Popis normalizace
Normalizace databáze je proces návrhu, který slouží k uspořádání dat do tabulek a sloupců v databázi. Každá tabulka by měla obsahovat data související s konkrétní entitou a obsahovat pouze informace, které tuto entitu podporují. Primárním cílem normalizace je minimalizovat duplicitní data v databázi, což pomáhá zabránit snížení výkonu během vkládání a aktualizací. Pokud je třeba například aktualizovat adresu zákazníka, je jednodušší implementovat změnu, pokud je adresa uložená v jednom umístění, například v Customers tabulce.
Nejběžnějšími formami normalizace jsou první, druhé a třetí normální formy.
První normální formulář
První normální formulář má následující specifikace:
- Vytvoření samostatné tabulky pro každou sadu souvisejících dat
- Eliminace opakujících se skupin v jednotlivých tabulkách
- Identifikace každé sady souvisejících dat pomocí primárního klíče
V tomto modelu byste se měli vyhnout použití více sloupců v jedné tabulce k ukládání podobných dat. Pokud například produkt může mít více barev, neměli byste mít v jednom řádku více sloupců obsahujících různé barevné hodnoty. První následující tabulka není v prvním normálním formátu, ProductColorsprotože obsahuje opakující se hodnoty pro barvu. U produktů s jedinou barvou je nevyužitý prostor. Kromě toho, pokud produkt přichází ve více než třech barvách, stává se nepraktické nastavit maximální počet sloupců. Místo toho můžeme tabulku vytvořit znovu, jak je znázorněno ve druhé tabulce. ProductColor
První normální formulář také vyžaduje, aby pro tabulku byl jedinečný klíč, což je sloupec (nebo sloupce), jehož hodnota jednoznačně identifikuje každý řádek. Ve druhé tabulce není žádný ze sloupců sám jedinečný, ale kombinace IDproduktu a barvy tvoří jedinečný klíč. Pokud k vytvoření jedinečného klíče potřebujete více sloupců, označuje se jako složený klíč.
ProductColorsstůl:Productid Barva 1 Color2 Barva 3 1 Červený Zelený Žlutý 2 Žlutý 3 Modrý Červený 4 Modrý 5 Červený ProductColorstůl:Productid Barva 1 Červený 1 Zelený 1 Žlutý 2 Žlutý 3 Modrý 3 Červený 4 Modrý 5 Červený
Třetí tabulka , je v prvním normálním formátu, ProductInfoprotože každý řádek odkazuje na konkrétní produkt, neexistují žádné opakující se skupiny a máme sloupec ProductID použít jako primární klíč.
| Productid | ProductName | Cena | ProductionCountry | Krátká poloha |
|---|---|---|---|---|
| 1 | widget | 15.95 | USA | USA |
| 2 | Foop | 41.95 | Spojené království | Spojené království |
| 3 | Glombit | 49.95 | Spojené království | Spojené království |
| 4 | Sorfin | 99.99 | Filipínská republika | RepPhil |
| 5 | Šroub kmene | 29.95 | USA | USA |
Druhý normální formulář
Druhý normální formulář má kromě těch, které vyžadují první normální formulář, následující specifikaci:
- Pokud tabulka obsahuje složený klíč, musí všechny atributy záviset na úplném klíči a ne jenom na jeho části.
Druhý normální formulář je relevantní pouze pro tabulky se složenými klíči, například v tabulce ProductColor, což je druhá tabulka. Vezměte v úvahu případ, ProductColor kdy tabulka obsahuje také cenu produktu. Tato tabulka má složený klíč zapnutý ProductID a Color, protože pouze pomocí obou hodnot sloupců můžeme jednoznačně identifikovat řádek. Pokud se cena produktu nezmění barvou, můžeme vidět data, jak je znázorněno v této tabulce.
| Productid | Barva | Cena |
|---|---|---|
| 1 | Červený | 15.95 |
| 1 | Zelený | 15.95 |
| 1 | Žlutý | 15.95 |
| 2 | Žlutý | 41.95 |
| 3 | Modrý | 49.95 |
| 3 | Červený | 49.95 |
| 4 | Modrý | 99,95 |
| 5 | Červený | 29.95 |
Tato tabulka není ve druhé normální podobě. Hodnota ceny závisí na hodnotě ProductID , ale ne na hodnotě Color. Existují tři řádky pro ProductID 1, takže cena produktu se opakuje třikrát. Problém s porušením druhého normálního formuláře je ten, že pokud potřebujeme aktualizovat cenu, musíme zajistit, aby se aktualizoval všude. Pokud aktualizujeme cenu v prvním řádku, ale ne ve druhém nebo třetím, dojde k anomálii aktualizace. Po aktualizaci bychom nemohli určit skutečnou cenu ProductID 1za . Řešením je přesunout Price sloupec do tabulky, která má ProductID jeden klíč sloupce, protože je to jediný sloupec, na který Price závisí. Mohli bychom například použít tabulku 3 k uložení Price.
