Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Platí pro:![]() SQL Server 2016 (13.x)
SQL Server 2016 (13.x) ![]() SQL Server 2017 (14.x)
SQL Server 2017 (14.x) ![]() SQL Server 2019 (15.x) v Linuxu
SQL Server 2019 (15.x) v Linuxu
Integrace Pythonu je dostupná v SQL Serveru 2017 a novějším, když do instalace služby Machine Learning Services (In-Database) zahrnete možnost Pythonu.
Poznámka:
Tento článek se v současné době týká SQL Serveru 2016 (13.x), SQL Serveru 2017 (14.x), SQL Serveru 2019 (15.x) a SQL Serveru 2019 (15.x) jenom pro Linux.
Pokud chcete vyvíjet a nasazovat řešení Pythonu pro SQL Server, nainstalujte Microsoftův revoscalepy a další knihovny Pythonu na vaši vývojovou pracovní stanici. Knihovna revoscalepy, která je také ve vzdálené instanci SQL Serveru, koordinuje výpočetní požadavky mezi oběma systémy.
V tomto článku se dozvíte, jak nakonfigurovat vývojovou pracovní stanici Pythonu, abyste mohli pracovat se vzdáleným SQL Serverem, který umožňuje integraci strojového učení a Pythonu. Po dokončení kroků v tomto článku budete mít stejné knihovny Pythonu jako ty na SQL Serveru. Budete také vědět, jak odesílat výpočty z místní relace Pythonu do vzdálené relace Pythonu na SQL Serveru.
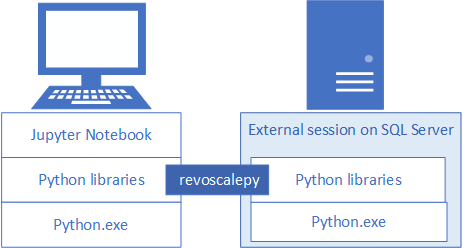
K ověření instalace můžete použít integrované poznámkové bloky Jupyter, jak je popsáno v tomto článku, nebo propojit knihovny s PyCharm nebo jiným integrovaným vývojovém prostředím, které běžně používáte.
Návod
Video s ukázkou těchto cvičení najdete v tématu Vzdálené spuštění R a Pythonu na SQL Serveru z poznámkových bloků Jupyter.
Běžně používané nástroje
Ať už jste vývojář Pythonu, který se seznamuje se SQL, nebo vývojář SQL, který začíná s Pythonem a analýzou v databázi, budete potřebovat jak vývojářský nástroj pro Python, tak editor dotazů T-SQL, jako je SQL Server Management Studio (SSMS), abyste mohli plně využít všechny možnosti analýzy v databázi.
Pro vývoj v Pythonu můžete použít poznámkové bloky Jupyter, které jsou součástí distribuce Anaconda nainstalované SQL Serverem. Tento článek vysvětluje, jak spustit poznámkové bloky Jupyter, abyste mohli kód Pythonu spouštět místně a vzdáleně na SQL Serveru.
SSMS je samostatný soubor ke stažení, který je užitečný pro vytváření a spouštění uložených procedur na SQL Serveru, včetně těch, které obsahují kód Pythonu. Téměř jakýkoli kód Pythonu, který píšete v poznámkových blocích Jupyter, lze vložit do uložené procedury. V dalších rychlých průvodcích se můžete seznámit s SSMS a vloženým Pythonem.
1. Instalace balíčků Pythonu
Místní pracovní stanice musí mít stejné verze balíčků Pythonu jako na SQL Serveru, včetně základní distribuce Anaconda 4.2.0 s distribucí Pythonu 3.5.2 a balíčků specifických pro Microsoft.
Instalační skript přidá do klienta Pythonu tři knihovny specifické pro Microsoft. Skript se nainstaluje:
- Revoscalepy slouží k definování objektů zdroje dat a výpočetního kontextu.
- Microsoftml poskytuje algoritmy strojového učení.
- Azureml se vztahuje na úlohy zprovoznění spojené s kontextem samostatného serveru a může být omezené pro analýzu v databázi.
Stáhněte instalační skript. Na příslušné následující stránce GitHubu vyberte Stáhnout nezpracovaný soubor.
Install-PyForMLS.ps1 nainstaluje balíčky Microsoft Pythonu verze 9.2.1. Tato verze odpovídá výchozí instanci SQL Serveru.
Install-PyForMLS.ps1 nainstaluje balíčky Microsoft Pythonu verze 9.3.
Otevřete okno PowerShellu se zvýšenými oprávněními správce (klikněte pravým tlačítkem na Spustit jako správce).
