Prozkoumání řešení vysoké dostupnosti a zotavení po havárii IaaS
Existuje mnoho různých kombinací funkcí, které je možné nasadit v Azure pro IaaS. Tato část se zabývá pěti běžnými příklady architektur SQL Serveru s vysokou dostupností a zotavením po havárii (HADR) v Azure.
Příklad vysoké dostupnosti v jedné oblasti 1 – skupiny dostupnosti AlwaysOn
Pokud potřebujete jenom vysokou dostupnost, a ne zotavení po havárii, konfigurace skupiny dostupnosti (skupina dostupnosti) je jednou z nejobsádnějších metod bez ohledu na to, kde používáte SQL Server. Následující obrázek je příkladem toho, jak by jedna možná skupina dostupnosti v jedné oblasti mohla vypadat.
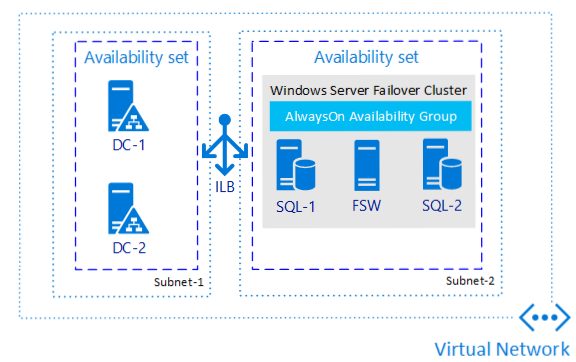
Proč je tato architektura stojí za zvážení?
Tato architektura chrání data tím, že má více než jednu kopii na různých virtuálních počítačích.
Tato architektura umožňuje splnit plánovanou dobu obnovení (RTO) a cíl bodu obnovení (RPO) s minimální a žádnou ztrátou dat, pokud je správně implementována.
Tato architektura poskytuje jednoduchou standardizovanou metodu pro aplikace pro přístup k primárním i sekundárním replikám (pokud se použijí repliky jen pro čtení).
Tato architektura poskytuje vylepšenou dostupnost během scénářů oprav.
Tato architektura nepotřebuje žádné sdílené úložiště, takže při použití instance clusteru s podporou převzetí služeb při selhání (FCI) je méně komplikací.
Příklad vysoké dostupnosti v jedné oblasti 2 – instance clusteru s podporou převzetí služeb při selhání AlwaysOn
Až do zavedení skupin dostupnosti byly FCI nejoblíbenějším způsobem implementace vysoké dostupnosti SQL Serveru. FcI však byly navrženy, když byla fyzická nasazení dominantní. Ve virtualizovaném světě fci neposkytují mnoho stejných ochrany způsobem, jakým by byli na fyzickém hardwaru, protože je vzácné, aby virtuální počítač měl problém. FcI byly navrženy tak, aby chránily před věcmi, jako je selhání síťové karty nebo selhání disku, z nichž obě pravděpodobně nedojde v Azure.
Jak už bylo řečeno, FCI mají místo v Azure. Fungují a pokud máte správná očekávání ohledně toho, co je a není poskytováno, je FCI dokonale přijatelné řešení. Následující obrázek z dokumentace Microsoftu ukazuje základní pohled na to, jak vypadá nasazení FCI při použití Prostory úložiště s přímým přístupem.
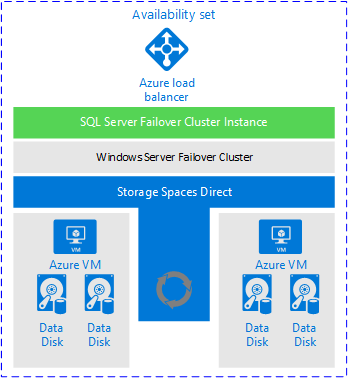
Proč je tato architektura stojí za zvážení?
FcI jsou stále oblíbeným řešením dostupnosti.
Scénář sdíleného úložiště se vylepšuje pomocí funkce, jako je sdílený disk Azure.
Tato architektura splňuje většinu rto a cíle bodu obnovení pro vysokou dostupnost (i když zotavení po havárii není zpracováno).
Tato architektura poskytuje jednoduchou standardizovanou metodu pro aplikace pro přístup ke clusterované instanci SQL Serveru.
Tato architektura poskytuje vylepšenou dostupnost během scénářů oprav.
Příklad zotavení po havárii 1 – Skupina dostupnosti AlwaysOn s více oblastmi nebo hybridním prostředím
Pokud používáte skupiny dostupnosti, jednou z možností je konfigurace skupiny dostupnosti napříč několika oblastmi Azure nebo potenciálně jako hybridní architektura. To znamená, že všechny uzly, které obsahují repliky, se účastní stejné WSFC. To předpokládá dobré připojení k síti, zejména pokud se jedná o hybridní konfiguraci. Jedním z největších aspektů by byl prostředek určující pro WSFC. Tato architektura by vyžadovala, aby služba AD DS a DNS byla dostupná v každé oblasti a potenciálně i v místním prostředí, pokud se jedná o hybridní řešení. Následující obrázek ukazuje, jak vypadá jedna skupina dostupnosti nakonfigurovaná přes dvě umístění pomocí Windows Serveru.

Proč je tato architektura stojí za zvážení?
Tato architektura je prověřeným řešením; v topologii skupiny dostupnosti se nijak neliší od současného používání dvou datových center.
