Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Platí pro:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Spravovaná instance
Spravovaná instance![]() Azure SQLDatabáze SQL v Microsoft Fabric
Azure SQLDatabáze SQL v Microsoft Fabric
Databázový stroj SQL Serveru zpracovává dotazy na různé architektury úložiště dat, jako jsou místní tabulky, dělené tabulky a tabulky distribuované napříč několika servery. Následující části obsahují informace o tom, jak SQL Server zpracovává dotazy a optimalizuje opakované použití dotazů prostřednictvím ukládání do mezipaměti plánu provádění.
Režimy provádění
Databázový stroj SQL Serveru může zpracovávat příkazy Transact-SQL pomocí dvou různých režimů zpracování:
- Výkon režimu řádku
- Spouštění v dávkovém režimu
Výkon režimu řádku
Provádění režimu řádků je metoda zpracování dotazů používaná u tradičních tabulek RDBMS, kde jsou data uložená ve formátu řádku. Při spuštění dotazu, který přistupuje k datům v tabulkách s řádkovým uložením, operátory stromu vykonávání a podřízené operátory čtou každý potřebný řádek napříč všemi sloupci určenými schématem tabulky. Z každého řádku, který je přečtený, SQL Server pak načte sloupce požadované pro sadu výsledků, jak odkazuje příkaz SELECT, predikát JOIN nebo predikát filtru.
Poznámka:
Provádění režimu řádků je velmi efektivní pro scénáře OLTP, ale může být méně efektivní při skenování velkých objemů dat, například ve scénářích datového skladu.
Spouštění v dávkovém režimu
Provedení dávkového režimu je metoda zpracování dotazů, která se používá ke zpracování více řádků dohromady (odtud termín dávka). Každý sloupec v dávce je uložen jako vektor v samostatné oblasti paměti, takže zpracování dávkovým způsobem je vektorové. Zpracování dávkového režimu používá také algoritmy optimalizované pro procesory s více jádry a zvýšenou propustnost paměti, které se nacházejí na moderním hardwaru.
Při svém prvním zavedení bylo provádění dávkového režimu úzce integrováno s formátem úložiště columnstore a kolem něj také optimalizováno. Od verze SQL Server 2019 (15.x) a ve službě Azure SQL Database však spouštění dávkového režimu už nevyžaduje indexy columnstore. Další informace najdete v dávkovém režimu na úložišti řádků.
Zpracování v dávkovém režimu funguje na komprimovaných datech, pokud je to možné, a eliminuje operátor výměny používaný při provedení v režimu řádku. Výsledkem je lepší paralelismus a rychlejší výkon.
Když se dotaz spustí v dávkovém režimu a přistupuje k datům ve sloupcových indexech, operátory stromu vykonávání a podřízené operátory načtou více řádků společně ve sloupcových segmentech. SQL Server čte pouze sloupce požadované pro výsledek, jak odkazuje příkaz SELECT, predikát JOIN nebo predikát filtru. Další informace o indexech columnstore najdete v tématu Architektura indexu columnstore.
Poznámka:
Spouštění v dávkovém režimu je velmi efektivní ve scénářích pro datové sklady, kde se čtou a agregují velké objemy dat.
Zpracování příkazů SQL
Zpracování jednoho příkazu Transact-SQL je nejzásadnější způsob, jakým SQL Server spouští příkazy Transact-SQL. Kroky použité ke zpracování jednoho SELECT příkazu, který odkazuje pouze na místní základní tabulky (bez zobrazení nebo vzdálených tabulek), znázorňuje základní proces.
Priorita logického operátoru
Pokud se v příkazu použije více než jeden logický operátor, NOT vyhodnotí se nejprve, pak ANDa nakonec OR. Aritmetické a bitové operátory se zpracovávají před logickými operátory. Další informace naleznete v tématu Priorita operátoru.
V následujícím příkladu se podmínka barvy týká produktového modelu 21, a ne modelu 20, protože AND má přednost před OR.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR ProductModelID = 21
AND Color = 'Red';
GO
Význam dotazu můžete změnit přidáním závorek k vynucení vyhodnocení OR jako prvního. Následující dotaz najde pouze produkty v modelech 20 a 21, které jsou červené.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE (ProductModelID = 20 OR ProductModelID = 21)
AND Color = 'Red';
GO
Použití závorek, i když nejsou povinné, může zlepšit čitelnost dotazů a snížit riziko drobné chyby kvůli přednosti operátoru. Při používání závorek neexistuje žádné významné snížení výkonu. Následující příklad je čitelnější než původní příklad, i když jsou syntakticky stejné.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR (ProductModelID = 21
AND Color = 'Red');
GO
Optimalizace příkazů SELECT
Příkaz SELECT není procedurální. Neuvádí přesné kroky, které by databázový server měl použít k načtení požadovaných dat. To znamená, že databázový server musí analyzovat příkaz, aby určil nejúčinnější způsob, jak extrahovat požadovaná data. To se označuje jako optimalizace SELECT příkazu. Komponenta, která to dělá, se nazývá Query Optimizer. Vstup optimalizátoru dotazů se skládá z dotazu, schématu databáze (definice tabulek a indexů) a statistiky databáze. Výstupem optimalizátoru dotazů je plán provádění dotazů, někdy označovaný jako plán dotazu nebo plán provádění. Obsah plánu provádění je podrobněji popsán dále v tomto článku.
Vstupy a výstupy optimalizátoru dotazů během optimalizace jednoho SELECT příkazu jsou znázorněny v následujícím diagramu:
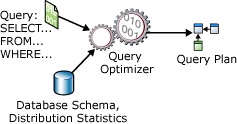
Příkaz SELECT definuje pouze následující:
- Formát sady výsledků To je určeno většinou ve výběrovém seznamu. Jiné klauzule, například
ORDER BYaGROUP BYtaké ovlivňují konečnou formu sady výsledků. - Tabulky, které obsahují zdrojová data. Toto je určeno v klauzuli
FROM. - Jak tabulky logicky souvisejí pro účely
SELECTpříkazu. Toto je definováno ve specifikacích spojení, které se mohou objevit v klauzuliWHEREnebo v klauzuliON, která následuje poFROM. - Podmínky, které musí řádky ve zdrojových tabulkách splňovat, aby se kvalifikoval pro
SELECTpříkaz. Ty jsou uvedené vWHEREklauzulích aHAVINGklauzulích.
Plán provádění dotazů je definice následujících:
Posloupnost, ve které jsou zdrojové tabulky přístupné.
Obvykle existuje mnoho sekvencí, ve kterých může databázový server přistupovat k základním tabulkám pro sestavení sady výsledků. Pokud napříkladSELECTpříkaz odkazuje na tři tabulky, databázový server by mohl nejprve získat přístupTableA, použít data zTableAk extrahování odpovídajících řádků zTableB, a pak použít data zTableBk extrahování dat zTableC. Další sekvence, ve kterých má databázový server přístup k tabulkám, jsou:
TableC,TableB,TableAnebo
TableB,TableA,TableCnebo
TableB,TableC,TableAnebo
TableC,TableA,TableBMetody použité k extrakci dat z každé tabulky.
Obecně platí, že pro přístup k datům v každé tabulce existují různé metody. Pokud se vyžaduje jenom několik řádků s konkrétními hodnotami klíče, může databázový server použít index. Pokud jsou požadovány všechny řádky v tabulce, databázový server může indexy ignorovat a provést kontrolu tabulky. Pokud jsou požadovány všechny řádky v tabulce, ale existuje index, jehož klíčové sloupce jsou v tabulceORDER BY, může provádění prohledávání indexu místo prohledávání tabulky uložit samostatné řazení sady výsledků. Pokud je tabulka velmi malá, může být prohledávání tabulek nejúčinnější metodou téměř veškerého přístupu k tabulce.Metody používané k výpočtům a způsob filtrování, agregace a řazení dat z každé tabulky.
Při přístupu k datům z tabulek existují různé metody pro výpočty dat, jako jsou výpočty skalárních hodnot, a agregace a řazení dat definovaných v textu dotazu, například při použití klauzuleGROUP BYneboORDER BYa filtrování dat, například při použití klauzuleWHEREneboHAVING.
Proces výběru jednoho plánu provádění z potenciálně mnoha možných plánů se označuje jako optimalizace. Optimalizátor dotazů je jednou z nejdůležitějších součástí databázového stroje. I když optimalizátor dotazů používá určitou režii na analýzu dotazu a výběr plánu provádění, tato režie se obvykle několikanásobně vrátí, když optimalizátor dotazů vybere efektivní plán provádění. Například dvě stavební společnosti mohou dostat identické projektové plány pro dům. Pokud jedna společnost stráví několik dní na začátku plánováním toho, jak dům sestaví, a druhá společnost začne stavět bez plánování, společnost, která potřebuje čas na naplánování projektu, se pravděpodobně dokončí jako první.
Optimalizátor dotazů SQL Serveru je optimalizátor založený na nákladech. Každý možný plán provádění má přidružené náklady z hlediska množství použitých výpočetních prostředků. Optimalizátor dotazů musí analyzovat možné plány a zvolit plán s nejnižšími odhadovanými náklady. Některé složité SELECT příkazy mají tisíce možných plánů provádění. V těchto případech optimalizátor dotazů neanalyzuje všechny možné kombinace. Místo toho používá složité algoritmy k vyhledání plánu provádění, který má náklady přiměřeně blízko minimální možné náklady.
Optimalizátor dotazů SQL Serveru nevybírej pouze plán provádění s nejnižšími náklady na prostředky; zvolí plán, který uživateli vrátí výsledky s rozumnými náklady v prostředcích a vrátí výsledky nejrychleji. Například paralelní zpracování dotazu obvykle používá více prostředků než jeho sériové zpracování, ale dokončí dotaz rychleji. Optimalizátor dotazů SQL Serveru použije plán paralelního spuštění k vrácení výsledků, pokud zatížení serveru nebude nepříznivě ovlivněno.
Optimalizátor dotazů SQL Serveru spoléhá na distribuční statistiku, když odhaduje náklady na prostředky různých metod pro extrakci informací z tabulky nebo indexu. Statistiky distribuce se uchovávají pro sloupce a indexy a uchovávají informace o hustotě1 podkladových dat. Slouží k označení selektivity hodnot v určitém indexu nebo sloupci. Například v tabulce představující auta má mnoho automobilů stejný výrobce, ale každé auto má jedinečné identifikační číslo vozidla (VIN). Index na VIN je selektivnější než index na výrobce, protože VIN má nižší hustotu než výrobce. Pokud statistiky indexu nejsou aktuální, optimalizátor dotazů nemusí být pro aktuální stav tabulky nejvhodnější volbou. Další informace o hustotách najdete v tématu Statistika.
1 Hustota definuje rozdělení jedinečných hodnot, které existují v datech, nebo průměrný počet duplicitních hodnot pro daný sloupec. S poklesem hustoty se selektivita hodnoty zvyšuje.
Optimalizátor dotazů SQL Serveru je důležitý, protože umožňuje databázovému serveru dynamicky upravovat měnící se podmínky v databázi, aniž by vyžadoval vstup od programátora nebo správce databáze. Programátoři se tak mohou zaměřit na popis konečného výsledku dotazu. Můžou důvěřovat tomu, že optimalizátor dotazů SQL Serveru sestaví efektivní plán provádění pro stav databáze při každém spuštění příkazu.
Poznámka:
SQL Server Management Studio má tři možnosti zobrazení plánů provádění:
- Odhadovaný plán provádění, což je zkompilovaný plán vytvořený optimalizátorem dotazů.
- Skutečný plán provádění, který je stejný jako zkompilovaný plán a jeho kontext spuštění. To zahrnuje informace o době běhu, které jsou k dispozici po dokončení provádění, jako jsou varování při provádění nebo v novějších verzích databázového stroje, doba a procesorový čas využitý během provádění.
- Statistika živého dotazu, která je stejná jako zkompilovaný plán a kontext spuštění. To zahrnuje informace o běhu programu během průběhu provádění a aktualizuje se každou sekundu. Informace o modulu runtime zahrnují například skutečný počet řádků procházejících operátory.
Zpracování příkazu SELECT
Základní kroky, které SQL Server používá ke zpracování jednoho příkazu SELECT, zahrnují následující:
- Analyzátor prohledá příkaz a rozdělí
SELECTho do logických jednotek, jako jsou klíčová slova, výrazy, operátory a identifikátory. - Strom dotazu, který se někdy označuje jako sekvenční strom, je sestavený s popisem logických kroků potřebných k transformaci zdrojových dat do formátu požadovaného sadou výsledků.
- Optimalizátor dotazů analyzuje různé způsoby přístupu ke zdrojovým tabulkám. Pak vybere řadu kroků, které vrací výsledky nejrychleji a současně používají méně prostředků. Strom dotazu se aktualizuje, aby zaznamenal tuto přesnou řadu kroků. Konečná optimalizovaná verze stromu dotazů se nazývá plán provádění.
- Relační modul spustí plán provádění. Jak se zpracovávají kroky, které vyžadují data ze základních tabulek, relační modul požaduje, aby modul úložiště předal data ze sad řádků požadovaných z relačního modulu.
- Relační modul zpracuje data vrácená z modulu úložiště do formátu definovaného pro sadu výsledků a vrátí sadu výsledků klientovi.
Skládání konstant a vyhodnocování výrazů
SQL Server vyhodnocuje některé konstantní výrazy brzy za účelem zlepšení výkonu dotazů. Cílem této techniky optimalizace, kterou používá optimalizátor dotazů, je zjednodušit výrazy v době kompilace, nikoli za běhu. Zahrnuje vyhodnocení konstantních výrazů během kompilace dotazu, aby výsledný plán provádění byl efektivnější. To se označuje jako konstantní skládání. Konstanta je Transact-SQL literál, například 3, 'ABC', '2005-12-31', 1.0e3nebo 0x12345678. Podívejte se například na tento dotaz:
SELECT * FROM Orders WHERE OrderDate < DATEADD(day, 30 * 12, '2020-01-01');
Zde 30 * 12 je konstantní výraz. SQL Server to může vyhodnotit během kompilace a interně přepsat dotaz jako:
SELECT * FROM Orders WHERE OrderDate < DATEADD(day, 360, '2020-01-01');
Skládací výrazové konstrukty
SQL Server používá konstantní posouvání s následujícími typy výrazů:
- Aritmetické výrazy, například
1 + 1a5 / 3 * 2, které obsahují pouze konstanty. - Logické výrazy, například
1 = 1a1 > 2 AND 3 > 4, které obsahují pouze konstanty. - Vestavěné funkce, které jsou považovány za hodnotitelné SQL Serverem, včetně
CASTaCONVERT. Vnitřní funkce je obecně skládací, pokud se jedná o funkci pouze jejích vstupů, a ne jiné kontextové informace, jako jsou možnosti SET, nastavení jazyka, možnosti databáze a šifrovací klíče. Nedeterministické funkce nejsou skládací. Deterministické předdefinované funkce jsou skládací, s některými výjimkami. - Deterministické metody uživatelem definovaných typů CLR a deterministické skalární funkce definované uživatelem CLR (počínaje SQL Serverem 2012 (11.x)). Další informace naleznete v tématu Konstantní posouvání pro CLR User-Defined Funkce a metody.
Poznámka:
Pro velké typy objektů se vytvoří výjimka. Pokud je výstupním typem skládacího procesu velký typ objektu (text,ntext, obrázek, nvarchar(max), varchar(max), varbinary(max) nebo XML), sql Server výraz nepřeloží.
Výrazy, které nelze zjednodušit
Všechny ostatní typy výrazů nejsou skládací. Zejména následující typy výrazů nejsou skládací:
- Nekonstantní výrazy, jako je výraz, jehož výsledek závisí na hodnotě sloupce.
- Výrazy, jejichž výsledky závisí na místní proměnné nebo parametru, například @x.
- Nedeterministické funkce.
- Uživatelem definované Transact-SQL funkce1.
- Výrazy, jejichž výsledky závisí na nastavení jazyka.
- Výrazy, jejichž výsledky závisí na možnostech SET.
- Výrazy, jejichž výsledky závisí na možnostech konfigurace serveru.
1 Před SQL Serverem 2012 (11.x) nebyly deterministické skalární funkce a metody uživatelem definovaných typů CLR skládány.
Příklady skládacích a nepřesunutelných konstantních výrazů
Představte si následující dotaz:
SELECT *
FROM Sales.SalesOrderHeader AS s
INNER JOIN Sales.SalesOrderDetail AS d
ON s.SalesOrderID = d.SalesOrderID
WHERE TotalDue > 117.00 + 1000.00;
Pokud pro tento dotaz není nastavená PARAMETERIZATIONFORCED možnost databáze, výraz 117.00 + 1000.00 se vyhodnotí a nahradí jeho výsledkem, 1117.00před kompilací dotazu. Mezi výhody tohoto skládání konstant patří:
- Výraz se nemusí opakovaně vyhodnocovat během provádění.
