Příjem dat pomocí Azure Databricks
Než budete moct pracovat s daty v Azure Databricks, musíte ingestovat data do platformy. Jakmile je cloudová výpočetní služba na platformě, umožňuje efektivně zpracovávat velké objemy dat.
Data v Azure Databricks se ukládají pomocí Apache Delta Lake, opensourcového systému pro správu datových souborů, na kterých je možné definovat a dotazovat relační tabulky. Skutečné umístění úložiště pro soubory delta lake se může lišit. Azure Databricks podporuje připojení ke cloudovým službám úložiště dat, jako je Azure Storage a Azure Data Lake. Azure Databricks také poskytuje Katalog Unity jako řešení zásad správného řízení pro správu a sledování přístupu k datům a rodokmenu napříč několika připojenými úložišti dat.
Existuje několik způsobů, jak ingestovat data do Azure Databricks, což z něj dělá všestranný a výkonný nástroj pro analýzu dat, mezi které patří:
Použití spravovaného konektoru Databricks v Lakeflow Connect
Azure Databricks Lakeflow Connect poskytuje architekturu pro příjem dat z aplikací SaaS, databází a dalších zdrojů do jezera pomocí spravovaných konektorů. Tyto konektory definují způsob nastavení a údržby ověřovacích, kanálů a cílových tabulek. U zdrojů SaaS jsou hlavními částmi připojení (pro ověřování), bezserverový kanál příjmu dat a tabulky Delta , které ukládají ingestované data. Databázové konektory zahrnují stejné prvky, ale také spoléhají na bránu příjmu, která běží na klasických výpočetních prostředcích, a přechodnou úložnou oblast v katalogu Unity pro dočasné uchovávání extrahovaných dat. Orchestrace se zpracovává prostřednictvím úloh Databricks a řízení přístupu a auditování se spravují prostřednictvím katalogu Unity.
Použití spravovaných konektorů umožňuje naplánování, opakování a škálování datových kanálů bez nutnosti psát vlastní kód pro příjem dat. Přírůstkové načítání dat je podporováno, což pomáhá snížit zatížení zdrojových systémů a zároveň udržovat tabulky aktuální. Přístup zdůrazňuje konzistentní zásady správného řízení, zpracování schémat a monitorování napříč různými zdroji dat.
K dispozici jsou následující spravované konektory:
- Google Analytics
- Salesforce
- Zprávy Workday
- SQL Server
- ServiceNow
- Služba SharePoint
Nahrání souborů do Azure Databricks
Pokud chcete vygenerovat tabulku Delta, můžete do Databricks importovat místní soubory CSV, TSV, JSON, XML, Avro, Parquet nebo prostého textu. Tento přístup je určený pro menší soubory (do 2 GB) přenášené přímo z počítače. Komprimované archivy, jako je ZIP nebo TAR, se nepodporují. Během procesu nahrávání poskytuje Databricks náhled až 50 řádků a můžete upravit nastavení formátování, aby se zajistilo správné rozpoznání sloupců a datových typů v souborech CSV nebo JSON.
Soubory libovolného formátu ( strukturované, částečně strukturované nebo nestrukturované) můžete také nahrát do svazku. Svazek je objekt katalogu Unity, který poskytuje zásady správného řízení pro netabularní datové sady a představuje logický prostor úložiště v cloudovém úložišti objektů. Svazky umožňují přístup k souborům, ukládání, uspořádání a používání zásad správného řízení. Existují dva typy svazků:
- Spravované svazky: Úložiště spravované Databricksem pro jednoduché případy použití
- Externí svazky: Zásady správného řízení použité pro existující umístění cloudového úložiště objektů
Poznámka:
Možnost DBFS umožňuje použít starší systém nahrávání souborů systému Databricks File System. Tato funkce se už nepodporuje.
Ingestování souborů pomocí rozhraní Apache Spark API
Apache Spark je nativní výpočetní platforma pro Azure Databricks a podporuje rozhraní API pro více programovacích jazyků, jako jsou Scala, Java, PySpark (varianta optimalizovaná pro Spark) a SQL. Pro jednoduchý příjem dat ve vzdáleném úložišti můžete napsat kód, který se připojuje k požadovaným datům a importuje je.
