Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
platí pro:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Díky fulltextovému vyhledávání v SQL Serveru a Azure SQL Database můžou uživatelé a aplikace spouštět fulltextové dotazy do znakových dat v tabulkách SQL Serveru.
Důležité
V SQL Serveru 2025 (17.x) a novějších verzích dochází k zásadním změnám ve Full-Textovém vyhledávání. Další informace naleznete v tématu Zásadní změny funkcí databázového stroje v SQL Serveru 2025.
Základní úkoly
Tento článek poskytuje přehled o Full-Text Vyhledávání a popisuje jeho komponenty a architekturu. Pokud chcete začít hned, tady jsou základní úkoly.
- Začínáme s Full-Text vyhledáváním
- Vytváření a správa katalogů Full-Text
- Vytváření a správa fulltextových indexů
- naplnění indexů Full-Text
- dotaz pomocí hledání Full-Text
Full-Text Search je volitelná součást databázového stroje SQL Serveru. Pokud jste při instalaci SQL Serveru nevybrali Full-Text Hledání, znovu ho přidejte spuštěním instalačního programu SQL Serveru.
Přehled
Fulltextový index obsahuje jeden nebo více sloupců založených na znakech v tabulce. Tyto sloupce můžou mít libovolný z následujících datových typů: char, varchar, nchar, nvarchar, text, ntext, image, xml nebo varbinary(max) a FILESTREAM. Každý fulltextový index indexuje jeden nebo více sloupců z tabulky a každý sloupec může používat určitý jazyk.
Fulltextové dotazy provádějí lingvistické vyhledávání textových dat v fulltextových indexech tím, že pracují se slovy a frázemi na základě pravidel určitého jazyka, jako je angličtina nebo japonština. Fulltextové dotazy můžou obsahovat jednoduchá slova a fráze nebo více forem slova nebo fráze. Fulltextový dotaz vrátí všechny dokumenty, které obsahují aspoň jednu shodu (označuje se také jako hit). Shoda nastane, když cílový dokument obsahuje všechny termíny zadané v fulltextovém dotazu a splňuje všechny ostatní podmínky hledání, jako je vzdálenost mezi odpovídajícími termíny.
Vyhledávací dotazy Full-Text
Po přidání sloupců do fulltextového indexu můžou uživatelé a aplikace spouštět fulltextové dotazy na text ve sloupcích. Tyto dotazy můžou hledat některou z následujících podmínek:
- Jedno nebo více konkrétních slov nebo frází (jednoduchý termín)
- Slovo nebo frázi, kde slova začínají zadaným textem (termín předpony)
- Inflexní formy konkrétního slova (termín generování)
- Slovo nebo fráze blízko jiného slova nebo fráze (proximální termín)
- Synonymní formy určitého slova (tesaurus)
- Slova nebo fráze používající vážené hodnoty (vážený termín)
Fulltextové dotazy nerozlišují malá a velká písmena. Například hledání Aluminum nebo aluminum vrátí stejné výsledky.
Fulltextové dotazy používají malou sadu Transact-SQL predikátů (CONTAINS a FREETEXT) a funkcí (CONTAINSTABLE a FREETEXTTABLE). Cíle hledání daného obchodního scénáře však ovlivňují strukturu fulltextových dotazů. Například:
Vyhledání produktu na webu elektronického obchodování:
SELECT product_id FROM products WHERE CONTAINS ((product_description), '"Snap Happy 100EZ" OR FORMSOF(THESAURUS,"Snap Happy") OR "100EZ"') AND product_cost < 200;Náborový scénář hledání uchazečů o zaměstnání, kteří mají zkušenosti s prací s SQL Serverem:
SELECT candidate_name, SSN FROM candidates WHERE CONTAINS ((candidate_resume), '"SQL Server"') AND candidate_division = 'DBA';
Další informace najdete v tématu Dotaz s vyhledáváním Full-Text.
Porovnání Full-Text vyhledávacích dotazů s predikátem LIKE
Na rozdíl od fulltextového vyhledávání funguje predikát LIKE Transact-SQL pouze na vzorech znaků. Predikát také nemůžete použít LIKE k dotazování na formátovaná binární data. Kromě toho LIKE je dotaz na velké množství nestrukturovaných textových dat mnohem pomalejší než ekvivalentní fulltextový dotaz na stejná data. Vrácení LIKE dotazu na miliony řádků textových dat může trvat několik minut. Zatímco fulltextový dotaz může trvat jenom několik sekund nebo méně u stejných dat v závislosti na počtu vrácených řádků.
