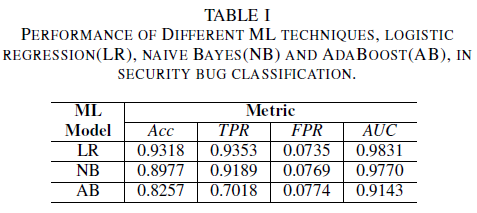
Nejvýkonnějším klasifikátorem je model logistické regrese. Jedná se o klasifikátor s nejvyšší hodnotou AUC 0,9826, úplností 0,9353 a hodnotou FPR 0,0735. Klasifikátor Naive Bayes vykazuje mírně nižší výkon než klasifikátor logistické regrese s hodnotou AUC 0,9779, úplností 0,9189 a hodnotou FPR 0,0769. Klasifikátor AdaBoost má oproti dvěma výše uvedeným klasifikátorům nižší výkon. Dosahuje hodnoty AUC 0,9143, úplnosti 0,7018 a hodnoty FPR 0,0774. Oblast pod křivkou ROC (AUC) je dobrou metrikou pro porovnání výkonu několika modelů, protože shrnuje jednu hodnotu TPR vs. vztah FPR. V další analýze omezíme naši srovnávací analýzu pouze na hodnoty AUC.
A. Šum ve třídě: jedna třída
Můžete si představit scénář, ve kterém se všechny chyby ve výchozím nastavení přiřadí ke třídě zpráv o chybách nesouvisejících se zabezpečením a k přiřazení chyby ke třídě zpráv o chybách zabezpečení dojde pouze v případě, že úložiště chyb kontroluje odborník na zabezpečení. Tento scénář je reprezentován v experimentálním nastavení jedné třídy, kde předpokládáme, že pnsbr = 0 a 0 < psbr< 0,5.
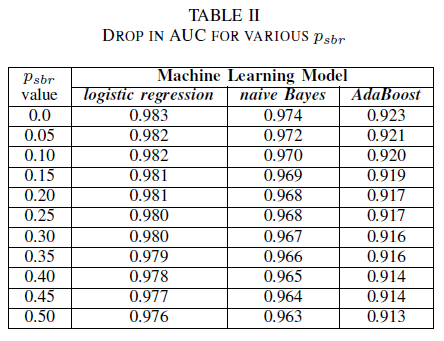
V tabulce II vidíme, že u všech tří klasifikátorů došlo k velmi malému dopadu na AUC. Hodnota AUC-ROC modelu natrénovaného s psbr = 0 se oproti hodnotě AUC-ROC modelu s psbr = 0,25 liší pouze o 0,003 v případě logistické regrese, o 0,006 v případě Naive Bayes a o 0,006 v případě AdaBoost. V případě psbr = 0,50 se naměřená hodnota AUC u jednotlivých modelů oproti modelům natrénovaným s psbr = 0 liší o 0,007 v případě logistické regrese, o 0,011 v případě Naive Bayes a o 0,010 v případě AdaBoost. Klasifikátor logistické regrese natrénovaný s šumem v jedné třídě vykazuje v porovnání s klasifikátory Naive Bayes a AdaBoost nejnižší odchylku v metrice AUC, tj. spolehlivější chování.
B. Šum ve třídě: šum nezávislý na třídě
Porovnáváme výkon našich tří klasifikátorů v případě, že je trénovací sada poškozená šumem nezávislým na třídě. Měříme hodnotu AUC jednotlivých modelů natrénovaných s různými úrovněmi pbr v trénovacích datech.
