Binární klasifikace
Poznámka:
Další podrobnosti najdete na kartě Text a obrázky .
Klasifikace, jako regrese, je technika strojového učení pod dohledem ; a proto se řídí stejným iterativním procesem trénování, ověřování a vyhodnocování modelů. Místo výpočtu číselných hodnot, jako je regresní model, algoritmy používané k trénování klasifikačních modelů vypočítají hodnoty pravděpodobnosti pro přiřazení třídy a metriky vyhodnocení použité k vyhodnocení výkonu modelu porovnávají predikované třídy se skutečnými třídami.
Binární klasifikační algoritmy slouží k trénování modelu, který předpovídá jeden ze dvou možných popisků pro jednu třídu. V podstatě predikce pravda nebo nepravda. Ve většině reálných scénářů se pozorování dat použitá k trénování a ověření modelu skládají z více hodnot funkce (x) a hodnoty y , která je buď 1 , nebo 0.
Příklad – binární klasifikace
Abychom pochopili, jak funguje binární klasifikace, podívejme se na zjednodušený příklad, který pomocí jedné funkce (x) předpovídá, jestli je popisek y 1 nebo 0. V tomto příkladu použijeme hladinu glukózy v krvi pacienta k predikci, jestli má pacient cukrovku nebo ne. Tady jsou data, pomocí kterých model vytrénujeme:

|

|
|---|---|
| Glukóza v krvi (x) | Diabetik? (y) |
| 67 | 0 |
| 103 | 1 |
| 114 | 1 |
| 72 | 0 |
| 116 | 1 |
| 65 | 0 |
Trénování binárního klasifikačního modelu
K trénování modelu použijeme algoritmus pro přizpůsobení trénovacích dat funkci, která vypočítá pravděpodobnost pravdivosti popisku třídy (jinými slovy, že pacient má cukrovku). Pravděpodobnost se měří jako hodnota mezi 0,0 a 1,0, takže celková pravděpodobnost všech možných tříd je 1,0. Pokud je například pravděpodobnost pacienta s cukrovkou 0,7, existuje odpovídající pravděpodobnost 0,3, že pacient není diabetik.
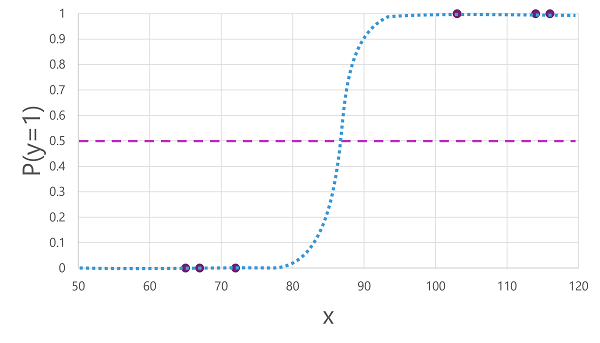
Existuje mnoho algoritmů, které lze použít pro binární klasifikaci, jako je logistická regrese, která odvozuje funkci sigmoid (S-shaped) s hodnotami mezi 0,0 a 1.0, například takto:
Poznámka:
I přes jeho název se v logistické regresi strojového učení používá pro klasifikaci, nikoli regresi. Důležitým bodem je logistická povaha funkce, kterou vytváří, která popisuje křivku tvaru S mezi nižší a horní hodnotou (0,0 a 1,0 při použití pro binární klasifikaci).
Funkce vytvořená algoritmem popisuje pravděpodobnost, že hodnota y je pravdivá (y=1) pro danou hodnotu x. Matematicky můžete funkci vyjádřit takto:
f(x) = P(y=1 | x)
U tří ze šesti pozorování v trénovacích datech víme, že y je rozhodně pravda, takže pravděpodobnost pro ta pozorování, která mají y=1, je 1,0. U dalších tří víme, že y je rozhodně nepravda, takže pravděpodobnost, že y=1, je 0,0. Křivka ve tvaru S popisuje rozdělení pravděpodobnosti tak, aby vykreslení hodnoty x na přímce identifikovalo odpovídající pravděpodobnost, že y je 1.
