Příjem a integrace dat
Příjem a integrace dat tvoří základní vrstvu pro efektivní zpracování dat v deklarativních kanálech Lakeflow v Rámci Azure Databricks. Tím zajistíte, že se data z různých zdrojů přesně a efektivně načtou do systému pro další analýzu a zpracování.
Deklarativní kanály Lakeflow usnadňují příjem a integraci dat prostřednictvím:
- Příjem dat ve více zdrojích: umožňuje shromažďovat data z různých zdrojů.
- Zpracování streamů a dávkových dat: umožňuje zpracovávat data nepřetržitě nebo v seskupených intervalech.
- Správa schématu: zajišťuje, že vaše data jsou dobře strukturovaná a snadno se spravují.
- Kvalita dat a zásady správného řízení: Pomáhá udržovat integritu a dodržování předpisů vašich dat.
- Automatizace a orchestrace kanálů: zjednodušuje a řídí posloupnost úloh zpracování dat.
- Integrace s ekosystémem Azure: Umožňuje bezproblémovou interakci s různými nástroji a službami Azure.
- Optimalizace výkonu: zlepšuje schopnost rychle a efektivně zpracovávat data.
- Sledování rodokmenu a sledování rodokmenu: pomáhá sledovat cestu k datům a monitorovat jejich pohyb v systému.
Vytvořit potrubí
Nejprve vytvoříte kanál ETL v deklarativních kanálech Lakeflow. Deklarativní kanály Lakeflow vytvářejí kanály překladem závislostí definovaných v poznámkových blocích nebo souborech (označovaných jako zdrojový kód) pomocí syntaxe deklarativních kanálů Lakeflow. Každý soubor zdrojového kódu může obsahovat pouze jeden jazyk, ale do kanálu můžete přidat více poznámkových bloků nebo souborů specifických pro jazyk.
V pracovním prostoru můžete vytvořit nový kanál ETL z části Úlohy a Kanály na bočním panelu. Měli byste přiřadit název kanálu, nakonfigurovat poznámkový blok nebo soubory , které obsahují zdrojový kód, a nastavit cílové umístění úložiště a schéma.
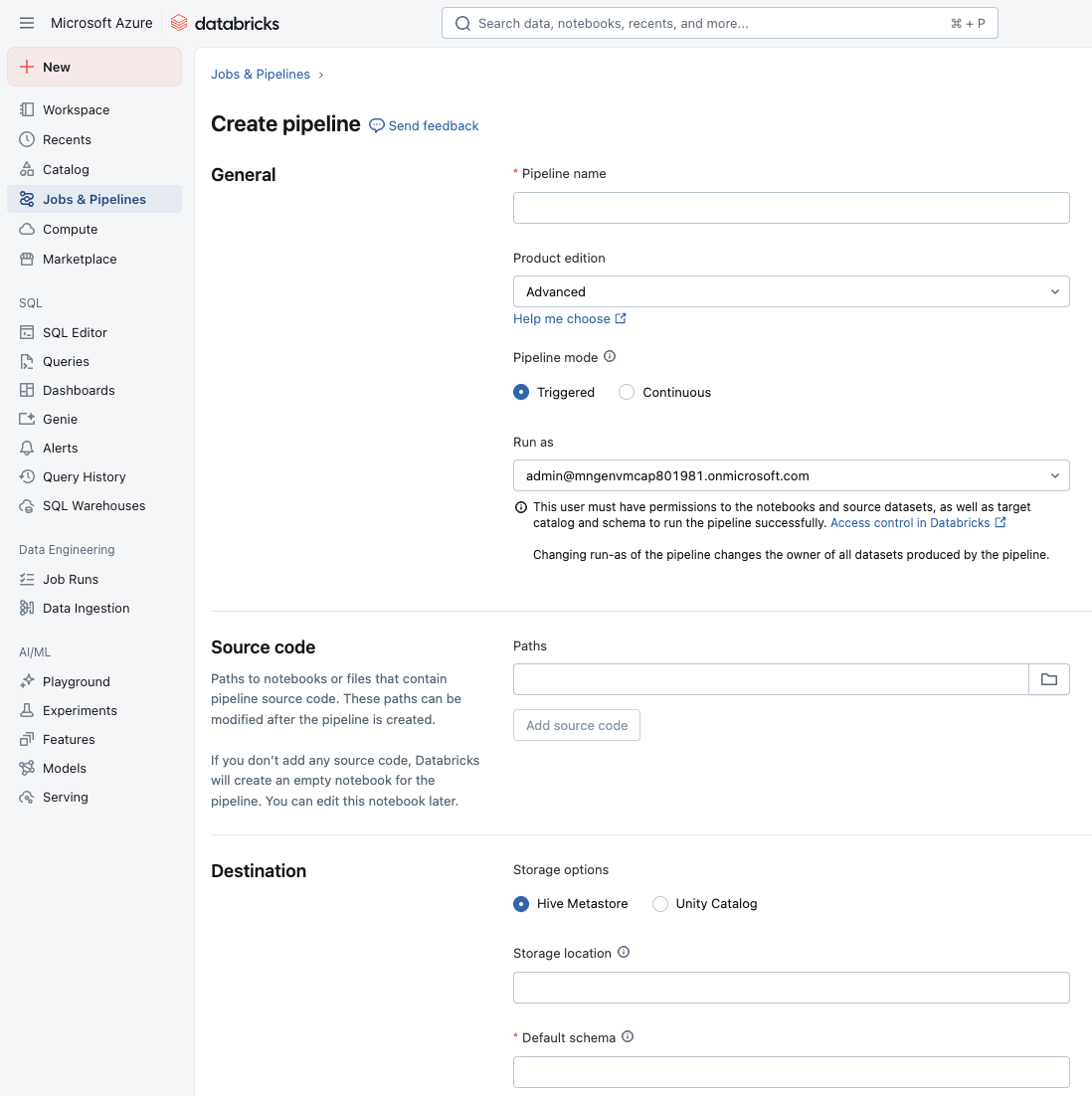
Načtení z existující tabulky
V poznámkovém bloku můžete načíst data z jakékoli existující tabulky v Databricks. Data můžete transformovat pomocí dotazu nebo načíst tabulku pro další zpracování ve zpracovatelském řetězci.
