Zkoumání a zpracování dat pomocí Microsoft Fabric
Data jsou základním kamenem datových věd, zejména při trénování modelu strojového učení pro dosažení umělé inteligence. Modely obvykle vykazují vyšší výkon při nárůstu velikosti trénovací datové sady. Kromě množství dat je kvalita dat stejně důležitá.
Pokud chcete zaručit kvalitu i množství vašich dat, je vhodné používat robustní moduly pro příjem a zpracování dat od Microsoft Fabric. Při vytváření základních kanálů pro příjem, zkoumání a transformaci dat máte flexibilitu zvolit buď nízký kód, nebo přístup založený na kódu.
Ingestování dat do Microsoft Fabric
Abyste mohli pracovat s daty v Microsoft Fabric, musíte nejprve ingestovat data. Můžete ingestovat data z více zdrojů, a to jak z místních, tak cloudových zdrojů dat. Můžete například ingestovat data ze souboru CSV uloženého na místním počítači nebo ve službě Azure Data Lake Storage (Gen2).
Tip
Přečtěte si další informace o tom, jak ingestovat a orchestrovat data z různých zdrojů pomocí Microsoft Fabric.
Po připojení ke zdroji dat můžete data uložit do Microsoft Fabric Lakehouse. Jezero můžete použít jako centrální umístění k ukládání jakýchkoli strukturovaných, částečně strukturovaných a nestrukturovaných souborů. Kdykoli budete chtít získat přístup k datům pro průzkum nebo transformaci, můžete se snadno připojit k jezeru.
Prozkoumání a transformace dat
Jako datový vědec možná znáte psaní a spouštění kódu v poznámkových blocích. Microsoft Fabric nabízí známé prostředí poznámkového bloku, které využívá výpočetní prostředí Sparku.
Apache Spark je opensourcová architektura paralelního zpracování pro rozsáhlé zpracování a analýzu dat.
Poznámkové bloky se automaticky připojí k výpočetním prostředkům Sparku. Při prvním spuštění buňky v poznámkovém bloku se spustí nová relace Sparku. Relace se zachová, když spustíte další buňky. Relace Sparku se po určité době nečinnosti automaticky zastaví, aby se ušetřily náklady. Relaci můžete také zastavit ručně.
Při práci v poznámkovém bloku můžete zvolit jazyk, který chcete použít. U úloh datových věd pravděpodobně budete pracovat s PySpark (Python) nebo SparkR (R).
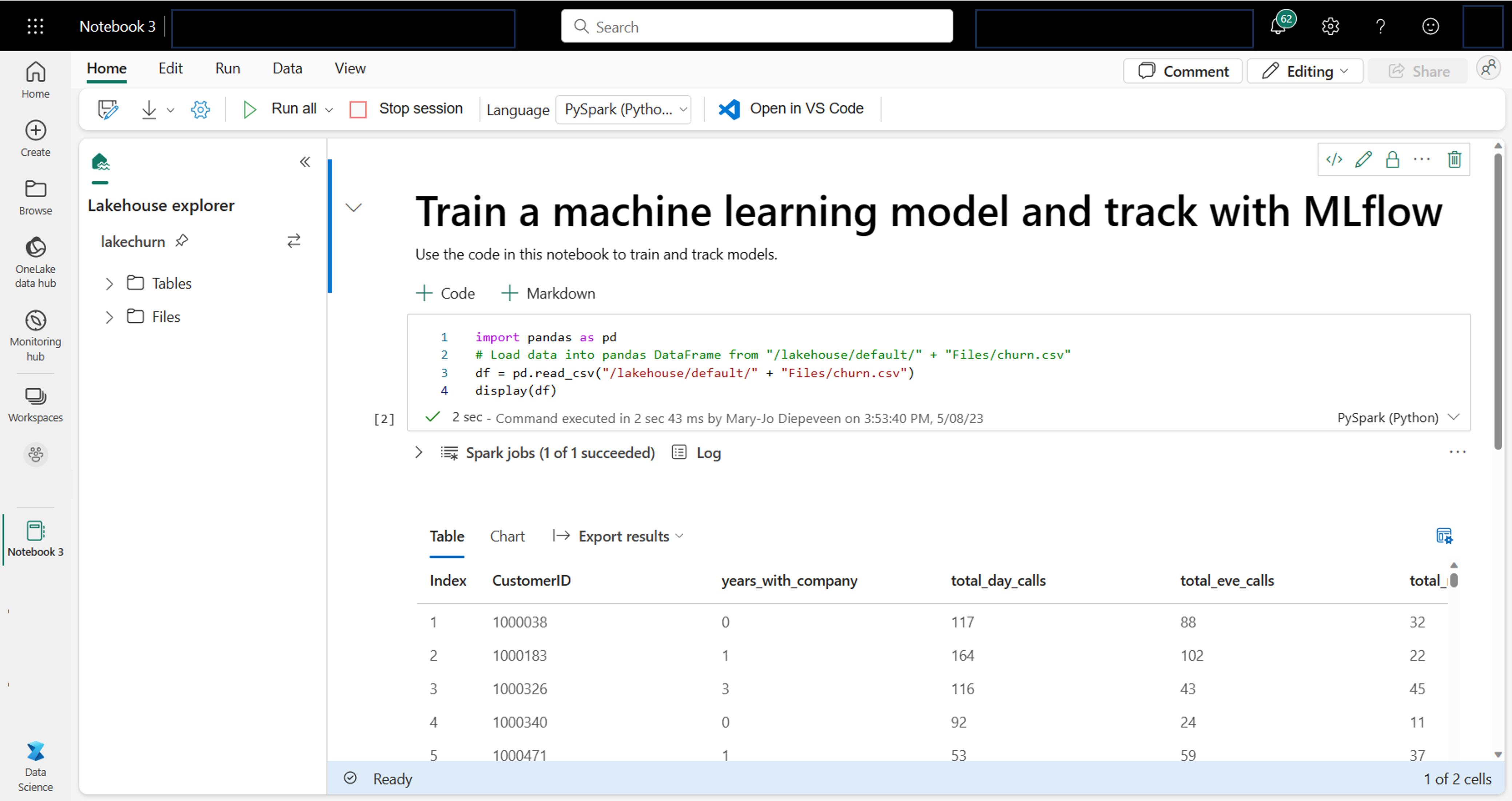
V poznámkovém bloku můžete zkoumat data pomocí preferované knihovny nebo s některou z předdefinovaných možností vizualizace. V případě potřeby můžete transformovat data a uložit zpracovaná data tak, že je zapíšete zpět do jezera.
Příprava dat pomocí služby Data Wrangler
Microsoft Fabric nabízí snadno použitelnou službu Data Wrangler, která vám pomůže rychleji zkoumat a transformovat data.
Po spuštění služby Data Wrangler získáte popisný přehled dat, se kterými pracujete. Můžete si prohlédnout souhrnnou statistiku dat a najít případné problémy, jako jsou chybějící hodnoty.
Pokud chcete data vyčistit, můžete zvolit některou z předdefinovaných operací čištění dat. Když vyberete operaci, vygeneruje se automaticky náhled výsledku a přidružený kód se automaticky vygeneruje. Když vyberete všechny potřebné operace, můžete transformace exportovat do kódu a spouštět je na vašich datech.