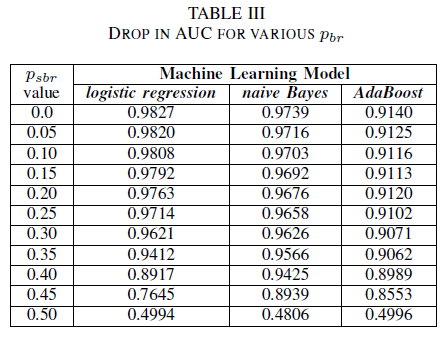
V tabulce III vidíme snížení hodnoty AUC-ROC při každém zvýšení úrovně šumu v experimentu. Naměřená hodnota AUC-ROC modelu natrénovaného na datech bez šumu se oproti hodnotě AUC-ROC modelu natrénovaného s šumem nezávislým na třídě s pbr = 0,25 liší o 0,011 v případě logistické regrese, o 0,008 v případě Naive Bayes a o 0,0038 v případě AdaBoost. Vidíme, že šum v popiscích nemá výrazný vliv na hodnotu AUC klasifikátorů Naive Bayes a AdaBoost, když jsou úrovně šumu nižší než 40 %. Na druhé straně u klasifikátoru logistické regrese mají na naměřenou hodnotu AUC vliv úrovně šumu v popiscích nad 30 %.
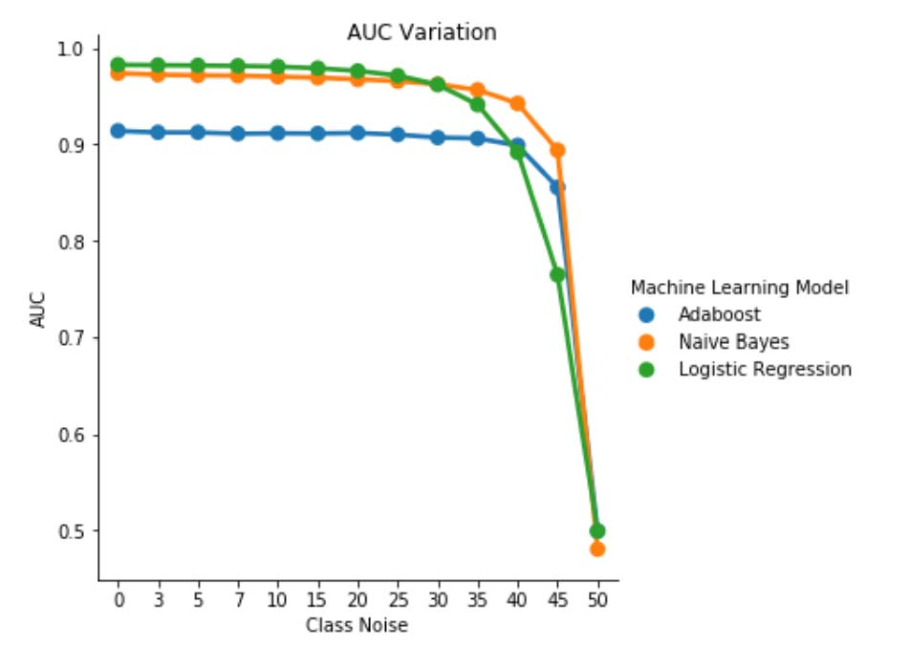
Obrázek 1. Odchylka hodnoty AUC-ROC v případě šumu nezávislého na třídě. V případě úrovně šumu pbr = 0,5 se klasifikátor chová jako náhodný klasifikátor, tj. AUC ≈ 0,5. Vidíme však, že v případě nižších úrovní šumu (pbr ≤ 0,30) klasifikátor logistické regrese vykazuje oproti zbývajícím dvěma modelům vyšší výkon. Pokud je však 0,35 ≤ pbr ≤ 0,45, klasifikátor Naive Bayes vykazuje lepší metriky AUC-ROC.
C. Šum ve třídě: šum závislý na třídě
V závěrečné sadě experimentů se podíváme na scénář, kdy různé třídy obsahují různé úrovně šumu, tj. psbr ≠ pnsbr. V trénovacích datech budeme systematicky a nezávisle na sobě zvyšovat hodnoty psbr a pnsbr o 0,05 a sledovat změnu chování tří klasifikátorů.