CREATE OR REFRESH MATERIALIZED VIEW top_baby_names_2021
COMMENT "A table summarizing counts of the top baby names for New York for 2021."
AS SELECT
First_Name,
SUM(Count) AS Total_Count
FROM baby_names_prepared
WHERE Year_Of_Birth = 2021
GROUP BY First_Name
ORDER BY Total_Count DESC
Načtení souborů z cloudového úložiště objektů
Databricks doporučuje používat Auto Loader s deklarativními pipeline Lakeflow pro většinu úloh příjmu dat z cloudového úložiště objektů nebo ze souborů ve svazku katalogu Unity. Deklarativní potrubí Auto Loader a Lakeflow jsou navržena pro postupné a idempotentní načítání neustále se rozšiřujících dat, jakmile dorazí do cloudového úložiště.
Automatický zavaděč může importovat JSON, CSV, XML, PARQUET, AVRO, ORC, TEXT, a BINARYFILE formáty souborů.
Následující příklad SQL načítá data z cloudového úložiště pomocí automatického zavaděče dat:
CREATE OR REFRESH STREAMING TABLE sales
AS SELECT *
FROM STREAM read_files(
'abfss://myContainer@myStorageAccount.dfs.core.windows.net/analysis/*/*/*.json',
format => "json"
);
Následující příklad SQL používá Automatický zaváděč k vytvoření datových sad ze souborů CSV ve svazku Unity Catalogu.
CREATE OR REFRESH STREAMING TABLE customers
AS SELECT * FROM STREAM read_files(
"/Volumes/my_catalog/retail_org/customers/",
format => "csv"
)
Analýza JSON
V deklarativních kanálech Lakeflow můžete při parsování dat JSON pomocí funkce from_jsonnechat systém automaticky zjistit schéma JSON (odvozování) a upravit je v průběhu času (vývoj) místo předem pevně zakódování schématu. To je užitečné, když schémata nejsou předem známá nebo když se často mění.
Každý from_json výraz, když je nastaven pro odvozování + vývoj, potřebuje jedinečný identifikátor označovaný jako schemaLocationKey. Umožňuje systému sledovat, které schéma JSON patří do kterého parsujícího výrazu. Pokud máte v kanálu více výrazů pro analýzu JSON, musí každý výraz používat jedinečný klíč schemaLocationKey. Klíč musí být také jedinečný v kontextu daného kanálu.