Tady je příklad, který pomocí příkazu wget načte vzdálený soubor do /tmp/ na uzlu ovladače, pomocí Sparku ho načte z místní cesty a pak ho uložte jako tabulku Delta v Databricks:
# Step 1: Use wget to download the file (e.g., a CSV from a public URL)
# In Databricks, prefix shell commands with "!"
!wget https://<location>/airtravel.csv -O /tmp/airtravel.csv
# Step 2: Load the downloaded file into a Spark DataFrame
df = spark.read.format("csv") \
.option("header", "true") \
.option("inferSchema", "true") \
.load("file:/tmp/airtravel.csv")
# Step 3: Preview the data
df.show(5)
# Step 4: Save as a Delta table
df.write.format("delta").mode("overwrite").saveAsTable("default.airtravel")
Načtení dat pomocí funkce COPY INTO s principálem služby
Pomocí COPY INTO příkazu můžete načíst data z kontejneru Azure Data Lake Storage (ADLS) ve vašem účtu Azure do tabulky v Databricks SQL.
COPY INTO my_json_data
FROM 'abfss://container@storageAccount.dfs.core.windows.net/jsonData'
FILEFORMAT = JSON;
Deklarativní kanály Lakeflow
Lakeflow Declarative Pipelines je deklarativní rámec pro vývoj a spouštění dávkových a streamovaných datových potrubí v SQL a Pythonu. Podporuje automatizovanou orchestraci, izolaci chyb, opakované pokusy, vývoj schématu, přírůstkové zpracování a CDC - zachycení změn dat typu 1 a typu 2.