Architektura vyhledávání Full-Text
Architektura fulltextového vyhledávání se skládá z následujících procesů:
Proces SQL Serveru (
sqlservr.exe).Proces hostitele démonu filtru (
fdhost.exe).Z bezpečnostních důvodů se filtry načítají samostatnými procesy, které se nazývají filter daemon hosty. Procesy
fdhost.exejsou vytvořeny službou spouštěče FDHOST (MSSQLFDLauncher) a spouští se pod přihlašovacími údaji zabezpečení účtu služby spouštěče FDHOST. Proto musí služba spouštěče FDHOST běžet, aby fungovalo fulltextové indexování a fulltextové dotazování. Informace o nastavení účtu služby pro tuto službu najdete v části Nastavení účtu služby pro spouštěč démona fulltextového filtru.
Tyto dva procesy obsahují komponenty architektury fulltextového vyhledávání. Tyto komponenty a jejich vztahy jsou shrnuty na následujícím obrázku. Komponenty jsou popsány za obrázkem.
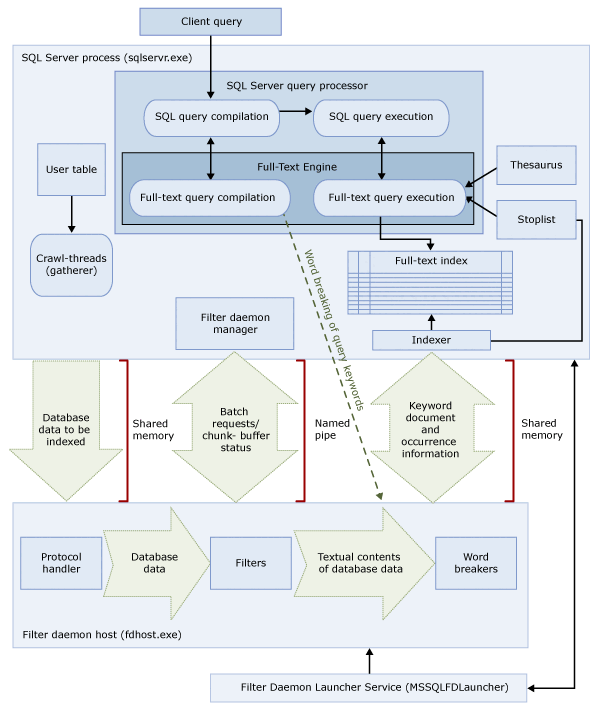
Proces SQL Serveru
Proces SQL Serveru používá pro fulltextové vyhledávání následující komponenty:
| Součást | Popis |
|---|---|
| Uživatelské tabulky | Tyto tabulky obsahují data, která mají být plnotextově indexována. |
| Fulltextový indexovací modul | Modul pro shromažďování fulltextu pracuje s vlákny procházení fulltextu. Zodpovídá za plánování a řízení populace fulltextových indexů a také za monitorování fulltextových katalogů. |
| Soubory Tesaurus | Tyto soubory obsahují synonyma hledaných termínů. Další informace najdete v tématu Konfigurace a správa souborů tesaurus pro Full-Text hledání. |
| Objekty zastavovacího seznamu | Objekty stoplist obsahují seznam běžných slov, která nejsou užitečná pro hledání. Pro více informací viz Konfigurace a správa stopwordů a stoplistů pro Full-Text Search. |
| Procesor dotazů SQL Serveru | Procesor dotazů zkompiluje a spouští dotazy SQL. Pokud dotaz SQL obsahuje fulltextový vyhledávací dotaz, odešle se dotaz do modulu Full-Text, a to jak během kompilace, tak během provádění. Výsledek dotazu se porovná s fulltextovým indexem. |
| motorFull-Text | Modul Full-Text v SQL Serveru je plně integrovaný s procesorem dotazů. Modul Full-Text zkompiluje a spouští fulltextové dotazy. V rámci provádění dotazů může modul Full-Text přijímat vstupy z teauru a seznamu stop. |
| Zapisovač indexu (indexer) | Zapisovač indexu sestaví strukturu, která se používá k ukládání indexovaných tokenů. |
| Správce filtrovacího démona | Správce démona filtru zodpovídá za monitorování stavu démona filtru modulu Full-Text. |
Proces démona filtru
Hostitel démon filtru je proces, který spouští modul Full-Text. Spustí následující komponenty fulltextového vyhledávání, které zodpovídají za přístup k datům z tabulek, filtrování a dělení slov, jakož i za dělení slov a odvozování kořenů zadaného dotazu.
