Kdy byste měli použít HDInsight Interactive Query?
Jako obchodní analytik musíte určit nejvhodnější typ clusteru HDInsight, který se má vytvořit, aby bylo možné sestavit řešení. Clustery Interaktivní dotazy poskytují řadu funkcí a možností interoperability, díky kterým jsou obchodní analytici obeznámeni s SQL jedinečně přínosem. Je to skvělé pro uživatele, kteří chtějí pracovat s nástroji business intelligence a vyžadují rychlé interaktivní dotazy. Existují další výhody, jako je podpora pro řadu formátů souborů, souběžnost a Atomic, Konzistentní, Izolované a Durable (ACID). Nemluvě o integraci s Apache Rangerem pro podrobnou kontrolu nad daty na úrovni řádků a sloupců.
Poznámka:
Obsah tohoto modulu se týká clusterů Interactive Query vytvořených pro HDInsight 4.0, které používají Hive 3.1 a LLAP, označované také jako Hive LLAP.
Máte velkou datovou sadu, která je připravená k dotazování.
Clustery interaktivních dotazů jsou nejvhodnější pro velké datové sady, které se dají dotazovat tak, jak jsou, nebo s minimálními transformacemi. Situace, kdy budete provádět různé dotazy na data a potřebujete okamžité odpovědi. Clustery interaktivních dotazů nejsou optimalizované pro provádění dlouhotrvajících dávkových výpočtů. Interaktivní dotaz podporuje následující formáty souborů: ORC, Parquet, CSV, Avro, JSON, text a tsv.
Vyžadujete funkce podobné SQL.
Pokud potřebujete provádět interaktivní a ad hoc dotazy na latenci podsekundových dat s velkými objemy dat, které máte v Úložišti Azure a Azure Data Lake Storage, a dáváte přednost prostředí podobné SQL, jsou clustery Azure HDInsight Interactive Query skvělou volbou. Jako obchodní analytik jste velmi obeznámeni s tabulkami SQL a vytvářením dotazů pomocí SQL. Apache Hadoop je výkonný nástroj pro provádění analýz velkých objemů dat. Použití architektury MapReduce a jeho rozhraní Java API pro Apache Hadoop může být pro vás překážkou, pokud jsou vaše programovací dovednosti v Javě trochu rustické. V tomto případě je HDInsight Interactive Query vhodnější, protože je postaven na Apache Hadoopu, ale je jednodušší pro každého, kdo má zkušenosti s SQL používat. Interaktivní dotaz používá tabulky Hive podobné SQL ke zpracování dat a dotazovacího jazyka podobného JAZYKu SQL, který se nazývá HiveQL k dotazování dat. Použití Hivu je méně složité než zpracování dat pomocí MapReduce v Apache Hadoopu. Hive usnadňuje a zefektivňuje zavádění řešení pro vaši společnost.
Rychlé interaktivní dotazy s inteligentním ukládáním do mezipaměti
Clustery Interactive Query používají inteligentní techniky ukládání do mezipaměti k vrstvení dat napříč dynamickou pamětí RAM, ssd místního uzlu clusteru a systémy vzdáleného úložiště, jako jsou Azure Blob a Azure Data Lake Storage, aby bylo možné dosáhnout interaktivních a rychlých výsledků dotazů nad velkými objemy dat. Jedním z dobrých příkladů pokročilé techniky ukládání do mezipaměti je dynamická mezipaměť textu, která převádí data CSV na optimalizovaný formát v paměti za běhu, takže ukládání do mezipaměti je dynamické a dotazy určují, jaká data se ukládají do mezipaměti. Tato funkce znamená, že nemusíte nejprve načítat a transformovat data. Data můžete nahrát do úložiště Azure v původním formátu a začít je dotazovat. A také to znamená, že dotazy jsou výkonnější při druhém spuštění. Při prvním spuštění dotazu se data čtou z vrstvy úložiště obchodních dat ve službě Azure Storage nebo Azure Data Lake Gen2. Data se pak ukládají do sdílené mezipaměti v paměti v clusteru. Při příštím spuštění dotazu se data jednoduše načtou ze sdílené mezipaměti v paměti a ušetříte čas načtením dat z vrstvy vzdáleného úložiště.
Spouštění dotazů pomocí oblíbených nástrojů
Interaktivní dotaz usnadňuje práci s velkými objemy dat pomocí nástrojů BI, které znáte, jako jsou Microsoft Power BI a Tableau. V analýzách velkých objemů dat jsou organizace stále častěji znepokojeny tím, že jejich koncoví uživatelé nedostávají dostatečnou hodnotu z analytických systémů, protože je často příliš náročné a vyžaduje použití neznámých a obtížně naučit se nástrojů ke spuštění analýzy. HDInsight Interactive Query řeší tento problém tím, že k získání přehledu z dat vyžaduje minimální, aby žádné nové uživatelské trénování nezískaly. Uživatelé mohou psát dotazy podobné SQL HiveQL v nástrojích, které už používají. Mezi tyto nástroje patří Visual Studio Code, Power BI, Apache Zeppelin, Visual Studio, Ambari Hive View, Beeline, Data Analytics Studio a Hive ODBC. V clusteru Interactive Query nemůžete provádět dotazy pomocí konzoly Hive, Templetonu, Azure Classic CLI nebo Azure PowerShellu.
Vyžadujete konzistenci transakcí a souběžnost.
Díky zavedení jemně odstupňované správy prostředků, vyřazení a sdílení dat uložených v mezipaměti napříč dotazy a uživateli podporuje Interactive Query souběžné uživatele snadno. HDInsight podporuje vytváření více clusterů ve sdíleném úložišti Azure. Metastore Hive pomáhá dosáhnout vysokého stupně souběžnosti. Souběžnost můžete škálovat přidáním dalších uzlů clusteru nebo přidáním dalších clusterů odkazujících na stejná podkladová data a metadata. Interactive Query také podporuje databázové transakce, které jsou Atomic, Consistent, Isolated a Durable (ACID). Transakce ACID zaručují, že transakce, i když obsahuje více operací, je obsažena v jedné jednotce. Proto, pokud jakákoli jedna operace v transakci selže, může být celá operace vrácena zpět, což udržuje data konzistentní a přesná.
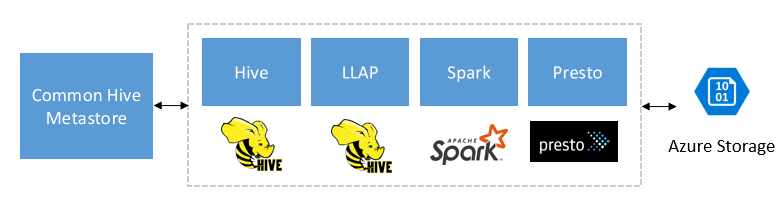
Vytvořeno pro doplnění Sparku, Hive, Presto a dalších modulů pro velké objemy dat
Interaktivní dotaz HDInsight je navržený tak, aby dobře fungoval s oblíbenými moduly pro velké objemy dat, jako jsou Apache Spark, Hive, Presto a další. Tento typ dotazu je zvlášť užitečný, protože uživatelé si můžou vybrat některý z těchto nástrojů ke spuštění analýz. Díky architektuře sdílených dat a metadat služby HDInsight pro externí tabulky můžou uživatelé vytvářet více clusterů se stejnými nebo různými moduly odkazujícími na stejná podkladová data a metadata. Tato funkce je výkonný koncept, protože už nejste vázáni jednou technologií pro analýzu.