Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Platí pro:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Spravovaná instance
Spravovaná instance![]() Azure SQLDatabáze SQL v Microsoft Fabric
Azure SQLDatabáze SQL v Microsoft Fabric
Tento článek popisuje, jak vykreslit data pomocí balíčku Python pandas'.hist(). Databáze SQL Serveru je zdrojem, který slouží k vizualizaci intervalů dat histogramu, které obsahují po sobě jdoucí a nepřekrývající se hodnoty.
Prerequisites
SQL Server Management Studio pro obnovení ukázkové databáze do služby Azure SQL Managed Instance
Azure Data Studio. K instalaci viz Azure Data Studio.
Obnovení ukázkové databáze DW za účelem získání ukázkových dat používaných v tomto článku
Ověření obnovené databáze
Obnovenou databázi můžete ověřit dotazem na Person.CountryRegion tabulku:
USE AdventureWorksDW;
SELECT * FROM Person.CountryRegion;
Instalace balíčků Pythonu
Stáhněte a nainstalujte Azure Data Studio.
Nainstalujte následující balíčky Pythonu:
pyodbcpandassqlalchemymatplotlib
Instalace těchto balíčků:
- V poznámkovém bloku Azure Data Studio vyberte Spravovat balíčky.
- V podokně Spravovat balíčky vyberte kartu Přidat novou .
- Pro každý z následujících balíčků zadejte název balíčku, vyberte Hledat a pak vyberte Nainstalovat.
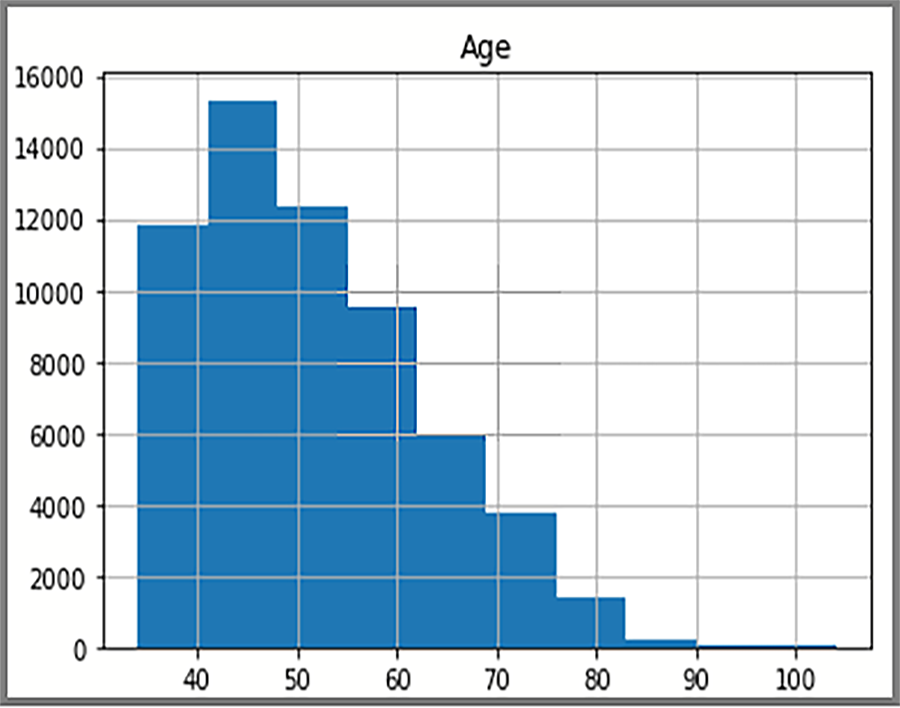
Vykreslení histogramu
Distribuovaná data zobrazená v histogramu jsou založená na dotazu SQL z AdventureWorksDW2025. Histogram vizualizuje data a frekvenci hodnot dat.
Upravte proměnné připojovacího řetězce: server, databaseusername, a password pro připojení k databázi SQL Serveru.
Vytvoření nového poznámkového bloku:
V Nástroji Azure Data Studio vyberte Soubor a vyberte Nový poznámkový blok.
V poznámkovém bloku vyberte jádro Python3 a vyberte +kód.
Vložte kód do poznámkového bloku. Vyberte Spustit vše.
import pyodbc import pandas as pd import matplotlib import sqlalchemy from sqlalchemy import create_engine matplotlib.use('TkAgg', force=True) from matplotlib import pyplot as plt # Some other example server values are # server = 'localhost\sqlexpress' # for a named instance # server = 'myserver,port' # to specify an alternate port server = 'servername' database = 'AdventureWorksDW2022' username = 'yourusername' password = 'databasename' url = 'mssql+pyodbc://{user}:{passwd}@{host}:{port}/{db}?driver=SQL+Server'.format(user=username, passwd=password, host=server, port=port, db=database) engine = create_engine(url) sql = "SELECT DATEDIFF(year, c.BirthDate, GETDATE()) AS Age FROM [dbo].[FactInternetSales] s INNER JOIN dbo.DimCustomer c ON s.CustomerKey = c.CustomerKey" df = pd.read_sql(sql, engine) df.hist(bins=50) plt.show()
Na displeji se zobrazuje věková distribuce zákazníků v FactInternetSales tabulce.