Tok je základním konceptem zpracování dat v Lakeflow deklarativních pipeline a podporuje jak sémantiku streamování, tak i batch. Tok čte data ze zdroje, použije uživatelsky definovanou logiku zpracování a zapíše výsledek do cíle.
Kvalitu dat můžete také spravovat podle očekávání kanálu, která umožňují definovat ověřovací pravidla, která zajišťují, aby data splňovala požadované standardy před zápisem do cíle.
Tady je příklad deklarativního kanálu:
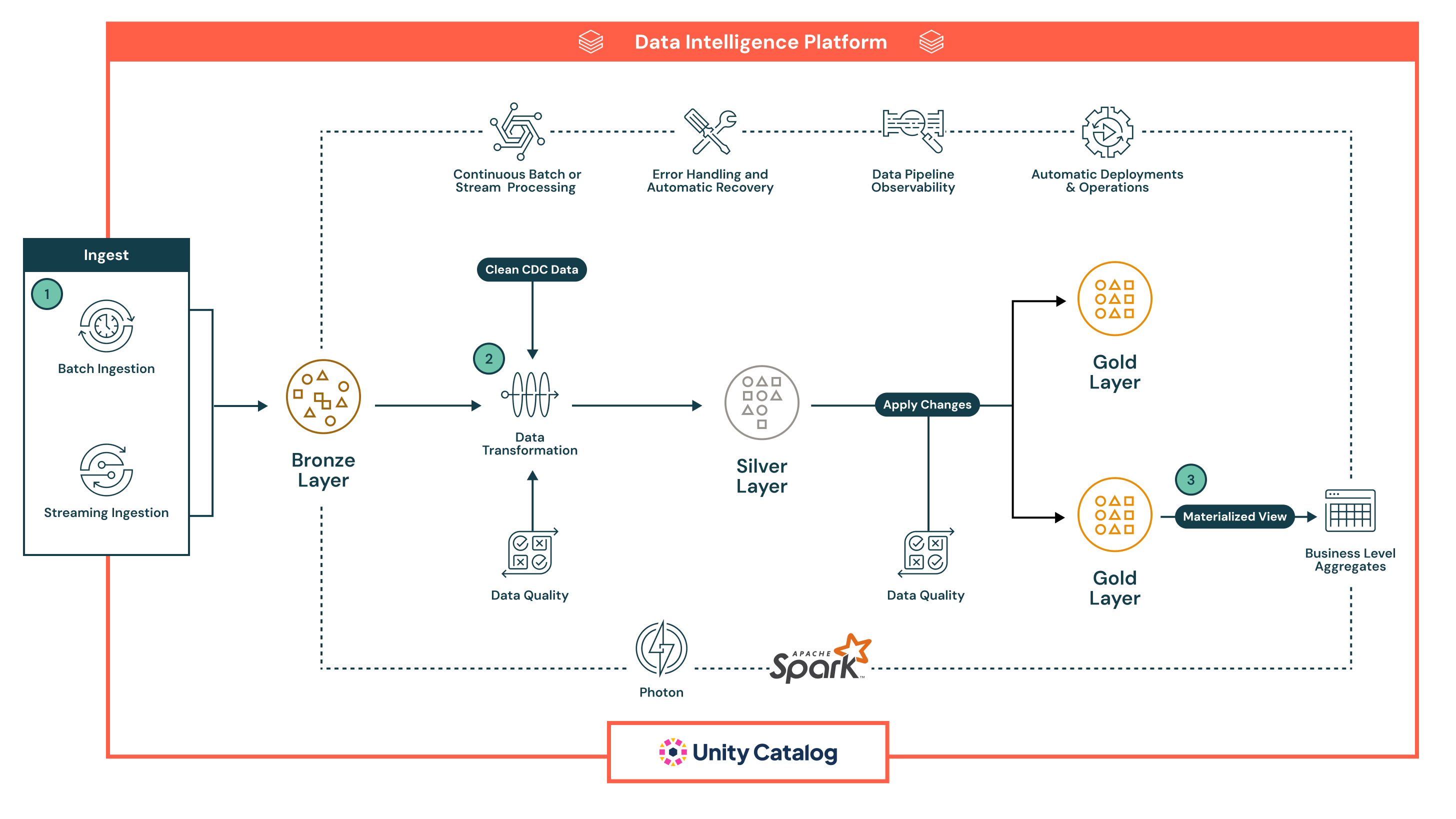
V tomto příkladu data nejprve přistane do bronzové vrstvy v nezpracované podobě pro rodokmen a bezpečné opětovné zpracování, pak postupuje do vrstvy Silver , kde jsou vyčištěna, rozšířena, ověřena pomocí vložených kontrol kvality a zpracována ve velkém měřítku pomocí Sparku, před dosažením vrstvy Gold , která poskytuje kurátorované datové sady připravené pro BI, strojové učení a pokročilé případy použití, jako je historické sledování.
Azure Data Factory
Azure Data Factory (ADF) umožňuje kopírovat data do a z Azure Databricks Delta Lake pomocí integrované aktivity kopírování. Když funguje jako zdroj, ADF může extrahovat data z tabulek Delta v Databricks a přesunout je do podporovaných jímek; když funguje jako jímka, může načíst data do tabulek Delta Lake z podporovaných zdrojů.
Přesun dat se orchestruje vyvoláním clusteru Databricks pro zpracování přenosu a ADF podporuje prostředí Azure Integration Runtime i místní prostředí Integration Runtime v závislosti na prostředí.
