Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Andrew Marshall, Jugal Parikh, Emre Kiciman a Ram Shankar Siva Kumar
Zvláštní díky Raulu Rojasovi a pracovní skupině AETHER Security Engineering
Listopad 2019
Tento dokument představuje dodávku technických postupů AETHER pro pracovní skupinu AI a doplňuje stávající postupy modelování hrozeb SDL tím, že poskytuje nové pokyny k výčtu hrozeb a zmírnění rizik specifické pro prostor AI a Machine Learning. Je určen k použití jako referenční materiál při kontrolních přezkumech návrhu zabezpečení následujícího:
Produkty/služby interagující se službami založenými na umělé inteligenci nebo strojovém učení a závislé na nich
Produkty/služby mající AI/ML jako svůj základ
Tradiční zmírnění bezpečnostních hrozeb je důležitější než kdy jindy. Požadavky stanovené životním cyklem vývoje zabezpečení jsou nezbytné k vytvoření základu zabezpečení produktu, na základě kterého tyto pokyny vycházejí. Selhání řešení tradičních bezpečnostních hrozeb pomáhá umožnit útoky specifické pro AI/ML popsané v tomto dokumentu v softwarových i fyzických doménách a zároveň zjednodušení kompromisů ve spodní části softwarového stacku. Pro úvod do zcela nových bezpečnostních hrozeb v této oblasti viz Zabezpečení budoucnosti AI a ML ve společnosti Microsoft.
Dovednosti techniků zabezpečení a datových vědců se obvykle nepřekrývají. Tyto pokyny poskytují způsob, jak pro obě disciplíny strukturovat konverzace o těchto net-new hrozbách a zmírněních rizik, aniž by se technici zabezpečení museli stát datovými vědci nebo naopak.
Tento dokument je rozdělený do dvou částí:
- Klíčové nové aspekty modelování hrozeb se zaměřují na nové způsoby myšlení a nových otázek, které se mají klást při modelování hrozeb v systémech AI/ML. Odborníci na data i technici zabezpečení by si to měli projít, protože to bude jejich playbook pro diskuze o modelování hrozeb a stanovení priorit zmírnění rizik.
- "Hrozby specifické pro AI/ML a jejich zmírnění" poskytují podrobnosti o konkrétních útocích a také konkrétní kroky pro zmírnění rizik, které se dnes používají k ochraně produktů a služeb Microsoftu před těmito hrozbami. Tato část je primárně zaměřená na datové vědce, kteří můžou potřebovat implementovat konkrétní zmírnění hrozeb jako výstup procesu modelování hrozeb nebo kontroly zabezpečení.
Tyto pokyny jsou uspořádané kolem taxonomie nežádoucích hrozeb strojového učení, kterou vytvořil Ram Shankar Siva Kumar, David O'Brien, Kendra Albert, Salome Viljoen a Jeffrey Snover s názvem "Režimy selhání ve strojovém učení". Pokyny ke správě incidentů týkající se třídění bezpečnostních hrozeb podrobně popsaných v tomto dokumentu najdete v panelu chyb SDL pro hrozby AI/ML. Všechny tyto živé dokumenty se v průběhu času budou vyvíjet s prostředím hrozeb.
Klíčové nové aspekty modelování hrozeb: Změna způsobu zobrazení hranic důvěryhodnosti
Předpokládejme ohrožení nebo otravu dat, která používáte, stejně jako poskytovatele těchto dat. Naučte se detekovat neobvyklé a škodlivé položky dat a také schopnost rozlišovat mezi nimi a zotavit se z nich.
Shrnutí
Trénovací úložiště dat a systémy, které je hostují, jsou součástí vašeho oboru modelování hrozeb. Největší bezpečnostní hrozbou v dnešním strojovém učení je otrava daty kvůli nedostatku standardních detekcí a zmírnění rizik v tomto prostoru v kombinaci se závislostí na nedůvěryhodných/nehodnocených veřejných datových sadách jako zdroji trénovacích dat. Sledování provenience a původu vašich dat je nezbytné pro zajištění jejich důvěryhodnosti a pro zabránění cyklu trénování "co se dá dovnitř, to se dostane ven".
Otázky týkající se kontroly zabezpečení
Pokud jsou vaše data otrávená nebo manipulována, jak byste věděli?
- Jakou telemetrii potřebujete ke zjištění nerovnoměrné distribuce kvality trénovacích dat?
Trénujete z uživatelských vstupů?
-Jaký typ ověřování nebo sanitizace vstupu provádíte s tímto obsahem?
-Je struktura těchto dat zdokumentovaná podobně jako Datové listy pro datové sady?
Pokud trénujete proti online úložištím dat, jaké kroky podniknete k zajištění zabezpečení připojení mezi vaším modelem a daty?
-Mají způsob, jak nahlásit kompromisy spotřebitelům jejich informačních kanálů?
- Jsou to dokonce schopní?
Jak citlivá jsou data, ze kterých trénujete?
- Katalogujete ho nebo řídíte přidání, aktualizaci nebo odstranění položek dat?
Může váš model generovat citlivá data?
-Byla tato data získána s oprávněním ze zdroje?
Je výstupem modelu pouze výstup, který je nezbytný k dosažení cíle?
Vrací váš model nezpracované skóre spolehlivosti nebo jakýkoli jiný přímý výstup, který by se dal zaznamenat a duplikovat?
Jaký je dopad obnovení trénovacích dat útokem nebo invertováním modelu?
