Charakteristiky a životní cyklus incidentu
Jak jste se dozvěděli v poslední lekci, incident je přerušení služeb, které ovlivňuje vaše zákazníky a koncové uživatele. Incidenty přicházejí v mnoha formách, od zpomalení výkonu, které frustrují uživatele ("pomalé je nové je nové") až po chybové ukončení systému, které po určitou dobu vykreslují službu nebo web zcela nedostupné.
Charakteristiky incidentu
Incidenty jsou obvykle neočekávané a zdá se, že se vyskytují v nejhorší možné době (například 2:00 nebo když jste hluboce ponořili do důležitého projektu). To je důvod, proč se incidenty často bojí a vyhýbají se tomu, a to i v okamžiku, kdy lidé někdy přehrávají význam incidentu. Tlak uvnitř organizací je někdy tak velký, že ze strachu z pokárání vzniká pokušení přerušení chybně pojmenovat nebo vůbec nenahlásit.
Minimálně incidenty vytvářejí neplánovanou práci, a protože trávíte většinu času prací na plánované práci s dobrou myšlenkou, co byste měli dělat, pravděpodobně si incidenty myslíte jako špatné věci. Existuje ale další způsob, jak se na to podívat: incidenty jsou skutečně investice* do poskytování hodnoty, kterou se snažíte koncovým uživatelům doručit. Bez ohledu na příčinu incidentu nebo rozsah dopadu mají všechny incidenty jedno společné: můžou poskytovat cenné studijní zkušenosti.
Incidenty byste měli vidět jako impuls vašich systémů. Říkají vám o systému mnohem víc informací, než jste předtím věděli. A tyto znalosti jsou užitečné. Pokud máte silný základ monitorování a získáte další informace o tom, co se děje ve vašem systému, bude to nutně generovat další výstrahy a incidenty a příležitosti k reakci. Alespoň incidenty vám říkají, co se děje, a tím zvyšují informovanost o provozu. V předchozím modulu týkajícím se monitorování jsme navrhli, že toto je důležitý prekurzor spolehlivosti práce.
Životní cyklus incidentu
Pokud chcete zvýšit stav týmu reakce na incidenty na "elitní/vysoce výkonné", musíte se podívat nad myšlenku přerušení služby nebo incidentu jako na jednoduchou lineární časovou osu a přistupovat k ní z cyklické perspektivy.
Životní cyklus incidentu můžete oddělit do různých fází, které logicky následují po druhém v cyklu, který se vrátí zpět na začátek. Pokaždé, když tento cyklus obcházíte (a budete to dělat mnohokrát), pokud to zvládnete správně, je možné se vrátit na začátek s lepším přehledem o vašich systémech. Pokud se budete této problematice záměrně věnovat, můžete být lépe připraveni a když dojde k incidentu příště, zareagujete rychle a efektivně.
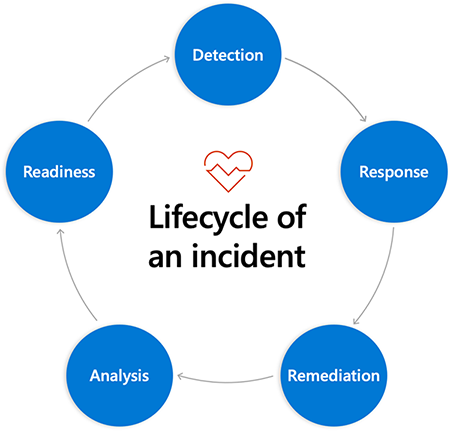
Fáze incidentu
Jednotlivé fáze procesu reakce na incidenty vypadají v závislosti na vámi používaném modelu trochu jinak. Pro účely tohoto modulu projdete v reakci na incident pěti fázemi:
- Detekce: Tato fáze spočívá v tom, jak přichází do hry znalosti monitorování z předchozího modulu tohoto studijního programu. Nástroje pro monitorování shromažďují informace z protokolů, analyzují tyto informace podle nakonfigurovaných cílů orientovaných na zákazníky a odesílají vám výstrahy s možností použití, abyste věděli, že je potřeba zásah člověka.
- Odpověď: Tato fáze se stane poté, co vy a váš tým obdržíte toto upozornění. Tuto fázi si podrobně probereme v tomto modulu, takže o této myšlence budeme za chvíli mít spoustu dalších informací.
- Náprava: V této fázi obnovíte systémy do normální funkčnosti. Způsob, jak to provedete, závisí na příčině přerušení služby. Zprovoznění a spuštění služby a její zpřístupnění zákazníkům je vaší nejvyšší prioritou. Jakmile se to ale dokončí, vaše úloha se nezastaví.
- Analýza: Pokud chcete získat trvalou hodnotu z incidentů, musíte se z nich poučit. Tato fáze je proces shromažďování informací o tom, co se stalo, a kdy během incidentu a zjištění toho, co se z něj můžete naučit, tím, že položíte správné otázky. K dispozici je celý modul Učení z selhání, který tuto fázi řeší.
- Připravenost: Měli byste začlenit lekce získané ve fázi analýzy do provozní praxe. Pokud existují položky akce, které by v budoucnosti pomohly zabránit podobnému výpadku, budou také součástí této fáze.
Než budete moct vytvořit plán reakcí na incidenty, musíte pochopit charakteristiky a hodnotu incidentů a seznámit se s fázemi životního cyklu incidentů. Dalším krokem je zajistit, aby byla strategie reakcí založená na pevných základech.