Modely strojového učení
Poznámka:
Další podrobnosti najdete na kartě Text a obrázky .
Vzhledem k tomu, že strojové učení je založené na matematikách a statistikách, je běžné uvažovat o modelech strojového učení z matematických pojmů. V zásadě je model strojového učení softwarová aplikace, která zapouzdřuje funkci k výpočtu výstupní hodnoty na základě jedné nebo více vstupních hodnot. Proces definování této funkce se označuje jako trénování. Po definování funkce ji můžete použít k predikci nových hodnot v procesu označovaného jako odvozování.
Pojďme se podívat na kroky, které se týkají trénování a odvozování.
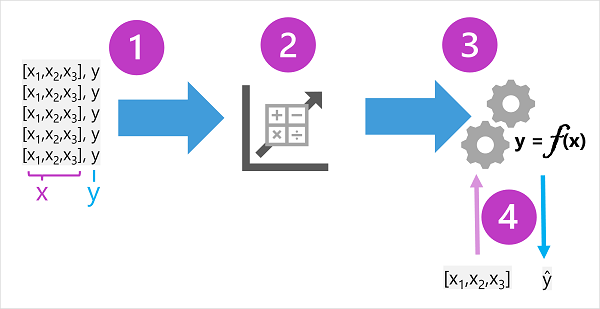
Trénovací data se skládají z minulých pozorování. Ve většině případů pozorování zahrnují pozorované atributy nebo vlastnosti pozorované věci a známou hodnotu věci, kterou chcete vytrénovat, aby předpověděl model (označovaný jako popisek).
V matematických termínech se často zobrazí funkce, na které se odkazuje, pomocí názvu zkratky x a popisku označovaného jako y. Pozorování se obvykle skládá z více hodnot vlastností, takže x je ve skutečnosti vektor (matice s více hodnotami), například: [x1,x2,x3,...].
Abychom to zpřesnily, podívejme se na výše popsané příklady:
- Ve scénáři prodeje zmrzliny je naším cílem vytrénovat model, který dokáže předpovědět počet prodejů zmrzliny na základě počasí. Měření počasí pro den (teplota, srážky, rychlost větru atd.) by byly parametry (x) a počet zmrzlin prodaných každý den by byl označení (y).
- V lékařském scénáři je cílem předpovědět, zda je pacient ohrožen cukrovkou na základě jejich klinických měření. Měření pacienta (hmotnost, hladina glukózy v krvi atd.) jsou vlastnosti (x) a pravděpodobnost cukrovky (například 1 pro rizika, 0 pro neriskovaná) je popisek (y).
- Ve scénáři výzkumu Antarktidy chceme předpovědět druh tučňáka na základě jeho fyzických atributů. Klíčové rozměry tučňáka (délka jeho ploutve, šířka zobáku atd.) jsou vlastnosti (x) a druh (například 0 pro Adelie, 1 pro Gentoo nebo 2 pro Chinstrap) je označení (y).
Na data se použije algoritmus , který se pokusí určit vztah mezi vlastnostmi a popiskem a zobecní tuto relaci jako výpočet, který lze provést s x k výpočtu y. Použitý konkrétní algoritmus závisí na druhu prediktivního problému, který se pokoušíte vyřešit (více o tom později), ale základním principem je pokus o přizpůsobení dat funkci, ve které se hodnoty funkcí dají použít k výpočtu popisku.
Výsledkem algoritmu je model , který zapouzdřuje výpočet odvozený algoritmem jako funkci – pojďme ho volat f. V matematickém zápisu:
y = f(x)
Teď, když je trénovací fáze dokončená, je možné trénovaný model použít k odvozování. Model je v podstatě softwarový program, který zapouzdřuje funkci vytvořenou trénovacím procesem. Můžete zadat sadu hodnot funkcí a přijmout jako výstup predikci odpovídajícího popisku. Vzhledem k tomu, že výstup z modelu je predikce vypočítaná funkcí, a ne pozorovaná hodnota, často se výstup této funkce zobrazuje jako ŷ (které se spíše hezky vyjadřuje jako "y-hat").