Pokud úrovně spolehlivosti výstupu modelu náhle poklesnou, můžete zjistit, jak/proč, a také data, která to způsobila?
Definovali jste pro svůj model dobře vytvořený vstup? Co děláte, abyste zajistili, že vstupy splňují tento formát a co dělat, když ne?
Pokud jsou vaše výstupy chybné, ale nezpůsobují hlášení chyb, jak byste věděli?
Víte, jestli jsou vaše trénovací algoritmy odolné vůči nežádoucím vstupům na matematické úrovni?
Jak se můžete zotavit z nežádoucí kontaminace trénovacích dat?
- Můžete izolovat nebo umístit nežádoucí obsah do karantény a přetrénovat ovlivněné modely?
-Můžete vrátit zpět/obnovit model předchozí verze pro opětovné trénování?
Používáte výztužné učení na nehodnocený veřejný obsah?
Začněte přemýšlet o původu vašich dat – najdete-li problém, mohli byste jej sledovat až k jeho zavedení do datové sady? Pokud ne, je to problém?
Zjistěte, odkud trénovací data pocházejí, a identifikujte statistické normy, abyste mohli začít rozumět tomu, jak vypadají anomálie.
- Jaké prvky trénovacích dat jsou zranitelné vůči vnějšímu vlivu?
- Kdo může přispívat do datových sad, ze kterých se učíte?
- Jak byste napadli zdroje trénovacích dat, aby poškodili konkurenta?
Související hrozby a zmírnění rizik v tomto dokumentu
Adversariální perturbace (všechny varianty)
Otrava dat (všechny typy)
Příklady útoků
Vynucení klasifikace neškodných e-mailů jako spamu nebo odstranění škodlivého příkladu
Vstupy vytvořené útočníkem, které snižují úroveň spolehlivosti správné klasifikace, zejména ve scénářích s vysokým následkem
Útočník náhodně vloží šum do zdrojových dat určených ke klasifikaci, aby se snížila pravděpodobnost, že se v budoucnu použije správná klasifikace, čímž účinně zjednodušuje model.
Kontaminace trénovacích dat tak, aby vynutil nesprávnou klasifikaci vybraných datových bodů, což vede ke konkrétním akcím, které systém podnikne nebo vynechá.
Identifikace akcí, které by mohly provést vaše modely nebo produkty nebo služby, které můžou způsobit poškození zákazníka online nebo ve fyzické doméně
Shrnutí
Pokud nejsou zmírněny, útoky na systémy AI/ML mohou proniknout do fyzického světa. Jakýkoli scénář, který může být převrácený na psychicky nebo fyzicky škodu uživatelům, představuje katastrofické riziko pro váš produkt nebo službu. To se vztahuje na všechna citlivá data o vašich zákaznících používaná pro trénování a návrhová rozhodnutí, která mohou uniknout tyto soukromé datové body.
Otázky týkající se kontroly zabezpečení
Trénujete s nežádoucími příklady? Jaký dopad mají na výstup modelu ve fyzické doméně?
Jak trolling vypadá ve vašem produktu nebo službě? Jak na to můžete zjistit a reagovat?
Co je potřeba, aby váš model vrátil výsledek, který přiměje vaši službu odepřít přístup legitimním uživatelům?
Jaký je dopad kopírování nebo odcizení modelu?
Dá se váš model použít k odvození členství jednotlivce v konkrétní skupině nebo jednoduše k trénovacím datům?
Může útočník způsobit poškození reputace nebo negativní reakci veřejnosti vůči vašemu produktu tím, že ho přinutí provést konkrétní akce?
Jak zpracováváte správně formátovaná, ale příliš zkreslená data, například z trollů?
Pro každý způsob interakce s modelem nebo jejich dotazování je možné tuto metodu prověřit, aby se odhalila trénovací data nebo funkce modelu?
Související hrozby a zmírnění rizik v tomto dokumentu
Odvození členství
Inverze modelu
Krádež modelu
Příklady útoků
Obnovení a extrakce trénovacích dat opakovaným dotazováním modelu na maximální spolehlivost
Duplikace samotného modelu vyčerpávajícím porovnáváním dotazů a odpovědí
Dotazování modelu způsobem, který odhalí konkrétní prvek privátních dat, byl zahrnut do trénovací sady.
Autonomní vozidlo je oklamáno, aby ignorovalo dopravní značky a semafory.
Konverzační roboti manipulovaní, aby trollovali neškodné uživatele
Identifikace všech zdrojů závislostí AI/ML a také front-endových prezentačních vrstev v dodavatelském řetězci dat/modelu
Shrnutí
Řada útoků v AI a Machine Learning začíná legitimním přístupem k rozhraním API, která se objevují, aby poskytovala přístup k dotazu na model. Vzhledem k bohatým zdrojům dat a bohatým uživatelským zkušenostem, které jsou zde zahrnuty, představuje ověřený, ale "nevhodný" (tady je šedá oblast) přístup třetí strany k vašim modelům riziko z důvodu schopnosti chovat se jako prezentační vrstva nad službou poskytovanou Microsoftem.
Otázky týkající se kontroly zabezpečení
Kteří zákazníci nebo partneři se ověřují pro přístup k vašemu modelu nebo rozhraním API služeb?
- Můžou fungovat jako prezentační vrstva nad vaší službou?
-Můžete jejich přístup okamžitě odvolat v případě ohrožení zabezpečení?
- Jaká je vaše strategie obnovení v případě škodlivého použití vaší služby nebo závislostí?