Tady je příklad použití syntaxe SQL demonstrující nastavení argumentu schématu na hodnotu NULL, což signalizovalo, že schéma by mělo být odvozeno spíše než opraveno:
SELECT
value,
from_json(value, NULL, map('schemaLocationKey', 'keyX')) parsedX,
from_json(value, NULL, map('schemaLocationKey', 'keyY')) parsedY,
FROM STREAM READ_FILES('/databricks-datasets/nyctaxi/sample/json/', format => 'text')
Místo toho máte možnost použít pevné schéma s from_json(jsonStr, schema, ...). Pokud zvolíte pevné schéma, nebude se používat odvození a vývoj. Také rady schématu jsou užitečné, když chcete pevné schéma, ale také chcete předvídat nebo zpracovávat posun schématu.
Tady je příklad v SQL, kde dotaz vezme řetězec JSON obsahující dvě pole, a a b a parsuje ho do strukturovaného objektu pomocí schématu zadaného v druhém argumentu. V této části schéma deklaruje jako celé číslo a b jako dvojité, takže výsledek je STRUCT<a: INT, b: DOUBLE>
SELECT from_json('{"a":1, "b":0.8}', 'a INT, b DOUBLE');
Správa kvality dat s očekáváními kanálu
Volitelně můžete použít očekávání k použití omezení kvality, která ověřují data při jejich toku prostřednictvím kanálů ETL. Očekávání poskytují lepší přehled o metrikách kvality dat a umožňují selhání aktualizací nebo vyřazení záznamů při zjišťování neplatných záznamů.
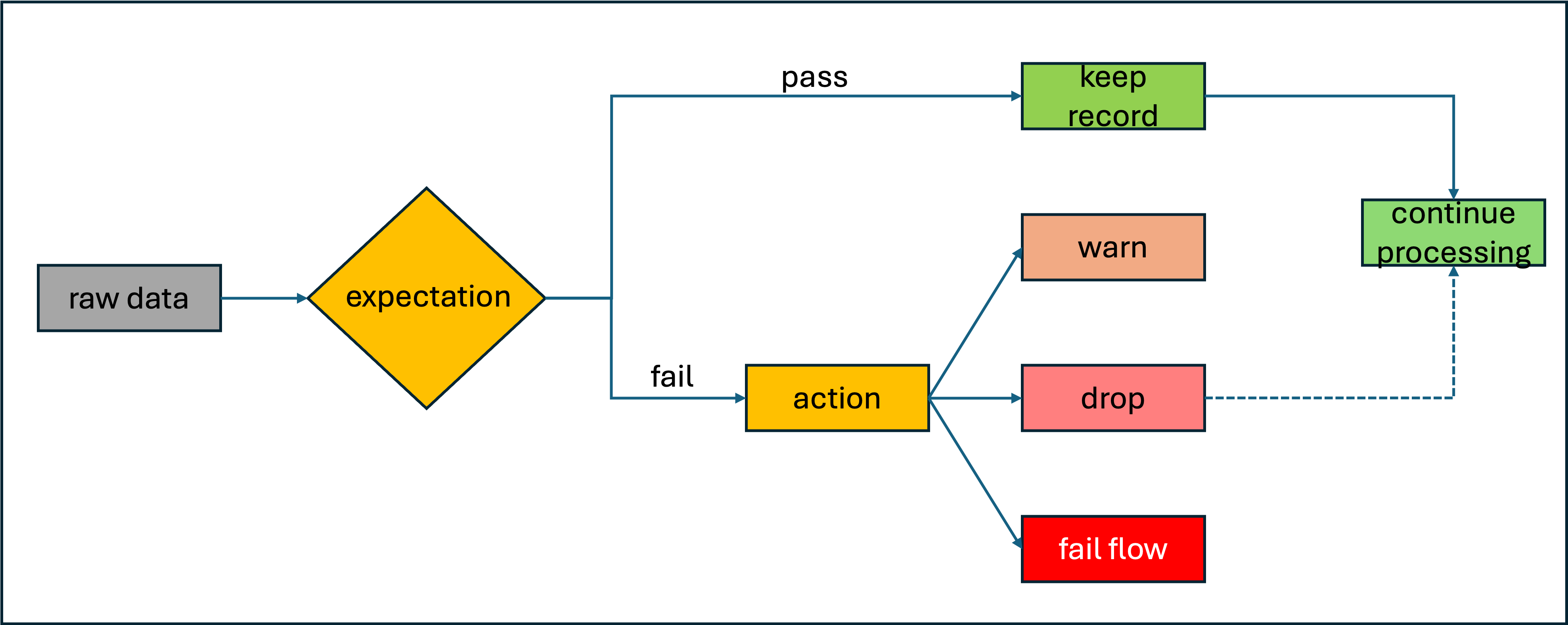
Tady je příklad materializovaného zobrazení, které definuje klauzuli constraint. V tomto případě omezení obsahuje skutečnou logiku pro to, co se ověřuje: Country_Region by nemělo být prázdné. Pokud záznam selže s touto podmínkou, aktivuje se očekávání.
