Vizualizace dat pomocí Sparku
Jedním z nejtuitivnějších způsobů, jak analyzovat výsledky datových dotazů, je vizualizovat je jako grafy. Poznámkové bloky ve službě Azure Synapse Analytics poskytují některé základní funkce grafů v uživatelském rozhraní a pokud tyto funkce neposkytují to, co potřebujete, můžete v poznámkovém bloku vytvářet a zobrazovat vizualizace dat pomocí některé z mnoha grafických knihoven Pythonu.
Používání vestavěných grafů poznámkových bloků
Když v poznámkovém bloku Sparku v Azure Synapse Analytics zobrazíte datový rámec nebo spustíte dotaz SQL, zobrazí se výsledky v buňce kódu. Ve výchozím nastavení se výsledky vykreslují jako tabulka, ale můžete také změnit zobrazení výsledků na graf a pomocí vlastností grafu přizpůsobit, jak graf vizualizuje data, jak je znázorněno tady:
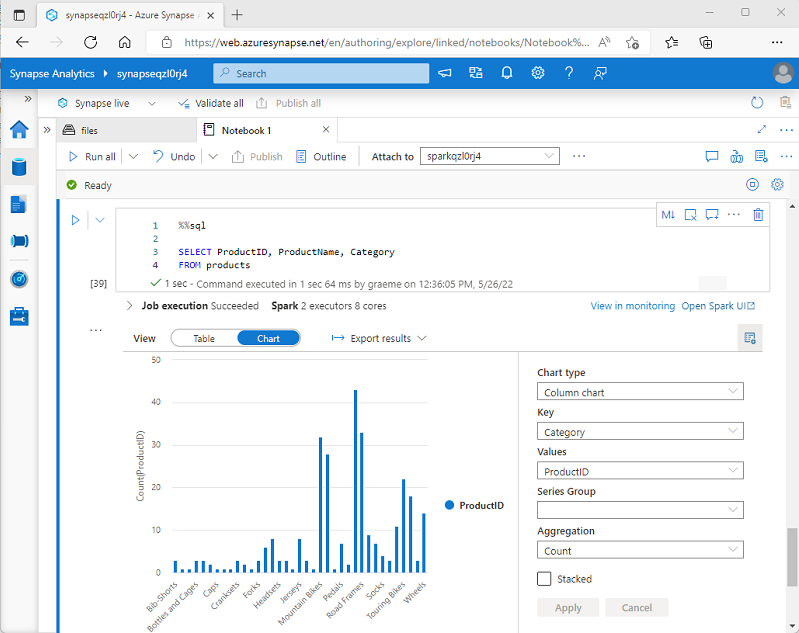
Integrované funkce grafů v poznámkových blocích jsou užitečné, když pracujete s výsledky dotazu, který neobsahuje žádné existující seskupení nebo agregace, a chcete data vizuálně shrnout. Pokud chcete mít větší kontrolu nad formátováním dat nebo zobrazením hodnot, které jste už v dotazu agregovali, měli byste zvážit použití grafického balíčku k vytvoření vlastních vizualizací.
Použití grafických balíčků v kódu
Existuje mnoho grafických balíčků, které můžete použít k vytváření vizualizací dat v kódu. Python zejména podporuje velký výběr balíčků; většina z nich je postavena na základní knihovně Matplotlib . Výstup z grafické knihovny je možné vykreslit v poznámkovém bloku, což usnadňuje kombinování kódu pro příjem a manipulaci s daty pomocí vložených vizualizací dat a buněk markdownu pro poskytnutí komentáře.
Pomocí následujícího kódu PySpark můžete například agregovat data z hypotetických dat produktů, která jste prozkoumali dříve v tomto modulu, a použít Matplotlib k vytvoření grafu z agregovaných dat.
from matplotlib import pyplot as plt
# Get the data as a Pandas dataframe
data = spark.sql("SELECT Category, COUNT(ProductID) AS ProductCount \
FROM products \
GROUP BY Category \
ORDER BY Category").toPandas()
# Clear the plot area
plt.clf()
# Create a Figure
fig = plt.figure(figsize=(12,8))
# Create a bar plot of product counts by category
plt.bar(x=data['Category'], height=data['ProductCount'], color='orange')
# Customize the chart
plt.title('Product Counts by Category')
plt.xlabel('Category')
plt.ylabel('Products')
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
plt.xticks(rotation=70)
# Show the plot area
plt.show()
Knihovna Matplotlib vyžaduje, aby data byla v datovém rámci Pandas, nikoli v datovém rámci Sparku, takže metoda toPandas se používá k převodu. Kód následně vytvoří obraz se zadanou velikostí a vykreslí pruhový graf s vlastní konfigurací, než zobrazí výsledný graf.
Graf vytvořený kódem by vypadal podobně jako na následujícím obrázku:
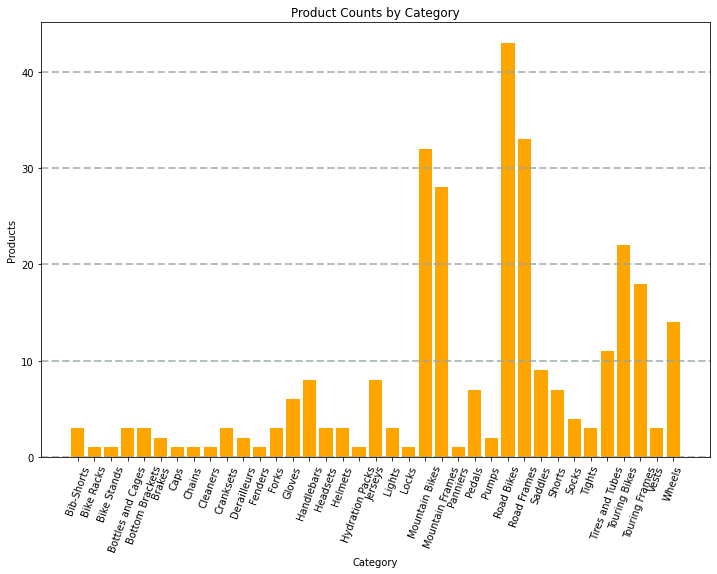
Knihovnu Matplotlib můžete použít k vytvoření mnoha druhů grafů; nebo pokud chcete, můžete k vytváření vysoce přizpůsobených grafů použít jiné knihovny, jako je Seaborn .