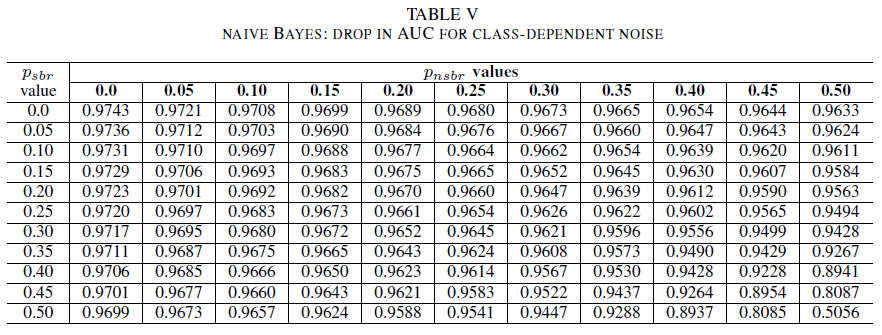
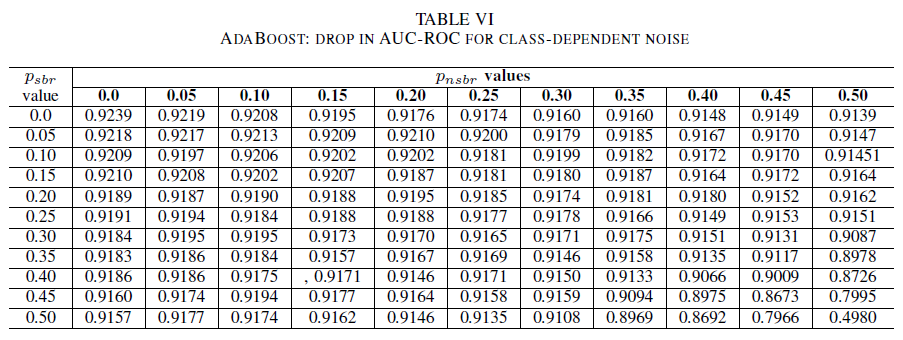
Tabulky IV (logistická regrese), V (Naive Bayes) a VI (AdaBoost) znázorňují odchylku hodnoty AUC při zvyšující se úrovni šumu na různých úrovních v jednotlivých třídách. U všech klasifikátorů si všimněme dopadu na metriku AUC, když obě třídy obsahují úroveň šumu nad 30 %. Klasifikátor Naive Bayes se chová nejspolehlivěji. Dopad na hodnotu AUC je při obrácení 50 % popisků v pozitivní třídě velmi malý za předpokladu, že negativní třída obsahuje maximálně 30 % popisků s šumem. V takovém případě hodnota AUC klesne o 0,03. Ze všech tří klasifikátorů vykázal nejspolehlivější chování klasifikátor AdaBoost. K výraznější změně hodnoty AUC dojde pouze v případě, že je úroveň šumu v obou třídách vyšší než 45 %. V takovém případě začínáme pozorovat pokles hodnoty AUC o více než 0,02.
D. Přítomnost zbytkového šumu v původní sadě dat
Popisky pro naši sadu dat vytvořily automatizované systémy založené na podpisech a lidští odborníci. Kromě toho všechny zprávy o chybách podrobněji zkontrolovali a uzavřeli lidští odborníci. Přestože předpokládáme, že je úroveň šumu v naší sadě dat minimální a nikterak statisticky významná, případný zbytkový šum naše závěry nezpochybňuje. Za účelem ilustrace předpokládejme, že původní datová sada je poškozena šumem nezávislým na třídě, který se rovná 0 < p < 1/2 nezávisle a identicky distribuovaný (i.i.d) pro každou položku.