- Hodnota výrazu po vyhodnocení se použije optimalizátorem dotazů k odhadu velikosti sady výsledků části dotazu
TotalDue > 117.00 + 1000.00.
Pokud je skalární uživatelem definovaná funkce, výraz dbo.f se naopak nepřeloží, protože SQL Server nepřeloží výrazy, dbo.f(100) které zahrnují uživatelem definované funkce, i když jsou deterministické. Další informace o parametrizaci naleznete v části Vynucené parametrizace dále v tomto článku.
Vyhodnocení výrazu
Kromě toho některé výrazy, které nejsou konstantně složené, ale jejichž argumenty jsou známé v době kompilace, ať už jsou argumenty parametry nebo konstanty, jsou vyhodnocovány odhadovačem velikosti sady výsledků (kardinality), který je součástí optimalizátoru při optimalizaci.
Konkrétně se při kompilaci vyhodnocují následující předdefinované funkce a speciální operátory, pokud jsou známy všechny jejich vstupy: UPPER, , LOWERRTRIM, DATEPART( YY only ), GETDATECAST, a CONVERT. Následující operátory se také vyhodnocují v době kompilace, pokud jsou známy všechny jejich vstupy:
- Aritmetické operátory: +, -, *, /, unární -
- Logické operátory:
AND,ORNOT - Operátory porovnání: <, >, <=, >=, <>,
LIKE,IS NULL,IS NOT NULL
Při odhadu kardinality nejsou vyhodnoceny žádné jiné funkce ani operátory optimalizátoru dotazů.
Příklady vyhodnocení výrazů v čase kompilace
Zvažte tuto uloženou proceduru:
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc( @d datetime )
AS
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d+1;
Během optimalizace SELECT příkazu v postupu se Optimalizátor dotazů pokusí vyhodnotit očekávanou kardinalitu sady výsledků pro podmínku OrderDate > @d+1. Výraz @d+1 není neustále složený, protože @d je parametr. V době optimalizace je však známa hodnota parametru. To umožňuje optimalizátoru dotazů přesně odhadnout velikost sady výsledků, která jí pomůže vybrat vhodný plán dotazu.
Nyní zvažte příklad podobný předchozímu, s tím rozdílem, že místní proměnná @d2 nahradí @d+1 v dotazu a výraz se vyhodnocuje v příkazu SET místo v dotazu.
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc2( @d datetime )
AS
BEGIN
DECLARE @d2 datetime
SET @d2 = @d+1
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d2
END;
Když je SELECT příkaz v MyProc2 SQL Serveru optimalizovaný, hodnota @d2 není známá. Optimalizátor dotazů proto používá výchozí odhad pro selektivitu OrderDate > @d2, (v tomto případě 30 procent).
Zpracujte další příkazy
Základní kroky popsané pro zpracování SELECT příkazu se vztahují na jiné Transact-SQL příkazy, jako jsou INSERT, UPDATE a DELETE.
UPDATE a DELETE příkazy musí cílit na sadu řádků, které se mají upravit nebo odstranit. Proces identifikace těchto řádků je stejný proces, který slouží k identifikaci zdrojových řádků, které přispívají k sadě SELECT výsledků příkazu.
UPDATE a INSERT příkazy mohou oba obsahovat vložené SELECT příkazy, které poskytují datové hodnoty k aktualizaci nebo vložení.
Dokonce i příkazy DDL (Data Definition Language), například CREATE PROCEDURE nebo ALTER TABLE, se nakonec překládají na řadu relačních operací v tabulkách systémového katalogu a někdy (například ALTER TABLE ADD COLUMN) s tabulkami dat.
Pracovní stoly
Relační modul může potřebovat vytvořit pracovní tabulku pro provedení logické operace zadané v příkazu Transact-SQL. Pracovní tabulky jsou interní tabulky, které slouží k ukládání průběžných výsledků. Pracovní tabulky se generují pro určité dotazy GROUP BY, ORDER BY nebo UNION. Pokud ORDER BY například klauzule odkazuje na sloupce, které nejsou pokryty žádnými indexy, relační modul může potřebovat vygenerovat pracovní tabulku pro seřazení sady výsledků do požadovaného pořadí. Pracovní tabulky se také někdy používají jako zásobníky, které dočasně uchovávají výsledek provádění části dotazovacího plánu. Pracovní tabulky jsou integrované tempdb a automaticky se zahodí, když už nejsou potřeba.
Zobrazení rozlišení
Procesor dotazů SQL Serveru zpracovává indexovaná a neindexovaná zobrazení odlišně:
- Řádky indexovaného zobrazení jsou uloženy v databázi ve stejném formátu jako tabulka. Pokud se Optimalizátor dotazů rozhodne použít indexované zobrazení v plánu dotazu, bude indexované zobrazení zacházeno stejně jako se základní tabulkou.
- Uložená je pouze definice neindexovaného zobrazení, nikoli řádků zobrazení. Optimalizátor dotazů zahrnuje logiku z definice zobrazení do plánu provádění, který sestaví pro příkaz Transact-SQL, který odkazuje na neindexované zobrazení.
Logika používaná optimalizátorem dotazů SQL Serveru k rozhodnutí, kdy použít indexované zobrazení, je podobná logice, která se používá k rozhodnutí, kdy použít index v tabulce. Pokud data v indexovaném zobrazení pokrývají všechny příkazy Transact-SQL nebo jeho část a optimalizátor dotazů zjistí, že index v zobrazení představuje cestu s nízkým přístupem, optimalizátor dotazů zvolí index bez ohledu na to, jestli se na zobrazení odkazuje v dotazu názvem.
Když příkaz Transact-SQL odkazuje na neindexované zobrazení, analyzátor a Optimalizátor dotazů analyzují zdroj příkazu Transact-SQL i zobrazení a pak je přeloží do jednoho plánu spuštění. Neexistuje jeden plán pro příkaz Transact-SQL a samostatný plán pro zobrazení.
Představte si například následující zobrazení:
USE AdventureWorks2022;
GO
CREATE VIEW EmployeeName AS
SELECT h.BusinessEntityID, p.LastName, p.FirstName
FROM HumanResources.Employee AS h
JOIN Person.Person AS p
ON h.BusinessEntityID = p.BusinessEntityID;
GO
V závislosti na tomto zobrazení obě tyto příkazy Transact-SQL provádějí stejné operace se základními tabulkami a vytvářejí stejné výsledky:
/* SELECT referencing the EmployeeName view. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.Sales.SalesOrderHeader AS soh
JOIN AdventureWorks2022.dbo.EmployeeName AS EmpN
ON (soh.SalesPersonID = EmpN.BusinessEntityID)
WHERE OrderDate > '20020531';
/* SELECT referencing the Person and Employee tables directly. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.HumanResources.Employee AS e
JOIN AdventureWorks2022.Sales.SalesOrderHeader AS soh
ON soh.SalesPersonID = e.BusinessEntityID
JOIN AdventureWorks2022.Person.Person AS p
ON e.BusinessEntityID =p.BusinessEntityID
WHERE OrderDate > '20020531';
Funkce Showplan aplikace SQL Server Management Studio ukazuje, že relační modul sestaví stejný plán provádění pro oba tyto SELECT příkazy.
Použijte tipy při práci se zobrazeními
Nápovědy, které jsou umístěny v zobrazeních v dotazu, můžou být v konfliktu s dalšími radami, které jsou zjištěny při rozbalení zobrazení pro přístup ke svým základním tabulkám. V takovém případě dotaz vrátí chybu. Představte si například následující zobrazení, které obsahuje indikaci tabulky v jeho definici.
USE AdventureWorks2022;
GO
CREATE VIEW Person.AddrState WITH SCHEMABINDING AS
SELECT a.AddressID, a.AddressLine1,
s.StateProvinceCode, s.CountryRegionCode
FROM Person.Address a WITH (NOLOCK), Person.StateProvince s
WHERE a.StateProvinceID = s.StateProvinceID;
Teď předpokládejme, že zadáte tento dotaz:
SELECT AddressID, AddressLine1, StateProvinceCode, CountryRegionCode
FROM Person.AddrState WITH (SERIALIZABLE)
WHERE StateProvinceCode = 'WA';
Dotaz selže, protože nápověda SERIALIZABLE, která je aplikována na zobrazení Person.AddrState v dotazu, se propaguje do obou tabulek Person.Address a Person.StateProvince ve zobrazení při jeho rozbalení. Rozšíření zobrazení však také odhalí nápovědu NOLOCKPerson.Address. Vzhledem k tomu, že dochází ke konfliktu nápověd SERIALIZABLE a NOLOCK, je výsledný dotaz nesprávný.
Nápovědy k tabulce PAGLOCK, NOLOCK, ROWLOCK, TABLOCK nebo TABLOCKX jsou v konfliktu mezi sebou, stejně jako HOLDLOCK, NOLOCK, READCOMMITTED, REPEATABLEREAD nebo SERIALIZABLE tabulkové nápovědy.
Nápověda se může šířit prostřednictvím úrovní vnořených zobrazení. Předpokládejme například, že dotaz použije nápovědu HOLDLOCK na zobrazení v1. Když v1 se rozšíří, zjistíme, že toto zobrazení v2 je částí jeho definice. Definice v2 obsahuje nápovědu k NOLOCK jedné ze svých základních tabulek. Tato tabulka ale také dědí nápovědu HOLDLOCK z dotazu v zobrazení v1. Vzhledem k tomu, že nápovědy NOLOCK a HOLDLOCK jsou v konfliktu, dotaz selže.
Při použití nápovědy FORCE ORDER v dotazu, který obsahuje zobrazení, je pořadí spojení tabulek v zobrazení určeno umístěním zobrazení v seřazené konstrukci. Například následující dotaz vybere ze tří tabulek a zobrazení:
SELECT * FROM Table1, Table2, View1, Table3
WHERE Table1.Col1 = Table2.Col1
AND Table2.Col1 = View1.Col1
AND View1.Col2 = Table3.Col2;
OPTION (FORCE ORDER);
A View1 je definován tak, jak je znázorněno v následujícím příkladu:
CREATE VIEW View1 AS
SELECT Colx, Coly FROM TableA, TableB
WHERE TableA.ColZ = TableB.Colz;
Pořadí spojení v plánu dotazu je Table1, Table2, TableA, TableB, . Table3
Řešení indexů v zobrazeních
Stejně jako u jakéhokoli indexu se SQL Server rozhodne použít indexované zobrazení v plánu dotazu jenom v případě, že optimalizátor dotazů zjistí, že je to výhodné.
Indexovaná zobrazení lze vytvořit v libovolné edici SQL Serveru. V některých edicích některých starších verzí SQL Serveru optimalizátor dotazů automaticky považuje indexované zobrazení. V některých edicích některých starších verzí SQL Serveru, aby bylo možné použít indexované zobrazení, je nutné použít hint tabulky NOEXPAND. Automatické použití indexovaného zobrazení optimalizátorem dotazů je podporováno pouze v konkrétních edicích SQL Serveru. Azure SQL Database a Azure SQL Managed Instance také podporují automatické použití indexovaných zobrazení bez zadání nápovědy NOEXPAND.
Optimalizátor dotazů SQL Serveru používá při splnění následujících podmínek indexované zobrazení:
- Tyto možnosti relace jsou nastavené na
ON:ANSI_NULLSANSI_PADDINGANSI_WARNINGSARITHABORTCONCAT_NULL_YIELDS_NULLQUOTED_IDENTIFIER
- Volba
NUMERIC_ROUNDABORTrelace je nastavena na VYPNUTO. - Optimalizátor dotazů najde shodu mezi sloupci indexu zobrazení a prvky v dotazu, například následující:
- Predikáty podmínky hledání v klauzuli WHERE
- Operace spojení
- Agregační funkce
-
GROUP BYklauzule - Odkazy na tabulky
- Odhadované náklady na použití indexu jsou nejnižší ze všech mechanismů přístupu, které optimalizátor dotazů zvažuje.
- Každá tabulka odkazovaná v dotazu (buď přímo, nebo rozšířením zobrazení pro přístup k podkladovým tabulkám), která odpovídá odkazu na tabulku v indexovaném zobrazení, musí mít stejnou sadu tipů použitých v dotazu.
Poznámka:
READCOMMITTED a READCOMMITTEDLOCK nápovědy jsou vždy považovány za odlišné nápovědy v tomto kontextu, bez ohledu na aktuální úroveň izolace transakcí.
Kromě požadavků na SET možnosti a rady tabulek se jedná o stejná pravidla, která optimalizátor dotazů používá k určení, jestli index tabulky pokrývá dotaz. V dotazu není nutné specifikovat nic dalšího, aby bylo možné použít indexované zobrazení.
Dotaz nemusí explicitně odkazovat na indexované zobrazení v FROM klauzuli, aby optimalizátor dotazů používal indexované zobrazení. Pokud dotaz obsahuje odkazy na sloupce v základních tabulkách, které se nacházejí také v indexovaném zobrazení, a Optimalizátor dotazů odhadne, že použití indexovaného zobrazení poskytuje nejnižší náklady na přístup, zvolí Optimalizátor dotazů indexované zobrazení podobně jako volí indexy základních tabulek, když nejsou přímo odkazovány v dotazu. Optimalizátor dotazů může zvolit zobrazení, pokud obsahuje sloupce, na které dotaz neodkazuje, pokud zobrazení nabízí nejnižší cenu pro pokrytí jednoho nebo více sloupců zadaných v dotazu.
Optimalizátor dotazů zpracovává indexované zobrazení odkazované v FROM klauzuli jako standardní zobrazení. Optimalizátor dotazů začleňuje definici zobrazení do dotazu na začátku procesu optimalizace. Potom se provede porovnávání indexovaného zobrazení. Indexované zobrazení lze použít v konečném plánu provádění vybraném optimalizátorem dotazů, nebo místo toho může plán materializovat potřebná data ze zobrazení přístupem k základním tabulkám, na které odkazuje zobrazení. Optimalizátor dotazů zvolí alternativu s nejnižšími náklady.
Použijte tipy s indexovanými zobrazeními
Pomocí nápovědy k dotazu EXPAND VIEWS můžete zabránit použití indexů zobrazení nebo můžete použít NOEXPAND nápovědu k tabulce a vynutit použití indexu pro indexované zobrazení zadané v FROM klauzuli dotazu. Měli byste však nechat optimalizátor dotazů dynamicky určit nejlepší metody přístupu, které se mají použít pro každý dotaz. Omezte využití EXPAND a NOEXPAND na konkrétní případy, kdy testování ukázalo, že výrazně zlepšují výkon.
Možnost
EXPAND VIEWSurčuje, že optimalizátor dotazů nepoužívá pro celý dotaz žádné indexy zobrazení.Pokud
NOEXPANDje zadán pro zobrazení, Optimalizátor dotazů považuje použití všech indexů definovaných v zobrazení.NOEXPANDurčená prostřednictvím volitelnéINDEX()klauzule přinutí Optimalizátor dotazů, aby použil určené indexy.NOEXPANDlze zadat pouze pro indexované zobrazení a nelze ho zadat pro zobrazení, které není indexováno. Automatické použití indexovaného zobrazení optimalizátorem dotazů je podporováno pouze v konkrétních edicích SQL Serveru. Azure SQL Database a Azure SQL Managed Instance také podporují automatické použití indexovaných zobrazení bez zadání nápovědyNOEXPAND.
Pokud není v dotazu, který obsahuje zobrazení, zadán ani NOEXPAND ani EXPAND VIEWS, zobrazení se rozbalí pro přístup k podkladovým tabulkám. Pokud dotaz, který tvoří zobrazení, obsahuje nějaké tabulkové hinty, tyto hinty se aplikují na podkladové tabulky. (Tento proces je podrobněji vysvětlen v zobrazení řešení.) Pokud je sada tipů, které existují v podkladových tabulkách zobrazení, identické s ostatními, je možné dotaz spárovat s indexovaným zobrazením. Ve většině případů se tyto nápovědy vzájemně shodují, protože jsou přebírány přímo ze zobrazení. Pokud ale dotaz odkazuje na tabulky místo zobrazení a rady použité přímo na tyto tabulky nejsou stejné, pak takový dotaz nemá nárok na porovnávání s indexovaným zobrazením. Pokud se nápovědy INDEX, PAGLOCK, ROWLOCK, TABLOCKX, UPDLOCK nebo XLOCK po rozšíření zobrazení použijí na tabulky odkazované v dotazu, tento dotaz nemá nárok na porovnání s indexovaným zobrazením.
Pokud hint tabulky ve formě INDEX (index_val[ ,...n] ) odkazuje na zobrazení v dotazu a nezadáte také hint NOEXPAND, bude hint indexu ignorován. Chcete-li určit použití určitého indexu, použijte NOEXPAND.