Diagram obsahuje také vodorovnou čáru označující prahovou hodnotu , při které model založený na této funkci bude predikovat hodnotu true (1) nebo false (0). Prahová hodnota leží uprostřed bodu pro y (P(y) = 0,5). U všech hodnot v tomto okamžiku nebo výše bude model predikovat hodnotu true (1); zatímco u všech hodnot pod tímto bodem bude predikovat hodnotu false (0). Například u pacienta s hladinou glukózy v krvi 90 by výsledkem funkce byla pravděpodobnostní hodnota 0,9. Vzhledem k tomu, že 0,9 je vyšší než prahová hodnota 0,5, model by předpověděl true (1) - jinými slovy, pacient je předpovězen, že má cukrovku.
Vyhodnocení binárního klasifikačního modelu
Stejně jako u regrese platí, že při trénování binárního klasifikačního modelu uchováváte náhodnou podmnožinu dat, pomocí které chcete natrénovaný model ověřit. Předpokládejme, že jsme uchovali následující data, abychom ověřili klasifikátor diabetu.
| Glukóza v krvi (x) | Diabetik? (y) |
|---|---|
| 66 | 0 |
| 107 | 1 |
| 112 | 1 |
| 71 | 0 |
| 87 | 1 |
| 89 | 1 |
Použití logistické funkce, které jsme předtím odvozli na hodnoty x , vede k následujícímu grafu.
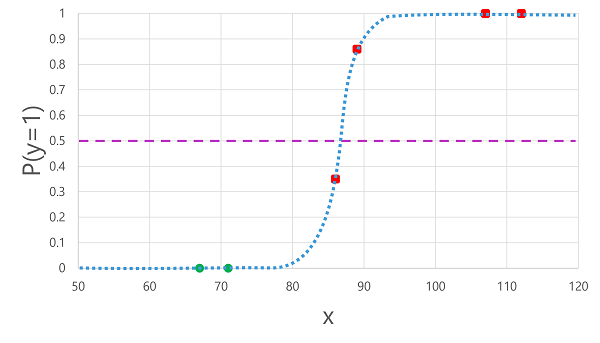
Na základě toho, jestli je pravděpodobnost vypočítaná funkcí nad nebo pod prahovou hodnotou, vygeneruje model pro každé pozorování predikovaný popisek 1 nebo 0. Pak můžeme porovnat předpovězené popisky tříd (ŷ) se skutečnými popisky tříd (y), jak je znázorněno tady:
| Glukóza v krvi (x) | Skutečná diagnóza cukrovky (y) | Předpovězená diagnóza cukrovky (ŷ) |
|---|---|---|
| 66 | 0 | 0 |
| 107 | 1 | 1 |
| 112 | 1 | 1 |
| 71 | 0 | 0 |
| 87 | 1 | 0 |
| 89 | 1 | 1 |
Metriky vyhodnocení binární klasifikace
Prvním krokem při výpočtu metrik vyhodnocení pro binární klasifikační model je obvykle vytvoření matice počtu správných a nesprávných předpovědí pro každý možný popisek třídy:
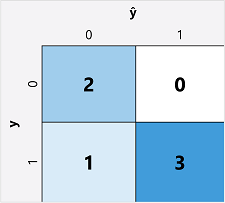
Tato vizualizace se nazývá konfuzní matice a zobrazuje součty předpovědí, kde:
- ŷ=0 a y=0: Pravé zápory (TN)
- ŷ=1 a y=0: Falešně pozitivní (FP)
- ŷ=0 a y=1: Falešně negativní hodnoty (FN)
- ŷ=1 a y=1: Pravdivě pozitivní ( TP)
Uspořádání konfuzní matice je takové, že správné (pravdivé) předpovědi jsou zobrazeny diagonálně od levého horního do dolního rohu. Intenzita barev se často používá k označení počtu předpovědí v každé buňce, takže rychlý přehled modelu, který dobře předpovídá, by měl odhalit hluboce stínovaný diagonální trend.
Přesnost
Nejjednodušší metrika, kterou můžete vypočítat z konfuzní matice, je přesnost – poměr předpovědí, které model získal správně. Přesnost se vypočítá takto:
(TN+TP) ÷ (TN+FN+FP+TP)
V případě našeho příkladu cukrovky je výpočet:
(2+3) ÷ (2+1+0+3)
= 5 ÷ 6
= 0.83
Takže pro naše ověřovací údaje, model klasifikace cukrovky vytvořil správné předpovědi 83% času.