CREATE OR REFRESH MATERIALIZED VIEW processed_covid_data (
CONSTRAINT valid_country_region EXPECT (Country_Region IS NOT NULL) ON VIOLATION FAIL UPDATE
)
COMMENT "Formatted and filtered data for analysis."
AS
SELECT
TO_DATE(Last_Update, 'MM/dd/yyyy') as Report_Date,
Country_Region,
Confirmed,
Deaths,
Recovered
FROM live.raw_covid_data;
Příklady omezení:
-- Simple constraint
CONSTRAINT non_negative_price EXPECT (price >= 0) ON VIOLATION DROP ROW
-- SQL functions
CONSTRAINT valid_date EXPECT (year(transaction_date) >= 2020) ON VIOLATION FAIL UPDATE
-- CASE statements
CONSTRAINT valid_order_status EXPECT (
CASE
WHEN type = 'ORDER' THEN status IN ('PENDING', 'COMPLETED', 'CANCELLED')
WHEN type = 'REFUND' THEN status IN ('PENDING', 'APPROVED', 'REJECTED')
ELSE false
END
)
-- Multiple constraints
CONSTRAINT non_negative_price EXPECT (price >= 0),
CONSTRAINT valid_purchase_date EXPECT (date <= current_date())
-- Complex business logic
CONSTRAINT valid_subscription_dates EXPECT (
start_date <= end_date
AND end_date <= current_date()
AND start_date >= '2020-01-01'
)
-- Complex boolean logic
CONSTRAINT valid_order_state EXPECT (
(status = 'ACTIVE' AND balance > 0)
OR (status = 'PENDING' AND created_date > current_date() - INTERVAL 7 DAYS)
)
Zachování neplatných záznamů je výchozím chováním pro očekávání. Záznamy, které porušují očekávání, se přidají do cílové datové sady spolu s platnými záznamy. Pokud zadáte ON VIOLATION DROP ROW, záznamy, které porušují očekávání, se z cílové datové sady zahodí. Nakonec, pokud zadáte ON VIOLATION FAIL UPDATE, pak systém atomicky vrátí zpět transakce.
Použití transformací
Data můžete transformovat pomocí dotazu, stejně jako u standardních příkazů SQL. V následujícím příkladu definujeme další materializované zobrazení, které agreguje data.
CREATE OR REFRESH MATERIALIZED VIEW aggregated_covid_data
COMMENT "Aggregated daily data for the US with total counts."
