Porozumění modelu a jeho testování
Vytvořili jsme model strojového učení! Pojďme to otestovat a podívat se, jak dobře funguje.
Výkon modelu
Custom Vision při testování modelu zobrazí tři metriky. Metriky jsou indikátory, které vám pomůžou pochopit, jak model funguje. Indikátory neudávají , jak je model faktický nebo přesný. Indikátory vám řeknou jenom to, jak model fungoval s daty, která jste zadali. Jak dobře model fungoval se známými daty, vám poskytne představu o tom, jak bude model fungovat s novými daty.
Pro celý model a pro každou třídu jsou k dispozici následující metriky:
| Metrický | Popis |
|---|---|
precision |
Pokud váš model predikuje značku, tato metrika udává, jak pravděpodobné je, že byla předpovězena správná značka. |
recall |
Z značek by model měl správně predikovat, tato metrika označuje procento značek, které model správně predikoval. |
average precision |
Měří výkon modelu tím, že vypočítá přesnost a úplnost při různých prahových hodnotách. |
Při testování modelu Custom Vision uvidíme čísla pro každou z těchto metrik ve výsledcích testu iterace.
Běžné chyby
Než model otestujeme, podívejme se na některé "chyby začátečníka" a podívejme se, kdy začnete vytvářet modely strojového učení.
Použití nevyvážených dat
Při nasazení modelu se může zobrazit toto upozornění:
Unbalanced data detected. The distribution of images per tag should be uniform to ensure model performance.
Toto upozornění znamená, že pro každou třídu dat nemáte sudý počet vzorků. I když máte v tomto scénáři několik možností, běžným způsobem, jak vyřešit nevyvážená data, je použít syntetickou menšinovou metodu over-vzorkování (SMOTE). SMOTE duplikuje příklady trénování z existujícího trénovacího fondu.
Poznámka:
V našem modelu se toto upozornění nemusí zobrazit, zejména pokud jste nahráli zlomek datové sady. Podmnožina dat modelu Red-tailed Hawk (Dark morph) obsahuje méně než 60 fotek v porovnání s jinými modely, které mají více než 100 fotografií. Použití nevyrovnaných dat je něco, co je potřeba sledovat v jakémkoli modelu strojového učení.
Přeurčení modelu
Pokud nemáte dostatek dat nebo pokud vaše data nejsou dostatečně různorodá, může se model převyšovat. Když je model pře fitovaný, dobře zná zadanou datovou sadu a je přetěžovaný na vzory v datech. V tomto případě model dobře funguje s trénovacími daty, ale špatně funguje s novými daty, která ještě neviděla. Z tohoto důvodu vždy k otestování modelu používáme nová data.
Testování pomocí trénovacích dat
Stejně jako při přeurčení model otestujete pomocí stejných dat, která jste použili k trénování modelu, zdá se, že model funguje dobře. Když ale model nasadíte do produkčního prostředí, s největší pravděpodobností bude fungovat špatně.
Použití chybná data
Další běžnou chybou je použití chybná data k trénování modelu. Některá data můžou ve skutečnosti snížit přesnost modelu. Například použití dat, která jsou "hlučná", může snížit přesnost modelu. V hlučnýchdatech Více dat je lepší jenom v případě, že data jsou dobrá data, která model může použít. Možná budete muset vyčistit data nebo odebrat funkce, aby se zlepšila přesnost modelu.
Test modelu
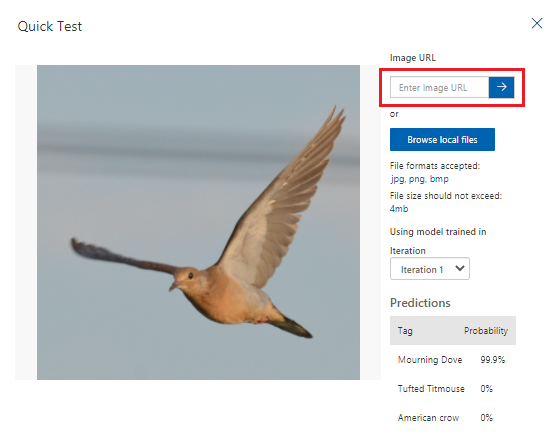
Podle metrik, které Služba Custom Vision poskytuje, náš model funguje na uspokojivé úrovni. Pojďme model otestovat a zjistit, jak funguje na dosud nespatřených datech. Použijeme obrázek ptáka z internetového vyhledávání.
Ve webovém prohlížeči vyhledejte obrázek ptáka, který odpovídá jednomu z druhů, které jste vytrénovali, aby model rozpoznal. Zkopírujte adresu URL obrázku.
V horním řádku nabídek vyberte Rychlý test.
V rychlém testu vložte adresu URL do adresy URL obrázku a stisknutím klávesy Enter otestujte přesnost modelu. V okně se zobrazí předpověď.
Custom Vision analyzuje obrázek a otestuje přesnost modelu a zobrazí výsledky:
V dalším kroku model nasadíme. Po nasazení modelu můžeme provést další testování pomocí koncového bodu, který vytvoříme.