Použití Apache Phoenixu v HDInsight HBase
Clustery HBase ve službě HDInsight jsou součástí Apache Phoenixu. Apache Phoenix je opensourcová, masivně paralelní relační databázová vrstva založená na Apache HBase. Apache Phoenix umožňuje používat dotazy podobné JAZYKu SQL přes HBase. Pomocí ovladačů JDBC pod nimi umožňuje uživatelům vytvářet, odstraňovat a měnit tabulky SQL. Můžete také indexovat, vytvářet zobrazení a sekvence a upsertovat řádky jednotlivě a hromadně. Phoenix používá nativní kompilaci noSQL místo použití MapReduce ke kompilaci dotazů, což umožňuje vytvářet aplikace s nízkou latencí nad HBase. Phoenix přidává koprocesory pro podporu spouštění kódu dodaného klientem v adresních prostorech serveru a spouští kód společně s daty. Tento přístup minimalizuje přenos dat klienta nebo serveru. Další informace najdete v dokumentaci k Apache Phoenixu.
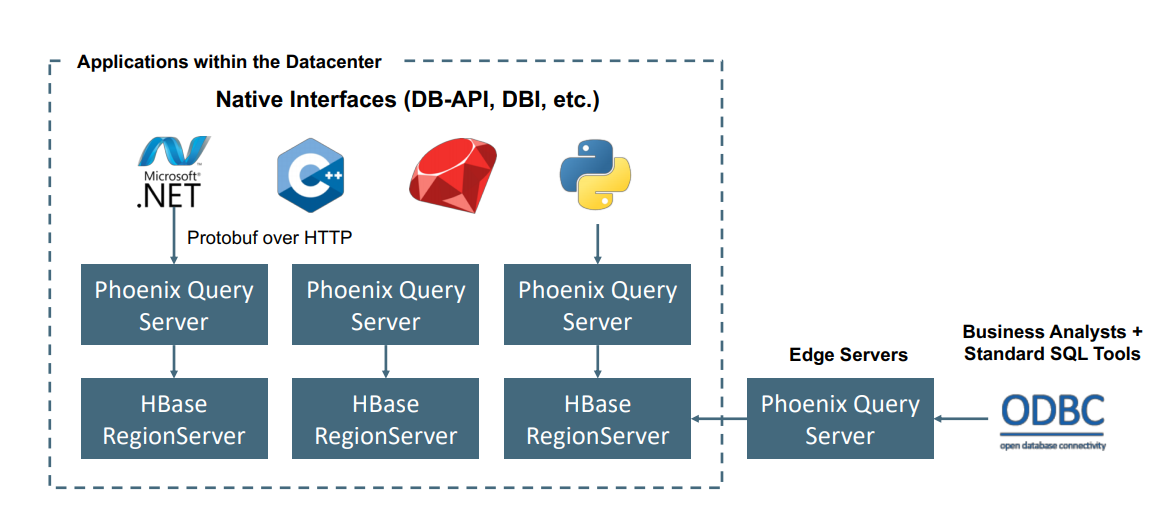
Apache Phoenix ve službě HDInsight HBase se obvykle používá k povolení samoobslužných analýz a extrahování přehledů, jak je znázorněno níže. Phoenix se může připojit k libovolnému nástroji ODBC kompatibilnímu s BI a povolit ad hoc analýzy SQL na HBase.