Pokud se cena produktu liší podle barvy, čtvrtá tabulka by byla ve druhé normální podobě, protože cena by závisela na obou částech klíče: a ProductIDColor.
Třetí normální formulář
Třetí normální forma je obvykle cílem většiny databází OLTP. Třetí normální formulář má kromě těch, které vyžadují druhý normální formulář, následující specifikaci:
- Všechny neklíčové sloupce jsou nepřenosně závislé na primárním klíči.
Přechodná relace znamená, že jeden sloupec v tabulce souvisí s jinými sloupci prostřednictvím druhého sloupce. Závislost znamená, že sloupec může v důsledku této relace odvodit jeho hodnotu z jiného. Váš věk můžete například určit od data narození, takže váš věk závisí na vašem datu narození. Vraťte se k třetí tabulce. ProductInfo Tato tabulka je ve druhé normální podobě, ale ne ve třetí. Sloupec ShortLocation závisí na sloupci ProductionCountry , což není klíč. Stejně jako druhá normální forma může porušení třetího normálního formuláře vést k aktualizaci anomálií. Pokud bychom aktualizovali řádek v jednom řádku, ale neaktualizovali ShortLocation bychom je ve všech řádcích, kde došlo k umístění, skončíme nekonzistentními daty. Abychom tomu zabránili, můžeme vytvořit samostatnou tabulku pro ukládání názvů zemí a oblastí a jejich zkrácených formulářů.
Denormalizace
I když je třetí normální forma teoreticky žádoucí, není vždy možné pro všechna data. Normalizovaná databáze navíc ne vždy poskytuje nejlepší výkon. Normalizovaná data často vyžadují více operací spojení, aby se získala všechna potřebná data vrácená v jednom dotazu. Mezi normalizací dat existuje kompromis mezi normalizací dat, když počet spojení potřebných k vrácení výsledků dotazů má vysoké využití procesoru a denormalizovaná data, která mají méně spojení a méně požadovaných procesorů, ale otevírá možnost aktualizovat anomálie.
