Nákladové funkce versus metriky vyhodnocení
V posledních několika lekcích jsme začali vidět rozdělení nákladových funkcí, které model učí, a vyhodnocovací metriky, což je způsob, jakým model vyhodnocujeme sami.
Všechny nákladové funkce můžou být vyhodnocované metriky.
Všechny nákladové funkce můžou být vyhodnocované metriky, i když ne nutně intuitivní. Ztráta protokolu, například: hodnoty nejsou intuitivní.
Některé metriky vyhodnocení nemůžou být nákladové funkce.
- U některých metrik vyhodnocení je obtížné stát se nákladovým funkcím.
- Důvodem jsou praktická a matematická omezení.
- Někdy se věci nesnadně vypočítají (například "jak se něco dělá)
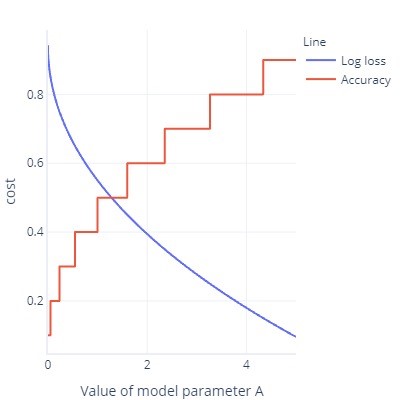
- Nákladové funkce jsou ideálně hladké. Přesnost je například užitečná, ale pokud model změníme mírně, nevšimneme si ho. Vzhledem k tomu, že přizpůsobení je postup s velkým množstvím malých změn, to dává dojem, že změny nebudou vést ke zlepšení.
- Graf nákladových funkcí s velkým množstvím plochých bitů
- Aktualizujte křivky ROC z dřívějších verzí. To vyžaduje změnu prahové hodnoty na nejrůznější hodnoty, ale na konci dne bude mít náš model jenom jednu hodnotu (0,5).
Není to všechno špatné!
Může to být frustrující, když zjistíme, že jako nákladovou funkci nemůžeme použít oblíbené metriky. Existuje však nevýhoda, která souvisí se skutečností, že všechny metriky jsou zjednodušením toho, čeho chceme dosáhnout; žádná není dokonalá. To znamená, že složité modely často "podvádějí": najdou způsob, jak získat nízké náklady, aniž by skutečně našli obecné pravidlo, které řeší náš problém. Metrika, která nefunguje jako nákladová funkce, nám poskytuje "kontrolu sanity", že model nenalezl způsob, jak podvést. Pokud víme, že model používá klávesové zkratky, můžeme znovu promyslit naši strategii trénování.
Viděli jsme tento "podvádění" několikrát. Například když modely silně převládnou trénovací data, v podstatě si "zapamatují" správné odpovědi místo nalezení obecného pravidla, které můžeme úspěšně použít na jiná data. Testovací datové sady používáme jako naši "kontrolu sanity" k vyhodnocení, abychom ověřili, že model to právě neudělal. Viděli jsme také, že s nevyrovnanými daty se modely někdy můžou jen naučit, aby vždy poskytovaly stejnou odpověď (například "false"), aniž by se podívaly na funkce, protože je to v průměru správné a poskytuje malou chybu.
Složité modely také hledají klávesové zkratky jinými způsoby. Složité modely můžou někdy přetěžovat samotnou nákladovou funkci. Představte si například, že se snažíme vytvořit model, který může kreslit psy. Máme nákladovou funkci, která kontroluje, jestli je obrázek hnědý, zobrazuje texturu furry a obsahuje objekt o správné velikosti. Díky této nákladové funkci se složitý model může naučit vytvořit hnědou furovou kuličku, ne proto, že vypadá jako pes, ale protože dává nízké náklady a je snadné generovat. Pokud máme externí metriku, která počítá počet nohou a hlav (což se nedá snadno použít jako nákladová funkce, protože tyto metriky nejsou hladké), rychle si všimneme, jestli náš model podvádí, a znovu se podíváme, jak ho trénujeme. Pokud je naše alternativní skóre metrik dobře, můžeme mít jistotu, že model pochopil představu o tom, jak by měl pes vypadat, a ne jen oklamat nákladovou funkci, aby získal nízkou hodnotu.