Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Platí pro:![]() SQL Server 2016 (13.x)
SQL Server 2016 (13.x) ![]() SQL Server 2017 (14.x)
SQL Server 2017 (14.x) ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Důležitý
Sql Server Distributed Replay není k dispozici s SQL Serverem 2022 (16.x) a novějšími verzemi.
Funkce distribuovaného přehrání microsoft SQL Serveru vám pomůže vyhodnotit vliv budoucích upgradů SQL Serveru. Můžete ho také použít k posouzení vlivu upgradů hardwaru a operačního systému a ladění SQL Serveru.
Vyřazení distribuovaného přehrávání v SQL Serveru 2022
Distribuované přehrání je zastaralé jako SQL Server 2022 (16.x), jak je uvedeno v zastaralých funkcích databázového stroje v SQL Serveru 2022 (16.x). Distribuované přehrávání je závislé na SQL Server Native Client (SNAC), který byl odebrán z SQL Serveru 2022 (16.x). Tato změna je zdokumentovaná v Zásady podpory pro SQL Server Native Client. Distribuované přehrání navíc závisí na souborech .trc, které jsou zachyceny pomocí SQL Trace a SQL Server Profiler, přičemž oba jsou rovněž zastaralé.
Distribuovaný řadič přehrávání byl odebrán z instalace SYSTÉMU SQL Server 2022 (16.x) a distribuovaný klient přehrávání již není k dispozici v aplikaci SQL Server Management Studio (SSMS) od verze 18. Chcete-li získat distribuovaný replay Controller, musíte nainstalovat SQL Server 2019 (15.x) nebo starší verzi. Chcete-li získat klienta pro distribuované přehrání, musíte nainstalovat SSMS 17.9.1.
Pro zákazníky s SQL Serverem 2022 (16.x) můžete místo toho použít nástroje RML (Replay Markup Language), které zahrnují ostress, k přehrání úlohy.
Výhody distribuovaného přehrávání
Podobně jako u SQL Server Profiler můžete pomocí Distributed Replay přehrát zachycené trasování v upgradovaném testovacím prostředí. Na rozdíl od SQL Server Profileru není distribuované přehrání omezené na přehrání úlohy z jednoho počítače.
Distribuované přehrání nabízí škálovatelnější řešení než SQL Server Profiler. S distribuovaným přehráváním můžete přehrávat úlohy z více počítačů a lépe simulovat kritickou úlohu.
Funkce distribuovaného přehrávání může použít více počítačů k přehrání dat trasování a simulaci kritické úlohy. K testování kompatibility aplikací, testování výkonu nebo plánování kapacity využijte distribuované přehrávání.
Kdy použít Distributed Replay
SQL Server Profiler a distribuované přehrání poskytují určitou vzájemnou překrývající se funkčnost.
K přehrání zachyceného trasování v upgradovaném testovacím prostředí můžete použít SQL Server Profiler. Výsledky přehrání můžete také analyzovat a vyhledat případné nekompatibility funkčnosti a výkonu. SQL Server Profiler ale může přehrát jenom úlohu z jednoho počítače. Při přehrávání náročné aplikace OLTP, která má mnoho aktivních souběžných připojení nebo vysokou propustnost, se SQL Server Profiler může stát úzkým hrdlem.
Distribuované přehrání nabízí škálovatelnější řešení než SQL Server Profiler. Pomocí distribuovaného přehrávání můžete přehrávat úlohy z více počítačů a lépe simulovat kritickou úlohu.
Následující tabulka popisuje, kdy použít jednotlivé nástroje.
| Nástroj | Použijte, když... |
|---|---|
| SQL Server Profiler | Chcete použít konvenční mechanismus přehrávání na jednom počítači. Konkrétně potřebujete možnosti ladění po jednotlivých řádcích, například Krok, Spustit na kurzor a Přepnout zarážku příkazy. Chcete znovu přehrát sledování služby Analysis Services. |
| Distribuované přehrání | Chcete vyhodnotit kompatibilitu aplikací. Chcete například otestovat scénáře upgradu SQL Serveru a operačního systému, upgrady hardwaru nebo ladění indexu. Souběžnost v zachyceném trasování je tak vysoká, že jeden přehrávací klient ji nemůže dostatečně simulovat. |
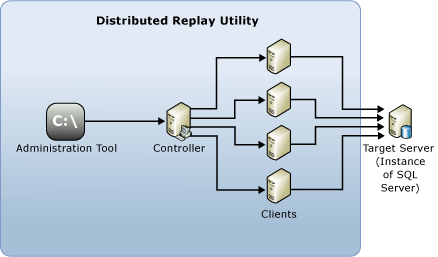
Principy distribuovaného přehrání
Následující komponenty tvoří prostředí distribuovaného přehrávání:
nástroj pro správu distribuovaného přehrávání: konzolová aplikace, DReplay.exe, sloužící ke komunikaci s distribuovaným kontrolerem přehrávání. Pomocí nástroje pro správu můžete řídit distribuované přehrávání.
distribuovaný řadič přehrávání: Počítač se službou Windows s názvem SQL Server Distributed Replay controller. Řadič distribuovaného přehrání orchestruje činnosti klientů distribuovaného přehrání. V každém prostředí distribuovaného přehrávání může existovat pouze jedna instance kontroleru.