Denormalizovaná data mohou být efektivnější pro dotazování, zejména pro úlohy náročné na čtení, jako je datový sklad. V takových případech může mít další sloupce lepší vzory dotazů a/nebo více zjednodušených dotazů.
Hvězdicové schéma
Většina normalizace je sice zaměřená na úlohy OLTP, ale datové sklady mají vlastní strukturu modelování, což je obvykle denormalizovaný model. Tento návrh používá tabulky faktů k zaznamenávání měření nebo metrik pro konkrétní události, jako je prodej, a spojuje je s tabulkami dimenzí. Tabulky dimenzí jsou z hlediska počtu řádků menší, ale mohou mít velký počet sloupců, které popisují data faktů. Mezi příklady dimenzí patří inventář, čas a zeměpis. Tento vzor návrhu usnadňuje dotazování databáze a nabízí zvýšení výkonu pro úlohy čtení.
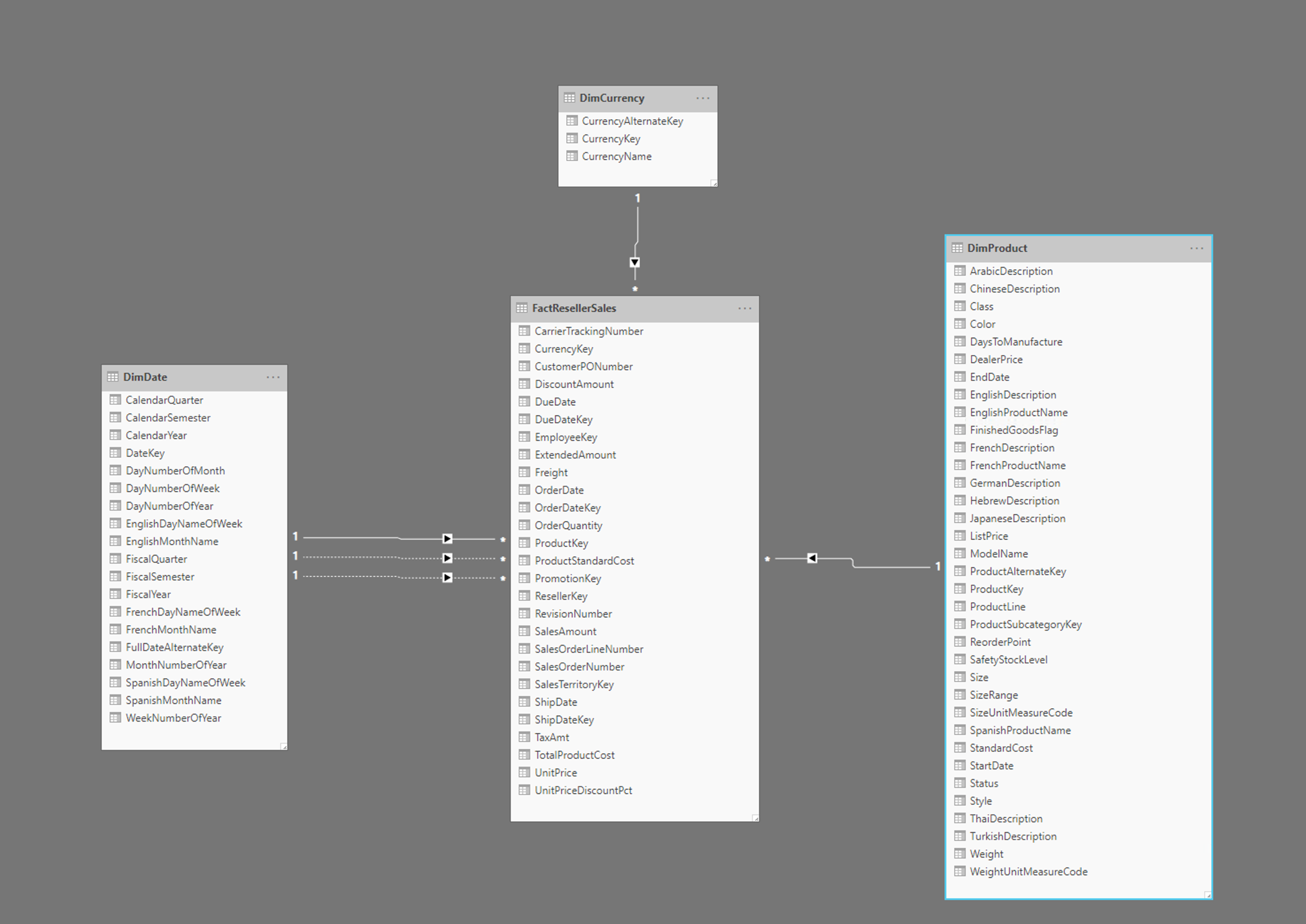
Obrázek znázorňuje příklad hvězdicového schématu s FactResellerSales tabulkou faktů a dimenzemi pro datum, měnu a produkty. Tabulka faktů obsahuje data související s prodejními transakcemi, zatímco dimenze obsahují pouze data související s konkrétními prvky prodejních dat. Tabulka například obsahuje pouze informace FactResellerSales o tom, ProductKey který produkt se prodal. Všechny podrobnosti o jednotlivých produktech jsou uloženy v DimProduct tabulce a souvisejí s tabulkou faktů pomocí ProductKey sloupce.
Souvisí s návrhem hvězdicového schématu je sněhové vločkové schéma, které používá sadu normalizovaných tabulek pro jednu obchodní entitu. Následující obrázek znázorňuje příklad jedné dimenze ve schématu sněhové vločky. Dimenze Products je normalizována a uložena ve třech tabulkách: DimProductCategory, DimProductSubcategorya DimProduct.
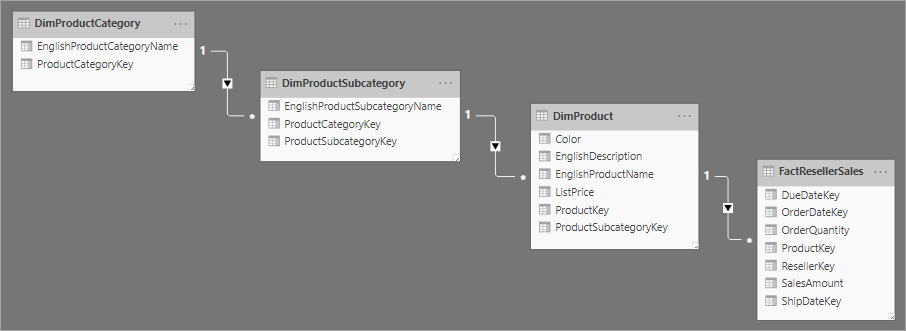
Hlavním rozdílem mezi hvězdicovým a sněhovým vločkovým schématem je, že rozměry ve schématu sněhové vločky jsou normalizovány, aby se snížila redundance, což šetří prostor úložiště. Nevýhodou je, že vaše dotazy vyžadují více spojení, což může zvýšit složitost a snížit výkon.