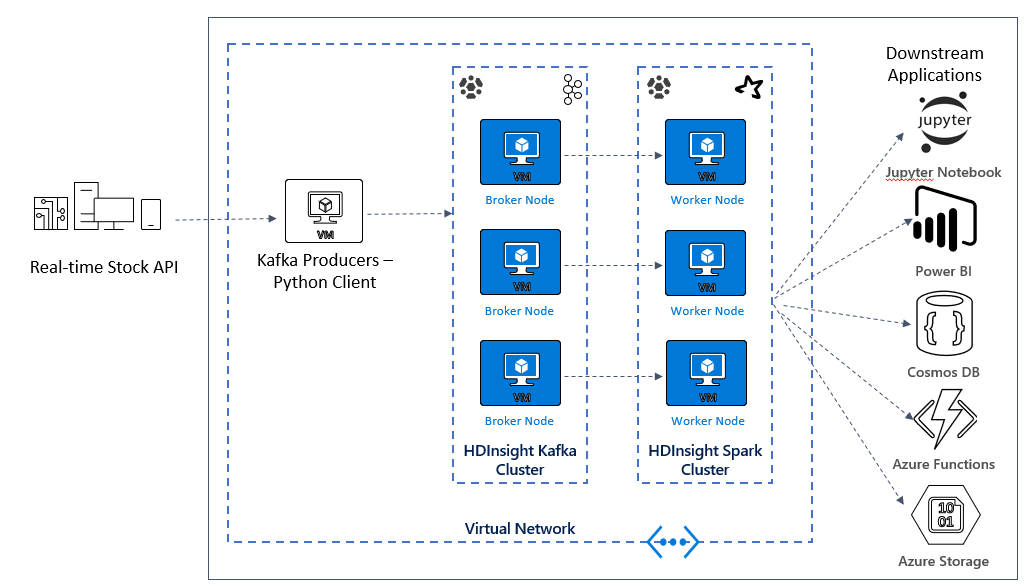
Vytvoření architektury Kafka a Sparku
Pokud chcete používat Kafka a Spark společně ve službě Azure HDInsight, musíte je umístit do stejné virtuální sítě nebo vytvořit partnerský vztah virtuálních sítí, aby clustery fungovaly s překladem názvů DNS.
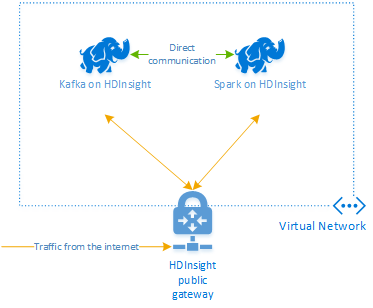
Postup vytvoření clusterů ve stejné virtuální síti:
- Vytvoření skupiny zdrojů
- Přidání virtuální sítě do skupiny prostředků
- Přidejte cluster Kafka a cluster Sparku do stejné virtuální sítě nebo případně vytvořte partnerský vztah mezi virtuálními sítěmi, ve kterých tyto služby pracují s překladem názvů DNS.
Doporučený způsob, jak připojit cluster HDInsight Kafka a Spark, je nativní konektor Spark-Kafka, který umožňuje clusteru Spark přistupovat k jednotlivým oddílům dat v clusteru Kafka, což zvyšuje paralelismus, který máte ve své úloze zpracování v reálném čase a poskytuje velmi vysokou propustnost.
Pokud jsou oba clustery ve stejné virtuální síti, můžete v kódu streamování Sparku také použít plně kvalifikované názvy domén služby Kafka Broker a v podnikové síti můžete vytvořit pravidla NSG.
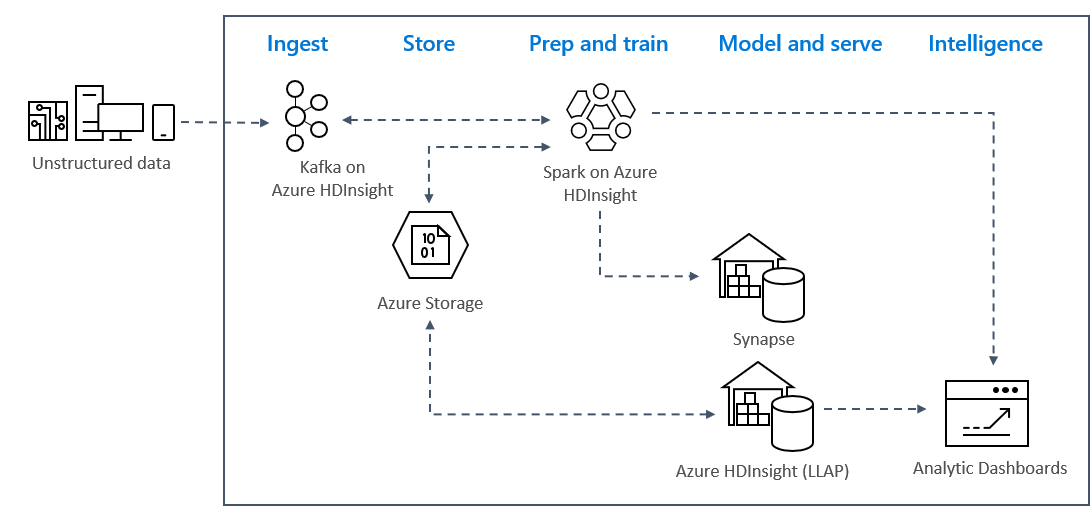
Architektura řešení
Vzory analýzy streamování v reálném čase v Azure obvykle používají následující architekturu řešení.
- Ingestace: Nestrukturovaná nebo strukturovaná data se ingestují do clusteru Kafka ve službě Azure HDInsight.
- Příprava a trénování: Data se předem natrénují a natrénují pomocí Sparku ve službě HDInsight.
- Model a obsluha: Data se přeloží do datového skladu, jako je Azure Synapse nebo HDInsight Interactive Query.
- Inteligentní funkce: Data se obsluhuje na analytickém řídicím panelu, jako je Power BI nebo Tableau.
- Úložiště: Data se zakládají do řešení studeného úložiště, jako je Azure Storage, a obsluhuje se později.
Architektura ukázkového scénáře
V další lekci začnete sestavovat architekturu řešení pro ukázkovou aplikaci. Tato ukázka používá soubor šablony Azure Resource Manageru k vytvoření skupiny prostředků, virtuální sítě, clusteru Spark a clusteru Kafka.
Po nasazení clusterů přejdete přes ssh do jednoho zprostředkovatele Kafka a zkopírujete soubor producenta Pythonu do hlavního uzlu. Tento soubor producenta poskytuje umělé ceny akcií každých 10 sekund, zapíše také číslo oddílu a posun zprávy do konzoly.
Po spuštění producenta můžete nahrát poznámkový blok Jupyter do clusteru Spark. V poznámkovém bloku připojíte clustery Spark a Kafka a spustíte na datech několik ukázkových dotazů, včetně vyhledání vysokých a nízkých hodnot akcií v okně události.