Obecně platí, že pokud optimalizátor dotazů odpovídá indexovanému zobrazení dotazu, všechny rady zadané v tabulkách nebo zobrazeních dotazu se použijí přímo v indexovaném zobrazení. Pokud se optimalizátor dotazů rozhodne nepoužívat indexované zobrazení, všechny rady se rozšíří přímo do tabulek odkazovaných v zobrazení. Další informace najdete v tématu Zobrazení řešení. Toto šíření se nevztahuje na nápovědy ke spojení. Použijí se pouze v původní pozici v dotazu. Hinty pro spojení nejsou zvažovány optimalizátorem dotazů při porovnávání dotazů s indexovanými zobrazeními. Pokud plán dotazu používá indexované zobrazení, které odpovídá té části dotazu obsahující nápovědu ke spojení, tato nápověda se v plánu nepoužije.
V definicích indexovaných zobrazení nejsou povoleny tipy. V režimu kompatibility 80 a vyšší sql Server ignoruje rady uvnitř indexovaných definic zobrazení při jejich údržbě nebo při provádění dotazů, které používají indexovaná zobrazení. I když použití tipů v definicích indexovaného zobrazení nevyvolá chybu syntaxe v režimu kompatibility 80, budou ignorovány.
Další informace naleznete v části Tipy pro tabulku (Transact-SQL).
Řešení potíží s distribuovanými rozdělenými zobrazeními
Procesor dotazů SQL Serveru optimalizuje výkon distribuovaných rozdělených zobrazení. Nejdůležitějším aspektem výkonu distribuovaného rozděleného zobrazení je minimalizace množství dat přenášených mezi členskými servery.
SQL Server vytváří inteligentní dynamické plány, které efektivně využívají distribuované dotazy pro přístup k datům z tabulek vzdálených členů:
- Procesor dotazů nejprve používá OLE DB k načtení definic omezení kontroly z každé členské tabulky. Procesoru dotazů tak umožníte namapovat distribuci hodnot klíče napříč tabulkami členů.
- Procesor dotazů porovnává rozsahy klíčů zadané v klauzuli příkazu
WHERETransact-SQL s mapou, která ukazuje, jak se řádky distribuují v tabulkách členů. Procesor dotazů pak sestaví plán provádění dotazů, který používá distribuované dotazy k načtení pouze vzdálených řádků, které jsou potřeba k dokončení příkazu Transact-SQL. Plán provádění je také sestaven takovým způsobem, že jakýkoli přístup k tabulkám vzdálených členů pro data nebo metadata se zpozdí, dokud se nebudou vyžadovat informace.
Představte si například systém, ve kterém Customers je tabulka rozdělená mezi Server1 (CustomerID od 1 do 3299999), Server2 (CustomerID od 33 00000 do 6599999) a Server3 (CustomerID od 66000000 do 9999999).
Zvažte plán provádění vytvořený pro tento dotaz spuštěný na serveru Server1:
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID BETWEEN 3200000 AND 3400000;
Plán provádění pro tento dotaz extrahuje řádky s klíčovými hodnotami z 32000000 až 3299999 z místní členské tabulky a vydá distribuovaný dotaz pro načtení řádků s CustomerID klíčovými hodnotami z 33000000 až 3400000 ze serveru Server2.
Procesor dotazů SQL Serveru může také vytvořit dynamickou logiku do plánů spouštění dotazů pro příkazy Transact-SQL, ve kterých nejsou klíčové hodnoty známé při sestavení plánu. Představte si například tuto uloženou proceduru:
CREATE PROCEDURE GetCustomer @CustomerIDParameter INT
AS
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID = @CustomerIDParameter;
SQL Server nemůže předpovědět hodnotu klíče, kterou @CustomerIDParameter parametr zadá při každém spuštění procedury. Vzhledem k tomu, že hodnotu klíče nelze predikovat, procesor dotazů také nedokáže předpovědět, ke které členské tabulce bude potřeba přistupovat. Pro zpracování tohoto případu SQL Server sestaví plán spouštění, který má podmíněnou logiku označovanou jako dynamické filtry, a řídí, ke které tabulce členů se přistupuje na základě hodnoty vstupního parametru. Za předpokladu, GetCustomer že se uložená procedura spustila na serveru Server1, je možné reprezentovat logiku plánu provádění, jak je znázorněno v následujících příkladech:
IF @CustomerIDParameter BETWEEN 1 and 3299999
Retrieve row from local table CustomerData.dbo.Customer_33
ELSE IF @CustomerIDParameter BETWEEN 3300000 and 6599999
Retrieve row from linked table Server2.CustomerData.dbo.Customer_66
ELSE IF @CustomerIDParameter BETWEEN 6600000 and 9999999
Retrieve row from linked table Server3.CustomerData.dbo.Customer_99
SQL Server někdy vytváří tyto typy dynamických plánů spouštění i pro dotazy, které nejsou parametrizovány. Optimalizátor dotazů může parametrizovat dotaz, aby bylo možné znovu použít plán provádění. Pokud optimalizátor dotazů parametrizuje dotaz odkazující na rozdělené zobrazení, optimalizátor dotazů už nemůže předpokládat, že požadované řádky budou pocházet ze zadané základní tabulky. Pak bude muset v plánu provádění používat dynamické filtry.
Uložená procedura a spuštění triggeru
SQL Server ukládá pouze zdroj uložených procedur a triggerů. Při prvním spuštění uložené procedury nebo triggeru se zdroj zkompiluje do plánu provádění. Pokud se uložená procedura nebo spouštěč znovu spustí před tím, než je plán provádění odstraněn z paměti, relační stroj rozpozná existující plán a znovu ho použije. Pokud je plán zapomenut, vytvoří se nový plán. Tento proces se podobá procesu SQL Serveru pro všechny příkazy Transact-SQL. Hlavní výhoda výkonu, kterou uložené procedury a triggery mají v SQL Serveru ve srovnání s dávkami dynamických Transact-SQL je, že jejich Transact-SQL příkazy jsou vždy stejné. Relační modul je proto snadno odpovídá všem existujícím plánům provádění. Uložené procedury a plány aktivačních událostí se snadno znovu používají.
Plán provádění uložených procedur a aktivačních událostí se spouští odděleně od plánu provádění pro dávku volání uložené procedury nebo aktivaci triggeru. To umožňuje větší opakované použití uložené procedury a aktivaci plánů spuštění.
Ukládání do mezipaměti a opakované použití plánu provádění
SQL Server má fond paměti, který se používá k ukládání plánů spouštění i vyrovnávací paměti dat. Procento fondu přiděleného plánům provádění nebo vyrovnávacím pamětím dat se dynamicky mění v závislosti na stavu systému. Část fondu paměti, která se používá k ukládání plánů spouštění, se označuje jako mezipaměť plánu.
Mezipaměť plánu má pro všechny kompilované plány dvě úložiště:
- Úložiště mezipaměti plánů objektů (OBJCP) používané pro plány související s trvalými objekty (uložené procedury, funkce a triggery).
- Úložiště mezipaměti SQL Plans (SQLCP) používané pro plány související s automatickyparametrizovanými, dynamickými nebo připravenými dotazy.
Následující dotaz obsahuje informace o využití paměti pro tato dvě úložiště mezipaměti:
SELECT * FROM sys.dm_os_memory_clerks
WHERE name LIKE '%plans%';
Poznámka:
Mezipaměť plánů má dvě další úložiště, která se nepoužívají k ukládání plánů:
- Úložiště mezipaměti Vázané stromy (PHDR) používané pro datové struktury používané při kompilaci plánu pro zobrazení, omezení a výchozí hodnoty. Tyto struktury se označují jako vázané stromy nebo algebrizerové stromy.
- Úložiště mezipaměti rozšířených uložených procedur (XPROC) používané pro předdefinované systémové procedury, jako
sp_executeSqlneboxp_cmdshell, které jsou definovány pomocí knihovny DLL, ne pomocí příkazů Transact-SQL. Struktura uložená v mezipaměti obsahuje pouze název funkce a název knihovny DLL, ve které je procedura implementována.
Plány spouštění SQL Serveru mají následující hlavní komponenty:
Kompilovaný plán (nebo plán dotazu)
Plán dotazu vytvořený procesem kompilace je většinou znovu použitelnou datovou strukturou určenou pouze pro čtení, kterou používá libovolný počet uživatelů. Ukládá informace o:Fyzické operátory, které implementují operaci popsanou logickými operátory.
Pořadí těchto operátorů, které určuje pořadí přístupu k datům, filtrování a agregaci.
Počet řádků, které odhadem procházejí přes operátory.
Poznámka:
V novějších verzích databázového stroje jsou uloženy také informace o statistických objektech, které byly použity pro odhad kardinality .
Jaké objekty podpory musí být vytvořeny, například pracovní tabulky nebo pracovní soubory v
tempdbsouboru . V plánu dotazu nejsou ukládány žádné informace o uživatelském kontextu ani o runtime. V paměti nikdy není více než jedna nebo dvě kopie plánu dotazu: jedna kopie pro všechna sériová spuštění a druhá pro všechna paralelní spuštění. Paralelní kopie pokrývá všechna paralelní spuštění bez ohledu na jejich stupeň paralelismu.
Kontext spuštění
Každý uživatel, který právě spouští dotaz, má datovou strukturu, která obsahuje data specifická pro jejich spuštění, například hodnoty parametrů. Tato datová struktura se označuje jako kontext spuštění. Datové struktury kontextu provádění se znovu používají, ale jejich obsah není znovu používán. Pokud jiný uživatel spustí stejný dotaz, datové struktury se znovu inicializují s kontextem nového uživatele.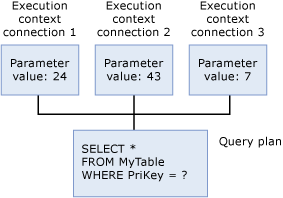
Když se v SQL Serveru spustí jakýkoli příkaz Transact-SQL, databázový stroj nejprve projde mezipamětí plánu a ověří, že existuje existující plán provádění pro stejný příkaz Transact-SQL. Příkaz Transact-SQL se kvalifikuje jako existující, pokud se doslova shoduje s dříve spouštěným příkazem Transact-SQL s plánem uloženým v mezipaměti, znakem na znak. SQL Server znovu použije jakýkoli existující plán, který najde, a šetří režii při rekompilování příkazu Transact-SQL. Pokud neexistuje žádný plán provádění, SQL Server vygeneruje pro dotaz nový plán provádění.
Poznámka:
Plány provádění některých příkazů Transact-SQL se neuchovávají v mezipaměti plánu, například příkazy hromadné operace spuštěné v úložišti řádků nebo příkazy obsahující řetězcové literály větší než 8 kB. Tyto plány existují pouze při provádění dotazu.
SQL Server má efektivní algoritmus pro vyhledání všech stávajících plánů provádění pro jakýkoli konkrétní příkaz Transact-SQL. Ve většině systémů jsou minimální prostředky použité tímto skenováním menší než prostředky ušetřené schopností znovu použít stávající plány namísto kompilace každého Transact-SQL prohlášení.
Algoritmy odpovídající novým příkazům Transact-SQL stávajícím nepoužitým plánům provádění v mezipaměti plánu vyžadují, aby všechny odkazy na objekty byly plně kvalifikované. Předpokládejme například, že Person je výchozím schématem pro uživatele, který spouští následující SELECT příkazy. I když v tomto příkladu není nutné, aby Person byla tabulka plně kvalifikovaná ke spuštění, znamená to, že druhý příkaz neodpovídá existujícímu plánu, ale třetí se shoduje:
USE AdventureWorks2022;
GO
SELECT * FROM Person;
GO
SELECT * FROM Person.Person;
GO
SELECT * FROM Person.Person;
GO
Změna některé z následujících možností SET pro dané spuštění ovlivní možnost opakovaného použití plánů, protože databázový stroj provádí konstantní posouvání a tyto možnosti ovlivňují výsledky těchto výrazů:
ANSI_NULL_DFLT_OFF (nastavení režimu pro zacházení s NULL hodnotami v SQL)
FORCEPLAN
ARITHABORT
DATEFIRST
ANSI_PADDING
NUMERIC_ROUNDABORT - Nastavení pro zrušení zaokrouhlování čísel
ANSI_NULL_DFLT_ON
JAZYK
Nastavení CONCAT_NULL_YIELDS_NULL
Formát datumu
Upozornění ANSI
Citovaný identifikátor
ANSI_NULLS
NO_BROWSETABLE
Výchozí hodnoty ANSI
Ukládání více plánů do mezipaměti pro stejný dotaz
Dotazy a plány provádění jsou v databázovém stroji jednoznačně identifikovatelné, podobně jako otisk prstu:
- Hodnota hash plánu dotazu je binární hodnota hash vypočítaná v plánu provádění pro daný dotaz a slouží k jedinečné identifikaci podobných plánů provádění.
- Hodnota hash dotazu je binární hodnota hash vypočítaná na Transact-SQL textu dotazu a slouží k jedinečné identifikaci dotazů.
Zkompilovaný plán lze načíst z mezipaměti plánu pomocí popisovače plánu, což je přechodný identifikátor, který zůstává konstantní pouze v době, kdy plán zůstává v mezipaměti. Identifikátor plánu je hodnota hash odvozená ze zkompilovaného plánu celé dávky. Identifikátor plánu pro zkompilovaný plán zůstane stejný, i když se jeden nebo více příkazů ve sdružené úloze zkompiluje znovu.
Poznámka:
Pokud byl plán zkompilován pro dávku místo jednoho příkazu, plán pro jednotlivé příkazy v dávce lze načíst pomocí popisovače plánu a offsetů příkazů.
sys.dm_exec_requests DMV obsahuje sloupec statement_start_offset a sloupec statement_end_offset pro každý záznam, které odkazují na právě prováděný příkaz k dávce nebo trvalému objektu. Další informace najdete v tématu sys.dm_exec_requests (Transact-SQL).
Zobrazení sys.dm_exec_query_stats dynamické správy obsahuje také tyto sloupce pro každý záznam, který odkazuje na pozici příkazu v dávkovém nebo trvalém objektu. Další informace najdete v tématu sys.dm_exec_query_stats (Transact-SQL).
Skutečný Transact-SQL text dávky je uložen v samostatném paměťovém prostoru, odděleném od mezipaměti plánu, nazývaném mezipaměť SQL Manager (SQLMGR). Text Transact-SQL zkompilovaného plánu lze načíst z mezipaměti sql Manageru pomocí popisovače SQL, což je přechodný identifikátor, který zůstává konstantní pouze v případě, že alespoň jeden plán, který na něj odkazuje, zůstane v mezipaměti plánu. SQL popisovač je hodnota haše odvozená z celého textu dávky a zaručeně jedinečná pro každou dávku.
Poznámka:
Podobně jako zkompilovaný plán se text Transact-SQL ukládá v dávkách, včetně komentářů. Popisovač SQL obsahuje MD5 hash celého dávkového textu a je zaručeno, že je pro každou dávku jedinečný.
Následující dotaz obsahuje informace o využití paměti pro mezipaměť sql Manageru:
SELECT * FROM sys.dm_os_memory_objects
WHERE type = 'MEMOBJ_SQLMGR';
Mezi SQL identifikátorem a identifikátory plánu existuje vztah 1:N. K takové podmínce dojde, když se klíč mezipaměti pro zkompilované plány liší. K tomu může dojít kvůli změně možností SET mezi dvěma spuštěními stejné dávky.
Zvažte následující uloženou proceduru:
USE WideWorldImporters;
GO
CREATE PROCEDURE usp_SalesByCustomer @CID int
AS
SELECT * FROM Sales.Customers
WHERE CustomerID = @CID
GO
SET ANSI_DEFAULTS ON
GO
EXEC usp_SalesByCustomer 10
GO
Pomocí následujícího dotazu ověřte, co se dá v mezipaměti plánu najít:
SELECT cp.memory_object_address, cp.objtype, refcounts, usecounts,
qs.query_plan_hash, qs.query_hash,
qs.plan_handle, qs.sql_handle
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_sql_text (cp.plan_handle)
CROSS APPLY sys.dm_exec_query_plan (cp.plan_handle)
INNER JOIN sys.dm_exec_query_stats AS qs ON qs.plan_handle = cp.plan_handle
WHERE text LIKE '%usp_SalesByCustomer%'
GO
Tady je soubor výsledků.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Teď spusťte uloženou proceduru s jiným parametrem, ale žádné další změny kontextu spuštění:
EXEC usp_SalesByCustomer 8
GO
Znovu ověřte, co lze najít v cache plánu. Tady je soubor výsledků.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
usecounts Všimněte si, že došlo ke zvýšení na 2, což znamená, že stejný plán v mezipaměti byl opakovaně použit as-is, protože se znovu používaly datové struktury kontextu provádění. Teď změňte SET ANSI_DEFAULTS možnost a spusťte uloženou proceduru pomocí stejného parametru.