Tato architektura funguje s edicemi Standard a Enterprise SQL Serveru.
Skupiny AG přirozeně poskytují redundanci s dalšími kopiemi dat.
Tato architektura využívá jednu funkci, která poskytuje vysokou dostupnost i D/R.
Příklad zotavení po havárii 2 – Distribuovaná skupina dostupnosti
Distribuovaná skupina dostupnosti je funkce edice Enterprise představená jenom v SQL Serveru 2016. Liší se od tradiční skupiny dostupnosti. Místo toho, abyste měli jednu základní WSFC, kde všechny uzly obsahují repliky, které se účastní jedné skupiny dostupnosti, jak je popsáno v předchozím příkladu, se distribuovaná skupina dostupnosti skládá z několika skupin dostupnosti. Primární replika obsahující databázi pro čtení zápisu se označuje jako globální primární. Primární skupina dostupnosti je známá jako předávací služba a udržuje sekundární repliky této skupiny dostupnosti synchronizované. V podstatě se jedná o skupiny dostupnosti skupin dostupnosti.
Tato architektura usnadňuje řešení věcí, jako je kvorum, protože každý cluster by zachoval vlastní kvorum, což znamená, že má také vlastní určující složku. Distribuovaná skupina dostupnosti by fungovala bez ohledu na to, jestli používáte Azure pro všechny prostředky, nebo pokud používáte hybridní architekturu.
Následující obrázek ukazuje příklad konfigurace distribuované skupiny dostupnosti. Existují dva řadiče WSFCs. Představte si, že každá je v jiné oblasti Azure nebo je místně a druhá je v Azure. Každá SLUŽBA WSFC má skupiny dostupnosti se dvěma replikami. Globální primární server ve skupině dostupnosti 1 uchovává sekundární repliku skupiny dostupnosti 1 synchronizovanou i předávací nástroj, což je také primární skupina dostupnosti 2. Tato replika uchovává sekundární repliku skupiny dostupnosti 2 synchronizovanou.
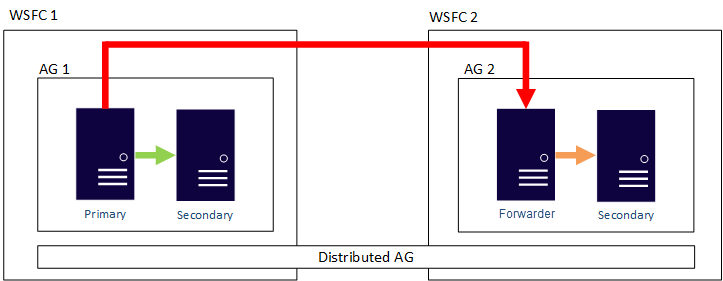
Proč je tato architektura stojí za zvážení?
Tato architektura odděluje WSFC jako jediný bod selhání, pokud všechny uzly ztratí komunikaci.
V této architektuře se jedna primární nesynchronuje všechny sekundární repliky.
Tato architektura může poskytovat navrácení služeb po obnovení z jednoho umístění do jiného.
Příklad zotavení po havárii 3 – Přesouvání protokolů
Přesouvání protokolů je jednou z nejstarších metod HADR pro konfiguraci zotavení po havárii pro SQL Server. Jak je popsáno výše, měrnou jednotkou je záloha transakčního protokolu. Pokud se nepřepne do aktivního pohotovostního režimu, aby se zajistilo, že nedojde ke ztrátě dat, pravděpodobně dojde ke ztrátě dat. Pokud jde o zotavení po havárii, je vždy nejlepší předpokládat určitou ztrátu dat, i když je minimální. Následující obrázek z dokumentace Microsoftu ukazuje ukázkovou topologii přesouvání protokolů.
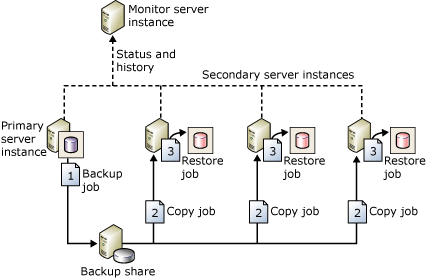
Proč je tato architektura stojí za zvážení?
Přesouvání protokolů je vyzkoušená a pravdivá funkce, která už více než 20 let existuje.
Přesouvání protokolů je snadné nasadit a spravovat, protože je založené na zálohování a obnovení.
Přesouvání protokolů je odolné vůči sítím, které nejsou robustní.
Přesouvání protokolů splňuje většinu cílů RTO a RPO pro zotavení po havárii.
Přesouvání protokolů je dobrým způsobem, jak chránit FCI.
Příklad zotavení po havárii 4 – Azure Site Recovery
Pro ty, kteří nechtějí implementovat řešení havárie založené na SQL Serveru, je azure Site Recovery potenciální možností. Většina odborníků na data ale preferuje přístup orientovaný na databázi, protože obecně bude mít nižší cíl bodu obnovení.
Následující obrázek z dokumentace Microsoftu ukazuje, kde na webu Azure Portal byste nakonfigurovali replikaci pro Azure Site Recovery.
Proč je tato architektura stojí za zvážení?
Azure Site Recovery bude fungovat s více než jen s SQL Serverem.
Azure Site Recovery může splňovat RTO a možná cíl bodu obnovení.
Azure Site Recovery se poskytuje jako součást platformy Azure.