Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Aby byl datový model uložen v databázi, je potřeba ho převést do formátu, kterému databáze rozumí. Různé databáze vyžadují různá schémata a formáty úložiště. Některé mají striktní schéma, které je potřeba dodržovat, zatímco jiné umožňují, aby schéma bylo definováno uživatelem.
Konektory vektorového úložiště, které poskytuje Sémantické jádro, mají integrované mapovače, které mapují datový model mezi datovým modelem a schématy databáze. Další informace o tom, jak integrované mapovače mapují data pro každou databázi, najdete na stránce jednotlivých konektorů .
Aby byl datový model definovaný buď jako třída , nebo definice uložená v databázi, musí být serializován do formátu, kterému databáze rozumí.
Existují dva způsoby, které lze provést buď pomocí integrované serializace poskytované sémantické jádro, nebo poskytnutím vlastní logiky serializace.
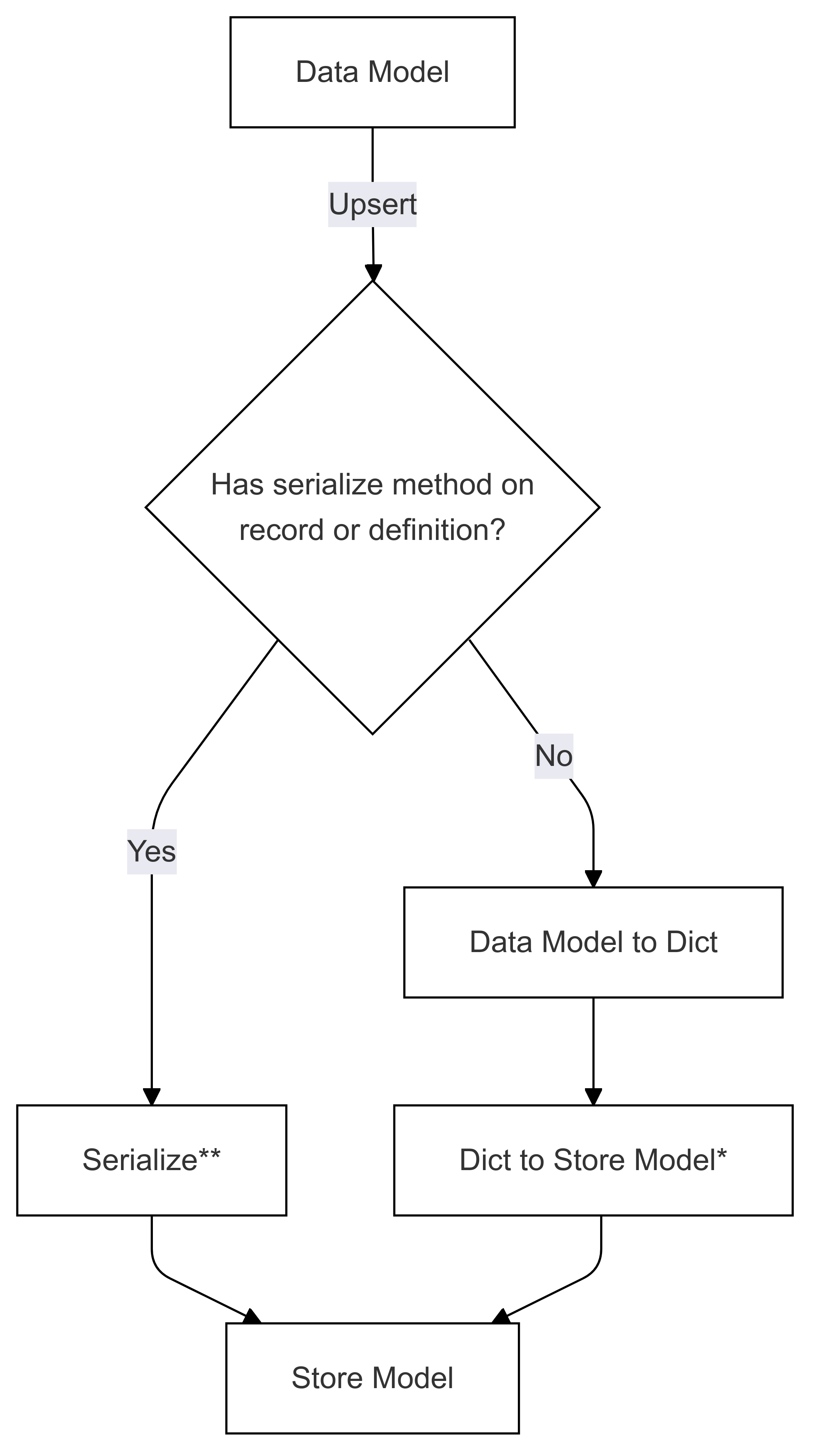
Následující dva diagramy znázorňují toky pro serializaci i deserializaci datových modelů do a z modelu úložiště.