SET ANSI_DEFAULTS OFF
GO
EXEC usp_SalesByCustomer 8
GO
Znovu ověřte, co lze najít v cache plánu. Tady je soubor výsledků.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CD01DEC060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02B031F111CD01000001000000000000000000000000000000000000000000000000000000
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Všimněte si, že ve výstupu sys.dm_exec_cached_plans DMV jsou teď dvě položky:
- Sloupec
usecountszobrazuje hodnotu1v prvním záznamu, což je plán proveden jednou sSET ANSI_DEFAULTS OFF. - Ve
usecountssloupci se zobrazí hodnota2ve druhém záznamu, což je plán spuštěný sSET ANSI_DEFAULTS ON, protože byl proveden dvakrát. - Jiný
memory_object_addressodkazuje na jiný záznam plánu provádění v mezipaměti plánu. Hodnotasql_handleje však stejná pro obě položky, protože se vztahují ke stejné dávce.- Provádění s
ANSI_DEFAULTSnastavené na OFF má novouplan_handle, a je k dispozici pro opakované použití pro volání, která mají stejnou sadu možností SET. Nový popisovač plánu je nutný, protože kontext spuštění byl znovu inicializován z důvodu změněných možností SET. To ale neaktivuje překompilování: obě položky odkazují na stejný plán a dotaz, což je doloženo stejnými hodnotamiquery_plan_hashaquery_hash.
- Provádění s
To efektivně znamená, že máme v paměti cache dvě položky plánu odpovídající stejné dávce, což zdůrazňuje důležitost zajištění, aby nastavení cache plánu související s volbami SET byly stejné, když jsou stejné dotazy opakovaně prováděny, aby se optimalizovalo opakované použití plánu a velikost cache plánu se udržovala na požadovaném minimu.
Návod
Běžnou nástrahou je, že různé klienty můžou mít různé výchozí hodnoty pro možnosti SET. Například připojení vytvořené prostřednictvím aplikace SQL Server Management Studio se automaticky nastaví QUOTED_IDENTIFIER na ZAPNUTO, zatímco SQLCMD se nastaví QUOTED_IDENTIFIER na VYPNUTO. Provedení stejných dotazů z těchto dvou klientů povede ke vzniku několika plánů (jak je uvedeno v příkladu výše).
Odebrat plány provádění z mezipaměti plánu
Plány spuštění zůstanou v mezipaměti plánu, dokud je k dispozici dostatek paměti pro jejich uložení. Pokud existuje tlak na paměť, databázový stroj SQL Serveru používá přístup založený na nákladech k určení, které prováděcí plány se mají z mezipaměti plánu odebrat. Aby bylo možné provést rozhodnutí založené na nákladech, databázový stroj SQL Serveru zvýší a sníží aktuální nákladovou proměnnou pro každý plán provádění podle následujících faktorů.
Když uživatelský proces vloží plán provádění do mezipaměti, nastaví aktuální náklady na úroveň původních nákladů na kompilaci dotazu; u ad hoc prováděcích plánů nastaví uživatelský proces aktuální náklady na nulu. Poté, když uživatelský proces odkazuje na plán provádění, nastaví aktuální náklady zpět na původní náklady kompilace; u ad hoc prováděcích plánů uživatelský proces zvýší aktuální náklady. Pro všechny plány je maximální hodnota aktuálních nákladů původní náklady kompilace.
Pokud existuje tlak na paměť, databázový stroj SQL Serveru reaguje odebráním plánů provádění z vyrovnávací paměti plánů. Chcete-li zjistit, které plány odebrat, databázový stroj SQL Serveru opakovaně kontroluje stav každého plánu provádění a odebere plány, když jejich aktuální náklady jsou nulové. Plán provádění s nulovými aktuálními náklady se automaticky neodebere, pokud existuje tlak na paměť; Odebere se pouze v případech, kdy databázový stroj SQL Serveru prozkoumá plán a aktuální náklady jsou nulové. Při zkoumání prováděcího plánu posunuje databázový stroj SQL Serveru aktuální náklady směrem k nule tím, že snižuje aktuální náklady, pokud plán není momentálně používán dotazem.
Databázový stroj SQL Server opakovaně zkoumá plány vykonávání, dokud není odstraněno dost, aby bylo splněno požadavky na paměť. Při zatížení paměti se může náklady plánu vykonání více než jednou zvýšit i snížit. Pokud už zatížení paměti neexistuje, databázový stroj SQL Serveru přestane snižovat aktuální náklady na nevyužité plány provádění a všechny plány provádění zůstanou v mezipaměti plánu, i když jejich náklady jsou nulové.
Databázový stroj SQL Serveru využívá monitor prostředků a uživatelská pracovní vlákna k uvolnění paměti z mezipaměti plánu v reakci na zatížení paměti. Monitor prostředků a uživatelská pracovní vlákna mohou zkoumat plány prováděné současně, aby se snížily aktuální náklady na každý nevyužitý plán provádění. Monitor prostředků odebere plány provádění z mezipaměti plánů, pokud dochází ke globálnímu tlaku na paměť. Uvolní paměť pro prosazení zásad týkajících se systémové paměti, paměti procesu, paměti fondu prostředků a maximální velikosti všech mezipamětí.
Maximální velikost všech mezipamětí je funkce velikosti fondu vyrovnávací paměti a nesmí překročit maximální paměť serveru. Další informace o konfiguraci maximální paměti serveru naleznete v nastavení max server memory ve sp_configure souboru.
Pracovní vlákna uživatele odeberou plány spuštění z mezipaměti plánu, pokud existuje zatížení paměti v jedné mezipaměti. Vynucují zásady pro maximální velikost jedné mezipaměti a maximální počet položek jedné mezipaměti.
Následující příklady ukazují, které plány provádění se odeberou z mezipaměti plánu:
- Na plán provádění se často odkazuje, takže náklady nikdy nepřejdou na nulu. Plán zůstane v mezipaměti plánu a neodebere se, pokud není zatížení paměti a aktuální náklady jsou nulové.
- Vloží se ad hoc plán provádění, na který se znovu neodkazuje, než existuje tlak na paměť. Vzhledem k tomu, že se plány ad hoc inicializují s aktuálními náklady na nulu, když databázový stroj SQL Serveru zkontroluje plán provádění, zobrazí se nulové aktuální náklady a odebere plán z mezipaměti plánu. Pokud není paměť žádným způsobem zatěžována, ad hoc plán provádění zůstává v mezipaměti plánu s nulovými aktuálními náklady.
Pokud chcete ručně odebrat jeden plán nebo všechny plány z mezipaměti, použijte DBCC FREEPROCCACHE.
DBCC FREESYSTEMCACHE lze použít k vymazání libovolné mezipaměti, včetně mezipaměti plánu. Počínaje SQL Serverem 2016 (13.x) ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE ke vymazání mezipaměti plánů procedur pro aktuální databázi.
Změna některých nastavení konfigurace prostřednictvím sp_configure a reconfigure také způsobí odebrání plánů z mezipaměti plánů. Seznam těchto nastavení konfigurace najdete v části Poznámky článku DBCC FREEPROCCACHE . Změna konfigurace, jako je tato, bude protokolovat následující informační zprávu v protokolu chyb:
SQL Server has encountered %d occurrence(s) of cachestore flush for the '%s' cachestore (part of plan cache) due to some database maintenance or reconfigure operations.
Rekompilovat plány provádění
Některé změny v databázi můžou způsobit, že plán provádění bude neefektivní nebo neplatný na základě nového stavu databáze. SQL Server zjistí změny, které zneplatní plán provádění, a označí plán jako neplatný. Je třeba znovu zkompilovat nový plán pro příští připojení, které vykoná dotaz. Mezi podmínky, které zneplatní plán, patří následující:
- Změny provedené v tabulce nebo zobrazení odkazovaném dotazem (
ALTER TABLEaALTER VIEW). - Změny provedené v jediném postupu, které by vyřadily všechny plány pro tento postup z mezipaměti (
ALTER PROCEDURE). - Změny všech indexů používaných plánem provádění
- Aktualizuje statistiky používané plánem provádění, vygenerované buď explicitně z příkazu, například
UPDATE STATISTICSnebo automaticky vygenerované. - Odstranění indexu používaného v plánu provádění
- Explicitní volání
sp_recompile. - Velký počet změn klíčů (vygenerovaných
INSERTjinými uživateli neboDELETEpříkazy od jiných uživatelů, kteří upravují tabulku odkazovanou dotazem). - U tabulek s aktivačními událostmi, pokud se výrazně zvětší počet řádků v tabulkách vložených nebo odstraněných.
- Spuštění uložené procedury pomocí volby
WITH RECOMPILE.
Většina rekompilace se vyžaduje buď kvůli správnosti příkazů, nebo k získání potenciálně rychlejších plánů provádění dotazů.
Ve verzích SQL Serveru před rokem 2005, při každém příkazu v dávce, který způsobí rekompilaci, byla rekompilována celá dávka, ať už odeslaná prostřednictvím uložené procedury, triggeru, ad hoc dávky nebo připraveného příkazu. Počínaje SQL Serverem 2005 (9.x) se rekompiluje pouze příkaz uvnitř dávky, která aktivuje rekompilace. Kromě toho existují i další typy rekompilace v SQL Serveru 2005 (9.x) a novějších kvůli rozšířené sadě funkcí.
Rekompilace na úrovni příkazů přináší výkon, protože ve většině případů malý počet příkazů způsobuje rekompilace a související sankce z hlediska času procesoru a zámků. Tyto sankce se proto netýkají ostatních prohlášení v dávce, která nemusí být znovu kompilována.
sql_statement_recompile Rozšířená událost (XEvent) hlásí rekompilace na úrovni příkazů. K této události XEvent dochází v případě, že jakýkoli druh dávky vyžaduje rekompilace na úrovni příkazu. To zahrnuje uložené procedury, triggery, ad hoc dávky a dotazy. Dávky je možné odeslat prostřednictvím několika rozhraní, včetně sp_executesql, dynamického SQL, metody přípravy nebo metody Execute.
recompile_cause Sloupec sql_statement_recompile XEvent obsahuje celočíselné kód, který označuje důvod rekompilace. Následující tabulka obsahuje možné důvody:
Změněné schéma
Statistika se změnila
Odložená kompilace
Možnost SET byla změněna
Dočasná tabulka se změnila.
Došlo ke změně vzdálené sady řádků
FOR BROWSE oprávnění změněno
Změna prostředí oznámení dotazu
Došlo ke změně rozděleného zobrazení
Změněné možnosti kurzoru
OPTION (RECOMPILE) požadovaný
Vyprázdněný parametrizovaný plán
Plán ovlivňující změněnou verzi databáze
Změna zásad vynucování plánu pro úložiště dotazů
Selhání vynucení plánu v Query Store
V úložišti dotazů chybí plán.
Poznámka:
Ve verzích SQL Serveru, kde nejsou k dispozici XEvents, je možné použít událost trasování SQL Server Profiler SP:Recompile pro účely hlášení překompilací na úrovni příkazů.
Událost SQL:StmtRecompile trasování také hlásí rekompilace na úrovni příkazů a tuto událost trasování lze také použít ke sledování a ladění rekompilace.
Zatímco SP:Recompile generuje pouze pro uložené procedury a triggery, SQL:StmtRecompile generuje pro uložené procedury, triggery, ad hoc dávky, dávky, které se spouští pomocí sp_executesql, připravených dotazů a dynamického SQL.
Sloupec EventSubClass ve sloupcích SP:Recompile a SQL:StmtRecompile obsahuje celočíselný kód, který označuje důvod rekompilace. Kódy jsou popsány ve třídě událostí SQL:StmtRecompile.
Poznámka:
AUTO_UPDATE_STATISTICS Pokud je možnost databáze nastavena na ON, dotazy se znovu kompilují, když cílí na tabulky nebo indexovaná zobrazení, jejichž statistiky byly aktualizovány nebo jejichž kardinality se výrazně změnily od posledního spuštění.
Toto chování platí pro standardní uživatelem definované tabulky, dočasné tabulky a vložené a odstraněné tabulky vytvořené triggery DML. Pokud je výkon dotazů ovlivněn nadměrným překompilacem, zvažte změnu tohoto nastavení na OFF.
AUTO_UPDATE_STATISTICS Pokud je možnost databáze nastavena na OFF, nedojde k žádné rekompilace na základě statistiky nebo změny kardinality, s výjimkou vložených a odstraněných tabulek vytvořených triggery DMLINSTEAD OF. Vzhledem k tomu, že jsou tyto tabulky vytvořeny v tempdb, rekompilace dotazů, které k nim přistupují, závisí na nastavení AUTO_UPDATE_STATISTICS v tempdb.
V systému SQL Server před verzí 2005 se dotazy i nadále znovu kompilují na základě změn kardinality tabulek vložených a odstraněných triggerem DML, i když je toto nastavení OFF.
Opětovné použití parametrů a vykonávacího plánu
Použití parametrů, včetně značek parametrů v aplikacích ADO, OLE DB a ODBC, může zvýšit opakované použití plánů provádění.
Výstraha
Použití parametrů nebo značek parametrů k uložení hodnot zadaných koncovými uživateli je bezpečnější než zřetězení hodnot do řetězce, který se pak spustí pomocí metody rozhraní API pro přístup k datům, EXECUTE příkazu nebo sp_executesql uložené procedury.
Jediným rozdílem mezi následujícími dvěma SELECT příkazy jsou hodnoty, které se porovnávají v WHERE klauzuli:
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
Jediným rozdílem mezi plány provádění těchto dotazů je hodnota uložená pro porovnání se sloupcem ProductSubcategoryID . I když je cílem SQL Serveru vždy rozpoznat, že příkazy generují v podstatě stejný plán a znovu používají plány, SQL Server někdy tento problém nezjistí v složitých příkazech Transact-SQL.
Oddělení konstant od příkazu Transact-SQL pomocí parametrů pomáhá relačnímu modulu rozpoznat duplicitní plány. Parametry můžete použít následujícími způsoby:
V Transact-SQL použijte
sp_executesql:DECLARE @MyIntParm INT SET @MyIntParm = 1 EXEC sp_executesql N'SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = @Parm', N'@Parm INT', @MyIntParmTato metoda se doporučuje pro Transact-SQL skripty, uložené procedury nebo triggery, které dynamicky generují příkazy SQL.
ADO, OLE DB a ODBC používají značky parametrů. Značky parametrů jsou otazníky (?), které nahrazují konstantu v příkazu SQL a jsou svázané s proměnnou programu. V aplikaci ODBC byste například udělali toto:
Použijte
SQLBindParameterk navázání celočíselné proměnné na první místo parametrů v příkazu SQL.Vložte celočíselnou hodnotu do proměnné.
Spusťte příkaz a určete značku parametru (?):
SQLExecDirect(hstmt, "SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = ?", SQL_NTS);
Zprostředkovatel OLE DB nativního klienta SQL Serveru a ovladač ODBC nativního klienta SQL Serveru, které jsou součástí SQL Serveru, používají
sp_executesqlk odesílání příkazů do SQL Serveru, když jsou v aplikacích použity značky parametrů.K návrhu uložených procedur, které jsou navrženy tak, aby používaly parametry.
Pokud do návrhu aplikací explicitně nezabudujete parametry, můžete se také spolehnout na optimalizátor dotazů SQL Serveru a automaticky parametrizovat určité dotazy pomocí výchozího chování jednoduché parametrizace. Alternativně můžete vynutit optimalizátor dotazů, aby zvážil parametrizaci všech dotazů v databázi nastavením PARAMETERIZATION možnosti ALTER DATABASE příkazu na FORCED.
Pokud je povolená vynucená parametrizace, může stále dojít k jednoduché parametrizaci. Například následující dotaz nelze parametrizovat podle pravidel vynucené parametrizace:
SELECT * FROM Person.Address
WHERE AddressID = 1 + 2;
Lze však parametrizovat podle jednoduchých pravidel parametrizace. Když je pokus o vynucenou parametrizaci neúspěšný, stále se pokouší jednoduchá parametrizace.
Jednoduchá parametrizace
V SQL Serveru se pomocí parametrů nebo značek parametrů v příkazech Transact-SQL zvyšuje schopnost relačního modulu odpovídat novým příkazům Transact-SQL s existujícími dříve kompilovanými plány provádění.
Výstraha
Použití parametrů nebo značek parametrů k uložení hodnot zadaných koncovými uživateli je bezpečnější než zřetězení hodnot do řetězce, který se pak spustí pomocí metody rozhraní API pro přístup k datům, EXECUTE příkazu nebo sp_executesql uložené procedury.