Přejděte do složky, ve které jste stáhli instalační program, a spusťte skript. Přidejte argument příkazového
-InstallFolderřádku pro zadání umístění složky pro knihovny. Například:cd {{download-directory}} .\Install-PyForMLS.ps1 -InstallFolder "C:\path-to-python-for-mls"
Pokud vynecháte instalační složku, výchozí hodnota je %ProgramFiles%\Microsoft\PyForMLS.
Dokončení instalace nějakou dobu trvá. Průběh můžete monitorovat v okně PowerShellu. Po dokončení instalace máte úplnou sadu balíčků.
Návod
Doporučujeme FAQ pro Python ve Windows pro obecné informace o spouštění programů Pythonu na Windows.
2. Vyhledání spustitelných souborů
V PowerShellu vypište obsah instalační složky a ověřte, že jsou nainstalované Python.exe, skripty a další balíčky.
Pro zadání přejděte na kořenový disk pomocí
cd \, a poté zadejte cestu, kterou jste specifikovali pro-InstallFolderv předchozím kroku. Pokud jste tento parametr během instalace vynechali, výchozí hodnota jecd %ProgramFiles%\Microsoft\PyForMLS.Zadejte
dir *.exe, abyste vypsali seznam spustitelných souborů. Měli byste vidět python.exe, pythonw.exea uninstall-anaconda.exe.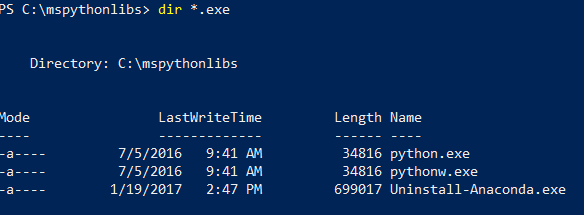
V systémech s více verzemi Pythonu nezapomeňte použít tento konkrétní Python.exe, pokud chcete načíst revoscalepy a další balíčky Microsoftu.
Poznámka:
Instalační skript neupravuje proměnnou prostředí PATH na vašem počítači, což znamená, že nový interpret Pythonu a moduly, které jste právě nainstalovali, nejsou automaticky dostupné pro jiné nástroje, které můžete mít. Nápovědu k propojení interpreta a knihoven Pythonu s nástroji najdete v tématu Instalace integrovaného vývojového prostředí (IDE).
3. Otevření poznámkových bloků Jupyter
Anaconda obsahuje poznámkové bloky Jupyter. V dalším kroku vytvořte poznámkový blok a spusťte kód Pythonu obsahující knihovny, které jste právě nainstalovali.
Na příkazovém řádku PowerShellu, který je stále ve složce
%ProgramFiles%\Microsoft\PyForMLS, otevřete Jupyter Notebooky ze složky Scripts..\Scripts\jupyter-notebookNotebook by se měl otevřít ve výchozím prohlížeči na adrese
https://localhost:8889/tree.Dalším způsobem, jak začít, je dvakrát kliknout jupyter-notebook.exe.
Vyberte Nový a pak vyberte Python 3.
Zadejte a spusťte
import revoscalepypříkaz, který načte jednu z knihoven specifických pro Microsoft.Zadáním a spuštěním
print(revoscalepy.__version__)vrátíte informace o verzi. Měla by se zobrazit verze 9.2.1 nebo 9.3.0. Na serveru můžete použít některou z těchto verzí s revoscalepy.Zadejte složitější řadu příkazů. Tento příklad generuje souhrnné statistiky pomocí rx_summary přes místní datovou sadu. Další funkce získají umístění ukázkových dat a vytvoří objekt zdroje dat pro místní soubor .xdf.
import os from revoscalepy import rx_summary from revoscalepy import RxXdfData from revoscalepy import RxOptions sample_data_path = RxOptions.get_option("sampleDataDir") print(sample_data_path) ds = RxXdfData(os.path.join(sample_data_path, "AirlineDemoSmall.xdf")) summary = rx_summary("ArrDelay+DayOfWeek", ds) print(summary)
Následující snímek obrazovky ukazuje vstup a část výstupu oříznutou pro stručnost.

4. Získání oprávnění SQL
Pokud se chcete připojit k instanci SQL Serveru, aby bylo možné spouštět skripty a nahrávat data, musíte mít na databázovém serveru platné přihlášení. Můžete použít přihlášení SQL nebo integrované ověřování systému Windows. Obecně doporučujeme používat integrované ověřování systému Windows, ale použití přihlášení SQL je pro některé scénáře jednodušší, zejména pokud váš skript obsahuje připojovací řetězce k externím datům.
Minimálně účet použitý ke spuštění kódu musí mít oprávnění ke čtení z databází, se kterými pracujete, a navíc speciální oprávnění SPUSTIT LIBOVOLNÝ EXTERNÍ SKRIPT. Většina vývojářů také vyžaduje oprávnění k vytváření uložených procedur a k zápisu dat do tabulek obsahujících trénovací data nebo vyhodnocená data.
