Sestavení kopírovaného grafu s tokem výzvy
Po nahrání dat do Azure AI Studia a vytvoření indexu dat pomocí integrace se službou Azure AI Search můžete implementovat model RAG s příkazem Prompt Flow k vytvoření aplikace copilot.
Prompt Flow je vývojová architektura pro definování toků, které orchestrují interakce s LLM.
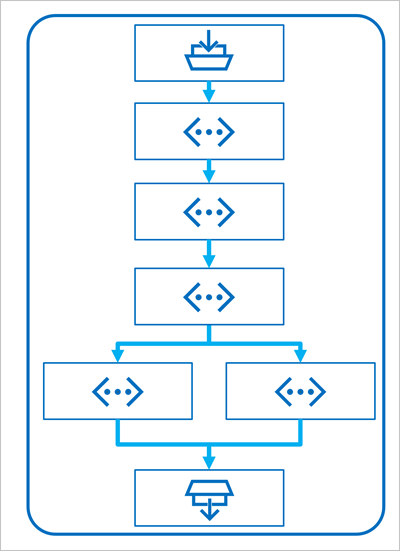
Tok začíná jedním nebo více vstupy, obvykle otázkou nebo výzvou, kterou uživatel zadal, a v případě iterativních konverzací historie chatu do tohoto bodu.
Tok se pak definuje jako řada připojených nástrojů, z nichž každá provádí konkrétní operaci se vstupy a dalšími proměnnými prostředí. Existuje několik typů nástrojů, které můžete zahrnout do toku výzvy k provádění úloh, jako jsou:
- Spuštění vlastního kódu Pythonu
- Vyhledání hodnot dat v indexu
- Vytváření variant výzvy – umožňuje definovat více verzí výzvy pro velký jazykový model (LLM), různé systémové zprávy nebo dotazování a porovnat a vyhodnotit výsledky z každé varianty.
- Odeslání výzvy k vygenerování výsledků do LLM
Nakonec má tok jeden nebo více výstupů, obvykle k vrácení vygenerovaných výsledků z LLM.
Použití vzoru RAG v toku výzvy
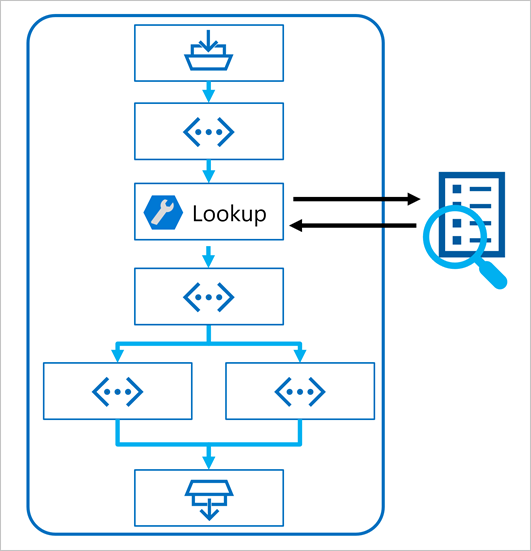
Klíčem k použití vzoru RAG v toku výzvy je použití vyhledávacího nástroje indexu k načtení dat z indexu, aby následné nástroje v toku mohly použít výsledky k rozšíření výzvy použité k vygenerování výstupu z LLM.
Vytvoření toku chatu pomocí ukázky
Tok výzvy poskytuje různé ukázky, které můžete použít jako výchozí bod k vytvoření aplikace. Pokud chcete zkombinovat RAG a jazykový model ve vaší aplikaci, můžete naklonovat více kruhové Q&A na ukázku dat .