Součásti hostitele démona filtru jsou následující:
| Součást | Popis |
|---|---|
| Obslužná rutina protokolu | Tato komponenta načítá data z paměti pro další zpracování a přistupuje k datům z tabulky uživatele v zadané databázi. Jednou z povinností je shromáždit data ze sloupců, které jsou fulltextově indexované, a předat je démonu hostitele filtru, který podle potřeby používá filtrování a dělení výrazů. |
| Filtry | Některé datové typy vyžadují filtrování před tím, než mohou být data v dokumentu indexována pomocí fulltextu, včetně dat v sloupcích varbinary, varbinary(max), image nebo xml. Filtr použitý pro daný dokument závisí na typu dokumentu. Například různé filtry se používají pro dokumenty Microsoft Wordu (.doc), dokumenty Microsoft Excelu (.xls) a dokumenty XML (.xml). Potom filtr extrahuje bloky textu z dokumentu, odebere vložené formátování a zachová text a případně informace o pozici textu. Výsledkem je datový proud textových informací. Další informace najdete v tématu Konfigurace a správa filtrů pro vyhledávání. |
| Dělitelé slov a stemmy | Rozdělovač slov je jazykově specifická komponenta, která určuje hranice slov na základě lexikálních pravidel daného jazyka (dělení slov). Každý modul pro dělení slov je přidružen k komponentě stemmer specifické pro jazyk, která konjuguje slovesa a provádí inflexní rozšíření. V době indexování používá hostitel démon filtru k provádění lingvistické analýzy textových dat z daného sloupce tabulky dělení slov a stemmer. Jazyk přidružený ke sloupci tabulky v fulltextovém indexu určuje, který oddělovač slov a stemmer se používají k indexování sloupce. Další informace naleznete v tématu Konfigurace a správa dělení slov a lemmatizátorů pro vyhledávání (SQL Server). |
SQL Server 2012 (11.x) instaluje novou verzi rozpoznávačů slov a lemmatizérů pro angličtinu v USA (LCID 1033) a angličtinu ve Spojeném království (LCID 2057). Pokud ale chcete zachovat předchozí chování, můžete přepnout na předchozí verzi těchto komponent. Další informace najdete v tématu Změna lámání slov používaného pro americkou angličtinu a britskou angličtinu.
Full-Text Zpracování vyhledávání
Fulltextové vyhledávání využívá modul Full-Text. Modul Full-Text má dvě role: pro podporu indexování a pro podporu dotazování.
Full-Text proces indexování
Když se zahájí zpracování fulltextu (označované také jako procházení), modul Full-Text odešle velké dávky dat do paměti a upozorní hostitele démona filtru. Hostitel filtruje data, rozděluje je na jednotlivá slova a převedená data přemění na invertované seznamy slov. Plnotextové vyhledávání pak načítá převedená data ze seznamů slov, zpracovává data k odstranění stopslov a ukládá seznamy slov pro jednu dávku do jednoho nebo více invertovaných indexů.
Při indexování dat uložených ve sloupci varbinary(max) nebo image filtr, který implementuje IFilter rozhraní, extrahuje text na základě zadaného formátu souboru pro tato data (například Microsoft Word). V některých případech komponenty filtru vyžadují, aby se data varbinary(max) nebo image zapisovala do filterdata složky místo vložení do paměti.
Při zpracování se shromážděná textová data předávají pomocí nástroje pro dělení slov, aby se text oddělil do jednotlivých tokenů nebo klíčových slov. Jazyk používaný pro tokenizaci je určen na úrovni sloupce nebo lze identifikovat v rámci varbinary(max), image nebo xml dat podle komponenty filtru.
Je možné provést dodatečné zpracování, které odebere stopwords a normalizuje tokeny před jejich uložením v fulltextovém indexu nebo fragmentu indexu.
Po dokončení populace se aktivuje konečný proces sloučení, který sloučí fragmenty indexu do jednoho hlavního fulltextového indexu. Výsledkem je vyšší výkon dotazů, protože pouze hlavní index je potřeba dotazovat místo několika fragmentů indexů a pro hodnocení relevance se můžou použít lepší statistiky hodnocení.