Může třetí strana vytvořit obal kolem vašeho modelu, aby ji znovu použila a poškodila Microsoft nebo jeho zákazníky?
Poskytují vám zákazníci přímo data pro školení?
- Jak tato data zabezpečíte?
- Co když je to škodlivý a vaše služba je cílem?
Jak vypadá falešně pozitivní výsledek? Jaký je dopad falešně negativního?
Můžete sledovat a měřit odchylku pravdivě pozitivních a falešně pozitivních sazeb v různých modelech?
Jaký druh telemetrie potřebujete k prokázání důvěryhodnosti výstupu modelu zákazníkům?
Identifikujte všechny závislosti třetích stran v dodavatelském řetězci strojového učení/tréninkových dat – nejen opensourcový software, ale také poskytovatele dat.
- Proč je používáte a jak ověříte jejich důvěryhodnost?
Používáte předem vytvořené modely od 3rd party nebo odesíláte trénovací data poskytovatelům MLaaS 3rd party?
Inventarizace zpráv o útocích na podobné produkty nebo služby Jaký dopad by tyto útoky měly na vaše vlastní produkty, abyste pochopili, že mnoho hrozeb AI/ML se přenáší mezi typy modelů?
Související hrozby a zmírnění rizik v tomto dokumentu
Přeprogramování neurální sítě
Nežádoucí příklady ve fyzické doméně
Poskytovatelé strojového učení se zlými úmysly obnovují trénovací data
Útok na dodavatelský řetězec ML
Model s backdoorem
Ohrožené závislosti specifické pro ML
Příklady útoků
Škodlivý poskytovatel MLaaS napadne váš model trojským koněm s konkrétním obejitím.
Nepřátelský zákazník najde zranitelnost v běžné závislosti otevřeného softwaru, kterou používáte, nahraje upravená trénovací data, aby kompromitoval vaši službu.
Neskrupulózní partner používá API pro rozpoznávání obličeje a vytváří prezentační vrstvu nad vaší službou pro vytváření "Deep Fakes".
Hrozby specifické pro AI/ML a jejich zmírnění
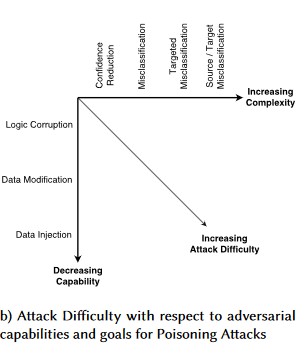
Č. 1: Adversariální perturbace
Popis
V perturbačním útoku útočník neviditelně upraví dotaz tak, aby získal požadovanou odpověď z modelu nasazeného v produkčním prostředí[1]. Jedná se o porušení integrity vstupu modelu, což vede k útokům ve stylu přibližného stylu, kdy konečným výsledkem nemusí být nutně porušení přístupu nebo EOP, ale místo toho dojde k ohrožení výkonu klasifikace modelu. To se také může projevit trolly, kteří používají určitá cílová slova způsobem, který je AI zakáže, a účinně zamítne službu legitimním uživatelům s názvem, který odpovídá "zakázanému" slovu.
 [24]
[24]
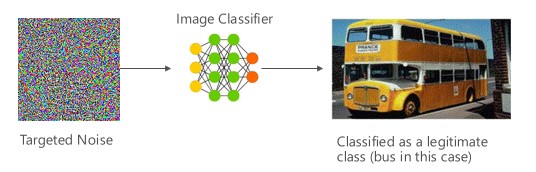
Variantní #1a: Cílová chybná klasifikace
V tomto případě útočníci vygenerují vzorek, který není ve vstupní třídě cílového klasifikátoru, ale klasifikuje model jako konkrétní vstupní třídu. Nežádoucí vzorek může vypadat jako náhodný šum pro lidské oči, ale útočníci mají určité znalosti o cílovém systému strojového učení, aby vygenerovali bílý šum, který není náhodný, ale využívá některé konkrétní aspekty cílového modelu. Nežádoucí osoba poskytne vstupní vzorek, který není legitimním vzorkem, ale cílový systém ho klasifikuje jako legitimní třídu.
Příklady
 [6]
[6]
Omezení rizik
Posílení odolnosti proti útokům pomocí modelové důvěry vyvolané adverzářským trénováním [19]: Autoři navrhují Vysoce sebevědomého blízkého souseda (HCNN), architekturu, která kombinuje informace o důvěře a hledání nejbližších sousedů, aby posílila odolnost základního modelu proti útokům. To může pomoct rozlišovat mezi správnými a nesprávnými predikcemi modelu v okolí bodu vzorkovaného z podkladové trénovací distribuce.
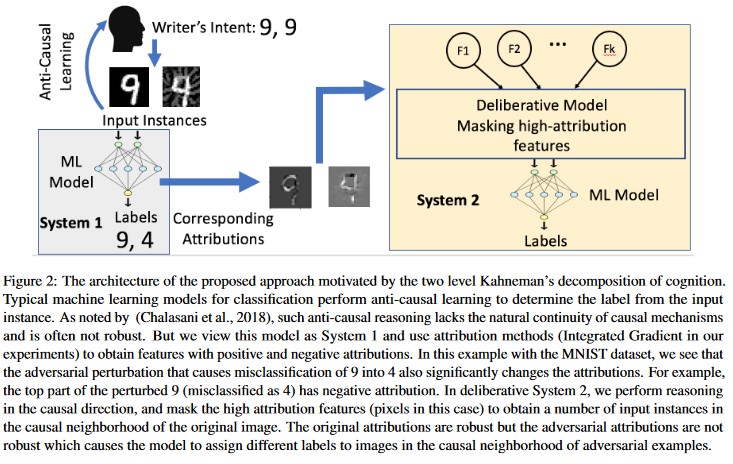
Kauzální analýza řízená atribucí [20]: Autoři studují propojení mezi odolností vůči adversiálním perturbacím a vysvětlením jednotlivých rozhodnutí generovaných modely strojového učení. Hlásí, že nežádoucí vstupy nejsou robustní v prostoru pro přisuzování, tj. maskování několika funkcí s vysokým přiřazením vede ke změně nedecision modelu strojového učení v nežádoucích příkladech. Naproti tomu přirozené vstupy jsou robustní v prostoru pro přisuzování.