AS
SELECT
Report_Date,
sum(Confirmed) as Total_Confirmed,
sum(Deaths) as Total_Deaths,
sum(Recovered) as Total_Recovered
FROM live.processed_covid_data
GROUP BY Report_Date;
Spuštění a monitorování kanálu ETL
Po definování kódu v poznámkových blocích nebo souborech zdrojového kódu můžete spustit kanál ETL. K monitorování provádění můžete použít vizuální rozhraní:
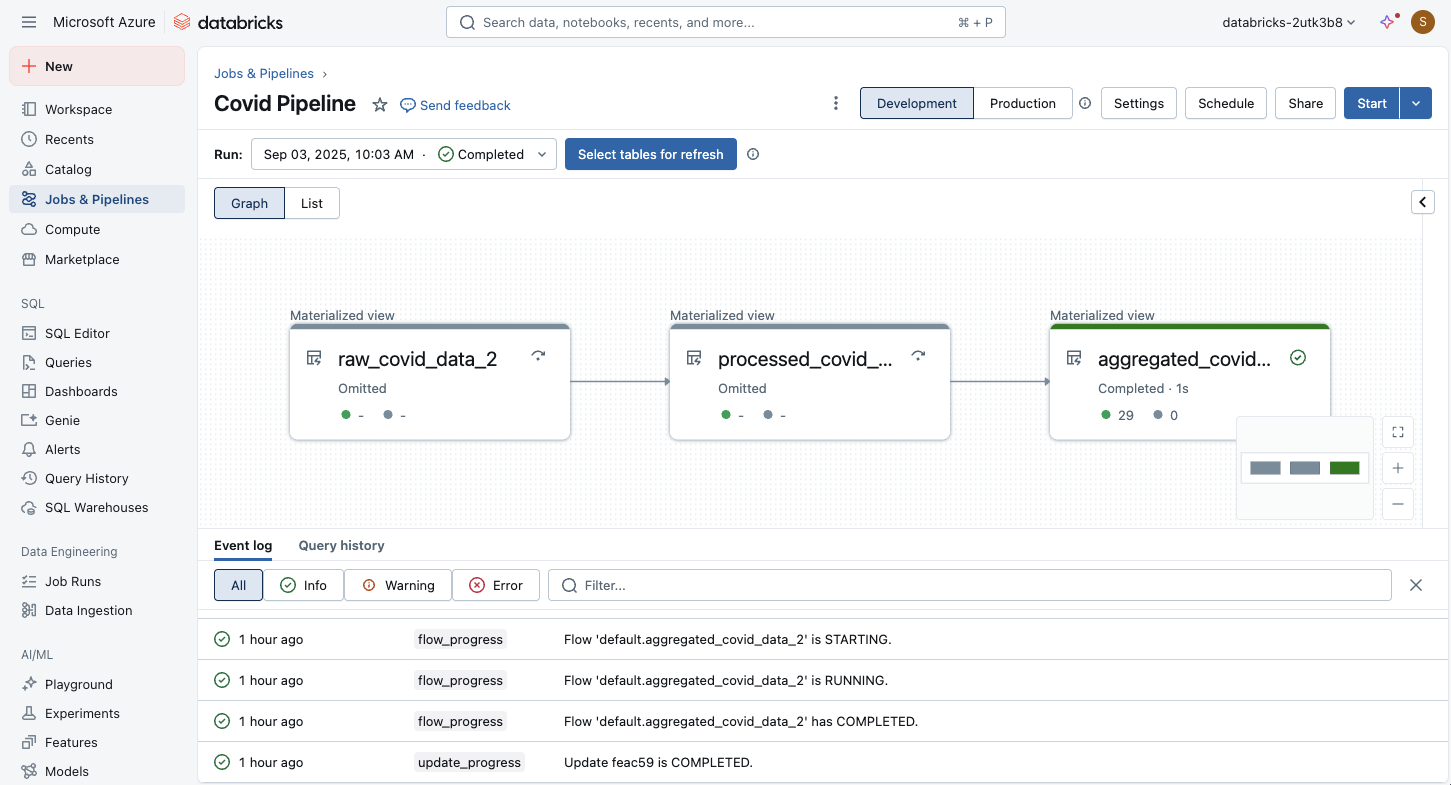
Graf pipeline se zobrazí, jakmile se úspěšně spustí aktualizace pipeline. Šipky představují závislosti mezi datovými sadami v potrubí. Ve výchozím nastavení se na stránce podrobností datového toku zobrazuje nejnovější aktualizaci tabulky, ale starší aktualizace můžete vybrat z rozevírací nabídky.
Deklarativní kanály Lakeflow podporují úlohy, jako jsou:
- Sledování průběhu a stavu aktualizací potrubí.
- Upozornění na události v kanálu, jako je úspěch nebo neúspěch aktualizací kanálu.
- Zobrazení metrik pro streamované zdroje, jako jsou Apache Kafka a Auto Loader
- Příjem e-mailových oznámení, když se aktualizace kanálu nezdaří nebo úspěšně dokončí