Ukázka obsahuje nezbytné prvky pro zahrnutí RAG a jazykového modelu:
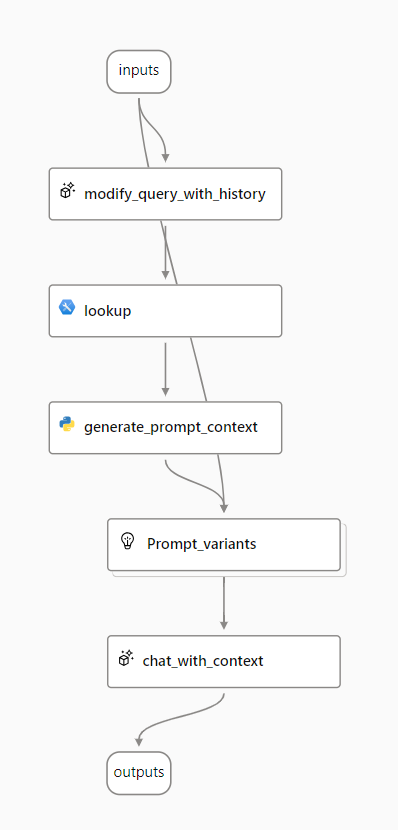
- Připojte historii ke vstupu chatu a definujte výzvu ve formě kontextové formy otázky.
- Pomocí indexu vyhledávání vyhledejte relevantní informace z dat.
- Vygenerujte kontext výzvy pomocí načtených dat z indexu k rozšíření otázky.
- Vytvořte varianty výzvy přidáním systémové zprávy a strukturováním historie chatu.
- Odešlete výzvu do jazykového modelu, který vygeneruje odpověď v přirozeném jazyce.
Pojďme se podrobněji podívat na každý z těchto prvků.
Úprava dotazu s historií
Prvním krokem v toku je uzel LLM (Large Language Model), který přebírá historii chatu a poslední otázku uživatele a vygeneruje novou otázku, která obsahuje všechny potřebné informace. Tím vygenerujete výstižnější vstup, který zpracuje zbytek toku.
Vyhledání relevantních informací
V dalším kroku použijete nástroj Vyhledávání indexu k dotazování indexu vyhledávání, který jste vytvořili pomocí integrované funkce Azure AI Search, a vyhledáte relevantní informace z vašeho zdroje dat.
Tip
Přečtěte si další informace o nástroji Vyhledávání indexu.
Generování kontextu výzvy
Výstupem nástroje Vyhledávání indexu je načtený kontext, který chcete použít při generování odpovědi uživateli. Chcete použít výstup v příkazovém řádku, který se odešle do jazykového modelu, což znamená, že chcete výstup analyzovat do vhodnějšího formátu.
Výstup nástroje Vyhledávání indexu může obsahovat prvních n výsledků (v závislosti na nastavených parametrech). Když vygenerujete kontext výzvy, můžete pomocí uzlu Pythonu iterovat načtené dokumenty ze zdroje dat a zkombinovat jejich obsah a zdroje do jednoho řetězce dokumentu. Řetězec se použije v příkazovém řádku, který odešlete do jazykového modelu v dalším kroku toku.
Definování variant výzvy
Při vytváření výzvy, kterou chcete odeslat do jazykového modelu, můžete použít varianty k reprezentaci jiného obsahu výzvy.
Pokud do toku chatu zahrnete RAG, vaším cílem je uzemnění odpovědí chatbota. Vedle načtení relevantního kontextu ze zdroje dat můžete také ovlivnit základ odpovědi chatovacího robota tím, že mu dá pokyn, aby používal kontext a aby byl faktický.
S variantami výzvy můžete na příkazovém řádku zadat různé systémové zprávy, abyste prozkoumali, který obsah poskytuje nejemovější.
Chat s kontextem
Nakonec pomocí uzlu LLM odešlete výzvu jazykovému modelu k vygenerování odpovědi pomocí relevantního kontextu načteného ze zdroje dat. Odpověď z tohoto uzlu je také výstupem celého toku.
Jakmile nakonfigurujete ukázkový tok chatu tak, aby používal indexovaná data a jazykový model podle vašeho výběru, můžete tok nasadit a integrovat ho s aplikací a nabídnout uživatelům prostředí copilotu.