Použití rozhraní API pro převod textu na řeč
Podobně jako rozhraní API pro převod řeči na text nabízí Azure Speech v nástroji Foundry rozhraní API pro převod textu na řeč pro syntézu řeči.
Stejně jako u rozpoznávání řeči se většina interaktivních aplikací s podporou řeči vytváří pomocí sady Azure Speech SDK.
Vzor pro implementaci syntézy řeči je podobný způsobu rozpoznávání řeči:
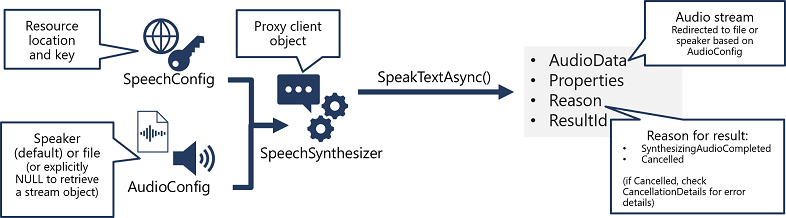
- Pomocí objektu SpeechConfig zapouzdřte informace potřebné pro připojení k vašemu prostředku Azure Speech. Konkrétně jeho umístění a klíč.
- Volitelně můžete použít AudioConfig k definování výstupního zařízení pro syntetizaci řeči. Ve výchozím nastavení se jedná o výchozí systémový reproduktor, ale můžete také zadat zvukový soubor nebo explicitně nastavit tuto hodnotu na hodnotu null, můžete zpracovat objekt zvukového streamu, který se vrátí přímo.
- K vytvoření objektu SpeechSynthesizer použijte SpeechConfig a AudioConfig. Tento objekt je proxy klient pro rozhraní API pro převod textu na řeč .
- K volání základních funkcí rozhraní API použijte metody objektu SpeechSynthesizer . Například metoda SpeakTextAsync() používá službu Azure Speech k převodu textu na mluvený zvuk.
- Zpracujte odpověď ze služby Azure Speech. V případě SpeakTextAsync metoda je výsledkem SpeechSynthesisResult objekt, který obsahuje následující vlastnosti:
- AudioData
- Vlastnosti
- Důvod
- Identifikátor výsledku
Pokud byla řeč úspěšně syntetizována, je vlastnost Reason nastavena na SynthesizingAudioCompleted výčtu a AudioData vlastnost obsahuje zvukový stream (který v závislosti na AudioConfig může být automaticky odeslán do reproduktoru nebo souboru).
Příklad – syntetizace textu jako řeči
Následující příklad Pythonu používá Azure Speech in Foundry Tools k vygenerování mluveného výstupu z textu.
import azure.cognitiveservices.speech as speechsdk
# Speech config encapsulates the connection to the resource
speech_config = speechsdk.SpeechConfig(subscription=KEY, endpoint=ENDPOINT)
# Audio output config determines where to send the audio stream (defaults to speaker)
audio_config = speechsdk.audio.AudioOutputConfig(use_default_speaker=True)
# Use speech synthesizer to synthesize text as speech
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config,
audio_config=audio_config)
text = "My voice is my password!"
speech_synthesis_result = speech_synthesizer.speak_text_async(text).get()
# Did it succeeed?
if speech_synthesis_result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted:
# Yes!
print("Speech synthesized for text [{}]".format(text))
elif speech_synthesis_result.reason == speechsdk.ResultReason.Canceled:
# No - Ty to find out why not
cancellation_details = speech_synthesis_result.cancellation_details
print("Speech synthesis canceled: {}".format(cancellation_details.reason))
if cancellation_details.reason == speechsdk.CancellationReason.Error:
if cancellation_details.error_details:
print("Error details: {}".format(cancellation_details.error_details))