Pokud k původnímu šumu přidáme šum nezávislý na třídě s pravděpodobností pbr IID, výsledný šum pro každou položku bude p∗ = p(1 − pbr)+(1 − p)pbr. Pro 0 < p,pbr< 1/2 máme, že skutečný šum na popisek p∗ je přísně větší než šum, který uměle přidáváme do sady dat pbr . Proto by výkon našich klasifikátorů byl ještě lepší, kdyby v první řadě byly natrénované na sadě dat zcela bez šumu (p= 0). V souhrnu přítomnost zbytkového šumu ve skutečné sadě dat znamená, že odolnost našich klasifikátorů vůči šumu je lepší než zde prezentované výsledky. Kromě toho, kdyby zbytkový šum v naší sadě dat byl statisticky významný, hodnota AUC našich klasifikátorů by pro úroveň šumu nižší než 0,5 byla 0,5 (náhodný odhad). V našich výsledcích takové chování nepozorujeme.
VI. ZÁVĚRY A BUDOUCÍ PRÁCE
Přínos tohoto dokumentu je dvojí.
Zaprvé jsme prokázali proveditelnost klasifikace zpráv o chybách zabezpečení pouze na základě názvu zpráv o chybách. To je důležité zejména ve scénářích, ve kterých kvůli omezením vyplývajícím z ochrany osobních údajů nejsou k dispozici celé zprávy o chybách. Například v našem případě zprávy o chybách obsahovaly soukromé informace, jako jsou hesla nebo kryptografické klíče, a nebyly k dispozici pro trénování klasifikátorů. Naše výsledky ukazují, že je možné provádět identifikaci zpráv o chybách zabezpečení s vysokou přesností i v případě, že jsou k dispozici pouze názvy zpráv. Náš model klasifikace, který využívá kombinaci algoritmu TF-IDF a logistické regrese, vykazuje hodnotu AUC 0,9831.
Zadruhé jsme analyzovali vliv trénovacích a ověřovacích dat s chybnými popisky. Porovnali jsme tři dobře známé techniky klasifikace strojového učení (Naive Bayes, logistickou regresi a AdaBoost) z hlediska jejich odolnosti vůči různým typům a úrovním šumu. Všechny tři klasifikátory jsou odolné vůči šumu v jedné třídě. Šum v trénovacích datech nemá na výsledný klasifikátor významný vliv. V případě 50% úrovně šumu je snížení hodnoty AUC je velmi malé (0,01). V případě šumu nezávislého na třídě v obou třídách vykazují modely Naive Bayes a AdaBoost výrazné odchylky hodnoty AUC pouze tehdy, když jsou natrénované na sadě dat s úrovní šumu vyšší než 40 %.
A konečně, šum závislý na třídě výrazně ovlivňuje hodnotu AUC pouze tehdy, když je v obou třídách více než 35% úroveň šumu. Klasifikátor AdaBoost vykázal nejvyšší spolehlivost. Dopad na hodnotu AUC je velmi malý i v případě šumu u 50 % popisků v pozitivní třídě za předpokladu, že negativní třída obsahuje maximálně 45 % popisků s šumem. V takovém případě hodnota AUC klesne o méně než 0,03. Pokud víme, toto je první systematická studie vlivu sad dat s šumem na identifikaci zpráv o chybách zabezpečení.
BUDOUCÍ PRÁCE
V tomto dokumentu jsme zahájili systematickou studii vlivu šumu na výkon klasifikátorů strojového učení v případě identifikace chyb zabezpečení. Tato práce může mít několik zajímavých pokračování, mezi která patří: zkoumání vlivu sad dat s šumem na určování úrovně závažnosti chyb zabezpečení, zkoumání vlivu nevyváženosti tříd na odolnost natrénovaných modelů vůči šumu nebo zkoumání vlivu šumu, který je do sady dat zavedený nežádoucím způsobem.
ODKAZY
[1] John Anvik, Lyndon Hiew a Gail C. Murphy. Who should fix this bug? In: Proceedings of the 28th International Conference on Software Engineering, s 361–370. ACM, 2006.
[2] Diksha Behl, Sahil Handa a Anuja Arora. A bug mining tool to identify and analyze security bugs using naive bayes and tf-idf. In: 2014 International Conference on Reliability, Optimization and Information Technology (ICROIT), s. 294–299. IEEE, 2014.
