Použití rozhraní API pro převod řeči na text
Tip
Další podrobnosti najdete na kartě Text a obrázky .
Azure Speech in Foundry Tools podporuje rozpoznávání řeči prostřednictvím rozhraní API Pro převod řeči na text*. Konkrétní podrobnosti se liší v závislosti na používané sadě SDK (Python, C#atd.); Existuje konzistentní vzor pro použití rozhraní Speech na text API:
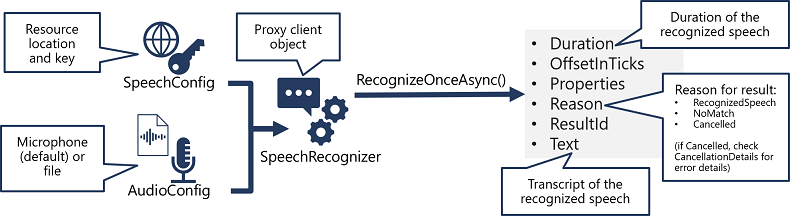
- Pomocí objektu SpeechConfig zapouzdřte informace potřebné pro připojení k vašemu prostředku Foundry. Konkrétně jeho koncový bod (nebo oblast) a klíč.
- Volitelně můžete použít AudioConfig k definování vstupního zdroje pro přepis zvuku. Ve výchozím nastavení se jedná o výchozí systémový mikrofon, ale můžete také zadat zvukový soubor.
- Pomocí SpeechConfig a AudioConfig vytvořte objekt SpeechRecognizer. Tento objekt je proxy klient pro Speech na text API.
- K volání základních funkcí rozhraní API použijte metody SpeechRecognizer objektu. Například metoda RecognizeOnceAsync() používá službu Azure Speech k asynchronnímu přepisu jedné mluvené promluvy.
- Zpracování odpovědi V případě metody RecognizeOnceAsync() je výsledkem SpeechRecognitionResult objekt, který obsahuje následující vlastnosti:
- Doba trvání
- OffsetInTicks
- Vlastnosti
- Důvod
- Identifikátor výsledku
- Text
Pokud byla operace úspěšná, vlastnost Reason má hodnotu výčtu RecognizedSpeecha vlastnost Text obsahuje přepis. Mezi další možné hodnoty Výsledek patří NoMatch (označující, že se zvuk úspěšně parsoval, ale nerozpoznal se žádný projev) nebo Zrušeno, což znamená, že došlo k chybě (v takovém případě můžete zkontrolovat Vlastnosti kolekci CancellationReason vlastnost zjistit, co se nepovedlo).
Příklad – přepis zvukového souboru
Následující příklad Pythonu používá Azure Speech in Foundry Tools k přepisu řeči ve zvukovém souboru.
import azure.cognitiveservices.speech as speech_sdk
# Speech config encapsulates the connection to the resource
speech_config = speech_sdk.SpeechConfig(subscription="YOUR_FOUNDRY_KEY",
endpoint="YOUR_FOUNDRY_ENDPOINT")
# Audio config determines the audio stream source (defaults to system mic)
file_path = "audio.wav"
audio_config = speech_sdk.audio.AudioConfig(filename=file_path)
# Use a speech recognizer to transcribe the audio
speech_recognizer = speech_sdk.SpeechRecognizer(speech_config=speech_config,
audio_config=audio_config)
result = speech_recognizer.recognize_once_async().get()
# Did it succeeed
if result.reason == speech_sdk.ResultReason.RecognizedSpeech:
# Yes!
print(f"Transcription:\n{result.text}")
else:
# No. Try to determine why.
print("Error transcribing message: {}".format(result.reason))