Přesnost může zpočátku vypadat jako dobrá metrika pro vyhodnocení modelu, ale zvažte to. Předpokládejme, že 11% populace má cukrovku. Mohli byste vytvořit model, který vždy predikuje 0, a dosáhl by přesnosti 89%, i když se nepokouší rozlišovat mezi pacienty vyhodnocením jejich vlastností. To, co skutečně potřebujeme, je hlubší pochopení toho, jak model funguje při predikci 1 pro pozitivní případy a 0 pro záporné případy.
Odvolat
Citlivost je metrika, která měří podíl pozitivních případů, které model správně identifikoval. Jinými slovy, ve srovnání s počtem pacientů s cukrovkou, kolik model predikoval , že má cukrovku?
Vzorec pro odvolání je:
÷ TP (TP+FN)
Pro náš příklad cukrovky:
3 ÷ (3+1)
= 3 ÷ 4
= 0.75
Náš model tedy správně identifikoval 75% pacientů s cukrovkou, kteří mají cukrovku.
Přesnost
Přesnost je metrika podobná odvolání, ale měří podíl predikovaných kladných případů, ve kterých je skutečné označení skutečně pozitivní. Jinými slovy, jaký podíl pacientů předpovězených modelem má skutečně cukrovku?
Vzorec pro přesnost je:
÷ TP (TP+FP)
Pro náš příklad cukrovky:
3 ÷ (3+0)
= 3 ÷ 3
= 1.0
Takže 100% pacientů predikovaných naším modelem, že cukrovka má ve skutečnosti cukrovku.
F1 skóre
F1-score je celková metrika, která kombinuje senzitivitu a přesnost. Vzorec pro skóre F1 je následující:
(2 x přesnost x úplnost) ÷ (přesnost + úplnost)
Pro náš příklad cukrovky:
(2 x 1,0 x 0,75) ÷ (1,0 + 0,75)
= 1,5 ÷ 1,75
= 0,86
Oblast pod křivkou (AUC)
Dalším názvem pro recall je pozitivní prediktivní hodnota (TPR) a existuje ekvivalentní metrika označovaná jako míra falešně pozitivních (FPR), která se vypočítá jako FP÷(FP+TN). Už víme, že TPR pro náš model při použití prahové hodnoty 0,5 je 0,75 a můžeme použít vzorec pro FPR k výpočtu hodnoty 0÷2 = 0.
Samozřejmě, pokud bychom chtěli změnit prahovou hodnotu, nad kterou model predikuje true (1), ovlivnilo by to počet kladných a záporných předpovědí, a tím pádem by se změnily metriky TPR a FPR. Tyto metriky se často používají k vyhodnocení modelu vykreslením křivky ROC (charakteristiky přijímaného operátora), která porovnává TPR a FPR pro každý možný práh mezi 0,0 a 1,0.
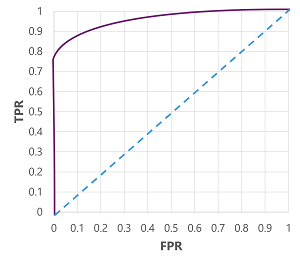
Křivka ROC pro dokonalý model by šla rovnou osu TPR vlevo a pak přes osu FPR v horní části. Vzhledem k tomu, že plocha grafu křivky měří 1x1, bude oblast pod touto dokonalou křivkou 1,0 (což znamená, že model je správný 100% času). Naproti tomu diagonální čára z levého dolního rohu do pravého horního rohu představuje výsledky, které by bylo dosaženo náhodným odhadem binárního popisku; vytváří plochu pod křivkou 0,5. Jinými slovy, vzhledem k dvěma možným popiskům tříd byste mohli přiměřeně očekávat, že se správně odhadne 50% času.
V případě našeho modelu diabetu se vytvoří výše uvedená křivka, a oblast pod křivkou (AUC) je 0,875. Vzhledem k tomu, že AUC je vyšší než 0,5, můžeme model lépe předpovědět, zda pacient má cukrovku, než náhodně odhadne.