 [20]
[20]
Díky těmto přístupům může být modely strojového učení odolnější vůči nežádoucím útokům, protože oklamat tento dvouvrstvý systém poznání vyžaduje nejen útok na původní model, ale také zajistit, aby přisuzování vygenerované pro nežádoucí příklad bylo podobné původním příkladům. Oba systémy musí být současně ohroženy úspěšným nežádoucím útokem.
Tradiční paralely
Vzdálené zvýšení oprávnění, protože útočník je teď pod kontrolou vašeho modelu
Závažnost
Kritický
Variantní #1b: Chybná klasifikace zdroje nebo cíle
To je charakterizováno jako pokus útočníka přimět model k vrácení požadovaného štítku pro daný vstup. To obvykle vynutí, aby model vrátil falešný pozitivní výsledek nebo falešný negativní výsledek. Konečným výsledkem je nepostřehnutelné ovlivnění přesnosti klasifikace modelu, kdy útočník může vyvolat specifická obejití podle své vůle.
I když má tento útok významný negativní dopad na přesnost klasifikace, může být také časově náročnější na provedení, protože útočník musí nejen manipulovat se zdrojovými daty, aby nebyla správně označena, ale také aby byla označena konkrétním požadovaným podvodným popiskem. Tyto útoky často zahrnují několik kroků nebo pokusů o vynucení chybné klasifikace [3]. Pokud je model náchylný k útokům využívajícím přenosové učení, které vedou k cílené nesprávné klasifikaci, nemusí existovat žádná rozpoznatelná stopa provozu útočníka, protože je možné provádět sondovací útoky offline.
Příklady
Vynucení klasifikace neškodných e-mailů jako spam nebo způsobení, že škodlivý příklad zůstane neodhalen. Označují se také jako modelové úniky nebo napodobování útoků.
Omezení rizik
Reaktivní/obranné akce detekce
- Implementujte minimální časovou prahovou hodnotu mezi voláními rozhraní API poskytujícím výsledky klasifikace. Tím se zpomalí vícestupňové testování útoků zvýšením celkové doby potřebné k nalezení perturbace úspěchu.
Proaktivní/ochranné akce
Odstraňování šumu pro zlepšení odolnosti vůči útokům [22]: Autoři vyvíjejí novou síťovou architekturu, která zvyšuje odolnost vůči útokům prováděním odstranění šumu z funkcí. Konkrétně sítě obsahují bloky, které označují funkce pomocí jiných než místních prostředků nebo jiných filtrů; celé sítě jsou vytrénované uceleně. V kombinaci s nežádoucím trénováním funkce označující sítě výrazně vylepšují špičkový stav nežádoucí robustnosti v nastavení útoku white-box i black-box.
Adverzariální trénink a regularizace: Trénování se známými adverzariálními ukázkami za účelem vytvoření odolnosti a robustnosti proti nepřátelským vstupům. To lze také považovat za formu regularizace, která penalizuje normu vstupních přechodů a usnadňuje predikční funkci klasifikátoru (zvýšení vstupního okraje). To zahrnuje správné klasifikace s nižší mírou spolehlivosti.
Investujte do vývoje monotónní klasifikace s výběrem monotónních funkcí. Tím se zajistí, že protivník nebude moct klasifikátor obejít jednoduše doplňkovými prvky ze záporné třídy [13].
Funkce squeezing [18] lze použít k posílení modelů DNN detekcí nežádoucích příkladů. Zmenšuje vyhledávací prostor dostupný nežádoucímu uživateli tak, že shodí vzorky, které odpovídají mnoha různým vektorům funkcí v původním prostoru, do jediného vzorku. Porovnáním predikce modelu DNN na původním vstupu s predikcí na zjednodušeném vstupu může zjednodušení funkcí pomoci detekovat útočné příklady. Pokud původní a transformované příklady produkují podstatně odlišné výstupy z modelu, je pravděpodobné, že vstup bude adverzární. Když systém změří neshodu mezi předpověďmi a vybere prahovou hodnotu, může vypíše správnou předpověď legitimních příkladů a odmítne nežádoucí vstupy.

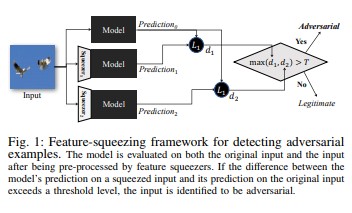 [18]
[18]Certified Defenses against Adversarial Examples [22]: Autoři navrhují metodu založenou na částečně jednoznačném uvolnění, které vypíše certifikát, který pro danou síť a testovací vstup, žádný útok nemůže vynutit, aby chyba překročila určitou hodnotu. Za druhé, protože tento certifikát je rozdílný, autoři ho společně optimalizují pomocí parametrů sítě a poskytují adaptivní regularizátor, který podporuje robustnost proti všem útokům.