Full-Text proces dotazování
Procesor dotazů předá celé textové části dotazu do Full-Text Engine ke zpracování. Engine Full-Text provádí dělení slov a volitelně rozšíření tesauru, stemování a zpracování stopslov (šumových slov). Poté jsou fulltextové části dotazu reprezentovány ve formě operátorů SQL, především jako streamované funkce s hodnotou tabulky (STVFs). Během provádění dotazu tyto STVF přistupují k invertovanému indexu a načítají odpovídající výsledky. Výsledky se v tuto chvíli vrátí klientovi nebo se ještě před vrácením klientovi zpracují.
Architektura fulltextového indexu
Informace v fulltextových indexech používá modul Full-Text ke kompilaci fulltextových dotazů, které mohou rychle hledat v tabulce konkrétní slova nebo kombinace slov. Fulltextový index ukládá informace o významných slovech a jejich umístění v jednom nebo více sloupcích databázové tabulky. Fulltextový index je speciální typ funkčního indexu založeného na tokenech, který je sestaven a udržován modulem Full-Text pro SQL Server. Proces vytváření fulltextového indexu se liší od vytváření jiných typů indexů. Místo vytvoření struktury B-stromu na základě hodnoty uložené v určitém řádku vytvoří modul Full-Text invertovanou, skládanou komprimovanou strukturu indexu na základě jednotlivých tokenů z indexovaného textu. Velikost fulltextového indexu je omezena pouze dostupnými paměťovými prostředky počítače, na kterém je spuštěna instance SQL Serveru.
Počínaje systémem SQL Server 2008 (10.0.x) jsou fulltextové indexy integrované s databázovým strojem, nikoli v systému souborů jako v předchozích verzích SQL Serveru. Pro novou databázi je teď fulltextový katalog virtuálním objektem, který nepatří do žádné skupiny souborů; jedná se pouze o logický koncept, který odkazuje na skupinu fulltextových indexů. Mějte však na paměti, že při upgradu databáze systému SQL Server 2005 (9.x) se pro každý fulltextový katalog obsahující datové soubory vytvoří nová skupina souborů; Podívejte se na Upgrade Full-Text Hledání pro více informací.
Pro každou tabulku je povolený pouze jeden fulltextový index. Aby se v tabulce vytvořil fulltextový index, musí mít tabulka jeden jedinečný sloupec, který není null. Můžete vytvořit fulltextový index pro sloupce typu char, varchar, nchar, nvarchar, text, ntext, image, xml, varbinary a varbinary(max) lze indexovat pro fulltextové vyhledávání. Vytvoření fulltextového indexu ve sloupci, jehož datový typ je varbinary, varbinary(max), obrázek nebo xml vyžaduje, abyste zadali sloupec typu.
Sloupec typu je sloupec tabulky, do kterého ukládáte příponu souboru (.doc, .pdf.xlsatd.) dokumentu v každém řádku.
Struktura fulltextového indexu
Dobré porozumění struktuře fulltextového indexu vám pomůže pochopit, jak Full-Text modul funguje. V tomto článku se jako ukázková tabulka používá následující výňatek Document tabulky AdventureWorks2025 . Tento výňatek zobrazuje pouze dva sloupce, DocumentID sloupec a Title sloupec a tři řádky z tabulky.
V tomto příkladu předpokládáme, že na sloupci Title byl vytvořen fulltextový index.
| Id dokumentu | Titulek |
|---|---|
1 |
Crank Arm and Tire Maintenance |
2 |
Front Reflector Bracket and Reflector Assembly 3 |
3 |
Front Reflector Bracket Installation |
Například následující tabulka, která ukazuje Fragment 1, znázorňuje obsah fulltextového indexu vytvořeného ve Title sloupci Document tabulky. Fulltextové indexy obsahují více informací, než je uvedeno v této tabulce. Tabulka je logická reprezentace fulltextového indexu a je k dispozici pouze pro demonstrační účely. Řádky jsou uložené v komprimovaném formátu pro optimalizaci využití disku.
Data jsou obrácena proti původním dokumentům. K inverzi dochází, protože klíčová slova jsou mapována na ID dokumentu. Z tohoto důvodu se fulltextový index často označuje jako invertovaný index.