Požádejte správce databáze, aby v databázi, ve které používáte Python, nakonfigurovali následující oprávnění pro váš účet:
- SPUŠTĚNÍM LIBOVOLNÉHO EXTERNÍHO SKRIPTU spusťte Python na serveru.
- db_datareader oprávnění ke spouštění dotazů používaných pro trénování modelu.
- db_datawriter pro zápis trénovacích dat nebo ohodnocených dat.
- db_owner vytvářet objekty, jako jsou uložené procedury, tabulky, funkce. K vytvoření ukázkových a testovacích databází potřebujete také db_owner .
Pokud váš kód vyžaduje balíčky, které nejsou ve výchozím nastavení nainstalovány s SQL Serverem, uspořádejte s správcem databáze, aby byly balíčky nainstalovány s instancí. SQL Server je zabezpečené prostředí a existují omezení, kde lze balíčky nainstalovat. Ad hoc instalace balíčků v rámci kódu se nedoporučuje, i když máte práva. Před instalací nových balíčků v knihovně serverů také vždy pečlivě zvažte důsledky zabezpečení.
5. Vytvoření testovacích dat
Pokud máte oprávnění k vytvoření databáze na vzdáleném serveru, můžete spustit následující kód a vytvořit ukázkovou databázi Iris použitou pro zbývající kroky v tomto článku.
5-1 – Vzdálené vytvoření databáze irissql
from mssql_python import connect
# creating a new db to load Iris sample in
new_db_name = "irissql"
connection_string = "Server=localhost;Database={0};Trusted_Connection=Yes;"
# you can also swap Trusted_Connection for UID={your username};PWD={your password}
conn = connect(connection_string.format("master"))
conn.setautocommit(True)
conn.cursor().execute("IF EXISTS(SELECT * FROM sys.databases WHERE [name] = '{0}') DROP DATABASE {0}".format(new_db_name))
conn.cursor().execute("CREATE DATABASE " + new_db_name)
conn.close()
print("Database created")
5-2 – Import vzorku Iris ze SkLearnu
from sklearn import datasets
import pandas as pd
# SkLearn has the Iris sample dataset built in to the package
iris = datasets.load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
5–3– Použití rozhraní Revoscalepy API k vytvoření tabulky a načtení dat Iris
from revoscalepy import RxSqlServerData, rx_data_step
# Example of using RX APIs to load data into SQL table. You can also do this with mssql-python
table_ref = RxSqlServerData(connection_string=connection_string.format(new_db_name), table="iris_data")
rx_data_step(input_data = df, output_file = table_ref, overwrite = True)
print("New Table Created: Iris")
print("Sklearn Iris sample loaded into Iris table")
6. Testování vzdáleného připojení
Než se pokusíte provést tento další krok, ujistěte se, že máte oprávnění k instanci SQL Serveru a řetězec připojení k ukázkové databázi Iris. Pokud databáze neexistuje a máte dostatečná oprávnění, můžete vytvořit databázi pomocí těchto vložených pokynů.
Nahraďte připojovací řetězec platnými hodnotami. Vzorový kód používá "Server=localhost;Database=irissql;Trusted_Connection=Yes;", ale váš kód by měl určit vzdálený server, pravděpodobně s názvem instance, a možnost zadání přihlašovacích údajů, která mapuje na přihlášení k databázi.
6-1 Definování funkce
Následující kód definuje funkci, kterou odešlete na SQL Server v pozdějším kroku. Při spuštění používá data a knihovny (revoscalepy, pandas, matplotlib) na vzdáleném serveru k vytvoření bodových grafů datové sady iris. Vrátí stream bajtů formátu .png zpět do poznámkových bloků Jupyter pro vykreslení v prohlížeči.
def send_this_func_to_sql():
from revoscalepy import RxSqlServerData, rx_import
from pandas.tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
import io
# remember the scope of the variables in this func are within our SQL Server Python Runtime
connection_string = "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;"
# specify a query and load into pandas dataframe df
sql_query = RxSqlServerData(connection_string=connection_string, sql_query = "select * from iris_data")
df = rx_import(sql_query)
scatter_matrix(df)
# return bytestream of image created by scatter_matrix
buf = io.BytesIO()
plt.savefig(buf, format="png")
buf.seek(0)
return buf.getvalue()
6–2 Odeslání funkce na SQL Server
V tomto příkladu vytvořte vzdálený výpočetní kontext a pak odešlete spuštění funkce na SQL Server s rx_exec. Funkce rx_exec je užitečná, protože přijímá výpočetní kontext jako argument. Každá funkce, kterou chcete spustit vzdáleně, musí mít argument výpočetního kontextu. Některé funkce, například rx_lin_mod podporují tento argument přímo. Pro operace, které ne, můžete použít rx_exec k doručení kódu ve vzdáleném výpočetním kontextu.