Akce odpovědi
- Vystavovat výstrahy na výsledky klasifikace s vysokou odchylkou mezi klasifikátory, zejména pokud jde o jednoho uživatele nebo malou skupinu uživatelů.
Tradiční paralely
Vzdálené zvýšení oprávnění
Závažnost
Kritický
Varianta #1c: Náhodná chybná klasifikace
Jedná se o speciální variantu, kdy cílová klasifikace útočníka může být cokoli jiného než legitimní klasifikace zdroje. Útok obecně zahrnuje injektáž šumu náhodně do zdrojových dat klasifikovaných, aby se snížila pravděpodobnost, že se v budoucnu použije správná klasifikace [3].
Příklady
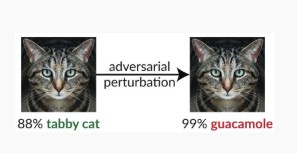
Omezení rizik
Stejné jako varianta 1a.
Tradiční paralely
Nepřetržité odepření služby
Závažnost
Důležité
Variantní #1d: Snížení spolehlivosti
Útočník může vytvořit vstupy, aby snížil důvěru ve správnou klasifikaci, zejména ve scénářích s vysokými důsledky. To může mít také podobu velkého počtu falešně pozitivních výsledků, které mají zahltit správce nebo systémy monitorování podvodnými výstrahami nerozlišující od legitimních výstrah [3].
Příklady

Omezení rizik
- Kromě akcí popsaných ve variantě #1a je možné omezení událostí použít ke snížení objemu výstrah z jednoho zdroje.
Tradiční paralely
Nepřetržité odepření služby
Závažnost
Důležité
#2a cílená otrava dat
Popis
Cílem útočníka je kontaminovat model stroje vygenerovaný ve fázi trénování, aby se předpovědi nových dat upravily ve fázi testování[1]. Při cílených útocích na otravu se útočník snaží nesprávně klasifikovat konkrétní příklady, aby vyvolal specifické akce, které mají být provedeny nebo vynechány.
Příklady
Odeslání softwaru AV jako malwaru k vynucení jeho chybné klasifikace jako škodlivého softwaru a odstranění použití cíleného AV softwaru v klientských systémech.
Omezení rizik
Definujte senzory anomálií pro každodenní zobrazení distribuce dat a upozorňování na varianty.
-Měření denní odchylky trénovacích dat, telemetrie pro nerovnoměrnou distribuci nebo posun
Ověřování vstupu, sanitizace i kontrola integrity
Otrava injektuje odsud trénovací vzorky. Dvě hlavní strategie pro boj proti této hrozbě:
-Sanitizace dat / ověření: odebrání vzorků otravy z trénovacích dat -Bagging pro boj s útoky na otravu [14]
-Ochrana odmítnutíNegative-Impact (RONI) [15]
-Robustní učení: Vyberte algoritmy učení, které jsou robustní v přítomnosti vzorků otravy.
-Jeden takový přístup je popsán v [21], kde autoři řeší problém otravy dat ve dvou krocích: 1) zavedení nové robustní maticové faktorizační metody pro obnovení skutečného podprostoru a 2) nové robustní hlavní regrese komponent, aby vyřazuje nežádoucí instance na základě základu obnoveného v kroku (1). Charakterizují nezbytné a dostatečné podmínky pro úspěšné obnovení skutečného podprostoru a představují vazbu na očekávanou ztrátu předpovědi v porovnání se základní pravdou.
Tradiční paralely
Trojský hostitel, kde útočník přetrvává v síti. Trénovací nebo konfigurační data jsou ohrožena a jsou ingestována nebo důvěryhodná pro vytváření modelů.
Závažnost
Kritický
#2b nerozlišující otravu dat
Popis
Cílem je zničit kvalitu a integritu napadené datové sady. Řada datových sad je veřejná, nedůvěryhodná nebo nehodnocená, takže to na prvním místě vytváří další obavy týkající se možnosti odhalit porušení integrity dat. Trénování na neúmyslně ohrožených datech je situace, kdy dochází k uvolnění paměti nebo uvolnění paměti. Po zjištění je potřeba určit rozsah dat, u kterých došlo k porušení zabezpečení, a karanténě nebo opětovnému natrénování.
Příklady
Společnost vytrénuje své modely známým a důvěryhodným webem pro data o budoucnosti ropy. Web poskytovatele dat je následně ohrožen útokem prostřednictvím injektáže SQL. Útočník může datovou sadu otrávit najednou a trénovaný model nemá žádnou představu o tom, že data jsou tainted.
Omezení rizik
Stejné jako varianta 2a.
Tradiční paralely
Ověření odepření služby vůči vysoce hodnotovanému prostředku
Závažnost
Důležité
Útoky na inverzi modelů č. 3
Popis
Privátní funkce používané v modelech strojového učení je možné obnovit [1]. To zahrnuje rekonstrukci privátních trénovacích dat, ke kterým útočník nemá přístup. Označuje se také jako útoky na horolezectví v biometrické komunitě [16, 17] Toho se dosahuje nalezením vstupu, který maximalizuje vrácenou úroveň spolehlivosti, v závislosti na klasifikaci odpovídající cíli [4].
Příklady
 [4]
[4]
Omezení rizik
Rozhraní k modelům natrénovaným z citlivých dat potřebují silné řízení přístupu.