Všimněte si také, že klíčové slovo and je odebráno z fulltextového indexu. To se provádí, protože and je stopslovo a odstranění stopslov z fulltextového indexu může vést k značným úsporám místa na disku, což zlepšuje výkon dotazů. Další informace o stopwords naleznete v tématu Konfigurace a správa stopwords a stoplists for Full-Text Search.
Fragment 1
| Klíčové slovo | Id sloupku | ID dokumentu | Výskyt |
|---|---|---|---|
Crank |
1 | 1 | 1 |
Arm |
1 | 1 | 2 |
Tire |
1 | 1 | 4 |
Maintenance |
1 | 1 | 5 |
Front |
1 | 2 | 1 |
Front |
1 | 3 | 1 |
Reflector |
1 | 2 | 2 |
Reflector |
1 | 2 | 5 |
Reflector |
1 | 3 | 2 |
Bracket |
1 | 2 | 3 |
Bracket |
1 | 3 | 3 |
Assembly |
1 | 2 | 6 |
3 |
1 | 2 | 7 |
Installation |
1 | 3 | 4 |
Sloupec Keyword obsahuje reprezentaci jednoho tokenu extrahovaného v době indexování. Děliče slov určují, co tvoří token.
Sloupec ColId obsahuje hodnotu odpovídající určitému sloupci, který je indexován fulltextem.
Sloupec DocId obsahuje hodnoty pro 8bajtové celé číslo, které se mapuje na určitou hodnotu klíče fulltextového indexu v tabulce, která je indexována pro fulltext. Toto mapování je nezbytné, pokud fulltextový klíč není celočíselný datový typ. V takových případech jsou mapování mezi hodnotami fulltextového klíče a DocId hodnotami udržována v samostatné tabulce nazývané DocId Mapping tabulkou. Pro dotazování na tato mapování použijte systémovou uloženou proceduru sp_fulltext_keymappings. Aby bylo možné vyhovět hledané podmínce, hodnoty z předchozí tabulky DocId musí být spojeny s mapovací tabulkou DocId, aby se načetly řádky z dotazované základní tabulky. Pokud je hodnota fulltextového klíče základní tabulky celočíselným typem, hodnota přímo slouží jako DocId hodnota a není nutné žádné mapování. Proto použití celočíselné hodnoty fulltextových klíčů může pomoct optimalizovat fulltextové dotazy.
Sloupec Occurrence obsahuje celočíselnou hodnotu. Pro každou hodnotu DocId je seznam hodnot výskytů, které odpovídají relativním posunům slov konkrétního klíčového slova v rámci tohoto DocId. Hodnoty výskytů jsou užitečné při určování shody frází nebo blízkosti, například fráze mají číselné sousední hodnoty výskytu. Jsou také užitečné při výpočtech skóre relevance; Například počet výskytů klíčového slova v DocId se může použít při bodování.
Fragmenty fulltextového indexu
Logický fulltextový index je obvykle rozdělen mezi několik interních tabulek. Každá interní tabulka se nazývá fragment fulltextového indexu. Některé z těchto fragmentů můžou obsahovat novější data než jiná. Pokud například uživatel aktualizuje následující řádek, jehož DocId je 3, a tabulka je automaticky sledována na změny, vytvoří se nový fragment.
| Id dokumentu | Titulek |
|---|---|
3 |
Rear Reflector |
V následujícím příkladu, který ukazuje Fragment 2, fragment obsahuje novější data o DocId 3 ve srovnání s fragmentem 1. Proto když se uživatel dotazuje na Rear Reflector, pro DocId 3 se použijí data z fragmentu 2. Každý fragment je označen časovým razítkem vytvoření, na které se dá dotazovat pomocí zobrazení katalogu sys.fulltext_index_fragments .
Fragment 2
| Klíčové slovo | Id sloupku | ID dokumentu | Occ |
|---|---|---|---|
Rear |
1 | 3 | 1 |
Reflector |
1 | 3 | 2 |
Jak je vidět z fragmentu 2, fulltextové dotazy musí dotazovat každý fragment interně a zahodit starší položky. Proto příliš mnoho fragmentů ve fulltextovém indexu může vést k podstatnému snížení výkonu dotazů. Chcete-li snížit počet fragmentů, přeorganizujte fulltext-katalog pomocí volby REORGANIZE příkazu ALTER FULLTEXT CATALOGTransact-SQL. Tento příkaz provede hlavní sloučení, které sloučí fragmenty do jednoho většího fragmentu a odebere všechny zastaralé položky z fulltextového indexu.
