Co je regrese?
Regrese je jednoduchá, běžná a vysoce užitečná technika analýzy dat, která se často označuje jako "přizpůsobení přímky". V nejjednodušší podobě regrese zapadá přímku mezi jednou proměnnou (funkcí) a jinou (popiskem). Ve složitějších formách může regrese najít nelineární vztahy mezi jedním popiskem a více funkcemi.
Jednoduchá lineární regrese
Jednoduché lineární regrese modeluje lineární vztah mezi jednou funkcí a obvykle souvislým popiskem, který funkci umožňuje předpovědět popisek. Vizuálně může vypadat nějak takto:
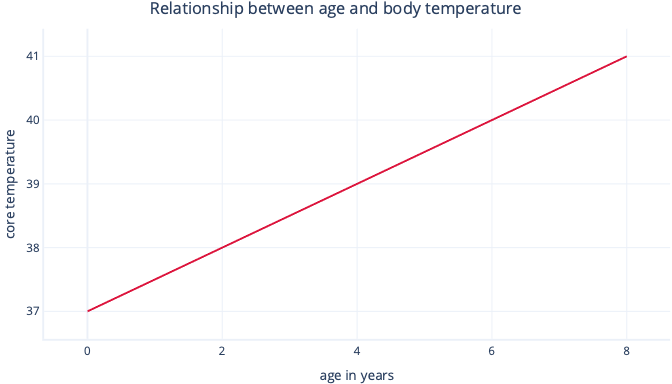
Jednoduchá lineární regrese má dva parametry: průsečík (c), který označuje hodnotu, že popisek je, když je funkce nastavená na nulu, a sklon (m), který označuje, kolik popisku se zvýší pro každé jednobodové zvýšení funkce.
Pokud se chcete matematicky zamyslet, stačí:
y=mx+c
Kde y je váš popisek a x je vaše funkce.
Pokud bychom se například v našem scénáři pokusili předpovědět, kteří pacienti budou mít teplotu v těle zvýšené horečkou na základě jejich věku, měli bychom model:
temperature=m*age+c
A musí najít hodnoty m a c během procesu montáže. Pokud jsme našli m = 0,5 a c = 37, můžeme ho vizualizovat takto:
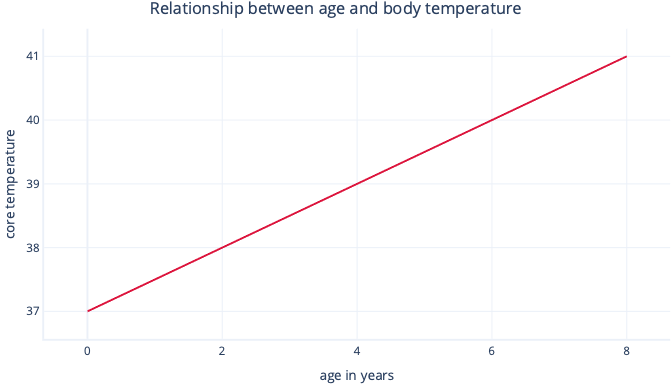
To by znamenalo, že každý rok věku je spojena s nárůstem tělesné teploty o 0,5°C, s počátečním bodem 37°C.
Fitování lineární regrese
K přizpůsobení regresních modelů pro nás obvykle používáme existující knihovny. Regrese se obvykle zaměřuje na nalezení přímky, která vede k nejmenšímu množství chyby, kde zde chyba znamená rozdíl mezi skutečnou hodnotou datového bodu a předpovězenou hodnotou. Například na následujícím obrázku černá čára označuje chybu mezi predikcí, červenou čárou a jednou skutečnou hodnotou: tečka.
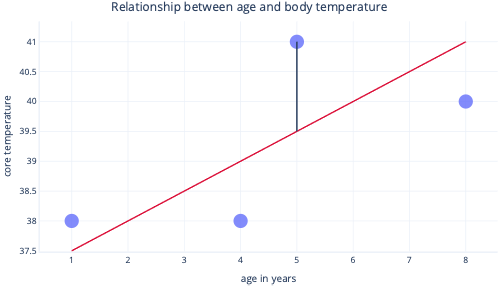
Když se podíváme na tyto dva body na ose y, vidíme, že předpověď byla 39,5, ale skutečná hodnota byla 41.
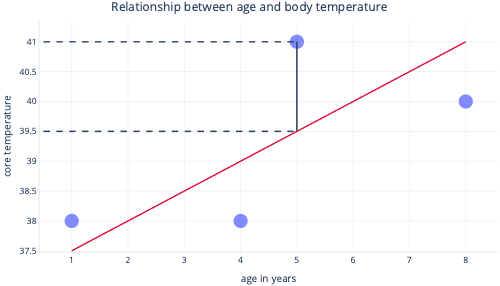
Proto byl model pro tento datový bod chybný ve verzi 1.5.
Nejčastěji se model hodí minimalizací zbytkového součtu čtverců. To znamená, že funkce nákladů se vypočítá takto:
- Vypočítejte rozdíl mezi skutečnými a predikovanými hodnotami (jako dříve) pro každý datový bod.
- Tyto hodnoty se čtverely.
- Součet (nebo průměr) těchto čtvercových hodnot
Tento krok squaringu znamená, že ne všechny body přispívají rovnoměrně ke spojnici: odlehlé hodnoty , což jsou body, které nespadají do očekávaného vzoru, mají nepřiměřeně větší chybu, která může ovlivnit pozici přímky.
Silné stránky regrese
Regresní techniky mají mnoho silných stránek, které složitější modely nemají.
Předvídatelné a snadno interpretovatelné
Regrese se snadno interpretují, protože popisují jednoduché matematické rovnice, které můžeme často grafovat. Složitější modely se často označují jako řešení černé skříňky , protože je obtížné pochopit, jak provádějí předpovědi nebo jak se budou chovat s určitými vstupy.
Snadné extrapolace
Regrese usnadňují extrapolaci; pro predikce hodnot mimo rozsah naší datové sady. V našem předchozím příkladu je například jednoduché odhadnout, že devět let starý pes bude mít teplotu 40,5°C. Na extrapolaci byste měli vždy aplikovat opatrnost: tento model by předpověděl, že 90letý by měl teplotu téměř horkou na vaření vody.
Optimální fitování je obvykle zaručeno.
Většina modelů strojového učení používá gradientní sestup pro přizpůsobení modelů, což zahrnuje ladění algoritmu gradientní sestupu a neposkytuje žádnou záruku, že se najde optimální řešení. Naproti tomu lineární regrese, která používá součet čtverců jako nákladové funkce, ve skutečnosti nepotřebuje iterativní postup gradientního sestupu. Místo toho lze chytrá matematika použít k výpočtu optimálního umístění pro umístění čáry. Matematika je mimo rozsah tohoto modulu, ale je užitečné vědět, že (pokud velikost vzorku není příliš velká), lineární regrese nemusí věnovat zvláštní pozornost procesu přizpůsobení a optimální řešení je zaručeno.