Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Platí na:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytický platformový systém (PDW)
Analytický platformový systém (PDW)![]() SQL databáze v Microsoft Fabric
SQL databáze v Microsoft Fabric
Možnosti a doporučení pro načítání dat do indexu columnstore pomocí standardních SQL metod hromadného načítání a metod postupného vkládání. Načtení dat do indexu columnstore je důležitou součástí jakéhokoli procesu datového skladu, protože přesouvá data do indexu při přípravě na analýzu.
Začínáte s columnstore indexy? Viz indexy Columnstore – přehled a architektura indexu Columnstore.
Co je hromadné načítání?
Hromadné vkládání se týká způsobu, jakým je velký počet řádků přidáván do datového úložiště. Nejvýkonnější způsob, jak přesunout data do columnstore indexu, protože zpracovává dávky řádků. Hromadné načítání vyplní skupiny řádků do maximální kapacity a zkomprimuje je přímo do sloupcového úložiště. Pouze řádky na konci nahrání, které nesplňují minimální počet 102 400 řádků na řádkovou skupinu, přejdou do deltastore.
K hromadnému načtení můžete použít nástroj bcp, integrační služby nebo vybrat řádky z pracovní tabulky.
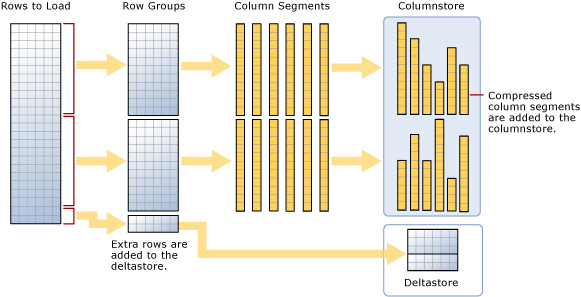
Jak napovídá diagram, hromadné nahrání:
- Nepředřazuje data. Data se vloží do skupin řádků v pořadí, v jakém jsou přijatá.
- Pokud je > velikost dávky rovna 102400, řádky se přímo načtou do komprimovaných skupin řádků. Pro efektivní hromadný import byste měli zvolit velikost dávky >=102400, protože tím můžete předcházet přesunu řádků dat do delta skupin řádků předtím, než jsou řádky nakonec přesunuty pomocí vlákna na pozadí a tuple mover (TM) do komprimovaných skupin řádků.
- Pokud je velikost < dávky 102 400 nebo pokud jsou zbývající řádky < 102 400, řádky se načtou do rozdílových skupin řádků.
Note
V tabulce typu rowstore s neclusterovaným indexem columnstore SQL Server vždy vkládá data do základní tabulky. Data se nikdy nevkládají přímo do indexu columnstore.
Hromadné načítání obsahuje tyto integrované optimalizace výkonu:
Paralelní načtení: Můžete mít několik souběžných hromadných načítání (bcp nebo hromadné vložení), které každý načítá samostatný datový soubor. Na rozdíl od hromadného načítání do SQL Serveru v režimu řádkového úložiště nemusíte zadávat
TABLOCK, protože každé vlákno při hromadném importu výhradně načítá data do samostatných skupin řádků (komprimovaných nebo rozdílových) s výhradním zámkem.Omezené protokolování: Data, která jsou přímo načtena do komprimovaných skupin řádků, vedou k významnému snížení velikosti protokolu. Například pokud byla data komprimována 10x, odpovídající transakční protokol je přibližně 10x menší, aniž by bylo nutné
TABLOCKnebo hromadně protokolovaný/jednoduchý model obnovení. Všechna data, která přejdou do delta řádkové skupiny, jsou plně zaznamenaná. To zahrnuje všechny velikosti dávek, které jsou menší než 102 400 řádků. Osvědčeným postupem je použít dávku >= 102400. Vzhledem k tomu, že neníTABLOCKpotřeba, můžete data načíst paralelně.Minimální protokolování: Pokud dodržujete požadavky na minimální protokolování, můžete protokolování dále snížit. Na rozdíl od načítání dat do rowstore,
TABLOCKvede kX(výhradnímu) zámku na tabulce místoBUzámku (hromadná aktualizace), proto nelze provádět paralelní načítání dat. Další informace o uzamčení naleznete v tématu Uzamčení a správa verzí řádků.Optimalizace uzamčení: Zámek
Xskupiny řádků se automaticky získá při načítání dat do komprimované skupiny řádků. Při hromadném načítání do rozdílové skupiny řádků se získá zámek pro skupinu řádků, ale databázový stroj stále využívá zámky stránek a rozsahů, protože zámek skupiny řádků není součástí hierarchie zámků.
Pokud máte neklastrový index B-stromu na index úložiště sloupců, neexistuje žádná optimalizace uzamčení ani protokolování pro samotný index, ale optimalizace na klastrový index úložiště sloupců, jak je popsáno výše, jsou použitelné.
Plánování velikostí hromadného načítání pro minimalizaci delta skupin řádků
Indexy columnstore fungují nejlépe, když je většina řádků komprimovaná do columnstore a nesedí v rozdílových řádkových skupinách. Nejlepší je optimalizovat velikost zatížení tak, aby řádky přešly přímo do columnstore a co nejvíce obešly deltastore.