Pokud je příkaz Transact-SQL proveden bez parametrů, SQL Server parametrizuje příkaz interně, aby se zvýšila možnost, že se shoduje s existujícím plánem provádění. Tento proces se nazývá jednoduchá parametrizace. Ve verzích SQL Serveru před 2005 se tento proces označoval jako automatická parametrizace.
Zvažte tento výrok:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
Hodnotu 1 na konci příkazu lze zadat jako parametr. Relační modul sestaví plán provádění pro tuto dávku, jako by byl parametr zadán místo hodnoty 1. Kvůli této jednoduché parametrizaci SQL Server rozpozná, že následující dva příkazy vygenerují v podstatě stejný plán provádění a znovu použije první plán druhého příkazu:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
Při zpracování složitých příkazů Transact-SQL může relační modul mít potíže s určením výrazů, které lze parametrizovat. Aby se zvýšila schopnost relačního modulu přiřazovat složité příkazy Transact-SQL ke stávajícím nevyužitým plánům provádění, explicitně určete parametry pomocí značek sp_executesql nebo značek parametrů.
Poznámka:
Pokud jsou operátory +, , -, */nebo % aritmetické operátory použity k provedení implicitního nebo explicitního převodu int, smallint, tinyint nebo bigint konstantních hodnot na plovoucí, reálné, desetinné nebo číselné datové typy, SQL Server použije konkrétní pravidla pro výpočet typu a přesnosti výsledků výrazu. Tato pravidla se ale liší v závislosti na tom, jestli je dotaz parametrizovaný nebo ne. Podobné výrazy v dotazech proto můžou v některých případech vést k různým výsledkům.
Při výchozím chování jednoduché parametrizace SQL Server parametrizuje relativně malou třídu dotazů. Můžete však určit, že všechny dotazy v databázi budou parametrizovány, s výhradou určitých omezení, nastavením možnosti PARAMETERIZATION příkazu na ALTER DATABASE. To může zlepšit výkon databází, které mají vysoké objemy souběžných dotazů snížením frekvence kompilací dotazů.
Alternativně můžete určit, že jeden dotaz a všechny ostatní, které jsou syntakticky ekvivalentní, ale liší se pouze v jejich hodnotách parametrů, budou parametrizovány.
Návod
Při použití řešení mapování Object-Relational (ORM), jako je Entity Framework (EF), nemusí být dotazy aplikací, jako jsou ruční stromy dotazů LINQ nebo některé nezpracované dotazy SQL, parametrizovány, což má vliv na opětovné použití plánu a schopnost sledovat dotazy v úložišti dotazů. Další informace naleznete v části Ukládání dotazů EF do mezipaměti a parametrizace a EF dotazy v surovém SQL.
Vynucená parametrizace
Výchozí jednoduché parametrizační chování SQL Serveru můžete přepsat zadáním, že všechny příkazy SELECT, INSERT, UPDATE a DELETE v databázi byly parametrizovány, s výhradou určitých omezení. Vynucená parametrizace je povolena nastavením možnosti PARAMETERIZATION na FORCED v příkazu ALTER DATABASE. Vynucené parametrizace může zlepšit výkon určitých databází snížením frekvence kompilací dotazů a rekompilacemi. Databáze, které mohou těžit z vynucené parametrizace, jsou obecně ty, které mají vysoké objemy souběžných dotazů ze zdrojů, jako jsou aplikace typu point-of-sale.
Pokud je možnost PARAMETERIZATION nastavena na FORCED, jakákoli hodnota literálu, která se objeví v příkazu SELECT, INSERT, UPDATE, nebo DELETE, odeslaném v libovolné formě, je během kompilace dotazu převedena na parametr. Výjimky jsou literály, které se zobrazují v následujících konstruktorech dotazu:
-
INSERT...EXECUTEvýroky. - Příkazy uvnitř těchto uložených procedur, triggerů nebo uživatelsky definovaných funkcí. SQL Server už pro tyto rutiny opakovaně používá plány dotazů.
- Připravené příkazy, které už byly parametrizovány v aplikaci na straně klienta.
- Příkazy, které obsahují volání metody XQuery, kde se metoda zobrazí v kontextu, kde jeho argumenty by obvykle byly parametrizovány, například
WHEREklauzule. Pokud se metoda zobrazí v kontextu, kde jeho argumenty nebudou parametrizovány, zbytek příkazu je parametrizován. - Příkazy uvnitř kurzoru Transact-SQL. (
SELECTpříkazy uvnitř kurzorů rozhraní API jsou parametrizovány.) - Zastaralé konstrukce dotazů.
- Libovolný příkaz, který je spuštěn v kontextu
ANSI_PADDINGneboANSI_NULLSkde je nastavenoOFF. - Příkazy, které obsahují více než 2 097 literálů, které mají nárok na parametrizaci.
- Příkazy, které odkazují na proměnné, například
WHERE T.col2 >= @bb. - Výrazy, které obsahují dotazovací nápovědu
RECOMPILE. - Příkazy, které obsahují klauzuli
COMPUTE. - Příkazy, které obsahují klauzuli
WHERE CURRENT OF.
Kromě toho nejsou parametrizovány následující klauzule dotazu. V těchto případech nejsou parametrizovány pouze klauzule. Jiné klauzule v rámci stejného dotazu mohou být způsobilé pro vynucené parametrizace.
- Select_list <> libovolného
SELECTpříkazu. To zahrnujeSELECTseznamy poddotazů aSELECTseznamů uvnitřINSERTpříkazů. - Poddotazové výrazy
SELECT, které se objeví uvnitřIFvýrazu. - Klauzule
TOP,TABLESAMPLE,HAVING,GROUP BY,ORDER BY,OUTPUT...INTOneboFOR XMLdotazu. - Argumenty, buď přímé, nebo jako dílčí výrazy, k
OPENROWSET,OPENQUERY,OPENDATASOURCE,OPENXML, nebo jakýkoliFULLTEXToperátor. - Argumenty vzoru a escape_character v klauzuli
LIKE. - Argument stylu klauzule
CONVERT. - Celočíselné konstanty uvnitř
IDENTITYklauzule. - Konstanty zadané pomocí syntaxe rozšíření ODBC
- Výrazy, které lze konstantně vyhodnotit a které jsou argumenty operátorů
+,-,*,/a%. Při zvažování oprávněnosti vynucené parametrizace považuje SQL Server výraz za konstantně složitelný, pokud platí alespoň jedna z následujících podmínek:- Ve výrazu se nezobrazují žádné sloupce, proměnné ani poddotazy.
- Výraz obsahuje klauzuli
CASE.
- Argumenty pro klauzule nápovědy dotazu Patří mezi ně number_of_rows argument
FASTnápovědy dotazu, number_of_processors argumentMAXDOPnápovědy dotazu a číselný argument nápovědyMAXRECURSIONdotazu.
Parametrizace probíhá na úrovni jednotlivých příkazů Transact-SQL. Jinými slovy, jednotlivé výroky v dávce jsou parametrizovány. Po kompilaci se parametrizovaný dotaz spustí v kontextu dávky, ve které byl původně odeslán. Pokud je plán provádění dotazu uložen v mezipaměti, můžete určit, zda byl dotaz parametrizován odkazem na sloupec sys.syscacheobjects SQL zobrazení dynamické správy. Pokud je dotaz parametrizován, názvy a datové typy parametrů přicházejí před text odeslané dávky v tomto sloupci, například (@1 tinyint).
Poznámka:
Názvy parametrů jsou libovolné. Uživatelé nebo aplikace by se neměli spoléhat na konkrétní pořadí pojmenování. Mezi verzemi upgradů SQL Server a kumulativní aktualizací (CU) se také může změnit následující: názvy parametrů, volba literálů, které jsou parametrizovány, a mezery v parametrizovaném textu.
Datové typy parametrů
Když SQL Server parametrizuje literály, parametry se převedou na následující datové typy:
- Celé literály, jejichž velikost by se jinak vešla do datového typu int, se parametrizují na int. Větší celé literály, které jsou součástí predikátů zahrnujících jakýkoli relační operátor (včetně
<,<=,=,!=,>,>=,!<,!>,<>,ALL,ANY,SOME,BETWEENaIN), se parametrizují na numeric(38,0). Větší literály, které nejsou součástí predikátů zahrnujících operátory porovnání, se parametrizují na číselnou hodnotu s přesností právě tak velkou, aby odpovídala její velikosti, a měřítkem 0. - Pevné číselné literály, které jsou součástí predikátů zahrnujících porovnávací operátory, se parametrizují na číselnou hodnotu s přesností 38 a měřítkem, které je právě dostatečné na podporu její velikosti. Číselné literály s pevnými body, které nejsou součástí predikátů, které zahrnují relační operátory parametrizované na číselnou hodnotu, jejichž přesnost a měřítko jsou dostatečně velké, aby podporovaly jeho velikost.
- Číselné literály s plovoucí desetinnou čárkou se vyhodnocují jako float(53).
- Řetězcové literály jiné než Unicode parametrizují varchar(8000), pokud se literál vejde do 8 000 znaků a varchar(max), pokud je větší než 8 000 znaků.
- Řetězcové literály Unicode se parametrizují na nvarchar(4000), pokud se literál vejde do 4 000 znaků Unicode, a na nvarchar(max), pokud je literál větší než 4 000 znaků.
- Binární literály parametrizují na varbinary(8000), pokud literál zapadá do 8 000 bajtů. Pokud je větší než 8 000 bajtů, převede se na varbinary(max).
- Literály typu peníze se parametrizují na peněžní hodnoty.
Pokyny pro použití vynucené parametrizace
Při nastavení možnosti PARAMETERIZATION na VYNUCENÍ zvažte následující:
- Vynucené parametrizace ve výsledku změní literální konstanty v dotazu na parametry při kompilaci dotazu. Optimalizátor dotazů proto může zvolit neoptimální plány pro dotazy. Optimalizátor dotazů je konkrétně méně pravděpodobné, že se dotaz shoduje s indexovaným zobrazením nebo indexem ve počítaném sloupci. Může také zvolit neoptimální plány dotazů v dělených tabulkách a distribuovaných rozdělených zobrazeních. Vynucená parametrizace by se neměla používat pro prostředí, která se silně spoléhají na indexovaná zobrazení a indexy na výpočtové sloupce. Obecně platí, že tuto
PARAMETERIZATION FORCEDmožnost by měli používat pouze zkušení odborníci na databáze po určení, že to nemá nepříznivý vliv na výkon. - Distribuované dotazy, které odkazují na více než jednu databázi, mají nárok na vynucenou parametrizaci, pokud je tato možnost nastavená na
PARAMETERIZATIONv databázi, v jejímž kontextu dotaz běží. - Nastavení možnosti
PARAMETERIZATIONnaFORCEDvyprázdní všechny plány dotazů z mezipaměti plánu databáze, kromě těch, které se aktuálně kompilují, rekonpilují nebo běží. Plány pro dotazy, které se kompilují nebo spouští během změny nastavení, se parametrizují při příštím spuštění dotazu. - Nastavení této
PARAMETERIZATIONmožnosti je online operace, která nevyžaduje žádné výhradní zámky na úrovni databáze. - Aktuální nastavení
PARAMETERIZATIONtéto možnosti se zachová při opětovném připojení nebo obnovení databáze.
Chování nucené parametrizace můžete přepsat tím, že určíte použití jednoduché parametrizace na jeden dotaz a všechny ostatní, které jsou syntakticky ekvivalentní, ale liší se pouze v hodnotách parametrů. Naopak můžete určit, že vynucená parametrizace bude provedena pouze na sadě syntakticky ekvivalentních dotazů, i když je vynucená parametrizace v databázi zakázána. K tomuto účelu se používají příručky plánu.
Poznámka:
Pokud je možnost PARAMETERIZATION nastavena na FORCED, hlášení chybových zpráv se může lišit od situace, kdy je možnost PARAMETERIZATION nastavena na SIMPLE: více chybových zpráv může být hlášeno v rámci vynucené parametrizace, zatímco méně zpráv by bylo hlášeno v rámci jednoduché parametrizace a čísla řádků, ve kterých k chybám dochází, mohou být hlášena nesprávně.
Příprava příkazů SQL
Relační modul SQL Serveru zavádí úplnou podporu pro přípravu příkazů Transact-SQL před jejich spuštěním. Pokud aplikace musí několikrát spustit příkaz Transact-SQL, může použít rozhraní API databáze k provedení následujících kroků:
- Připravte prohlášení pouze jednou. Tím se zkompiluje příkaz Transact-SQL do plánu provádění.
- Spusťte předkompilovaný plán provádění pokaždé, když musí provést příkaz. Tím se zabrání opětovnému kompilaci příkazu Transact-SQL při každém spuštění po prvním spuštění. Příprava a spouštění příkazů se řídí funkcemi a metodami rozhraní API. Není součástí jazyka Transact-SQL. Model přípravy/spuštění příkazů Transact-SQL je podporován zprostředkovatelem OLE DB nativního klienta SQL Server a ovladačem ODBC nativního klienta SQL Server. Při přípravě požadavku buď zprostředkovatel, nebo ovladačem pošle příkaz SQL Serveru s požadavkem na přípravu příkazu. SQL Server zkompiluje plán provádění a vrátí popisovač daného plánu poskytovateli nebo ovladači. Při provedení požadavku zašle poskytovatel nebo ovladač serveru žádost na provedení plánu, který je přidružený k popisovači.
Připravené příkazy nelze použít k vytváření dočasných objektů na SQL Serveru. Připravené příkazy nemůžou odkazovat na systémové uložené procedury, které vytvářejí dočasné objekty, jako jsou dočasné tabulky. Tyto postupy se musí provést přímo.
Nadměrné využití modelu přípravy/spuštění může snížit výkon. Pokud se příkaz provede jen jednou, přímé provedení vyžaduje pouze jednu cestu po síti na server a zpět. Příprava a spuštění příkazu Transact-SQL, který je spuštěn pouze jednou, vyžaduje dodatečnou síťovou komunikaci; jednu komunikaci na přípravu příkazu a jednu na jeho provedení.
Příprava příkazu je efektivnější, pokud se použijí značky parametrů. Předpokládejme například, že aplikace je občas požádána k načtení informací o produktu z AdventureWorks ukázkové databáze. Existují dva způsoby, jak to může aplikace provést.
Pomocí prvního způsobu může aplikace spustit samostatný dotaz pro každý požadovaný produkt:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductID = 63;
Pomocí druhého způsobu aplikace provede následující:
Připraví příkaz, který obsahuje značku parametru (?):
SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductID = ?;Připojí proměnnou programu k parametrickému ukazateli.
Pokaždé, když jsou potřebné informace o produktu, dosadí do vázané proměnné hodnotu klíče a provede každý příkaz.
Druhý způsob je efektivnější při provádění příkazu více než třikrát.
V SQL Serveru nemá model přípravy/spuštění žádnou významnou výhodu výkonu oproti přímému spuštění, protože SQL Server opakovaně používá plány provádění. SQL Server má efektivní algoritmy pro porovnávání aktuálních Transact-SQL příkazů s plány provádění, které jsou generovány pro předchozí spuštění stejného příkazu Transact-SQL. Pokud aplikace spustí příkaz Transact-SQL se značkami parametrů několikrát, SQL Server znovu použije plán provádění z prvního spuštění pro druhé a následné spuštění (pokud plán nesáhne od mezipaměti plánu). Přípravný a spouštěcí model má stále tyto výhody:
- Nalezení plánu provádění pomocí identifikačního popisovače je efektivnější než algoritmy pro spárování Transact-SQL příkazu s existujícími plány provádění.
- Aplikace může řídit, kdy se plán provádění vytvoří a kdy se znovu použije.
- Model prepare/execute je přenosný do jiných databází, včetně dřívějších verzí SQL Serveru.
Citlivost parametrů
Citlivost parametrů, označovaná také jako "parametr sniffing", odkazuje na proces, při kterém SQL Server během kompilace nebo rekompilace přenese aktuální hodnoty parametrů a předá ho optimalizátoru dotazů, aby bylo možné je použít k vygenerování potenciálně efektivnějších plánů provádění dotazů.