[3] Nicolas Bettenburg, Rahul Premraj, Thomas Zimmermann a Sunghun Kim. Duplicate bug reports considered harmful really? V údržbě softwaru 2008. ICSM 2008. Mezinárodní konference IEEE, strana 337–345. IEEE, 2008.
[4] Andres Folleco, Taghi M Khoshgoftaar, Jason Van Hulse a Lofton Bullard. Identifying learners robust to low quality data. V tématu Opětovné použití a integrace informací, 2008. IRI 2008. Mezinárodní konference IEEE, strana 190–195. IEEE, 2008.
[5] Benoît Frénay. Uncertainty and label noise in machine learning. Diplomová práce. Catholic University of Louvain, Louvain-la-Neuve. Belgie, 2013.
[6] Benoît Frénay a Michel Verleysen. Classification in the presence of label noise: a survey. In: IEEE Transactions on Neural Networks and Learning Systems, 2014, 25(5), s. 845–869.
[7] Michael Gegick, Pete Rotella a Tao Xie. Identifikace zpráv o chybách zabezpečení prostřednictvím dolování textu: Průmyslová případová studie. In: 2010 7th IEEE Working Conference on Mining Software Repositories (MSR), s. 11–20. IEEE, 2010.
[8] Katerina Goseva-Popstojanova a Jacob Tyo. Identification of security related bug reports via text mining using supervised and unsupervised classification. In: 2018 IEEE International Conference on Software Quality, Reliability and Security (QRS), 2018, s. 344–355.
[9] Ahmed Lamkanfi, Serge Demeyer, Emanuel Giger a Bart Goethals. Predicting the severity of a reported bug. In: 2010 7th IEEE Working Conference on Mining Software Repositories (MSR), s. 1–10. IEEE, 2010.
[10] Naresh Manwani a P. S. Sastry. Noise tolerance under risk minimization. In: IEEE Transactions on Cybernetics, 2013, 43(3), s. 1146–1151.
[11] G. Murphy a D. Cubranic. Automatic bug triage using text categorization. In: Proceedings of the Sixteenth International Conference on Software Engineering & Knowledge Engineering. Citeseer, 2004.
[12] Mykola Pechenizkiy, Alexey Tsymbal, Seppo Puuronen a Oleksandr Pechenizkiy. Šum třídy a učení pod dohledem v lékařských oblastech: Účinek extrakce funkcí. In: Proceedings of the IEEE Symposium on Computer-Based Medical Systems, s. 708–713. IEEE, 2006.
[13] Charlotte Pelletier, Silvia Valero, Jordi Inglada, Nicolas Champion, Claire Marais Sicre a Gerard Dedieu. Effect of training class label noise on classification performances for land cover mapping with satellite image time series. In: Remote Sensing, 2017, 9(2), s. 173.
[14] P. S. Sastry, G. D. Nagendra a Naresh Manwani. A team of continuousaction learning automata for noise-tolerant learning of half-spaces. In: IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2010, 40(1), s. 19–28.
[15] Choh-Man Teng. A comparison of noise handling techniques. In: FLAIRS Conference, s. 269–273, 2001.
[16] Dumidu Wijayasekara, Milos Manic a Miles McQueen. Vulnerability identification and classification via text mining bug databases. In Industrial Electronics Society, IECON 2014-40th Annual Conference of the IEEE, pages 3612–3618. IEEE, 2014.
[17] Xinli Yang, David Lo, Qiao Huang, Xin Xia a Jianling Sun. Automated identification of high impact bug reports leveraging imbalanced learning strategies. In: 2016 IEEE 40th Annual Computer Software and Applications Conference (COMPSAC), 1. svazek, s. 227–232. IEEE, 2016.
[18] Deqing Zou, Zhijun Deng, Zhen Li a Hai Jin. Automatically identifying security bug reports via multitype features analysis. In: Australasian Conference on Information Security and Privacy, s. 619–633. Springer, 2018.