Tok serializace (použitý v upsertu)
Tok deserializace (použitý v Get and Search)
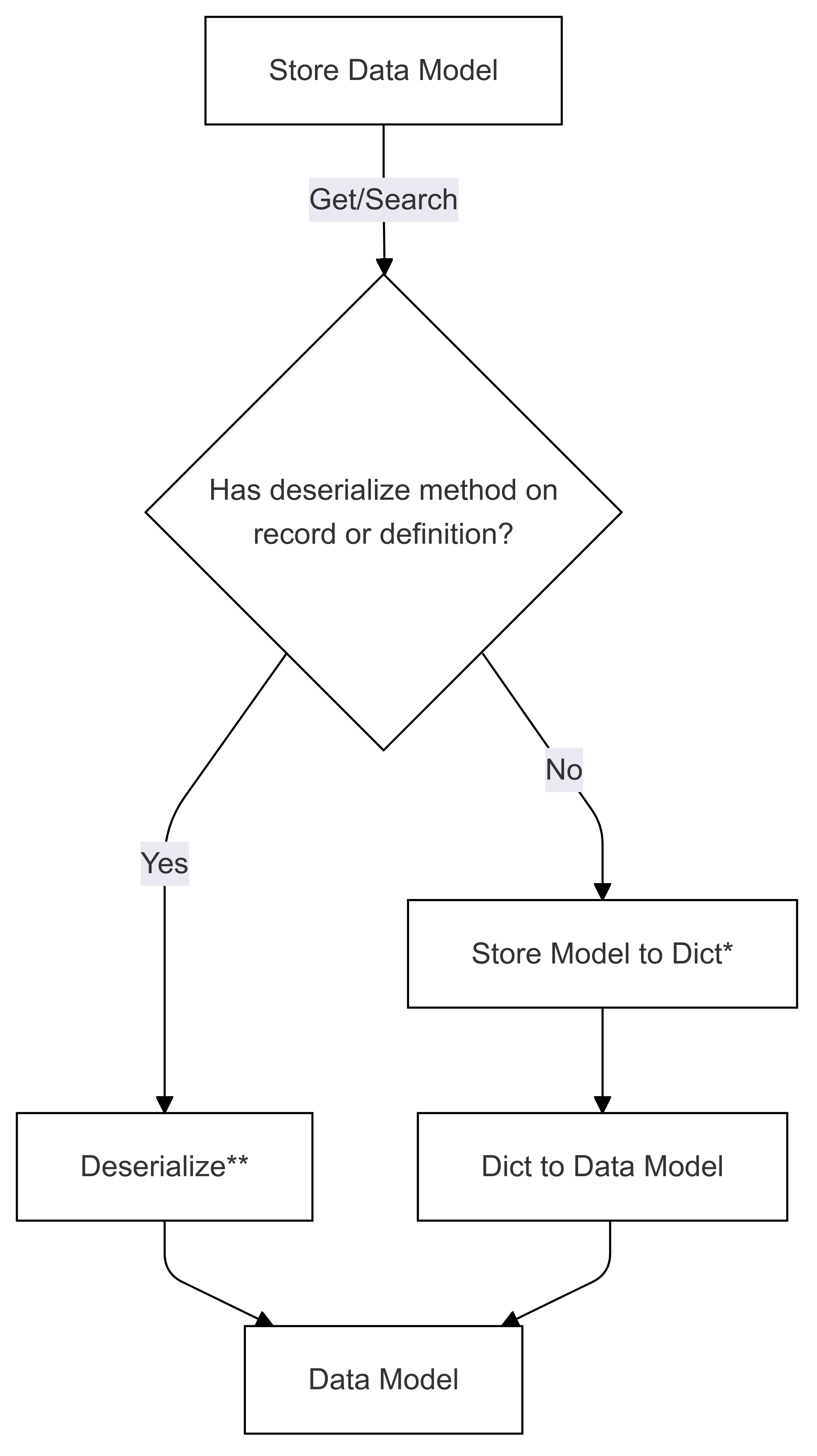
Kroky označené * (v obou diagramech) jsou implementovány vývojářem konkrétního konektoru a liší se pro každé úložiště. Kroky označené ** (v obou diagramech) se zadají buď jako metoda záznamu, nebo jako součást definice záznamu, to je vždy zadáno uživatelem, viz Přímé serializace , kde najdete další informace.
