Možnosti konfigurace HDInsightu
HDInsight má celou řadu integrovaných technologií operačního systému, které je možné použít k řešení scénářů streamování i dávkových dat, což jsou termíny definované v architektuře Lambda. V tomto modelu architektury existuje horká cesta dat a studená cesta dat. Horká cesta dat se generuje v reálném čase zařízeními, senzory nebo aplikacemi a analýza dat téměř v reálném čase, což se často označuje jako streamovaná data. Studená cesta dat je, když se data přesunou v dávkách, obvykle z jiných úložišť dat a často se označují jako dávková data.
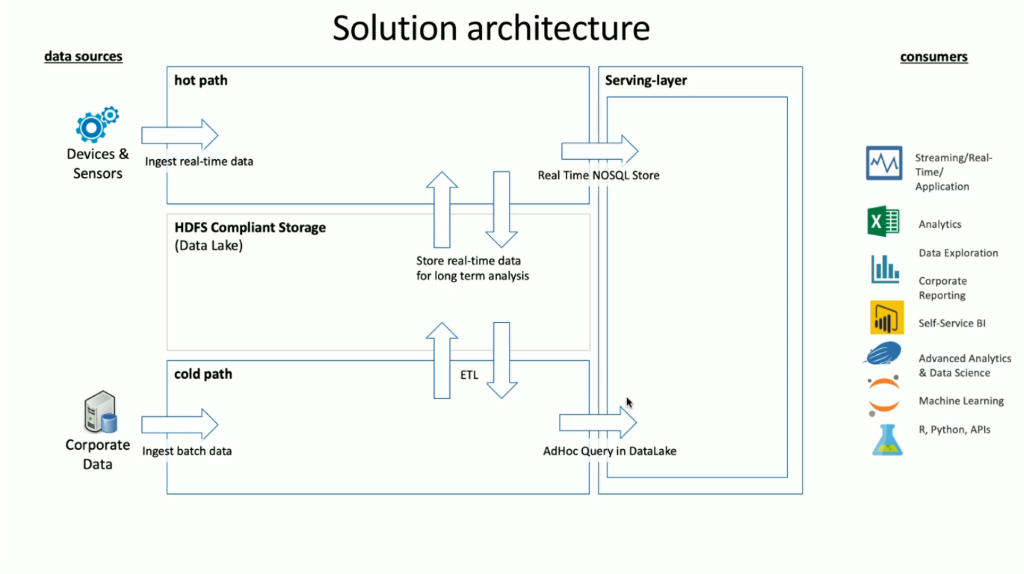
Při implementaci SLUŽBY HDInsight se úložiště dat uchovává v kompatibilním systému souborů HDFS (Hadoop Distributed File System). V Azure se Data Lake Gen2 obvykle používá jako úložiště dat, protože je kompatibilní s HDFS. Data z horké cesty a studené cesty po zpracování se ukládají do centralizovaného úložiště dat s názvem Data Lake. Samotné datové jezero může být rozdělené na ukládání dat v různých oddílech, které mohou být definovány stavem dat (cílová zóna, zóna transformace atd.), požadavky na přístup (horké, teplé a studené) a obchodní skupiny. Obslužná vrstva je posledním oddílem v datovém jezeře, která obsahuje data ve formátu, který je připravený ke spotřebě různými typy příjemců.
Důležitým aspektem výpočetních prostředků služby HDInsight je zpracování streamovaných nebo dávkových dat a může se lišit v závislosti na typu clusteru, který vyberete při zřizování clusteru HDInsight. HDInsight nabízí služby v jednotlivých možnostech clusteru, jak je znázorněno v následující tabulce.
| Typ clusteru | Popis |
|---|---|
| Apache Hadoop | Architektura, která používá HDFS, a jednoduchý programovací model MapReduce ke zpracování a analýze dávkových dat. |
| Apache Spark | Opensourcová architektura paralelního zpracování, která podporuje zpracování v paměti za účelem zvýšení výkonu aplikací pro analýzu velkých objemů dat. |
| HBase | Databáze NoSQL založená na Hadoopu, která poskytuje náhodný přístup a silnou konzistenci pro velké objemy nestrukturovaných a částečně strukturovaných dat – potenciálně miliardy řádků krát miliony sloupců. |
| Apache Interactive Query | Ukládání do mezipaměti v paměti pro interaktivní a rychlejší dotazy Hive |
| Apache Kafka | Open source platforma, která se používá k vytváření streamovaných datových kanálů a aplikací. Kafka také poskytuje funkce propojující fronty zpráv, pomocí kterých můžete publikovat datové streamy a přihlašovat se k jejich odběru. |
Proto je důležité vybrat správný typ clusteru pro splnění obchodního případu, který se pokoušíte vyřešit. Bez ohledu na vybraný typ clusteru se do clusteru přidají také další opensourcové komponenty, které poskytují další možnosti, mezi které patří:
Správa Hadoopu
HCatalog – Vrstva správy tabulek a úložiště pro Hadoop
Apache Ambari – Usnadňuje správu a monitorování clusteru Apache Hadoop
Apache Oozie – Systém plánovače pracovních postupů pro správu úloh Apache Hadoop
Apache Hadoop YARN – spravuje správu prostředků a plánování úloh/ monitorování
Apache ZooKeeper – centralizovaná služba pro správu informací o konfiguraci, pojmenování, poskytování distribuované synchronizace a poskytování skupinových služeb.
Zpracování dat
Apache Hadoop MapReduce – architektura pro snadné psaní aplikací, které zpracovávají obrovské objemy dat
Apache Tez – aplikační architektura pro zpracování dat
Apache Hive – Usnadňuje správu velkých datových sad umístěných v distribuovaném úložišti pomocí SQL.
Analýza dat
Apache Pig – poskytuje abstrakci vrstvy nad MapReduce pro analýzu velkých datových sad.
Apache Phoenix – Umožňuje OLTP a provozní analýzy v Hadoopu.
Apache Mahout – architektura Algebra pro vytvoření vlastních algoritmů
Poznámka:
V době psaní jsou vrstvy úložiště dat pro HDInsight podporované vrstvy úložiště dat Azure Data Lake Gen1 a Azure Blob Storage. Měli byste tato data migrovat do Azure Data Lake Gen2, protože se jedná o doporučenou platformu úložiště pro Spark a Hadoop a jako výchozí volbu pro HBase.