Klienti distribuovaného přehrávání: Jeden nebo více počítačů (fyzických nebo virtuálních) s Windows službou nazvanou klient SQL Server Distributed Replay. Klienti Distributed Replay spolupracují na simulaci zátěže proti instanci SQL Serveru. V každém prostředí distribuovaného přehrávání může být jeden nebo více klientů.
cílový server: Instance SQL Serveru, kterou mohou klienti distribuovaného přehrávání použít k opětovnému přehrání dat ze sledování. Doporučujeme, aby cílový server byl umístěn v testovacím prostředí.
Nástroj pro správu distribuovaného přehrávání, kontroler a klient lze nainstalovat do různých počítačů nebo stejného počítače. Na stejném počítači může běžet pouze jedna instance řadiče distribuovaného přehrávání nebo klientské služby.
Následující obrázek ukazuje fyzickou architekturu SQL Server Distributed Replay.
Distribuované úlohy přehrávání
| Popis úkolu | Článek |
|---|---|
| Popisuje, jak nakonfigurovat Distributed Replay. | Konfigurace Distribuovaného Přehrání |
| Popisuje, jak připravit vstupní stopová data. | Příprava vstupních dat sledování |
| Popisuje, jak znovu přehrát data trasování. | Přehrát údaje o trasování |
| Popisuje, jak zkoumat výsledky trasovacích dat distribuovaného přehrávání. | Zkontrolujte výsledky přehrávání |
| Popisuje, jak pomocí nástroje pro správu zahájit, monitorovat a rušit operace na kontroleru. | Možnosti příkazového řádku nástroje pro administraci (Nástroj pro distribuované přehrávání) |
Požadavky
Před použitím funkce Distribuované přehrání zvažte požadavky na produkt, které jsou popsané v tomto článku.
Požadavky na sledování vstupu
Aby bylo možné úspěšně přehrát data trasování, musí splňovat požadavky na verzi a formát a obsahovat požadované události a sloupce.
Verze sledování vstupu
Distribuované přehrání podporuje vstupní data trasování shromážděná v následujících verzích SQL Serveru:
- SQL Server 2019 (15.x)
- SQL Server 2017 (14.x) (kumulativní aktualizace 1 a novější verze – viz verze sestavení SQL Serveru 2017)
- SQL Server 2016 (13.x)
- SQL Server 2014 (12.x)
- SQL Server 2012 (11.x)
- SQL Server 2008 R2 (10.50.x)
- SQL Server 2008 (10.0.x)
- SQL Server 2005 (9.x)
Formáty sledování vstupu
Vstupní data trasování můžou být v některém z následujících formátů:
Jeden trasovací soubor, který má příponu
.trc.Sada souborů s trasovacími údaji, které se řídí konvencí pro rotaci názvů souborů, například:
<TraceFile>.trc,<TraceFile>_1.trc,<TraceFile>_2.trc,<TraceFile>_3.trc, ...<TraceFile>_n.trc.
Události trasování vstupů a sloupce
Vstupní data trasování musí obsahovat konkrétní události a sloupce, které mají být přehrány pomocí funkce Distributed Replay. Šablona TSQL_Replay v SQL Server Profileru obsahuje kromě dalších informací také všechny požadované události a sloupce. Další informace o této šabloně najdete v tématu Požadavky na přehrání.
Varování
Pokud šablonu TSQL_Replay nepoužíváte k zachycení vstupních dat trasování, nebo pokud nejsou splněny požadavky na tato vstupní data, může se zobrazit neočekávaný výsledek přehrání.