Dotazy na omezení rychlosti povolené modelem
Implementujte brány mezi uživateli nebo volajícími a skutečným modelem provedením ověřování vstupu u všech navrhovaných dotazů, odmítnutím čehokoli, co nesplňuje definici správnosti vstupu modelu, a vrácením pouze minimálního množství informací potřebných k tomu, aby bylo užitečné.
Tradiční paralely
Cílem je zpřístupnění tajných informací.
Závažnost
Výchozí hodnota je důležitá podle standardního panelu chyb SDL, ale pokud by došlo k extrakci citlivých nebo osobně identifikovatelných dat, zvýšilo by to úroveň na kritickou.
Útok na odvození členství č. 4
Popis
Útočník může určit, jestli byl daný datový záznam součástí trénovací datové sady modelu, nebo ne[1]. Výzkumní pracovníci dokázali předpovědět hlavní postup pacienta (např. operaci, po které pacient prošel) na základě atributů (např. věk, pohlaví, nemocnice) [1].
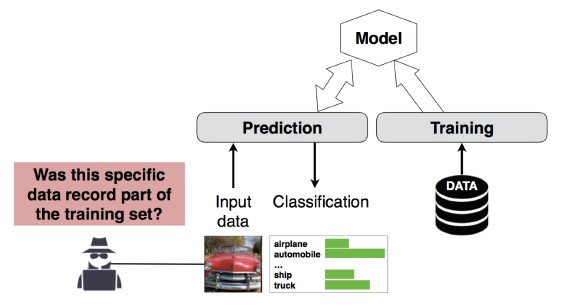 [12]
[12]
Omezení rizik
Výzkumné studie demonstrující životaschopnost tohoto útoku naznačují, že rozdílové soukromí [4, 9] by bylo efektivním zmírněním rizik. Tento obor je ve společnosti Microsoft stále ještě v plenkách a AETHER Security Engineering doporučuje rozvíjet v něm odborné znalosti prostřednictvím investic do výzkumu. Tento výzkum by potřeboval vytvořit výčet schopností rozdílové ochrany osobních údajů a vyhodnotit jejich praktickou efektivitu jako zmírnění rizik a pak navrhnout způsoby, jak se tyto ochrany zdědí transparentně na našich platformách online služeb, podobně jako kompilace kódu v sadě Visual Studio vám poskytne on-byvýchozí ochranu zabezpečení, která jsou pro vývojáře a uživatele transparentní.
Využití výpadku neuronů a stohování modelů může být do jisté míry efektivní opatření. Použití výpadku neuronu nejen zvyšuje odolnost neurální sítě k tomuto útoku, ale také zvyšuje výkon modelu [4].
Tradiční paralely
Ochrana osobních údajů Odvozování se týká zahrnutí datového bodu do trénovací sady, ale samotná trénovací data se nezveřejňují.
Závažnost
Jedná se o problém s ochranou osobních údajů, ne o problém se zabezpečením. Řeší se v doprovodných materiálech k modelování hrozeb, protože se domény překrývají, ale jakákoli odpověď by zde byla řízena ochranou osobních údajů, nikoli zabezpečením.
Č. 5 Krádež modelu
Popis
Útočníci znovu vytvoří základní model legitimním dotazováním modelu. Funkce nového modelu jsou stejné jako funkce základního modelu[1]. Po opětovném vytvoření modelu jej lze invertovat k obnovení informací o vlastnostech nebo k odhadu založenému na trénovacích datech.
Řešení rovnic – Pro model, který vrací pravděpodobnosti tříd prostřednictvím výstupu rozhraní API, může útočník vytvořit dotazy k určení neznámých proměnných v modelu.
Hledání cest – útok, který využívá specifika rozhraní API k extrahování "rozhodnutí" přijatých stromem při klasifikaci vstupu [7].
Útok na přenoselnost – nežádoucí osoba může vytrénovat místní model – pravděpodobně vydáním prediktivních dotazů na cílový model – a použít ho k vytvoření nežádoucích příkladů, které se přenesou do cílového modelu [8]. Pokud se váš model extrahuje a zjistí, že je ohrožený typem nežádoucího vstupu, můžou nové útoky na model nasazený v produkčním prostředí vyvíjet zcela offline útočníkem, který extrahoval kopii vašeho modelu.
Příklady
V nastavení, kde model ML slouží k detekci nežádoucího chování, jako je identifikace spamu, klasifikace malwaru a detekce anomálií sítě, může extrakce modelů usnadnit útoky před únikem [7].
Omezení rizik
Proaktivní/ochranné akce
Minimalizujte nebo zatemněte podrobnosti vrácené v rozhraních API pro predikce a přitom zachovejte jejich užitečnost pro upřímné aplikace [7].
Definujte dobře formátovaný dotaz pro vstupy modelu a vrátí výsledky pouze v reakci na dokončené vstupy ve správném formátu.
Vrátí hodnoty spolehlivosti zaokrouhlené na celé číslo. Většina legitimních účastníků volání nepotřebuje více desetinných míst pro přesné hodnoty.
Tradiční paralely
Neověřená manipulace se systémovým datem jen pro čtení, cílená zpřístupnění vysoce hodnotných informací?
Závažnost
Důležité v modelech citlivých na zabezpečení, jinak střední
#6 Přeprogramování neurální sítě
Popis
Pomocí speciálně vytvořeného dotazu od nežádoucího uživatele lze systémy strojového učení přeprogramovat na úkol, který se liší od původního záměru autora [1].
Příklady
Slabé řízení přístupu k rozhraní API pro rozpoznávání obličeje umožňuje třetím stranám začlenit ho do aplikací navržených k poškození zákazníků Microsoftu, jako je generátor hlubokých padělků.