Po opětovném uspořádání by ukázkový index obsahoval následující řádky:
| Klíčové slovo | Id sloupku | ID dokumentu | Occ |
|---|---|---|---|
Crank |
1 | 1 | 1 |
Arm |
1 | 1 | 2 |
Tire |
1 | 1 | 4 |
Maintenance |
1 | 1 | 5 |
Front |
1 | 2 | 1 |
Rear |
1 | 3 | 1 |
Reflector |
1 | 2 | 2 |
Reflector |
1 | 2 | 5 |
Reflector |
1 | 3 | 2 |
Bracket |
1 | 2 | 3 |
Assembly |
1 | 2 | 6 |
3 |
1 | 2 | 7 |
Rozdíly mezi fulltextovými indexy a běžnými indexy SQL Serveru
| Fulltextové indexy | Běžné indexy SQL Serveru |
|---|---|
| Pro každou tabulku je povolený pouze jeden fulltextový index. | Pro každou tabulku je povoleno několik běžných indexů. |
| Přidání dat do fulltextových indexů, nazývaných jako populace, může být požadováno buď prostřednictvím plánu, konkrétního požadavku, nebo může dojít k němu automaticky s přidáním nových dat. | Aktualizuje se automaticky, když se data, na kterých jsou založená, vloží, aktualizuje nebo odstraní. |
| Seskupené v rámci stejné databáze do jednoho nebo více fulltextových katalogů. | Není seskupené. |
Full-Text prohledat jazykové komponenty a podporu jazyků
Fulltextové vyhledávání podporuje téměř 50 různých jazyků, jako je angličtina, španělština, čínština, japonština, arabština, Bangla a hindština. Úplný seznam podporovaných fulltextových jazyků najdete v sys.fulltext_languages. Každý ze sloupců obsažených v fulltextovém indexu je přidružený k identifikátoru národního prostředí Systému Microsoft Windows (LCID), který odpovídá jazyku podporovanému fulltextovým vyhledáváním. Například LCID 1033 odpovídá americké angličtině a LCID 2057 odpovídá britské angličtině. Pro každý podporovaný fulltextový jazyk poskytuje SQL Server lingvistické komponenty, které podporují indexování a dotazování fulltextových dat uložených v tomto jazyce.
Součásti specifické pro jazyk zahrnují následující položky:
| Součást | Popis |
|---|---|
| Dělitelé slov a stemmy | Oddělovač slov najde hranice slov na základě lexikálních pravidel daného jazyka (dělení slov). Každý oddělovač slov je spojen se stemmerem, který zpracovává slovesa pro tentýž jazyk. Další informace naleznete v tématu Konfigurace a správa dělení slov a lemmatizátorů pro vyhledávání (SQL Server). |
| Seznamy vyloučených slov | Je k dispozici seznam stop systému, který obsahuje základní sadu stopwords (označovaných také jako slova šumu).
Stopword je slovo, které nepomáhá při hledání a je ignorováno fulltextovými dotazy. Například pro anglická národní prostředí slova, jako aje , andis, a the jsou považovány za stopwords. Obvykle potřebujete nakonfigurovat jeden nebo více souborů tesaurus a stoplistů. Pro více informací viz Konfigurace a správa stopwordů a stoplistů pro Full-Text Search. |
| Soubory Tesaurus | SQL Server také nainstaluje soubor tesaurus pro každý fulltextový jazyk a globální soubor tesaurus. Nainstalované soubory tesaurus jsou prázdné, ale můžete je upravit a definovat synonyma pro konkrétní jazyk nebo obchodní scénář. Díky vývoji tesauru přizpůsobeného fulltextovým datům můžete efektivně rozšířit rozsah fulltextových dotazů na tato data. Další informace najdete v tématu Konfigurace a správa souborů tesaurus pro Full-Text hledání. |
| Filtry (Filters) | Indexování dokumentu ve sloupci s datovým typem varbinary(max), image nebo xml vyžaduje filtr k dalšímu zpracování. Filtr musí být specifický pro typ dokumentu (.doc, .pdf, .xls, .xmlatd.). Další informace najdete v tématu Konfigurace a správa filtrů pro vyhledávání. |
Rozdělovače slov (a lematizátory) a filtry se spouštějí v hostitelském procesu služby filtru (fdhost.exe).