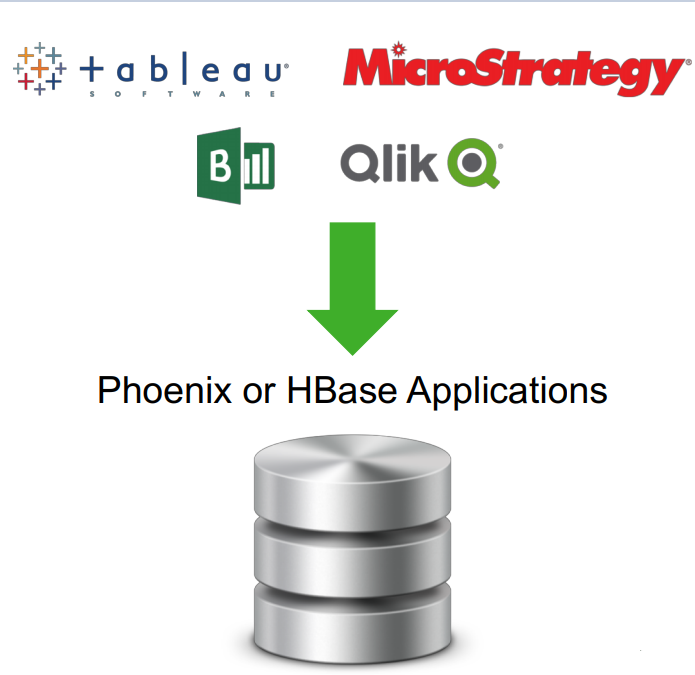
Kombinování Apache HBase a Phoenixu lze použít jako úložiště dat pro proměnlivá data. Dotazovací modul Apache Phoenix v HBase obsahuje některé důležité funkce.
Sekundární indexy
K záznamům v HBase se přistupuje pomocí primárního klíče řádku pomocí jednoho indexu, který je lexikicky seřazený na primárním klíči řádku. Pokud se pokusíte získat přístup k záznamům jakýmkoli jiným způsobem než primárním řádkem, mohlo by to vést k neefektivní kontrole všech dat v tabulce HBase. Apache Phoenix umožňuje vytvořit sekundární indexy pro sloupce a výrazy a vytvořit alternativní klíče řádků, které umožní prohledání bodů nebo rozsahu podél tohoto nového indexu. Další informace najdete v dokumentaci k sekundárním indexům Apache Phoenix.
Příkaz CREATE INDEX slouží k vytvoření sekundárních indexů v HBase, jak je znázorněno níže.
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
Zobrazení
Doporučeným strategií je omezení počtu fyzických tabulek v HBase a omezení počtu oblastí. Zobrazení v Phoenixu pomáhají tomuto doporučení tím, že umožňují vytvářet více virtuálních tabulek sdílejících stejnou základní fyzickou tabulku v HBase. Další informace najdete v dokumentaci k Apache Phoenix Views.
Vzhledem k následující definici tabulky v HBase.
CREATE TABLE product_metrics (
metric_type CHAR(1),
created_by VARCHAR,
created_date DATE,
metric_id INTEGER
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
Můžete definovat následující zobrazení.
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS SELECT * FROM product_metric WHERE metric_type = 'm';
Transakce
I když HBase funguje pouze s transakcemi na úrovni řádků, Apache Phoenix umožňuje transakce mezi tabulkami a křížovými řádky s plnou podporou ACID integrací s Apache Tephra.
Další informace najdete v dokumentaci k transakcím Apache Phoenix.
Následující příklad vytvoří tabulku s názvem my_table a potom změní tabulku tak, aby umožňoval transakce.
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
Slané stoly
Pokud se klíče řádků monotonicky zvětší, může během sekvenčních zápisů dojít k hotspotům oblastového serveru v HBase. Apache Phoenix může zmírnit hotspoty tím, že poskytuje způsob, jak slanit klíč řádku se slaným bajtem pro určitou tabulku. Další informace najdete v dokumentaci k Apache Phoenix Salted Table.
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
Přeskočit kontrolu
Pro danou sadu řádků používá Apache Phoenix ke skenování uvnitř řádků kontrolu v rozsahu, aby se zlepšil výkon. Skip Scan využívá filtr SEEK_NEXT_USING_HINT HBase. Ukládá informace o tom, jakou sadu klíčů a rozsahů klíčů se hledají v jednotlivých sloupcích. Pak vezme klíč (předaný ho během vyhodnocení filtru) a zjistí, jestli je v jedné z kombinací nebo rozsahu nebo ne. Pokud ne, zjistí, na který další nejvyšší klíč se má přeskočit. Další informace najdete v dokumentaci apache Phoenix Skip Scan.
Optimalizace výkonu v Apache Phoenixu je volitelná požadovaná funkce, která je většinou závislá na optimalizaci výkonu HBase pod ním. Optimalizace výkonu je komplexní téma, které je nad rámec tohoto kurzu. Pokud vás to ale zajímá, můžete se podívat do dokumentace k osvědčeným postupům pro výkon Apache Phoenixu.