Omezení rizik
Silné vzájemné ověřování klient-server a řízení přístupu k rozhraní modelu
Odstranění nevhodných účtů.
Identifikujte a vynucujte smlouvu o úrovni služeb pro vaše rozhraní API. Určete přijatelnou dobu opravy problému po nahlášení a zajistěte, aby se problém po vypršení platnosti smlouvy SLA přestal opakovat.
Tradiční paralely
Toto je scénář zneužití. Méně pravděpodobné je, že na tomto incidentu otevřete bezpečnostní incident, než když jednoduše zakážete účet pachatele.
Závažnost
Od důležitých po kritické
#7 Nepřátelský příklad v oblasti fyzického světa (bity-atomy >)
Popis
Záludný příklad je vstup nebo dotaz od zlomyslného subjektu, odeslaný s jediným cílem zmást systém strojového učení [1]
Příklady
Tyto příklady se můžou projevit ve fyzické doméně, jako je autonomní auto, které je oklamáno, aby přejelo stopku kvůli určité barvě světla (nežádoucí vstup), svítící na stopku, a vynutí tak systém rozpoznávání obrazu, aby přestal rozeznávat stopku jako stopku.
Tradiční paralely
Zvýšení oprávnění, vzdálené spuštění kódu
Omezení rizik
Tyto útoky se projeví, protože se nezmírnily problémy ve vrstvě strojového učení (vrstva dat a algoritmu pod rozhodováním řízeným AI). Stejně jako u jakéhokoli jiného softwarového *nebo* fyzického systému může být vrstva pod cílem vždy napadena tradičními vektory. Z tohoto důvodu jsou tradiční postupy zabezpečení důležitější než kdy dřív, zejména u vrstvy nemitigovaných ohrožení zabezpečení (vrstvy dat/algo), které se používají mezi AI a tradičním softwarem.
Závažnost
Kritický
#8 Poskytovatelé strojového učení se zlými úmysly, kteří můžou obnovit trénovací data
Popis
Poskytovatel se zlými úmysly představuje algoritmus s zadními vrátky, ve kterém jsou obnovena soukromá trénovací data. Podařilo se jim rekonstruovat tváře a texty, samo pomocí modelu.
Tradiční paralely
Zpřístupnění cílových informací
Omezení rizik
Výzkumné studie demonstrující životaschopnost tohoto útoku naznačují, že homomorfní šifrování by bylo efektivním zmírněním rizik. Toto je oblast s malými aktuálními investicemi v Microsoftu a AETHER Security Engineering doporučuje vytvářet odborné znalosti s investicemi do výzkumu v tomto prostoru. Tento výzkum by potřeboval vytvořit výčet homomorfních šifrovacích tenetů a vyhodnotit jejich praktickou efektivitu jako zmírnění rizik v případě škodlivých poskytovatelů ML jako služeb.
Závažnost
Důležité, pokud jsou data osobní identifikační informace (PII), jinak střední.
#9: Útok na dodavatelský řetězec ML
Popis
Vzhledem k velkým prostředkům (data + výpočty) potřebným k trénování algoritmů je současnou praxí znovu použít modely natrénované velkými korporacemi a mírně je upravit pro konkrétní úkol (např. ResNet je významný model pro rozpoznávání obrazů od Microsoftu). Tyto modely jsou kurátorovány v Model Zoo (Caffe hostuje oblíbené modely rozpoznávání obrázků). V tomto útoku nežádoucí osoba napadá modely hostované v Caffe, čímž otravuje dobře pro všechny ostatní. [1]
Tradiční paralely
Ohrožení závislostí třetích stran nesouvisenou se zabezpečením
App Store neúmyslně hostující malware
Omezení rizik
Pokud je to možné, minimalizujte závislosti třetích stran pro modely a data.
Tyto závislosti začleníte do procesu modelování hrozeb.
Využijte silné ověřování, řízení přístupu a šifrování mezi systémy prvních a třetích stran.
Závažnost
Kritický
Číslo 10: Skryté mechanismy strojového učení
Popis
Proces trénování je outsourcovaný škodlivé třetí straně, která manipuluje s trénovacími daty a doručila infikovaný model, který vynutí cílené chybné klasifikace, například klasifikaci určitého viru jako neškodného[1]. Jedná se o riziko ve scénářích generování modelů ML jako služby.
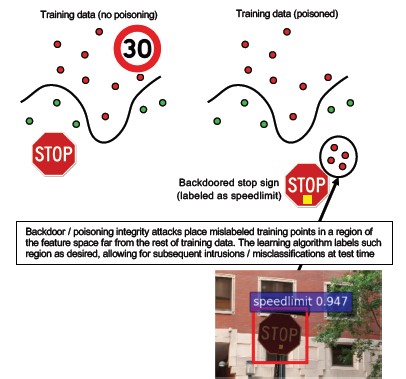 [12]
[12]
Tradiční paralely
Porušení bezpečnostní závislosti třetích stran
Ohrožený mechanismus aktualizace softwaru
Kompromitace certifikační autority
Omezení rizik
Reaktivní/obranné akce detekce
- Poškození je již způsobeno, jakmile je tato hrozba zjištěna, takže model a veškerá trénovací data poskytnutá škodlivým poskytovatelem nemohou být důvěryhodná.
Proaktivní/ochranné akce
Trénujte všechny citlivé modely interně
Katalogizujte tréninková data nebo zajistěte, že pocházejí od důvěryhodné třetí strany s silnými bezpečnostními postupy.
