Prozkoumání architektury MLOps
Jako datový vědec chcete vytrénovat nejlepší model strojového učení. Pokud chcete model implementovat, chcete ho nasadit do koncového bodu a integrovat ho s aplikací.
V průběhu času můžete model přetrénovat. Model můžete například přetrénovat, když máte více trénovacích dat.
Obecně platí, že jakmile vytrénujete model strojového učení, budete chtít model připravit na podnikové škálování. Pokud chcete model připravit a zprovoznit, chcete:
- Převeďte trénování modelu na robustní a reprodukovatelný kanál.
- Otestujte kód a model ve vývojovém prostředí.
- Nasaďte model v produkčním prostředí.
- Automatizujte kompletní proces.
Nastavení prostředí pro vývoj a produkci
V rámci MLOps podobně jako DevOps odkazuje prostředí na kolekci prostředků. Tyto prostředky se používají k nasazení aplikace nebo k nasazení modelu pomocí projektů strojového učení.
Poznámka:
V tomto modulu se podíváme na interpretaci prostředí DevOps. Všimněte si, že Azure Machine Učení také používá termínová prostředí k popisu kolekce balíčků Pythonu potřebných ke spuštění skriptu. Tyto dva koncepty prostředí jsou nezávislé na sobě.
Kolik prostředí pracujete, závisí na vaší organizaci. Běžně existují aspoň dvě prostředí: vývoj, vývoj, vývoj a produkční prostředí nebo prod. Kromě toho můžete přidat prostředí mezi pracovní nebo předprodukční prostředí (předprodukční).
Typickým přístupem je:
- Experimentujte s trénováním modelů ve vývojovém prostředí.
- Přesuňte nejlepší model do přípravného nebo předem připraveného prostředí pro nasazení a otestování modelu.
- Nakonec model uvolněte do produkčního prostředí a nasaďte ho tak, aby ho koncoví uživatelé mohli využívat.
Uspořádání prostředí Azure Machine Učení
Při implementaci MLOps a práci s modely strojového učení ve velkém měřítku je osvědčeným postupem pracovat s samostatnými prostředími pro různé fáze.
Představte si, že váš tým používá vývojové, předem připravené a produžované prostředí. Ne všichni členové vašeho týmu by měli mít přístup ke všem prostředím. Datoví vědci můžou pracovat pouze v rámci vývojového prostředí s neprodukčními daty, zatímco technici strojového učení pracují na nasazení modelu v předprodukčním a prod prostředí s produkčními daty.
Samostatná prostředí usnadňují řízení přístupu k prostředkům. Každé prostředí je pak možné přidružit k samostatnému pracovnímu prostoru Azure Machine Učení.
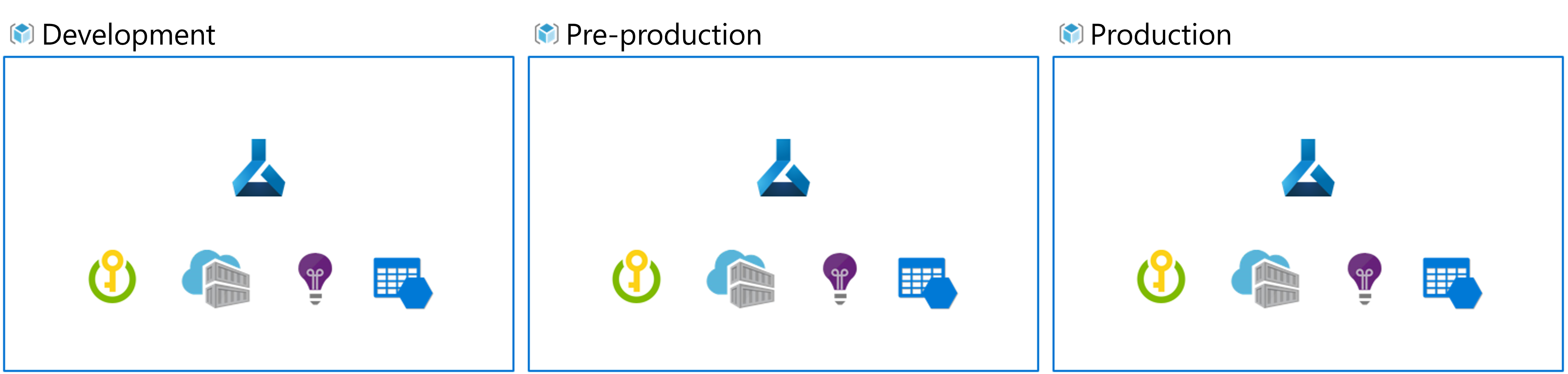
V Azure používáte řízení přístupu na základě role (RBAC) k tomu, abyste kolegům poskytli správnou úroveň přístupu k podmnožině prostředků, se kterými potřebují pracovat.