V tomto příkladu se žádná nezpracovaná data nemusela přenášet z SQL Serveru do poznámkového bloku Jupyter. Všechny výpočty probíhají v databázi Iris a klientovi se vrátí pouze soubor image.
from IPython import display
import matplotlib.pyplot as plt
from revoscalepy import RxInSqlServer, rx_exec
# create a remote compute context with connection to SQL Server
sql_compute_context = RxInSqlServer(connection_string=connection_string.format(new_db_name))
# use rx_exec to send the function execution to SQL Server
image = rx_exec(send_this_func_to_sql, compute_context=sql_compute_context)[0]
# only an image was returned to my jupyter client. All data remained secure and was manipulated in my db.
display.Image(data=image)
Následující snímek obrazovky ukazuje vstup a výstup bodového grafu.

7. Spuštění Pythonu z nástrojů
Vzhledem k tomu, že vývojáři často pracují s více verzemi Pythonu, instalační program nepřidá Python do cesty PATH. Pokud chcete použít spustitelný soubor Pythonu a knihovny nainstalované nastavením, propojte integrované vývojové prostředí (IDE ) aPython.exe v cestě, která také poskytuje revoscalepy a microsoftml.
Příkazový řádek
Když spustíte Python.exe z %ProgramFiles%\Microsoft\PyForMLS (nebo z libovolného umístění, které jste zadali pro instalaci klientské knihovny Pythonu), budete mít přístup k úplné distribuci Anaconda a k modulům Microsoft Pythonu, revoscalepy a microsoftml.
- Přejděte na
%ProgramFiles%\Microsoft\PyForMLSa spusťte Python.exe. - Otevřete interaktivní nápovědu:
help(). - Na příkazovém řádku nápovědy zadejte název modulu:
help> revoscalepy. Nápověda vrátí název, obsah balíčku, verzi a umístění souboru. - Vraťte informace o verzi a balíčku ve výzvě nápovědy>:
revoscalepy. Několikrát stiskněte klávesu Enter pro ukončení nápovědy. - Import modulu:
import revoscalepy.
Poznámkové bloky Jupyter
Tento článek používá integrované poznámkové bloky Jupyter k předvedení volání funkcí pro revoscalepy. Pokud s tímto nástrojem teprve začínáte, následující snímek obrazovky ukazuje, jak se jednotlivé části vejdou dohromady a proč to všechno funguje.
Nadřazená složka %ProgramFiles%\Microsoft\PyForMLS obsahuje Anaconda a balíčky Microsoftu. Poznámkové bloky Jupyter jsou součástí Anaconda ve složce Scripts a spustitelné soubory Pythonu se automaticky zaregistrují s poznámkovými bloky Jupyter. Balíčky nalezené v rámci balíčků webu je možné importovat do poznámkového bloku, včetně tří balíčků Microsoftu používaných pro datové vědy a strojové učení.
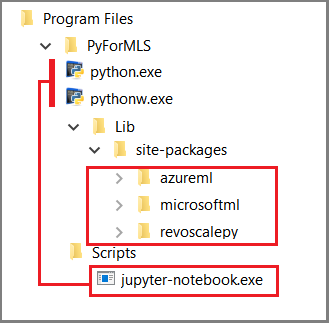
Pokud používáte jiné integrované vývojové prostředí (IDE), budete muset ke svému nástroji propojit spustitelné soubory Pythonu a knihovny funkcí. Následující části obsahují pokyny pro běžně používané nástroje.
Visual Studio
Pokud máte Python v sadě Visual Studio, pomocí následujících možností konfigurace vytvořte prostředí Pythonu, které obsahuje balíčky Microsoft Pythonu.
| Nastavení konfigurace | value |
|---|---|
| Cesta předpony | %ProgramFiles%\Microsoft\PyForMLS |
| Cesta interpreta | %ProgramFiles%\Microsoft\PyForMLS\python.exe |
| Okénkový interpret | %ProgramFiles%\Microsoft\PyForMLS\pythonw.exe |
Nápovědu ke konfiguraci prostředí Pythonu najdete v tématu Správa prostředí Pythonu v sadě Visual Studio.
PyCharm
V PyCharm nastavte interpret na nainstalovaný spustitelný soubor Pythonu.
V novém projektu v Nastavení vyberte Přidat místní.
Zadejte
%ProgramFiles%\Microsoft\PyForMLS\.
Teď můžete importovat moduly revoscalepy, microsoftml nebo azureml . Můžete také zvolit Nástroje>Python konzole a otevřít interaktivní okno.