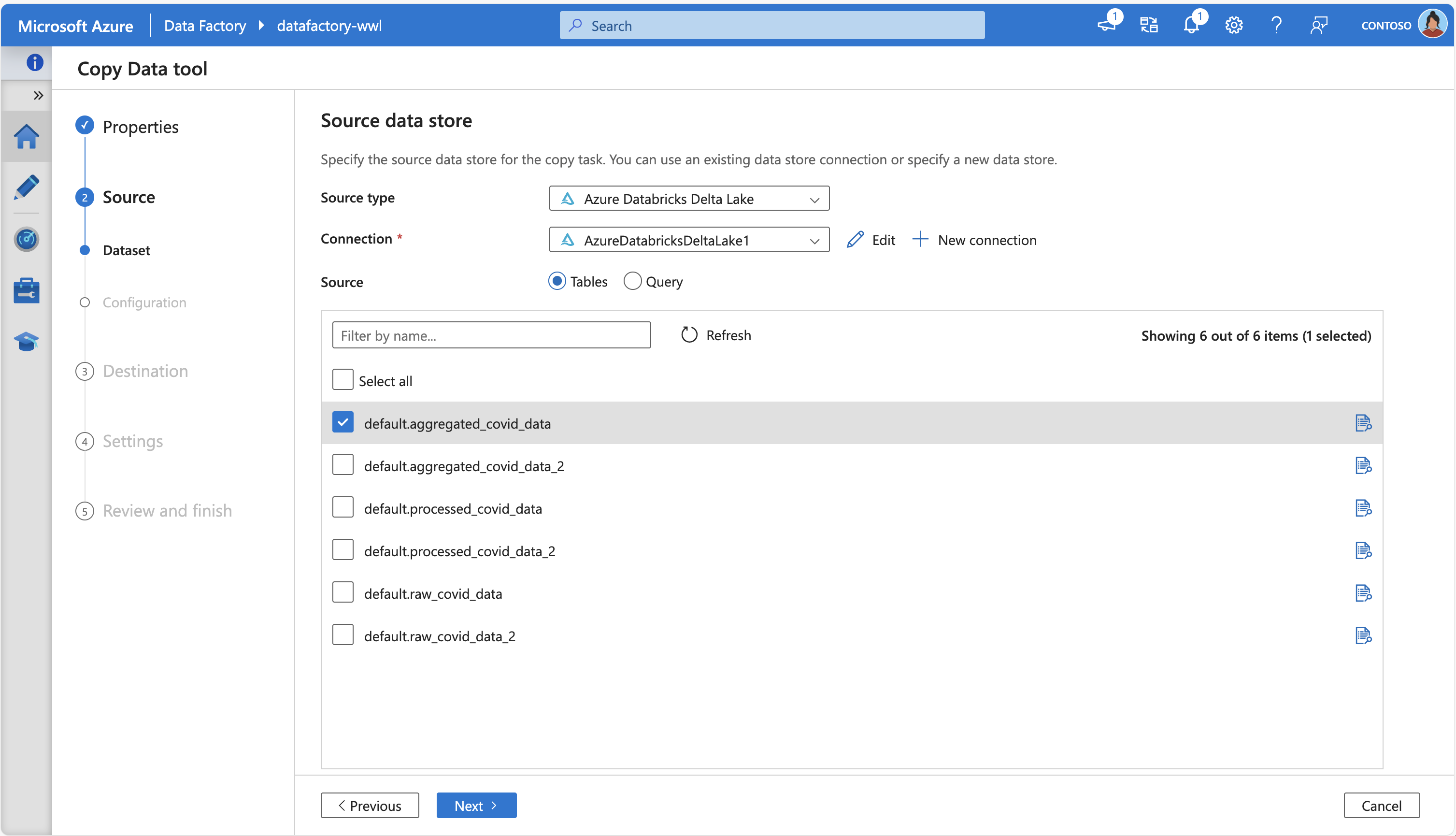
Následující snímek obrazovky ukazuje nástroj pro kopírování dat služby Azure Data Factory, který se připojuje k Azure Databricks Delta Lake a načítá některé zdrojové tabulky:
Kromě toho mapování toků dat ADF nabízejí bezkódové prostředí ETL: mohou zdrojovat a ukládat data ve formátu Delta na Azure Storage, což umožňuje transformace bez psaní kódu, které běží ve spravovaném prostředí Azure Integration Runtime.
Azure Event Hubs a IoT Centrály
Pro příjem dat v reálném čase jsou nejvhodnějšími volbami Azure Event Hubs a IoT Hubs. Umožňují streamovat data přímo do Azure Databricks a umožňují zpracovávat a analyzovat data při jejich doručení. Příjem a analýza dat v reálném čase je užitečný pro scénáře, jako je monitorování živých událostí nebo sledování dat zařízení Internetu věcí (IoT).
Azure Event Hubs má koncový bod kompatibilní se systémem Kafka, který funguje s konektorem Structured Streaming Kafka v Databricks Runtime. Můžete nastavit deklarativní kanály Lakeflow pro připojení k instanci služby Event Hubs a zpracování událostí z tématu.