Můžete také vytvořit vlastní šablonu trasování a použít ji k přehrání událostí pomocí distribuovaného přehrávání, pokud obsahuje následující události:
- Auditorské přihlášení
- Odhlášení z auditu
- Stávající připojení
- Výstupní parametr RPC
- RPC:Dokončeno
- RPC:Spuštění
- SQL:Dávka dokončena
- SQL:BatchStarting
Pokud přehráváte kurzory na straně serveru, vyžadují se také následující události:
- Ukončení kurzoru
- CursorExecute
- CursorOpen
- CursorPrepare
- Zrušení přípravy kurzoru
Pokud přehráváte připravené příkazy SQL na straně serveru, vyžadují se také následující události:
- Provést připravený SQL příkaz
- Připravte SQL
Všechna vstupní data trasování musí obsahovat následující sloupce:
- Třída události
- Sekvence událostí
- Textová data
- Název aplikace
- Přihlašovací jméno
- Název databáze
- ID databáze
- Název hostitele
- Binární data
- SPID
- Čas zahájení
- Čas ukončení
- IsSystem
Podporované kombinace sledování vstupu a cílového serveru
Následující tabulka uvádí podporované verze dat trasování a pro každou z nich podporované verze SQL Serveru, se kterými se dají data přehrávat.
| Verze vstupních sledovacích dat | Podporované verze SQL Serveru pro instanci cílového serveru |
|---|---|
| SQL Server 2005 (9.x) | SQL Server 2008 (10.0.x), SQL Server 2008 R2 (10.50.x), SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2008 (10.0.x) | SQL Server 2008 (10.0.x), SQL Server 2008 R2 (10.50.x), SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2008 R2 (10.50.x) | SQL Server 2008 R2 (10.50.x), SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2012 (11.x) | SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2014 (12.x) | SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2016 (13.x) | SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2017 (14.x) | SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2019 (15.x) | SQL Server 2019 (15.x) |
Požadavky na operační systém
Podporované operační systémy pro spuštění nástroje pro správu a kontroleru a klientských služeb jsou stejné jako instance SQL Serveru. Další informace o podporovaných operačních systémech pro instanci SQL Serveru najdete v tématu Požadavky na hardware a software pro SQL Server 2016 a SQL Server 2017.
Distribuované funkce přehrávání jsou podporovány v operačních systémech založených na platformě x86 i x64. V případě operačních systémů založených na platformě x64 se podporuje pouze režim Windows v systému Windows (WOW).
Omezení instalace
Každý počítač může mít nainstalovanou jenom jednu instanci každé funkce distribuovaného přehrávání. Následující tabulka uvádí, kolik instalací jednotlivých funkcí je povoleno v jednom prostředí distribuovaného přehrávání.
| Distribuovaná funkce přehrávání | Maximální počet instalací na prostředí pro přehrávání |
|---|---|
| Služba kontroleru distribuovaného přehrávání SQL Serveru | 1 |
| Služba klienta pro distribuované přehrávání SQL Serveru | 16 (fyzické nebo virtuální počítače) |
| Nástroj pro správu | Neomezený |
Poznámka
I když se na jeden počítač dá nainstalovat jenom jedna instance nástroje pro správu, můžete spustit několik instancí nástroje pro správu. Příkazy vydané z více nástrojů pro správu jsou vyřešeny v pořadí, v jakém jsou přijaty.
Zprostředkovatel přístupu k datům
Funkce Distribuované přehrávání podporuje pouze ODBC zprostředkovatele přístupu k datům nativního klienta SQL Serveru.
Požadavky na přípravu cílového serveru
Doporučujeme, aby cílový server byl umístěn v testovacím prostředí. Pokud chcete přehrát trasovací data proti jiné instanci SQL Serveru, než byla původně zaznamenána, ujistěte se, že na cílovém serveru byly provedeny následující kroky:
Všechna přihlášení a uživatelé, kteří jsou obsaženi v datech trasování, musí být ve stejné databázi na cílovém serveru.
Všechna přihlášení a uživatelé na cílovém serveru musí mít stejná oprávnění, jaká měli na původním serveru.
ID databáze v cíli by měla být v ideálním případě stejná jako ID databáze ve zdroji. Pokud ale nejsou stejné, dají se spárovat na základě DatabaseName, pokud je přítomen ve sledování.
Výchozí databáze pro každé přihlášení obsažené v datech trasování musí být nastavena (na cílovém serveru) na příslušnou cílovou databázi přihlášení. Například trasovaná data, která mají být přehrána, obsahují aktivitu pro přihlášení Fredv databázi Fred_Db na původní instanci SQL Serveru. Proto na cílovém serveru musí být výchozí databáze pro přihlášení, Fred, nastavena na databázi, která odpovídá Fred_Db (i když je název databáze jiný). Pokud chcete nastavit výchozí databázi přihlášení, použijte uloženou proceduru
sp_defaultdbsystému.
Přehrání událostí přidružených k chybějícím nebo nesprávným přihlášením vede k chybám přehrávání, ale operace přehrání pokračuje.