Hodnoty parametrů se při kompilaci nebo rekompilaci zachycují pro následující typy dávek:
- Uložené procedury
- Dotazy odeslané prostřednictvím
sp_executesql - Připravené dotazy
Další informace o řešení potíží s zašifrováním parametrů najdete v tématu:
- Zkoumání a řešení problémů citlivých na parametry
- Parametry a opětovné použití plánu vykonávání
- Optimalizace plánu citlivého na parametry
- Řešení potíží s dotazy s plánem spouštění dotazů citlivým na parametry ve službě Azure SQL Database
- Řešení potíží s dotazy s plánem spouštění dotazů citlivým na parametry ve službě Azure SQL Managed Instance
Když dotaz na SQL Serveru použije nápovědu OPTION (RECOMPILE) , optimalizátor dotazů změní parametr a místní proměnné na konstanty kompilačního času, které se dají neustále skládat a snižovat na literály. To znamená, že optimalizátor během kompilace ví a může použít aktuální hodnoty parametrů a místních proměnných, jak existují těsně před tímto příkazem. OPTION (RECOMPILE) umožňuje optimalizátoru vygenerovat optimální plán dotazů přizpůsobený konkrétním hodnotám a využít nejlepších podkladových indexů za běhu. U parametrů tento proces neodkazuje na hodnoty, které byly původně předány dávce nebo uložené proceduře, ale jejich hodnoty v době rekompilace. Tyto hodnoty mohly být změněny v rámci postupu před dosažením příkazu, který obsahuje RECOMPILE. Toto chování může zlepšit výkon dotazů s vysoce proměnlivými nebo nerovnoměrnými vstupními daty.
Místní proměnné
Když dotaz používá místní proměnné, SQL Server nemůže v době kompilace otestovat jejich hodnoty, odhadne kardinalitu pomocí dostupných statistik nebo heuristik. Pokud existují statistiky, obvykle používá hodnotu Veškerá hustota (označovaná také jako průměrná hustota) ze statistického histogramu k odhadu, kolik řádků odpovídá predikátu. Pokud však nejsou pro sloupec k dispozici žádné statistiky, SQL Server se vrátí k heuristickým odhadům, jako je například předpokladem selektivita 10% pro predikáty rovnosti, a selektivita 30% pro nerovnosti a rozsahy, což může vést k méně přesným plánům provádění. Tady je příklad dotazu, který používá místní proměnnou.
DECLARE @ProductId INT = 100;
SELECT * FROM Products WHERE ProductId = @ProductId;
V takovém případě SQL Server k optimalizaci dotazu nepoužívá hodnotu 100. Používá obecný odhad.
Paralelní zpracování dotazů
SQL Server poskytuje paralelní dotazy pro optimalizaci operací spouštění a indexování dotazů pro počítače, které mají více než jeden mikroprocesor (CPU). Vzhledem k tomu, že SQL Server může paralelně provádět operaci dotazu nebo indexu pomocí několika pracovních vláken operačního systému, je možné operaci rychle a efektivně dokončit.
Během optimalizace dotazů SQL Server hledá dotazy nebo operace indexu, které můžou těžit z paralelního spouštění. U těchto dotazů SQL Server vloží operátory výměny do plánu provádění dotazů a připraví dotaz na paralelní spuštění. Operátor výměny je operátor v plánu provádění dotazů, který poskytuje správu procesů, redistribuci dat a řízení toku. Operátor výměny zahrnuje logické operátory Distribute Streams, Repartition Streams, a Gather Streams jako podtypy, z nichž jeden nebo více se může zobrazit ve výstupu Showplan plánu dotazu pro dotaz zpracovávaný paralelně.
Důležité
Některé konstrukty inhibují schopnost SQL Serveru využít paralelismus buď v celém plánu provádění, nebo v jeho části.
Konstrukty, které inhibují paralelismus, zahrnují:
Skalární UDFs
Další informace o skalárních uživatelem definovaných funkcích najdete v tématu Vytvoření uživatelem definovaných funkcí. Počínaje SQL Serverem 2019 (15.x) má databázový stroj SQL Serveru možnost vložit tyto funkce a odemknout použití paralelismu během zpracování dotazů. Další informace o vkládání skalárních UDF najdete v tématu Inteligentní zpracování dotazů v databázích SQL.vzdáleného dotazu
Další informace o vzdáleném dotazu naleznete v tématu Showplan Logical and Physical Operators Reference.Dynamické kurzory
Další informace o kurzorech naleznete v tématu DEKLAROVÁNÍ KURZORU.Rekurzivní dotazy
Další informace o rekurzi najdete v tématu Pokyny pro definování a použití rekurzivních běžných tabulkových výrazů a rekurzev T-SQL.Funkce vracející tabulku s vícero příkazy (MSTVFs)
Další informace o MSTVFs naleznete viz Vytvoření uživatelsky definovaných funkcí (databázový stroj).Klíčové slovo TOP
Další informace naleznete v tématu TOP (Transact-SQL).
Plán provádění dotazu může obsahovat Atribut NonParallelPlanReason v elementu QueryPlan , který popisuje, proč se nepoužíval paralelismus. Mezi hodnoty tohoto atributu patří:
| NonParallelPlanReason – hodnota | Popis |
|---|---|
| MaxDOPSetToOne | Maximální stupeň paralelismu nastavený na hodnotu 1. |
| OdhadovanýDOPjeJeden | Odhadovaný stupeň paralelismu je 1. |
| Bez Paralelního Dotazu S Vzdáleným Serverem | U vzdálených dotazů se nepodporuje paralelismus. |
| NoParallelDynamicCursor | Paralelní plány nejsou podporovány pro dynamické kurzory. |
| Bez Paralelního Kurzorového Předběhu | Paralelní plány nejsou podporovány pro kurzory rychlého posuvu. |
| Žádné paralelní získávání kurzoru podle záložky | Paralelní plány nejsou podporovány pro kurzory, které se načítají záložkou. |
| Vytváření indexů paralelně není povoleno v neenterprisní edici | Paralelní vytváření indexů není podporováno pro edici jiné verze než Enterprise. |
| Žádné paralelní plány v edici Desktop nebo Express | Paralelní plánování není podporováno v edici Desktop a Express. |
| NeparalelizovatelnáIntrinsickáFunkce | Dotaz odkazuje na vnitřní funkci, která není paralelizovatelná. |
| CLR požadovaná uživatelská funkce vyžaduje přístup k datům | Paralelismus není podporován pro UDF CLR, který vyžaduje přístup k datům. |
| Uživatem definované funkce TSQL nejsou paralelizovatelné | Dotaz odkazuje na uživatelem definovanou funkci T-SQL, která nebyla paralelizovatelná. |
| TransakceSProměnnýmiTabulkyNepodporujíParalelníVnořenéTransakce | Transakce tabulkových proměnných nepodporují vnořené paralelní transakce. |
| DMLQueryReturnsOutputToClient | Dotaz DML vrací výstup klientovi a není paralelizovatelný. |
| Smíšené sériové a paralelní online sestavení indexu není podporováno | Nepodporovaná kombinace sériových a paralelních plánů pro sestavení jednoho online indexu. |
| NelzeVytvořitPlatnýParalelníPlán | Ověřování paralelního plánu selhalo, přechod zpět na sériový plán. |
| Žádné paralely pro paměťově optimalizované tabulky | Paralelismus není podporován pro odkazované tabulky In-Memory OLTP. |
| Funkce 'NoParallelForDmlOnMemoryOptimizedTable' (žádná paralelizace pro DML na paměťově optimalizované tabulce) | Paralelismus není podporován pro DML v tabulce In-Memory OLTP. |
| Žádné paralelní zpracování pro nativně zkompilovaný modul | Paralelismus není podporován pro odkazované na nativně kompilované moduly. |
| ŽádnéRozsahyObnovitelnéVytvoření | Generování rozsahu selhalo u operace obnoveného vytvoření. |
Po vložení operátorů výměny je výsledkem plán provádění paralelního dotazu. Plán provádění paralelních dotazů může používat více než jedno pracovní vlákno. Plán sériového spuštění, který používá neběžný (sériový) dotaz, používá ke spuštění pouze jedno pracovní vlákno. Skutečný počet pracovních vláken používaných paralelním dotazem je určen při inicializaci spuštění plánu dotazu a je určen složitostí plánu a stupněm paralelismu.
Stupeň paralelismu (DOP) určuje maximální počet procesorů, které se používají; neznamená počet používaných pracovních vláken. Limit DOP je nastavený na každou úlohu. Nejedná se o limit na každý požadavek nebo dotaz. To znamená, že během paralelního spuštění dotazu může jeden požadavek vytvořit více úloh, které jsou přiřazeny plánovači. V jakémkoli okamžiku provádění dotazu může být současně použito více procesorů, než kolik specifikuje MAXDOP, když se spustí různé úlohy současně. Další informace naleznete v Příručce k architektuře vláken a úloh.
Optimalizátor dotazů SQL Serveru nepoužívá pro dotaz plán paralelního spouštění, pokud platí některá z následujících podmínek:
- Plán sériového spuštění je triviální nebo nepřekračuje prahovou hodnotu nákladů pro nastavení paralelismu.
- Plán sériového spuštění má nižší celkové odhadované náklady podstromu než jakýkoli paralelní plán spuštění prozkoumaný optimalizátorem.
- Dotaz obsahuje skalární nebo relační operátory, které nejde spustit paralelně. Některé operátory mohou způsobit spuštění části plánu dotazu v sériovém režimu nebo celý plán spustit v sériovém režimu.
Poznámka:
Celkové odhadované náklady na podstromy paralelního plánu můžou být nižší než prahová hodnota nákladů pro nastavení paralelismu. To znamená, že celkové odhadované náklady podstromu sériového plánu tyto náklady překročily, a plán dotazu s nižšími celkovými odhadovanými náklady podstromu byl vybrán.
Stupeň paralelismu (DOP)
SQL Server automaticky rozpozná nejlepší stupeň paralelismu pro každou instanci operace paralelního spouštění dotazů nebo jazyka DDL (Index Data Definition Language). Provede to na základě následujících kritérií:
Zda sql Server běží na počítači, který má více než jeden mikroprocesor nebo procesor, například symetrický multiprocessingový počítač (SMP). Paralelní dotazy můžou používat jenom počítače, které mají více než jeden procesor.
Zda je k dispozici dostatečný počet pracovních vláken. Každá operace dotazu nebo indexu vyžaduje spuštění určitého počtu pracovních vláken. Provádění paralelního plánu vyžaduje více pracovních vláken než sériový plán a počet požadovaných pracovních vláken se zvyšuje o stupeň paralelismu. Pokud požadavek pracovního vlákna paralelního plánu pro určitý stupeň paralelismu nelze splnit, databázový stroj SQL Serveru sníží stupeň paralelismu automaticky nebo zcela opustí paralelní plán v zadaném kontextu úlohy. Potom spustí sériový plán (jedno pracovní vlákno).
Typ dotazu nebo operace indexu. Indexovací operace, které vytvářejí nebo znovu sestavují index, nebo odstraňují clusterovaný index a dotazy, které používají cykly procesoru, jsou nejvhodnějšími kandidáty pro paralelní plán. Dobrými kandidáty jsou například spojení velkých tabulek, velkých agregací a řazení velkých sad výsledků. Jednoduché dotazy, často vyskytující se v aplikacích pro zpracování transakcí, zjistí, že dodatečná koordinace potřebná k paralelnímu provedení dotazu převažuje nad potenciálním zvýšením výkonu. Aby bylo možné rozlišovat mezi dotazy, které využívají paralelismus, a dotazy, které nemají prospěch, porovná databázový stroj SQL Serveru odhadované náklady na provedení operace dotazu nebo indexu s prahovou hodnotou nákladů pro hodnotu paralelismu . Uživatelé můžou změnit výchozí hodnotu 5 pomocí sp_configure , pokud správné testování zjistilo, že pro spuštěnou úlohu je vhodnější jiná hodnota.
Zda existuje dostatečný počet řádků ke zpracování. Pokud optimalizátor dotazů zjistí, že počet řádků je příliš nízký, nezavádí operátory výměny pro distribuci řádků. Operace jsou tedy prováděny sériově. Provádění operátorů v sériovém plánu zabraňuje scénářům, kdy náklady na spuštění, distribuci a koordinaci překračují zisky dosažené paralelním spuštěním operátoru.
Zda jsou k dispozici aktuální distribuční statistiky. Pokud nejvyšší stupeň paralelismu není možný, zvažují se nižší stupně před opuštěním paralelního plánu. Například při vytváření clusterovaného indexu v zobrazení nelze vyhodnotit statistiky distribuce, protože clusterovaný index ještě neexistuje. V tomto případě databázový stroj SQL Serveru nemůže poskytnout nejvyšší stupeň paralelismu pro operaci indexu. Některé operátory, jako je řazení a prohledávání, ale můžou i nadále těžit z paralelního provádění.
Poznámka:
Paralelní indexové operace jsou k dispozici pouze v edicích SQL Server Enterprise, Developer a Evaluation.
V době provádění databázový stroj SQL Serveru určuje, zda aktuální systémové úlohy a informace o konfiguraci dříve popsané umožňují paralelní spouštění. Pokud je zaručeno paralelní provádění, databázový stroj SQL Serveru určí optimální počet pracovních vláken a rozloží provádění paralelního plánu mezi tato pracovní vlákna. Když se spustí operace dotazu nebo indexu na více pracovních vláknech pro paralelní spuštění, použije se stejný počet pracovních vláken, dokud se operace nedokončí. Databázový stroj SQL Serveru znovu přehodnotí optimální počet pracovních vláken pokaždé, když je prováděcí plán získán z mezipaměti. Například jedno spuštění dotazu může vést k použití sériového plánu, pozdější spuštění stejného dotazu může vést k paralelnímu plánu pomocí tří pracovních vláken a třetí spuštění může vést k paralelnímu plánu pomocí čtyř pracovních vláken.
Operátory aktualizace a odstranění v plánu vykonávání dotazů paralelně se provádí sériově, ale klauzule WHERE příkazu UPDATE nebo DELETE se může spustit paralelně. Skutečné změny dat se poté postupně aplikují na databázi.
Až do SQL Serveru 2012 (11.x) se operátor vložení také spouští sériově. Část SELECT příkazu INSERT však může být spuštěna paralelně. Skutečné změny dat se poté postupně aplikují na databázi.
Počínaje SQL Serverem 2014 (12.x) a úrovní kompatibility databáze 110 SELECT ... INTO je možné příkaz spustit paralelně. Jiné formy operátorů vložení fungují stejným způsobem, jak je popsáno pro SQL Server 2012 (11.x).
Počínaje SQL Serverem 2016 (13.x) a úrovní kompatibility databáze 130 lze příkaz INSERT ... SELECT provést paralelně při vkládání do hald nebo clusterovaných columnstore indexů (CCI), a to s použitím náznaku TABLOCK. Vložení do místních dočasných tabulek (identifikovaných předponou #) a globálních dočasných tabulek (identifikovaných předponami ##) jsou také povoleny pro paralelismus pomocí nápovědy TABLOCK. Další informace naleznete v tématu INSERT (Transact-SQL).
Statické a klíčové kurzory můžou být naplněny plány paralelního spouštění. Chování dynamických kurzorů však může být poskytováno pouze sériovým spuštěním. Optimalizátor dotazů vždy generuje plán sériového spuštění pro dotaz, který je součástí dynamického kurzoru.
Překonání stupňů paralelismu
Stupeň paralelismu nastavuje počet procesorů, které se mají použít při paralelním provádění plánu. Tuto konfiguraci lze nastavit na různých úrovních:
Úroveň serveru s použitím možnostikonfigurace serveru
Platí pro: SQL ServerPoznámka:
SQL Server 2019 (15.x) zavádí automatická doporučení pro nastavení možnosti konfigurace serveru MAXDOP během procesu instalace. Uživatelské rozhraní nastavení umožňuje buď přijmout doporučená nastavení, nebo zadat vlastní hodnotu. Další informace najdete na stránce Konfigurace databázového stroje – MaxDOP.
Úroveň zatížení pomocí možnosti konfigurace skupiny pracovního zatížení MAX_DOP Správce prostředků. Platí pro: SQL Server
Úroveň databáze s použitím konfigurace s vymezeným oborem databázeMAXDOP.
Platí pro: SQL Server a Azure SQL DatabaseÚroveň dotazu nebo příkazu indexu, použití MAXDOPdotazového tipu nebo možnosti indexu MAXDOP K řízení můžete například použít možnost MAXDOP zvýšením nebo snížením počtu procesorů vyhrazených pro online operaci indexu. Tímto způsobem můžete vyrovnávat prostředky používané operací indexu s prostředky souběžných uživatelů.
Platí pro: SQL Server a Azure SQL Database
Nastavení maximálního stupně paralelismu na hodnotu 0 (výchozí) umožňuje SQL Serveru používat všechny dostupné procesory až do maximálního počtu 64 procesorů při provádění paralelního plánu. Ačkoli SQL Server nastaví při možnosti MAXDOP nastavené na 0 cílový počet modulu runtime na 64 logických procesorů, v případě potřeby může být ručně nastavena jiná hodnota. Nastavení maxDOP na 0 pro dotazy a indexy umožňuje SQL Serveru používat všechny dostupné procesory až do maximálního počtu 64 procesorů pro dané dotazy nebo indexy v paralelním spuštění plánu. MAXDOP není vynucená hodnota pro všechny paralelní dotazy, ale spíše nezávazný cíl pro všechny dotazy, které mají nárok na paralelismus. To znamená, že pokud není k dispozici dostatek pracovních vláken za běhu, může se dotaz spustit s nižším stupněm paralelismu než možnost konfigurace serveru MAXDOP.