Alternativně můžete použít pouze jeden pracovní prostor azure machine Učení. Při použití jednoho pracovního prostoru pro vývoj a produkci máte menší nároky na Azure a méně režijních nákladů na správu. Řízení přístupu na základě role se ale vztahuje na vývojová a prodá prostředí, což může znamenat, že lidem dáváte příliš málo nebo příliš velký přístup k prostředkům.
Tip
Přečtěte si další informace o osvědčených postupech pro uspořádání prostředků azure machine Učení.
Návrh architektury MLOps
Přenesení modelu do produkčního prostředí znamená, že potřebujete škálovat řešení a spolupracovat s ostatními týmy. Společně s dalšími datovými vědci, datovými inženýry a týmem infrastruktury se můžete rozhodnout, že použijete následující přístup:
- Ukládejte všechna data do úložiště objektů blob v Azure spravovaném datovým inženýrem.
- Tým infrastruktury vytvoří všechny potřebné prostředky Azure, jako je pracovní prostor Azure Machine Učení.
- Datoví vědci se zaměřují na to, co dělají nejlépe: vývoj a trénování modelu (vnitřní smyčka).
- Technici strojového učení nasazují natrénované modely (vnější smyčka).
V důsledku toho architektura MLOps zahrnuje následující části:
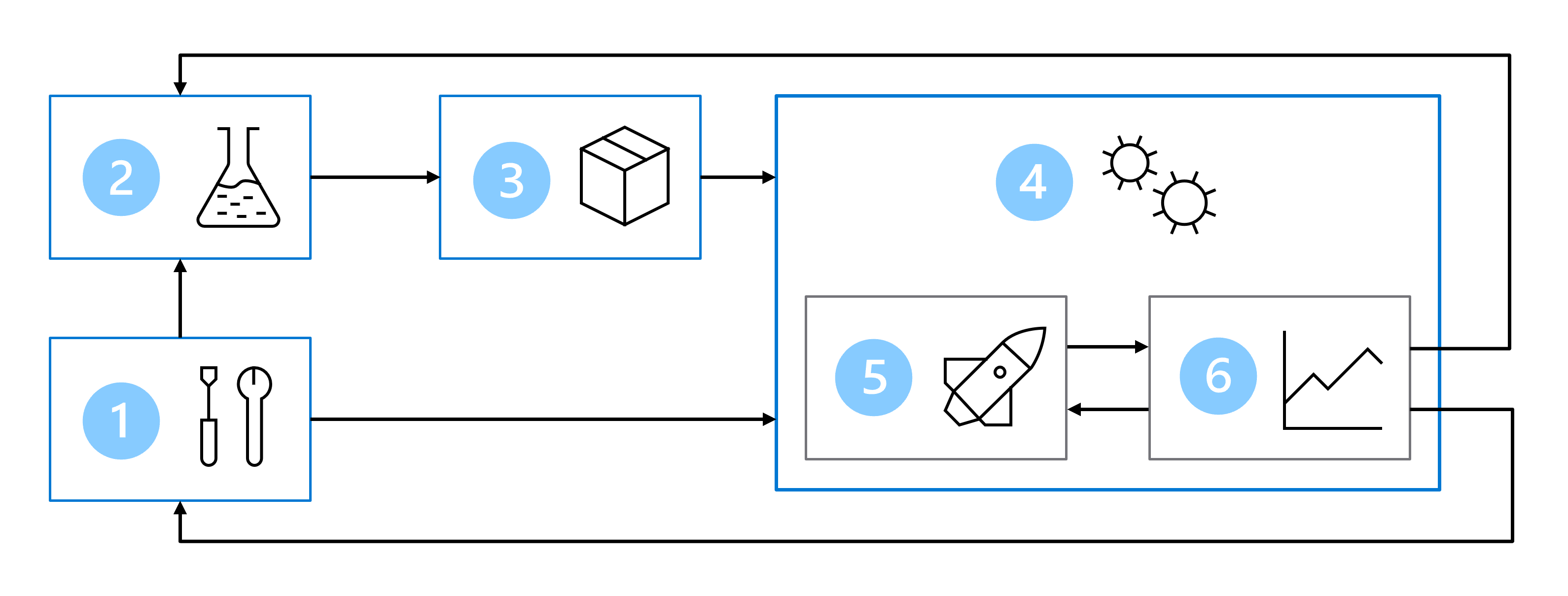
- Nastavení: Vytvořte všechny potřebné prostředky Azure pro řešení.
- Vývoj modelů (vnitřní smyčka):Prozkoumejte a zpracujte data pro trénování a vyhodnocení modelu.
- Kontinuální integrace: Zabalte a zaregistrujte model.
- Nasazení modelu (vnější smyčka): Nasaďte model.
- Průběžné nasazování: Otestujte model a propagujte ho do produkčního prostředí.
- Monitorování: Monitorování výkonu modelu a koncového bodu
Při práci s většími týmy se neočekává, že byste jako datový vědec zodpovídají za všechny části architektury MLOps. Pokud chcete model připravit na MLOps, měli byste se zamyslet nad tím, jak navrhnout monitorování a opětovné trénování.