Model ohrožení interakce mezi poskytovatelem MLaaS a vašimi vlastními systémy
Akce odpovědi
- Stejné jako v případě ohrožení externí závislosti
Závažnost
Kritický
Č. 11 Zneužít softwarové závislosti systému ML
Popis
V tomto útoku útočník nemanipuluje s algoritmy. Místo toho zneužije chyby zabezpečení softwaru, jako jsou přetečení vyrovnávací paměti nebo skriptování mezi weby[1]. Stále je jednodušší ohrozit softwarové vrstvy pod AI/ML, než přímo napadnout vrstvu učení, takže jsou nezbytné tradiční postupy pro zmírnění hrozeb zabezpečení podrobně popsané v životním cyklu vývoje zabezpečení.
Tradiční paralely
Ohrožená závislost na open-sourcovém softwaru
Ohrožení zabezpečení webového serveru (XSS, CSRF, chyba ověření vstupu rozhraní API)
Omezení rizik
Spolupracujte se svým týmem zabezpečení a postupujte podle příslušných osvědčených postupů pro vývoj zabezpečení nebo provozního zabezpečení.
Závažnost
Proměnná; Až kritické v závislosti na typu tradičního ohrožení zabezpečení softwaru.
Bibliografie
[1] Režimy selhání ve strojovém učení, Ram Shankar Siva Kumar, David O'Brien, Kendra Albert, Salome Viljoen a Jeffrey Snover, https://learn.microsoft.com/security/failure-modes-in-machine-learning
[2] AETHER Security Engineering Workstream, Tým pro původ/datovou linii
[3] Nežádoucí příklady v hlubokém učení: Charakterizace a divergence, Wei, et al, https://arxiv.org/pdf/1807.00051.pdf
[4] ML-Leaks: Nezávislé útoky a obrany pro zjišťování členství v modelech strojového učení, Salem, et al, https://arxiv.org/pdf/1806.01246v2.pdf
[5] M. Fredrikson, S. Jha a T. Ristenpart, „Útoky na inverzi modelů využívající informace o důvěře a základní opatření“, v Proceedings of the 2015 ACM SIGSAC Conference on Computer and Communications Security (CCS).
[6] Nicolas Papernot & Patrick McDaniel - Nežádoucí příklady ve strojovém učení AIWTB 2017
[7] Krádež modelů strojového učení prostřednictvím rozhraní API pro predikce, Florian Tramèr, École Polytechnique Fédérale de Lausanne (EPFL); Fan Zhang, Cornell University; Ari Juels, Cornell Tech; Michael K. Reiter, Univerzita Severní Karolíny na Chapel Hill; Thomas Ristenpart, Cornell Tech
[8] Prostor přenositelných nežádoucích příkladů, Florian Tramèr , Nicolas Papernot , Ian Goodfellow , Dan Boneh a Patrick McDaniel
[9] Principy odvozování členství na Well-Generalized Learning Models Yunhui Long1 , Vincent Bindschaedler1 , Lei Wang2 , Diyue Bu2 , Xiaofeng Wang2 , Haixu Tang2 , Carl A. Gunter1 a Kai Chen3,4
[10] Simon-Gabriel et al., adversiální zranitelnost neurálních sítí se zvyšuje s rostoucí dimenzí vstupu, ArXiv 2018;
[11] Lyu et al., Jednotná rodina gradientní regularizace pro adversariální příklady, ICDM 2015
[12] Divoké vzory: Deset let po vzestupu nežádoucího strojového učení - NeCS 2019 Battista Biggioa, Fabio Roli
[13] Adversální robustní detekce malwaru pomocí monotónní klasifikace Inigo Incer et al.
[14] Battista Biggio, Igino Corona, Giorgio Fumera, Giorgio Giacinto a Fabio Roli. Bagging klasifikátorů pro boj proti otravným útokům v úkoly adversariální klasifikace
[15] Vylepšené odmítnutí negativního dopadu obrany Hongjiang Li a Patrick P.K. Chan
[16] Adler. Ohrožení zabezpečení v biometrických šifrovacích systémech 5. mezinárodní konference AVBPA, 2005
[17] Galbally, McCool, Fierrez, Marcel, Ortega-Garcia. Na zranitelnost systémů pro ověřování tváře vůči útokům typu "hill-climbing". Patt. Rec., 2010
[18] Weilin Xu, David Evans, Yanjun Qi. Vyřazování funkcí: Detekce nežádoucích příkladů v hlubokých neurálních sítích 2018 Network and Distributed System Security Symposium. 18–21. února.
[19] Posílení odolnosti proti útokům pomocí modelové spolehlivosti vyvolané tréninkem zaměřeným na útoky – Xi Wu, Uyeong Jang, Jiefeng Chen, Lingjiao Chen, Somesh Jha
[20] Přisuzovaná kauzální analýza pro detekci nežádoucích příkladů, Susmit Jha, Sunny Raj, Steven Fernandes, Sumit Kumar Jha, Somesh Jha, Gunjan Verma, Brian Jalaian, Ananthram Swami
[21] Robustní lineární regrese proti znečištění výcvikových dat – Chang Liu et al.
[22] Odstranění šumu pro zlepšení odolnosti proti útokům, Cihang Xie, Yuxin Wu, Laurens van der Maaten, Alan Yuille, Kaiming He
[23] Certifikované obrany proti nežádoucím příkladům – Aditi Raghunathan, Jacob Steinhardt, Percy Liang