Návod
Další informace najdete v tématu Doporučení MAXDOP pro pokyny ke konfiguraci MAXDOP na úrovni serveru, databáze, dotazu nebo nápovědy.
Příklad paralelního dotazu
Následující dotaz spočítá počet objednávek zadaných v určitém čtvrtletí počínaje 1. dubnem 2000, ve kterém zákazník obdržel alespoň jednu řádkovou položku objednávky později než datum potvrzení. Tento dotaz uvádí počet takových objednávek seskupených podle jednotlivých priorit objednávek a seřazených ve vzestupném pořadí priority.
V tomto příkladu se používají teoretické názvy tabulek a sloupců.
SELECT o_orderpriority, COUNT(*) AS Order_Count
FROM orders
WHERE o_orderdate >= '2000/04/01'
AND o_orderdate < DATEADD (mm, 3, '2000/04/01')
AND EXISTS
(
SELECT *
FROM lineitem
WHERE l_orderkey = o_orderkey
AND l_commitdate < l_receiptdate
)
GROUP BY o_orderpriority
ORDER BY o_orderpriority
Předpokládejme, že jsou v tabulkách lineitemorders definovány následující indexy:
CREATE INDEX l_order_dates_idx
ON lineitem
(l_orderkey, l_receiptdate, l_commitdate, l_shipdate)
CREATE UNIQUE INDEX o_datkeyopr_idx
ON ORDERS
(o_orderdate, o_orderkey, o_custkey, o_orderpriority)
Tady je jeden z možných paralelních plánů vygenerovaných pro dříve zobrazený dotaz:
|--Stream Aggregate(GROUP BY:([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=COUNT(*)))
|--Parallelism(Gather Streams, ORDER BY:
([ORDERS].[o_orderpriority] ASC))
|--Stream Aggregate(GROUP BY:
([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=Count(*)))
|--Sort(ORDER BY:([ORDERS].[o_orderpriority] ASC))
|--Merge Join(Left Semi Join, MERGE:
([ORDERS].[o_orderkey])=
([LINEITEM].[l_orderkey]),
RESIDUAL:([ORDERS].[o_orderkey]=
[LINEITEM].[l_orderkey]))
|--Sort(ORDER BY:([ORDERS].[o_orderkey] ASC))
| |--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([ORDERS].[o_orderkey]))
| |--Index Seek(OBJECT:
([tpcd1G].[dbo].[ORDERS].[O_DATKEYOPR_IDX]),
SEEK:([ORDERS].[o_orderdate] >=
Apr 1 2000 12:00AM AND
[ORDERS].[o_orderdate] <
Jul 1 2000 12:00AM) ORDERED)
|--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([LINEITEM].[l_orderkey]),
ORDER BY:([LINEITEM].[l_orderkey] ASC))
|--Filter(WHERE:
([LINEITEM].[l_commitdate]<
[LINEITEM].[l_receiptdate]))
|--Index Scan(OBJECT:
([tpcd1G].[dbo].[LINEITEM].[L_ORDER_DATES_IDX]), ORDERED)
Následující obrázek znázorňuje plán dotazu, který se provádí s stupněm paralelismu, který se rovná 4 a zahrnuje spojení se dvěma tabulkami.
Paralelní plán obsahuje tři operátory paralelismu. Operátor Vyhledávání v indexu o_datkey_ptr i operátor Skenování indexu l_order_dates_idx se provádějí paralelně. Výsledkem je několik exkluzivních streamů. To lze určit z nejbližších operátorů paralelismu, které jsou umístěny nad operátory Index Scan a Index Seek. Oba přerozdělují typ výměny. To znamená, že přeskupují data mezi datovými proudy a vytváří stejný počet datových proudů na výstupu, jako mají na vstupu. Tento počet datových proudů se rovná stupni paralelismu.
Operátor paralelismu nad operátorem l_order_dates_idx Index Scan přerozděluje své vstupní proudy pomocí hodnoty L_ORDERKEY jako klíče. Tímto způsobem skončí stejné hodnoty L_ORDERKEY ve stejném výstupním datovém proudu. Výstupní datové proudy současně udržují pořadí ve L_ORDERKEY sloupci tak, aby splňovaly vstupní požadavek operátoru Merge Join.
Operátor paralelismu nad operátorem Index Seek předěluje vstupní datové proudy pomocí hodnoty O_ORDERKEY. Vzhledem k tomu, že jeho vstup není seřazený podle hodnot sloupců O_ORDERKEY a jedná se o sloupec spojení v operátoru Merge Join, operátor Řazení mezi operátory paralelismu a slučovací spojení zajišťuje, že je vstup seřazený pro Merge Join operátor ve sloupcích spojení. Operátor Sort , jako je operátor Merge Join, se provádí paralelně.
Nejvrchnější operátor paralelismu shromažďuje výsledky z několika datových proudů do jednoho datového proudu. Částečné agregace prováděné operátorem Agregace datových proudů pod operátorem paralelismu se pak shromáždí do jedné SUM hodnoty pro každou jinou hodnotu operátoru agregace datového O_ORDERPRIORITY proudu nad operátorem paralelismu. Vzhledem k tomu, že tento plán má dva segmenty výměny, s stupněm paralelismu rovnajícím se 4, používá osm pracovních vláken.
Další informace o operátorech použitých v tomto příkladu najdete v tématu Odkaz na logické a fyzické operátory Showplan.
Paralelní operace indexu
Plány dotazů vytvořené pro operace indexu, které vytvářejí nebo znovu sestavují index, nebo odstraňují clusterovaný index, umožňují paralelní operace s více pracovními vlákny na počítačích, které mají více mikroprocesorů.
Poznámka:
Paralelní indexové operace jsou dostupné jenom v edici edice Enterprise počínaje SQL Serverem 2008 (10.0.x).
SQL Server používá stejné algoritmy k určení stupně paralelismu (celkový počet samostatných pracovních vláken ke spuštění) pro operace indexu stejně jako u jiných dotazů. Maximální stupeň paralelismu pro operaci indexu podléhá maximálnímu stupni konfigurace serveru paralelismu . Maximální stupeň paralelismu pro jednotlivé operace indexu můžete přepsat nastavením možnosti indexu MAXDOP v příkazech CREATE INDEX, ALTER INDEX, DROP INDEX a ALTER TABLE.
Když databázový stroj SQL Serveru sestaví plán provádění indexu, nastaví se počet paralelních operací na nejnižší hodnotu z následujících položek:
- Počet mikroprocesorů nebo procesorů v počítači.
- Číslo zadané v maximálním stupni konfigurace serveru paralelismu.
- Počet procesorů, které ještě nejsou nad prahovou hodnotou práce provedených pro pracovní vlákna SQL Serveru.
Například na počítači, který má osm procesorů, ale kde je maximální stupeň paralelismu nastaven na 6, ne více než šest paralelních pracovních vláken jsou generovány pro operaci indexu. Pokud pět procesorů v počítači překročí prahovou hodnotu sql Serveru při sestavení plánu provádění indexu, plán provádění určuje pouze tři paralelní pracovní vlákna.
Mezi hlavní fáze paralelní operace indexu patří:
- Koordinující pracovní vlákno rychle a náhodně prohledá tabulku, aby odhadla distribuci klíčů indexu. Koordinující pracovní vlákno vytvoří klíčové hranice, které vytvoří počet rozsahů klíčů, které se budou rovnat stupni paralelních operací, kde se odhaduje, že každá oblast klíčů bude zahrnovat podobný počet řádků. Pokud jsou v tabulce například čtyři miliony řádků a stupeň paralelismu je 4, koordinační pracovní vlákno určí klíčové hodnoty, které odděluje čtyři sady řádků s 1 milionem řádků v každé sadě. Pokud není možné navázat dostatek rozsahů klíčů pro použití všech procesorů, stupeň paralelismu se odpovídajícím způsobem sníží.
- Koordinující pracovní vlákno spustí množství pracovních vláken rovnající se stupni paralelních operací a čeká na jejich dokončení. Každé pracovní vlákno prohledá základní tabulku pomocí filtru, který načte pouze řádky s klíčovými hodnotami v rozsahu přiřazeného pracovnímu vláknu. Každé pracovní vlákno vytvoří strukturu indexu pro řádky v jeho rozsahu klíčů. V případě děleného indexu vytvoří každé pracovní vlákno zadaný počet particí. Oddíly nejsou sdíleny mezi pracovními vlákny.
- Po dokončení všech paralelních pracovních vláken koordinující pracovní vlákno spojí indexové části do jediného indexu. Tato fáze se vztahuje pouze na offline indexové operace.
Jednotlivé CREATE TABLE příkazy ALTER TABLE můžou mít několik omezení, která vyžadují vytvoření indexu. Tyto více operací vytváření indexů se provádí v řadě, i když každá jednotlivá operace vytvoření indexu může být paralelní operací v počítači s více procesory.
Architektura distribuovaných dotazů
Microsoft SQL Server podporuje dvě metody pro odkazování na heterogenní zdroje dat OLE DB v příkazech Transact-SQL:
Názvy propojených serverů
Systémové uložené procedurysp_addlinkedserverasp_addlinkedsrvloginslouží k pojmenování serveru zdroji dat OLE DB. Na objekty na těchto propojených serverech lze odkazovat v příkazech Transact-SQL pomocí čtyřdílných názvů. Pokud je například název propojenéhoDeptSQLSrvrserveru definovaný proti jiné instanci SQL Serveru, odkazuje následující příkaz na tabulku na tomto serveru:SELECT JobTitle, HireDate FROM DeptSQLSrvr.AdventureWorks2022.HumanResources.Employee;Název propojeného
OPENQUERYserveru lze také zadat v příkazu pro otevření sady řádků ze zdroje dat OLE DB. Na tuto sadu řádků se pak dá odkazovat jako na tabulku v Transact-SQL příkazech.Názvy ad hoc konektorů
U zřídka používaných odkazů na zdroj dat jsou funkceOPENROWSETneboOPENDATASOURCEzadány s informacemi potřebnými pro připojení k propojenému serveru. Na sadu řádků se pak dá odkazovat stejným způsobem jako na tabulku v příkazech Transact-SQL:SELECT * FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'c:\MSOffice\Access\Samples\Northwind.mdb';'Admin';''; Employees);
SQL Server používá OLE DB ke komunikaci mezi relačním modulem a modulem úložiště. Relační modul rozdělí každý příkaz Transact-SQL do řady operací na jednoduchých sadách řádků OLE DB otevřené modulem úložiště ze základních tabulek. To znamená, že relační modul může také otevřít jednoduché sady řádků OLE DB na jakémkoli zdroji dat OLE DB.
Relační modul používá aplikační programovací rozhraní OLE DB (API) k otevření sad řádků na propojených serverech, načtení řádků a správu transakcí.
Pro každý zdroj dat OLE DB, ke který se přistupuje jako propojený server, musí být na serveru s SQL Serverem přítomen zprostředkovatel OLE DB. Sada Transact-SQL operací, které lze použít pro konkrétní zdroj dat OLE DB, závisí na možnostech zprostředkovatele OLE DB.
Pro každou instanci SQL Serveru můžou členové sysadmin pevné role serveru povolit nebo zakázat použití názvů ad hoc konektorů pro zprostředkovatele OLE DB pomocí vlastnosti SQL Server DisallowAdhocAccess . Pokud je povolený ad hoc přístup, může každý uživatel přihlášený k této instanci spouštět příkazy Transact-SQL obsahující názvy ad hoc konektorů, odkazující na jakýkoli zdroj dat v síti, ke kterému je možné získat přístup pomocí zprostředkovatele OLE DB. Pokud chcete řídit přístup ke zdrojům dat, můžou členové role zakázat ad hoc přístup pro tohoto zprostředkovatele OLE DB, a tím omezit uživatele pouze na tyto zdroje dat, na které odkazují názvy propojených sysadmin serverů definované správci. Ve výchozím nastavení je pro zprostředkovatele OLE DB SYSTÉMU SQL Server povolený ad hoc přístup a pro všechny ostatní zprostředkovatele OLE DB je zakázaný.
Distribuované dotazy můžou uživatelům umožnit přístup k jinému zdroji dat (například k souborům, nerelačním zdrojům dat, jako je služba Active Directory atd.), a to pomocí kontextu zabezpečení účtu Microsoft Windows, pod kterým je služba SQL Server spuštěná. SQL Server zosobňuje přihlášení odpovídajícím způsobem pro přihlášení systému Windows; to ale není možné pro přihlášení k SQL Serveru. To může potenciálně umožnit uživateli distribuovaného dotazu přístup k jinému zdroji dat, pro který nemá oprávnění, ale účet, pod kterým je spuštěná služba SQL Serveru, má oprávnění. Slouží sp_addlinkedsrvlogin k definování konkrétních přihlášení, která mají oprávnění pro přístup k odpovídajícímu propojenému serveru. Tento ovládací prvek není k dispozici pro ad hoc názvy, proto buďte opatrní při povolování zprostředkovatele OLE DB pro ad hoc přístup.
Pokud je to možné, SQL Server odešle relační operace, jako jsou spojení, omezení, projekce, řazení a seskupení podle operací do zdroje dat OLE DB. SQL Server ve výchozím nastavení neskenuje základní tabulku a neprovádí relační operace sám. SQL Server se dotazuje zprostředkovatele OLE DB, aby určil úroveň gramatiky SQL, kterou podporuje, a na základě těchto informací odešle poskytovateli co nejvíce relačních operací.
SQL Server určuje mechanismus pro zprostředkovatele OLE DB, který vrátí statistiku označující způsob distribuce hodnot klíčů v rámci zdroje dat OLE DB. To umožňuje optimalizátoru dotazů SQL Serveru lépe analyzovat vzor dat ve zdroji dat s ohledem na požadavky každého příkazu Transact-SQL, což zvyšuje schopnost Optimalizátoru dotazů generovat optimální plány provádění.
Vylepšení zpracování dotazů u dělených tabulek a indexů
SQL Server 2008 (10.0.x) vylepšil výkon zpracování dotazů u dělených tabulek pro mnoho paralelních plánů, změnil způsob znázornění paralelních a sériových plánů a rozšířil informace o dělení uvedené v plánech provádění za běhu i kompilace. Tento článek popisuje tato vylepšení, poskytuje pokyny, jak interpretovat plány spouštění dotazů dělených tabulek a indexů a poskytuje osvědčené postupy pro zlepšení výkonu dotazů u dělených objektů.
Poznámka:
Až do verze SQL Server 2014 (12.x) se dělené tabulky a indexy podporují jenom v edicích SQL Server Enterprise, Developer a Evaluation. Počínaje SQL Serverem 2016 (13.x) SP1 se v edici SQL Server Standard podporují také dělené tabulky a indexy.
Nová operace hledání citlivá na oddíly
V SQL Serveru se interní reprezentace dělené tabulky změní tak, aby se v procesoru dotazů zobrazila vícesloupcová index s úvodním sloupcem PartitionID .
PartitionID je skrytý počítaný sloupec, který interně představuje ID oddílu obsahujícího konkrétní řádek. Předpokládejme například, že tabulka T, definovaná jako T(a, b, c), je rozdělena podle sloupce a a má clusterovaný index na sloupci b. V SQL Serveru se tato dělená tabulka interně považuje za nedílnou tabulku se schématem T(PartitionID, a, b, c) a clusterovaným indexem složeného klíče (PartitionID, b). Optimalizátor dotazů tak může provádět operace hledání na PartitionID základě libovolné dělené tabulky nebo indexu.
Eliminace oddílu se teď provádí v této vyhledávací operaci.
Optimalizátor dotazů je navíc rozšířený tak, aby operace hledání nebo prohledávání s jednou podmínkou mohla být provedena PartitionID (jako logický počáteční sloupec) a případně i u dalších sloupců s klíčem indexu a následné hledání druhé úrovně s jinou podmínkou, je možné provést u jednoho nebo více dalších sloupců pro každou jedinečnou hodnotu, která splňuje kvalifikaci pro operaci hledání první úrovně. To znamená, že tato operace označovaná jako přeskočit prohledávání umožňuje optimalizátoru dotazů provést operaci hledání nebo prohledávání na základě jedné podmínky, aby určila, ke kterým oddílům se má přistupovat, a operace hledání indexu druhé úrovně v rámci tohoto operátoru vrací řádky z těchto oddílů, které splňují jinou podmínku. Představte si například následující dotaz.