(De)Přístupy k serializaci
Přímé serializace (datový model pro uložení modelu)
Přímá serializace je nejlepší způsob, jak zajistit úplnou kontrolu nad tím, jak se modely serializují a optimalizují výkon. Nevýhodou je, že je specifická pro úložiště dat, a proto při použití tohoto úložiště není tak snadné přepínat mezi různými úložišti se stejným datovým modelem.
Můžete to použít implementací metody, která se řídí protokolem SerializeMethodProtocol v datovém modelu, nebo přidáním funkcí, které následují SerializeFunctionProtocol definici záznamu, najdete obojí v semantic_kernel/data/vector_store_model_protocols.py.
Pokud je k dispozici jedna z těchto funkcí, použije se k přímému serializaci datového modelu do modelu úložiště.
Můžete dokonce implementovat pouze jednu z těchto dvou možností a použít vestavěnou serializaci/deserializaci pro opačný směr, což může být například užitečné při práci s kolekcí, která byla vytvořena mimo vaši kontrolu a potřebujete provést určité přizpůsobení způsobu deserializace (a stejně nemůžete provést upsert).
Integrovaná (de)serializace (datový model pro diktování a diktování pro uložení modelu a naopak)
Předdefinovaná serializace se provádí tak, že nejprve převedete datový model do slovníku a potom ho serializujete na model, který ukládá, pro každé úložiště, které je odlišné a definované jako součást integrovaného konektoru. Deserializace se provádí v obráceném pořadí.
Serializace Krok 1: Datový model do diktování
V závislosti na typu datového modelu, který máte, se kroky provádějí různými způsoby. Existují čtyři způsoby, jak se pokusí serializovat datový model do slovníku:
-
to_dictdefiniční metoda (se řadí k atributu to_dict datového modelu, dleToDictFunctionProtocol) - zkontrolujte, jestli je záznam
ToDictMethodProtocol, a použijte metoduto_dict. - zkontrolujte, jestli je záznam Pydantickým modelem, a použijte
model_dumpmodelu. Další informace najdete v následující poznámce. - procházení polí v definici a vytvoření slovníku
Volitelné: Vkládání
Pokud máte datový model s polem embedding_generator nebo je v kolekci embedding_generator pole, vkládání se vygeneruje a přidá do slovníku, než se serializuje do modelu úložiště.
Serializace Krok 2: Diktování pro uložení modelu
Konektor musí poskytnout metodu pro převod slovníku na model úložiště. To provádí vývojář konektoru a pro každý obchod se liší.
Deserializace – krok 1: Uložení modelu do diktování
Pro převod modelu úložiště na slovník musí konektor dodat metodu. To provádí vývojář konektoru a pro každý obchod se liší.
Deserializace – krok 2: Diktování do datového modelu
Deserializace se provádí v obráceném pořadí, zkouší tyto možnosti:
- Definice metody
from_dict(shoduje se s atributem from_dict datového modelu, v souladu sFromDictFunctionProtocol) - zkontrolujte, jestli je záznam
FromDictMethodProtocol, a použijte metodufrom_dict. - zkontrolujte, jestli je záznam Pydantickým modelem, a použijte
model_validatemodelu. Další informace najdete v následující poznámce. - Projděte pole v definici a nastavte hodnoty, pak se tento slovník předá do konstruktoru datového modelu jako pojmenované argumenty (pokud je datový model samotný slovník, v takovém případě se vrátí tak, jak je).
Poznámka
Použití Pydantic s vestavěnou serializací
Když definujete model pomocí modelu Pydantic BaseModel, použije model_dumpmodel_validate a metody k serializaci a deserializaci datového modelu do a z diktování. To se provádí pomocí metody model_dump bez parametrů, pokud chcete tuto možnost řídit, zvažte implementaci ToDictMethodProtocol v datovém modelu, protože se to zkouší jako první.
Již brzy
Další informace budou brzy k dispozici.