Tyto scénáře popisují, kdy načtené řádky přecházejí přímo do columnstore nebo kdy přecházejí do deltastore. V příkladu může mít každá skupina řádků 102 400–1 048 576 řádků na skupinu řádků. V praxi může být maximální velikost skupiny řádků menší než 1 048 576 řádků, pokud je zatížení paměti.
| Řádky k hromadnému nahrání | Řádky přidané do komprimované skupiny řádků | Řádky přidané do delta skupiny řádků |
|---|---|---|
| 102,000 | 0 | 102,000 |
| 145,000 | 145,000 Velikost skupiny řádků: 145 000 |
0 |
| 1,048,577 | 1,048,576 Velikost skupiny řádků: 1 048 576. |
1 |
| 2,252,152 | 2,252,152 Velikosti skupin řádků: 1 048 576, 1 048 576, 155 000. |
0 |
Následující příklad ukazuje výsledky načtení 1 048 577 řádků do tabulky. Výsledky ukazují, že je jedna komprimovaná skupina řádků ve sloupcovém úložišti (jako komprimované segmenty sloupců) a jeden řádek v deltovém úložišti.
SELECT object_id, index_id, partition_number, row_group_id, delta_store_hobt_id,
state, state_desc, total_rows, deleted_rows, size_in_bytes
FROM sys.dm_db_column_store_row_group_physical_stats;

Zvýšení výkonu pomocí pracovní tabulky
Pokud načítáte data pouze pro přípravu před spuštěním dalších transformací, je načtení do haldy mnohem rychlejší než načtení dat do clusterové tabulky columnstore. Kromě toho se načítání dat do [dočasné tabulky][Dočasné] také načte mnohem rychleji než načtení tabulky do trvalého úložiště.
Běžným vzorem pro načtení dat je načtení dat do pracovní tabulky, provedení určité transformace a následné načtení do cílové tabulky pomocí následujícího příkazu:
INSERT INTO [<columnstore index>]
SELECT col1 /* include actual list of columns in place of col1*/
FROM [<Staging Table>]
Tento příkaz načítá data do sloupcového indexu podobným způsobem jako bcp nebo hromadná vložka, ale v jedné dávce. Pokud počet řádků v přechodové tabulce < 102400, řádky se načtou do delta skupiny řádků, jinak se přímo načtou do komprimované skupiny řádků. Jedním z klíčových omezení bylo, že tato INSERT operace byla jednovláknová. Pokud chcete načíst data paralelně, můžete vytvořit několik pracovních tabulek nebo problém INSERT/SELECT s nepřekrývajícími se rozsahy řádků z pracovní tabulky. Toto omezení zmizí s SQL Serverem 2016 (13.x). Následující příkaz načte data z předběžné tabulky paralelně, ale musíte zadat TABLOCK. Může se vám zdát, že to je v rozporu s tím, co bylo řečeno dříve ohledně hromadného načítání, ale klíčovým rozdílem je, že paralelní načítání dat z pracovní tabulky je prováděno ve stejné transakci.
INSERT INTO [<columnstore index>] WITH (TABLOCK)
SELECT col1 /* include actual list of columns in place of col1*/
FROM [<Staging Table>]
Při načítání do clusterovaného indexu columnstore z přípravné tabulky jsou k dispozici následující optimalizace:
- Optimalizace protokolů: Omezené protokolování při načtení dat do komprimované skupiny řádků.
-
Optimalizace uzamčení: Při načítání dat do komprimované skupiny
Xřádků se získá zámek skupiny řádků. Při hromadném načítání do rozdílové skupiny řádků se získá zámek pro skupinu řádků, ale databázový stroj stále využívá zámky stránek a rozsahů, protože zámek skupiny řádků není součástí hierarchie zámků.
Pokud máte jeden nebo více neklastrovaných indexů, neexistuje žádná optimalizace zamykání ani protokolování pro samotný index, ale optimalizace u clusterovaného columnstore indexu popsané výše stále platí.
Co je průběžné vložení?
Trickle insert odkazuje na způsob, jak se jednotlivé řádky vkládají do columnstore indexu. Trikle inserts používá příkaz INSERT INTO . U trickle insert se všechny řádky dostanou do deltastore. To je užitečné pro malý počet řádků, ale není praktické pro velké zatížení.
INSERT INTO [<table-name>] VALUES ('some value' /*replace with actual set of values*/)
Note
Souběžná vlákna využívající insert INTO k vložení hodnot do clusterovaného indexu columnstore mohou vkládat řádky do stejné skupiny řádků deltastore.
Jakmile skupina řádků obsahuje 1 048 576 řádků, skupina řádků delta je označená jako uzavřená, ale stále je k dispozici pro dotazy a operace aktualizace/odstranění, ale nově vložené řádky přejdou do existující nebo nově vytvořené skupiny řádků deltastore. Existuje vlákno na pozadí označované jako přesunovač tuply (TM), které komprimuje uzavřená delta řádková skupiny pravidelně každých 5 minut nebo tak. Můžete explicitně vyvolat následující příkaz, který zkomprimuje uzavřenou delta rowgroup.
ALTER INDEX [<index-name>] on [<table-name>] REORGANIZE
Pokud chcete vynutit zavřenou a komprimovanou skupinu řádků delta, můžete spustit následující příkaz. Tento příkaz můžete spustit, pokud jste dokončili načítání řádků a neočekáváte žádné nové řádky. Když explicitně uzavřete a zkomprimujete rozdílovou řádkovou skupinu, můžete ušetřit více úložného prostoru a zlepšit výkon analytických dotazů. Osvědčeným postupem je vyvolat tento příkaz, pokud neočekáváte, že se vloží nové řádky.
ALTER INDEX [<index-name>] on [<table-name>] REORGANIZE with (COMPRESS_ALL_ROW_GROUPS = ON)
Jak funguje načítání do rozdělené tabulky
U dělených dat databázový stroj nejprve přiřadí každý řádek k oddílu a potom provede operace columnstore s daty v rámci oddílu. Každý oddíl má vlastní skupiny řádků a alespoň jednu delta skupinu řádků.