SELECT * FROM T WHERE a < 10 and b = 2;
V tomto příkladu předpokládejme, že tabulka T, definovaná jako T(a, b, c), je rozdělena na sloupec a, a má clusterovaný index ve sloupci b. Hranice oddílů tabulky T jsou definovány následující funkcí oddílu:
CREATE PARTITION FUNCTION myRangePF1 (int) AS RANGE LEFT FOR VALUES (3, 7, 10);
Aby bylo možné tento dotaz vyřešit, procesor dotazu provede operaci hledání na první úrovni, aby našel každý oddíl obsahující řádky, které splňují podmínku T.a < 10. Tím se identifikují oddíly, ke které se mají přistupovat. V rámci každého identifikovaného oddílu pak procesor provede hledání druhé úrovně do clusterovaného indexu ve sloupci b a najde řádky, které splňují podmínku T.b = 2 a T.a < 10.
Následující ilustrace je logickým zobrazením operace skip scan. Zobrazuje tabulku T s daty ve sloupcích a a b. Oddíly jsou očíslovány od 1 do 4 s hranicemi oddílů zobrazenými přerušovanými svislými čarami. Operace hledání na první úrovni pro oddíly (nezobrazuje se na obrázku) zjistila, že oddíly 1, 2 a 3 splňují podmínku hledání předpokládanou dělením definovanou pro tabulku a predikát ve sloupci a. To znamená, T.a < 10. Cesta, kterou prochází část vyhledávání na druhé úrovni operace přeskočení skenování, je znázorněna zakřivenou čárou. V podstatě operace skenování přeskočením vyhledává v každém z těchto oddílů řádky, které splňují podmínku b = 2. Celkové náklady na operaci přeskakování prohledávání jsou stejné jako u tří samostatných hledání indexů.
Zobrazení informací o particionování v plánech zpracování dotazů
Plány provádění dotazů na dělené tabulky a indexy je možné zkoumat pomocí příkazů Transact-SQL SETSET SHOWPLAN_XML nebo SET STATISTICS XMLpomocí grafického výstupu plánu provádění v aplikaci SQL Server Management Studio. Plán provádění v době kompilace můžete zobrazit například tak, že na panelu nástrojů Editoru dotazů vyberete Možnost Zobrazit odhadovaný plán provádění a plán běhu výběrem možnosti Zahrnout skutečný plán provádění.
Pomocí těchto nástrojů můžete zjistit následující informace:
- Operace, jako
scans,seeks,inserts,updates,mergesadeletes, které přistupují k děleným tabulkám nebo indexům. - Oddíly, k nimž dotaz přistupuje. Například celkový počet oddílů, ke kterým se přistupuje, a rozsahy souvislých oddílů, ke kterým se přistupuje, jsou k dispozici v plánech spuštění za běhu.
- Pokud se operace přeskočení kontroly použije v operaci hledání nebo prohledávání k načtení dat z jednoho nebo více oddílů.
Vylepšení informací o oddílech
SQL Server poskytuje rozšířené informace o particionování pro plány provádění jak během kompilace, tak i během spuštění. Plány provádění teď poskytují následující informace:
- Volitelný
Partitionedatribut, který označuje, že operátor, napříkladseek,scan,insert,update,mergenebodelete, se provádí v dělené tabulce. - Nový
SeekPredicateNewprvek s dílčím prvkemSeekKeys, který obsahujePartitionIDjako úvodní indexový klíčový sloupec a podmínky filtru, které určují rozsah hledání vPartitionID. Přítomnost dvouSeekKeyspodsložek naznačuje použití operace přeskokového skenování naPartitionID. - Souhrnné informace, které poskytují celkový počet přístupných oddílů. Tyto informace jsou k dispozici pouze v běhových plánech.
Chcete-li předvést, jak se tyto informace zobrazují ve výstupu grafického plánu provádění i výstupu showplan XML, zvažte následující dotaz na dělenou tabulku fact_sales. Tento dotaz aktualizuje data ve dvou oddílech.
UPDATE fact_sales
SET quantity = quantity - 2
WHERE date_id BETWEEN 20080802 AND 20080902;
Následující obrázek znázorňuje vlastnosti operátora Clustered Index Seek v plánu provádění modulu runtime pro tento dotaz. Pokud chcete zobrazit definici fact_sales tabulky a definici oddílu, přečtěte si část "Příklad" v tomto článku.

Dělený atribut
Když je na dělené tabulce nebo indexu spuštěn operátor, jako je Index Seek, atribut Partitioned se objeví v plánu kompilace a za běhu a je nastaven na True (1). Atribut se nezobrazuje, když je nastavený na False (0).
Atribut Partitioned se může objevit v následujících fyzických a logických operátorech:
- Prohledávání tabulek
- Indexové skenování
- Prohledávání indexu
- Vložit
- Aktualizace
- Vymazat
- Sloučit
Jak je znázorněno na předchozím obrázku, tento atribut se zobrazí ve vlastnostech operátoru, ve kterém je definován. Ve výstupu XML Showplan se tento atribut zobrazí jako Partitioned="1" v RelOp uzlu operátoru, ve kterém je definován.
Nový predikát hledání
Ve výstupu XML Showplan se SeekPredicateNew prvek zobrazí v operátoru, ve kterém je definován. Může obsahovat až dva výskyty subelementu SeekKeys . První SeekKeys položka určuje operaci hledání na první úrovni na úrovni ID oddílu logického indexu. To znamená, že toto hledání určuje oddíly, ke kterým musí být přístup, aby splňovaly podmínky dotazu. Druhá SeekKeys položka specifikuje část operace přeskočení skenování na druhé úrovni vyhledávání, která se vyskytuje v rámci každé partition, jak byla identifikována v prvním stupni vyhledávání.
Souhrnné informace o oddílech
V plánech spouštění za běhu poskytují souhrnné informace o oddílech počet oddílů, ke kterých se přistupuje, a identitu skutečných oddílů, ke kterých se přistupuje. Tyto informace můžete použít k ověření, že správné oddíly jsou ve vyhledávacím dotazu přístupovány a všechny ostatní oddíly jsou vyřazeny z úvahy.
K dispozici jsou následující informace: Actual Partition Counta Partitions Accessed.
Actual Partition Count je celkový počet oddílů, ke kterým dotaz přistupuje.
Partitions Accessed, ve výstupu XML Showplan jsou souhrnné informace o oddílu, které se zobrazí v novém prvku RuntimePartitionSummary uzlu RelOp operátoru, kde je definován. Následující příklad ukazuje obsah elementu RuntimePartitionSummary , který označuje, že jsou přístupné dva celkové oddíly (oddíly 2 a 3).
<RunTimePartitionSummary>
<PartitionsAccessed PartitionCount="2" >
<PartitionRange Start="2" End="3" />
</PartitionsAccessed>
</RunTimePartitionSummary>
Zobrazení informací o oddílu pomocí jiných metod Showplan
Metody SHOWPLAN_ALL, SHOWPLAN_TEXT, a STATISTICS PROFILE neoznamují informace o oddílu popsané v tomto článku s následující výjimkou. V rámci SEEK predikátu jsou oddíly, ke které se má přistupovat, identifikovány predikátem rozsahu ve počítaném sloupci představujícím ID oddílu. Následující příklad ukazuje SEEK predikát pro Clustered Index Seek operátor. Oddíly 2 a 3 jsou přístupné a operátor hledání filtruje na řádcích, které splňují podmínku date_id BETWEEN 20080802 AND 20080902.
|--Clustered Index Seek(OBJECT:([db_sales_test].[dbo].[fact_sales].[ci]),
SEEK:([PtnId1000] >= (2) AND [PtnId1000] \<= (3)
AND [db_sales_test].[dbo].[fact_sales].[date_id] >= (20080802)
AND [db_sales_test].[dbo].[fact_sales].[date_id] <= (20080902))
ORDERED FORWARD)
Interpretace plánů provádění pro rozdělené haldy
Dělená halda se považuje za logický index ID oddílu. Odstranění oddílu v partitionované haldě je v plánu provádění reprezentováno jako Table Scan operátor s SEEK predikátem na identifikátor oddílu. Následující příklad ukazuje informace poskytnuté Showplanem:
|-- Table Scan (OBJECT: ([db].[dbo].[T]), SEEK: ([PtnId1001]=[Expr1011]) ORDERED FORWARD)
Interpretace plánů provádění pro kolaciovaná spojení
Ke spojení může dojít v případě, že jsou dvě tabulky rozdělené pomocí stejné nebo ekvivalentní funkce dělení a sloupce dělení z obou stran spojení jsou zadány v podmínce spojení dotazu. Optimalizátor dotazů může vygenerovat plán, ve kterém jsou oddíly každé tabulky, které mají stejné ID oddílů, připojeny samostatně. Kompletované spojení můžou být rychlejší než neshromážděná spojení, protože mohou vyžadovat méně paměti a doby zpracování. Optimalizátor dotazů zvolí nekolokovaný plán nebo kolokovaný plán na základě odhadů nákladů.
V kolokačním plánu Nested Loops se spoj čte z jedné nebo více připojených tabulek nebo oddílů indexu z vnitřní strany. Čísla v operátorech Constant Scan představují oddíly.
Pokud se pro dělené tabulky nebo indexy vygenerují paralelní plány pro umístěná spojení, objeví se operátor paralelismu mezi operátory spojení Constant Scan a Nested Loops. V tomto případě několik pracovních vláken na vnější straně spojení každý čte a pracuje na jiném oddílu.
Následující obrázek znázorňuje paralelní plán dotazu pro kolokované spojení.
Strategie paralelního spouštění dotazů pro dělené objekty
Procesor dotazů používá strategii paralelního spouštění pro dotazy, které vybírají z dělených objektů. V rámci strategie provádění procesor dotazů určuje oddíly tabulky vyžadované pro dotaz a poměr pracovních vláken k přidělení jednotlivým oddílům. Ve většině případů procesor dotazů přidělí každému oddílu stejný nebo téměř stejný počet pracovních vláken a pak dotaz provede paralelně napříč oddíly. Následující odstavce vysvětlují přidělení pracovních vláken podrobněji.
Pokud je počet pracovních vláken menší než počet oddílů, procesor dotazů přiřadí každé pracovní vlákno jinému oddílu, přičemž na začátku ponechá jeden nebo více oddílů bez přiřazeného pracovního vlákna. Když pracovní vlákno dokončí provádění v oddílu, procesor dotazu ho přiřadí k dalšímu oddílu, dokud nebude každému oddílu přiřazeno jedno pracovní vlákno. Toto je jediný případ, kdy procesor dotazů relokuje pracovní vlákna do jiných oddílů.
Ukazuje pracovní vlákno přesunuté k nové úloze poté, co dokončí svou práci. Pokud se počet pracovních vláken rovná počtu oddílů, procesor dotazů přiřadí každému oddílu jedno pracovní vlákno. Pracovní vlákno po dokončení není přiděleno do jiného oddílu.

Pokud je počet pracovních vláken větší než počet oddílů, procesor dotazů přidělí každému oddílu stejný počet pracovních vláken. Pokud počet pracovních vláken není přesným násobem počtu oddílů, procesor dotazů přidělí některému oddílu další pracovní vlákno, aby bylo možné použít všechna dostupná pracovní vlákna. Pokud existuje jenom jeden oddíl, přiřadí se k němu všechny pracovní podprocesy. V následujícím diagramu jsou čtyři oddíly a 14 pracovních vláken. Každý oddíl má přiřazená 3 pracovní vlákna a dva oddíly mají další pracovní vlákno pro celkem 14 přiřazení pracovních vláken. Když pracovní vlákno skončí, není znovu přiřazeno k jinému oddílu.

I když výše uvedené příklady naznačují jednoduchý způsob přidělování vláken pracovních procesů, skutečná strategie je složitější a bere v úvahu další proměnné, které se vyskytují během provádění dotazu. Pokud je například tabulka rozdělená na oddíly a má clusterovaný index ve sloupci A a dotaz má predikát klauzuli WHERE A IN (13, 17, 25), procesor dotazu přidělí každému z těchto tří hodnot hledání jedno nebo více pracovních vláken (A=13, A=17 a A=25) místo každého oddílu tabulky. Je nutné spustit dotaz pouze v oddílech, které obsahují tyto hodnoty, a pokud všechny tyto predikáty hledání budou ve stejném oddílu tabulky, budou všechna pracovní vlákna přiřazena ke stejnému oddílu tabulky.
Předpokládejme, že tabulka má čtyři oddíly ve sloupci A s hraničními body (10, 20, 30), index ve sloupci B a dotaz má predikát klauzuli WHERE B IN (50, 100, 150). Vzhledem k tomu, že oddíly tabulky jsou založené na hodnotách A, mohou nastat hodnoty B v libovolném oddílu tabulky. Procesor dotazu tedy bude hledat pro každou ze tří hodnot B (50, 100, 150) v každém ze čtyř oddílů tabulky. Procesor dotazů přiřadí pracovní vlákna úměrně, aby mohl provádět každou z těchto 12 kontrol dotazů paralelně.
| Oddíly tabulky založené na sloupci A | Hledá sloupec B v každém oddílu tabulky. |
|---|---|
| Díl tabulky 1: A < 10 | B=50, B=100, B=150 |
| Oddíl tabulky 2: A > = 10 AND A < 20 | B=50, B=100, B=150 |
| Oddíl tabulky 3: A >= 20 a A < 30 | B=50, B=100, B=150 |
| Část tabulky 4: A >= 30 | B=50, B=100, B=150 |
Osvědčené postupy
Pokud chcete zlepšit výkon dotazů, které přistupují k velkému množství dat z velkých dělených tabulek a indexů, doporučujeme následující osvědčené postupy:
- Rozdělte každý oddíl na mnoho disků. To je zvlášť důležité při používání rotujících disků.
- Pokud je to možné, použijte server s dostatečnou hlavní pamětí, aby se vešly často používané oddíly nebo všechny oddíly v paměti, abyste snížili náklady na vstupně-výstupní operace.
- Pokud se data, která zadáte do paměti, nevejdou, komprimujte tabulky a indexy. Tím se sníží náklady na vstupně-výstupní operace.
- Pomocí serveru s rychlými procesory a tolika procesorovými jádry, kolik si můžete dovolit, můžete využít možnosti paralelního zpracování dotazů.
- Ujistěte se, že server má dostatečnou šířku pásma V/V kontroleru.
- Vytvořte clusterovaný index pro každou velkou dělenou tabulku, abyste mohli využít optimalizace prohledávání stromové struktury B.
- Při hromadném načítání dat do dělených tabulek postupujte podle doporučených postupů v dokumentu White Paper, Průvodce výkonem načítání dat.
Příklad
Následující příklad vytvoří testovací databázi obsahující jednu tabulku se sedmi oddíly. Pomocí nástrojů popsaných dříve při provádění dotazů v tomto příkladu můžete zobrazit informace o dělení pro plány kompilace i za běhu.
Poznámka:
Tento příklad vloží do tabulky více než 1 milion řádků. Spuštění tohoto příkladu může trvat několik minut v závislosti na hardwaru. Před provedením tohoto příkladu ověřte, že máte k dispozici více než 1,5 GB místa na disku.
USE master;
GO
IF DB_ID (N'db_sales_test') IS NOT NULL
DROP DATABASE db_sales_test;
GO
CREATE DATABASE db_sales_test;
GO
USE db_sales_test;
GO
CREATE PARTITION FUNCTION [pf_range_fact](int) AS RANGE RIGHT FOR VALUES
(20080801, 20080901, 20081001, 20081101, 20081201, 20090101);
GO
CREATE PARTITION SCHEME [ps_fact_sales] AS PARTITION [pf_range_fact]
ALL TO ([PRIMARY]);
GO
CREATE TABLE fact_sales(date_id int, product_id int, store_id int,
quantity int, unit_price numeric(7,2), other_data char(1000))
ON ps_fact_sales(date_id);
GO
CREATE CLUSTERED INDEX ci ON fact_sales(date_id);
GO
PRINT 'Loading...';
SET NOCOUNT ON;
DECLARE @i int;
SET @i = 1;
WHILE (@i<1000000)
BEGIN
INSERT INTO fact_sales VALUES(20080800 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
GO
DECLARE @i int;
SET @i = 1;
WHILE (@i<10000)
BEGIN
INSERT INTO fact_sales VALUES(20080900 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
PRINT 'Done.';
GO
-- Two-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080802 AND 20080902
GROUP BY date_id ;
GO
SET STATISTICS XML OFF;
GO
-- Single-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080801 AND 20080831
GROUP BY date_id;
GO
SET STATISTICS XML OFF;
GO
Související obsah
- Odkaz na operátory logického a fyzického plánu zobrazení
- přehled rozšířených událostí
- osvědčené postupy pro monitorování úloh pomocí úložiště dotazů
- Odhad kardinality (SQL Server)
- inteligentní zpracování dotazů v databázích SQL
- Priorita operátorů (Transact-SQL)
- přehled plánu provádění
- Performance Center pro databázový stroj SQL Serveru a službu Azure SQL Database